跟着刚哥学Redis
NoSQL 简介
NoSQL(NoSQL = Not Only SQL ),意即"不仅仅是SQL"。是对不同于传统的关系型数据库的数据库管理系统的统称。它泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题,包括超大规模数据的存储。
为什么使用NoSQL?
今天我们可以通过第三方平台(如:Google,Facebook等)可以很容易的访问和抓取数据。用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍的增加。我们如果要对这些用户数据进行挖掘,那SQL数据库已经不适合这些应用了, NoSQL数据库的发展也却能很好的处理这些大的数据。NoSQL用于超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
1、扩展性更好
NoSQL去掉了关系数据库的关系型特性。数据之间无关系更易扩展。也无形之间,在架构的层面上带来了可扩展的能力。
2、性能更优
NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。
3、数据类型多样灵活
NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段简直就是一个噩梦
关系型数据库遵循ACID规则
事务在英文中是transaction,和现实世界中的交易很类似,它有如下四个特性:
1、A (Atomicity) 原子性
原子性很容易理解,也就是说事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚。
比如银行转账,从A账户转100元至B账户,分为两个步骤:1)从A账户取100元;2)存入100元至B账户。这两步要么一起完成,要么一起不完成,如果只完成第一步,第二步失败,钱会莫名其妙少了100元。
2、C (Consistency) 一致性
一致性也比较容易理解,也就是说数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。
例如现有完整性约束a+b=10,如果一个事务改变了a,那么必须得改变b,使得事务结束后依然满足a+b=10,否则事务失败。
3、I (Isolation) 独立性
所谓的独立性是指并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。
比如现有有个交易是从A账户转100元至B账户,在这个交易还未完成的情况下,如果此时B查询自己的账户,是看不到新增加的100元的。
4、D (Durability) 持久性
持久性是指一旦事务提交后,它所做的修改将会永久的保存在数据库上,即使出现宕机也不会丢失。
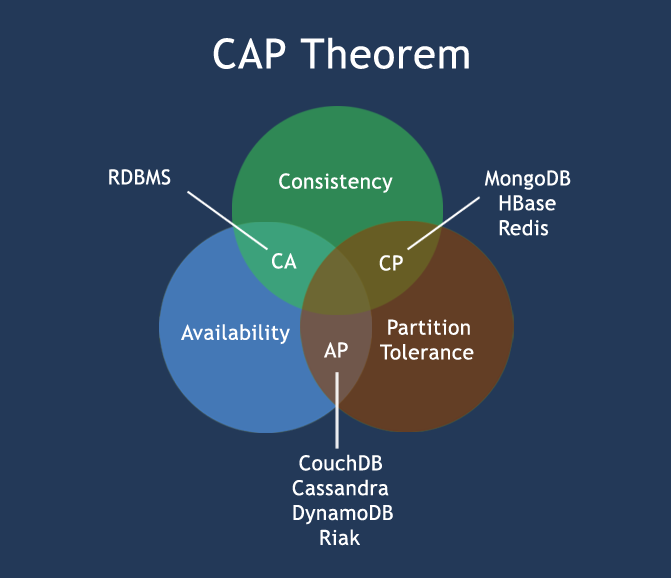
CAP定理(CAP theorem)
在计算机科学中, CAP定理指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency) (所有节点在同一时间具有相同的数据)
- 可用性(Availability) (保证每个请求不管成功或者失败都有响应)
- 分区容忍(Partition tolerance) (系统中任意信息的丢失或失败不会影响系统的继续运作)
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时满足两个。
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三大类:
- CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。传统的数据库Mysql
- CP - 满足一致性,分区容忍性的系统,通常性能不是特别高。Redis、Mongodb
- AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
BASE
BASE:Basically Available, Soft-state, Eventually Consistent。 由 Eric Brewer 定义。
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
BASE是NoSQL数据库通常对可用性及一致性的弱要求原则:
- Basically Availble --基本可用
- Soft-state --软状态/柔性事务。 "Soft state" 可以理解为"无连接"的, 而 "Hard state" 是"面向连接"的
- Eventual Consistency --最终一致性 最终一致性, 也是是 ACID 的最终目的。
它的思想是通过让系统放松对某一时刻数据一致性的要求来换取系统整体伸缩性和性能上改观。为什么这么说呢,缘由就在于大型系统往往由于地域分布和极高性能的要求,不可能采用分布式事务来完成这些指标,要想获得这些指标,我们必须采用另外一种方式来完成,这里BASE就是解决这个问题的办法
ACID vs BASE
| ACID | BASE |
|---|---|
| 原子性(Atomicity) | 基本可用(Basically Available) |
| 一致性(Consistency) | 软状态/柔性事务(Soft state) |
| 隔离性(Isolation) | 最终一致性 (Eventual consistency) |
| 持久性 (Durable) |
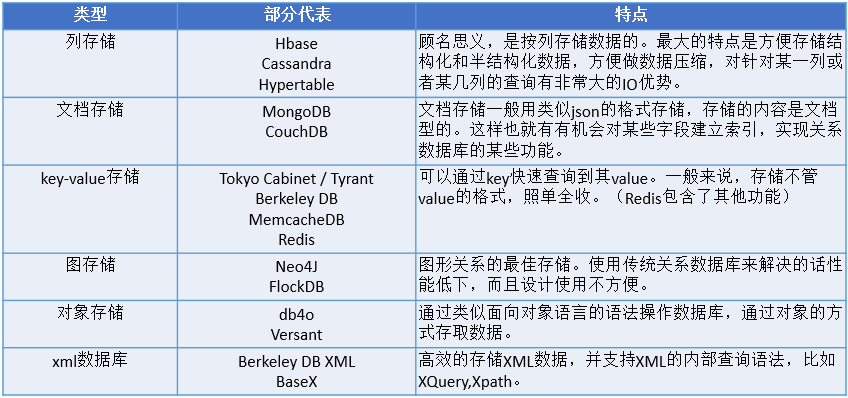
NoSQL 数据库分类
分布式和集群的区别
- 分布式:不同的多台服务器上面部署不同的模块(工程),他们通过Rpc/Rmi之间通信和调用,对外提供服务和组内协作。
- 集群:不同的多台服务器上面部署相同的模块,通过分布式调度软件进行统一的调度,对外提供服务和访问。
Redis简介:
- 是完全开源免费的,用C语言编写的,遵守BSD协议,
- 是一个高性能的(key/value)分布式内存数据库,基于内存运行
- 并支持持久化的NoSQL数据库,是当前最热门的NoSql数据库之一
Redis 优势
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 持久性 – Redis可以将内存的数据保存在磁盘中,重启的时候可以再次加载到内存中使用。
- 丰富的特性 – Redis还支持 发布和订阅, 通知, key 过期等等特性。
Redis 安装
1、先去下载Redis,下载地址:http://www.redis.cn/(Redis中文官网)
2、把下载好的文件:redis-3.2.9.tar.gz放到/opt下,然后运行tar -zxvf redis-3.2.9.tar.gz。解压完成后出现文件夹:redis-3.2.9
3、进入目录:cd redis-3.2.9,在目录下执行make命令(需要Linux上有c的编译器JCC)
4、看到以下信息证明编译(编译命令是make)OK了,它会建议你执行make test,这里想说的是不需要执行,因为它需要一个很恶心的TCL。跳过。

5、编译完成之后就是安装(make install)了,进入到redis-3.2.9目录下执行make install

6、安装完后,看看/usr/local/bin下目录多了redis的安装目录(usr目录就是我们Windows里的Program Files)
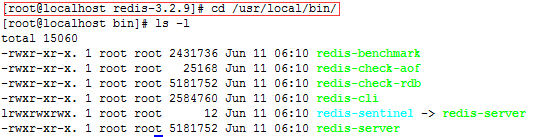
7、将redis.conf文件移动到其他的目录下(目的是不要污染原redis文件),
① 执行mkdir文件 ,创建一个环境文件夹,mkdir /opt/redis-3.2.9/etc
② 执行cp命令 /opt/redis-3.2.9/redis.conf /opt/redis-3.2.9/etc/redis.conf
8、修改一下刚刚redis移动后的配置文件,把启动改为后台自动运行,vim /opt/redis/ect/redis.conf

9、启动服务,redis-server /opt/redis-3.2.9/etc/redis.conf(服务已经启动了,到这里其实所有安装和部署都OK了)
那我们需要验证一下安装和部署的redis是否正常
1、运行一下客户端,还是在bin的目录下,执行 redis-cli 命令(目的是验证一下服务是否启动正常)

2、执行一下ping,然后返回 pong
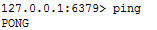
到此所有的安装和部署都验证通过了。6379:redis的默认端口号
如何关闭redis服务呢?
执行shutdown命令就行了,或者kill掉进程(先用ps -ef|grep redis查看进程号,然后kill -9 进程号)

Redis 有多快
1、还是进入到bin目录下,cd /usr/local/bin。
2、执行redis-benchmark命令(官方自带的Redis性能测试工具,可以有效的测试Redis服务的性能)

上面讲到了官网读是每秒11万,写每秒是8万,虚拟机实际跑出来的数据还是差很远,服务器的肯定会比这数字高很多。
不过这数字也够吓人的,互联网的产品太可怕了,不亏是性能强悍的高速缓存,太牛逼了。
Redis 启动后的一些知识点
1、Redis有16个数据库
我们还是看一下redis.conf文件,就能发现默认就是16个数据库

默认是第一个库即(select 0)

2、常用的命令
① select 命令:切换数据库
② dbsize命令:查看当前数据的key的数量
③ flushdb:清空当前库
④ Flushall:通杀16个全部库
Redis 命令
1、redis键(key)
① keys *:查看当前数据库的所有key
② keys k?:查看当前数据库k开头后面有1位的key
③ exists key的名字,判断某个key是否存在
④ move key db:将当前数据库的 key 移动到给定的数据库 db 当中。当前的移除了。
⑤ expire key 秒钟:为给定的key设置过期时间
⑥ ttl key 查看还有多少秒过期,-1表示永不过期,-2表示已过期
⑦ type key 查看你的key是什么类型
2、redis字符串(string)
① set/get/del/append/strlen:设置(存在就覆盖)/获取/删除/附件/获取字符串长度
② incr/decr/incrby/decrby:自增一/自减一/增加指定数字/减去指定数字
③ getrange/setrange:获取/设置指定范围内的字符串 例如:gerrange k1 0 3
④ setex(set with expire)键秒值/setnx(set if not exist)

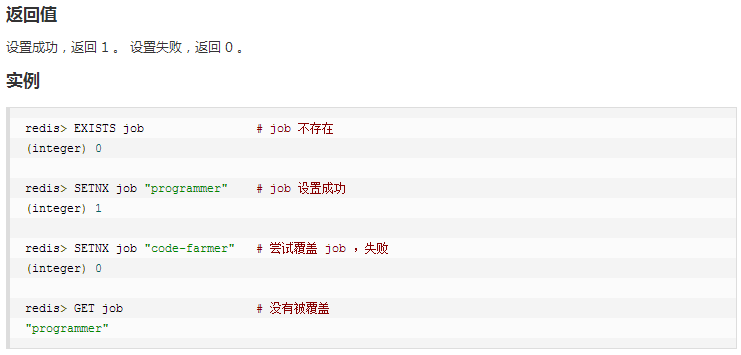
⑤ mset/mget/msetnx:m代表more即可以设置多个
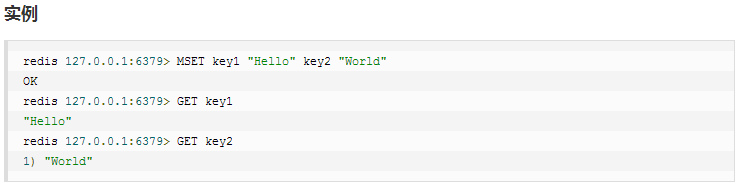

2、redis列表(list)
redis的list是双向链表,更像java的LinkedList,不像ArrayList。
它是一个字符串链表,left、right都可以插入添加;
如果键不存在,创建新的链表;如果键已存在,新增内容;如果值全移除,对应的键也就消失了。
① lpush/rpush/lrange
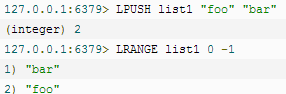
rpush是和lpush正好相反。lrange查询集合的范围
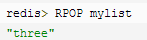
② lpop/rpop:移出并获取列表的第一个元素/移除并获取列表最后一个元素
③ lindex,按照索引下标获得元素(从上到下)。以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。

④ llen:返回列表的长度。 如果列表 key 不存在,则 key 被解释为一个空列表,返回 0
⑤ lrem key 删N个value。
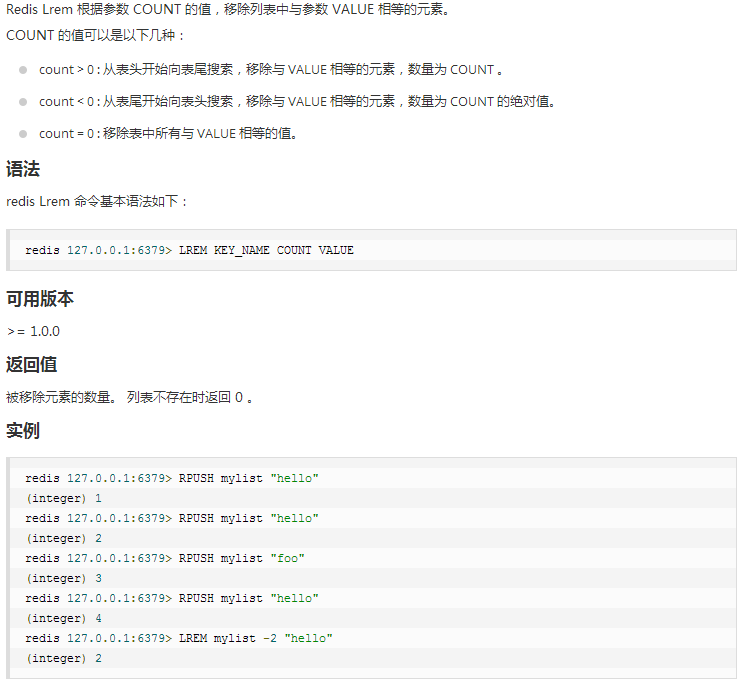
⑥ ltrim key 开始index 结束index,截取指定范围的值后再赋值给key
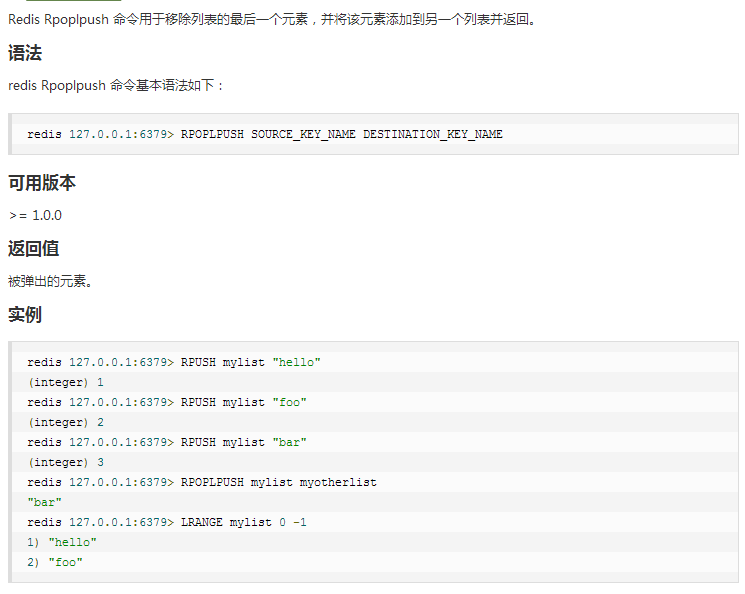
⑦ rpoplpush 源列表 目的列表
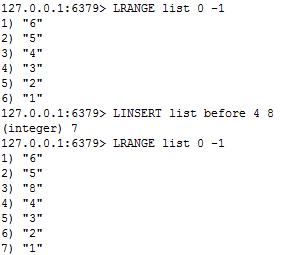
⑧ linsert key before/after 值1 值2
3、redis集合(set)
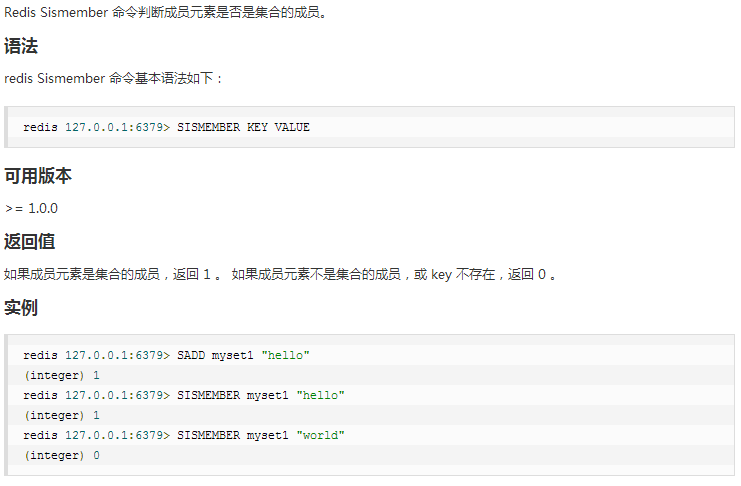
① sadd/smembers/sismember

② scard,获取集合里面的元素个数
③ srem key value 删除集合中元素
④ srandmember key 某个整数(随机出几个数)

⑤ spop key 随机出栈

⑥ smove key1 key2 在key1里某个值 作用是将key1里的某个值赋给key2

⑦ 差集:sdiff

⑧ 交集:sinter

⑨ 并集:sunion
4、redis哈希(hash)
① hset/hget/hmset/hmget/hgetall/hdel

② hlen:获取哈希表中字段的数量
③ hexists key 在key里面的某个值的key
④ hkeys/hvals:获取哈希表中所有的key/value
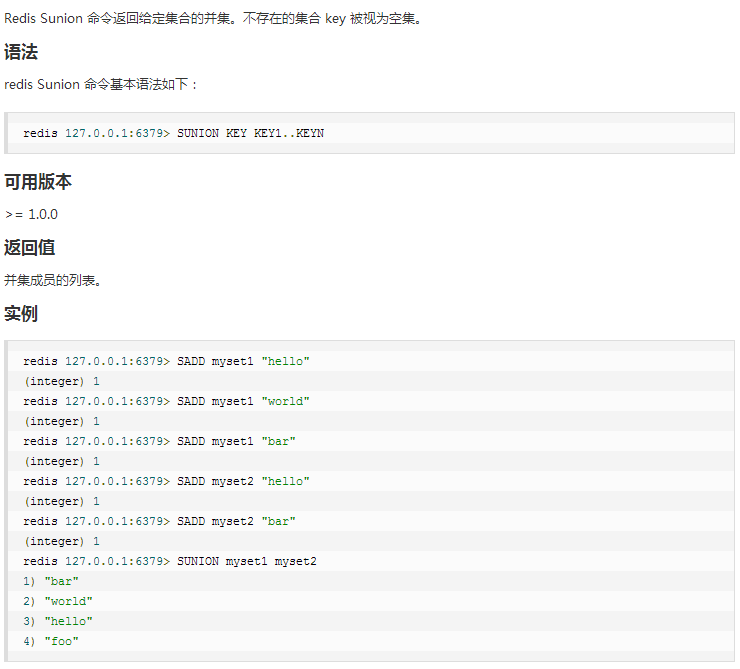
⑤ hincrby/hincrbyfloat
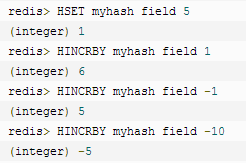
⑥ hsetnx

5、redis有序集合(zset)
在set基础上,加一个score值。之前set是k1 v1 v2 v3,现在zset是k1 score1 v1 score2 v2
① zadd/zrange

② zrangebyscore key 开始score 结束score
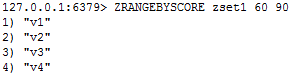
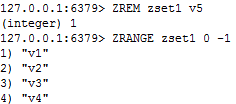
③ zrem key 某score下对应的value值,作用是删除元素
④ zcard/zcount key score区间/zrank key values值,作用是获得下标值/zscore key 对应值,获得分数,“左括号”表示“不等于”

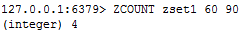
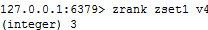

⑤ zrevrank key values值,作用是逆序获得下标值

⑦ zrevrange key 开始index 结束index/zrevrangebyscore key 结束score 开始score


Redis 事务
Redis 事务可以一次执行多个命令, 并且带有以下两个重要的保证:
- 事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
- 事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
一个事务从开始到执行会经历以下三个阶段:
- 开始事务。
- 命令入队。
- 执行事务。
实例
以下是一个事务的例子, 它先以 MULTI 开始一个事务, 然后将多个命令入队到事务中, 最后由 EXEC 命令触发事务, 一并执行事务中的所有命令:

事务遵循几点原则:
刚才的实例是一个正常的一个流程,如果发生错误怎么办?事务在发生错误的时候我们都知道是回滚,redis事务回滚是有两种场景:
1、全部回滚(编译错误)

2、部分回滚(执行错误)

如果取消执行使用关键字:discard
redis事务的锁(watch/unwatch)
学习关系型数据库的时候,我们都知道悲观锁和乐观锁。再回想一下,
1、悲观锁:我很悲观,我有心理疾病,到哪我都觉得有人想杀我,去哪我都先锁门,执行之前先锁表,锁行。适用于强一致性场景。
2、乐观锁:我很乐观,每次去拿数据的时候都不会上锁,只有更新的时候判断一下是否被人改过,适合用于多读的场景。
3、悲观锁和乐观锁是如何实现的呢?
悲观锁应该不用说了吧,直接锁上表和行。
乐观锁是加版本号来实现的,在对某行数据进行一系列操作开始的时候在该行的末尾加了一个版本号例如1.0,在更新时检查一下版本号是否是1.0,中间有人修改过版本号就不是1.0了。那么就不执行了。
回到redis事务的锁,redis事务锁用的是乐观锁
看一个实例,立马就明白了
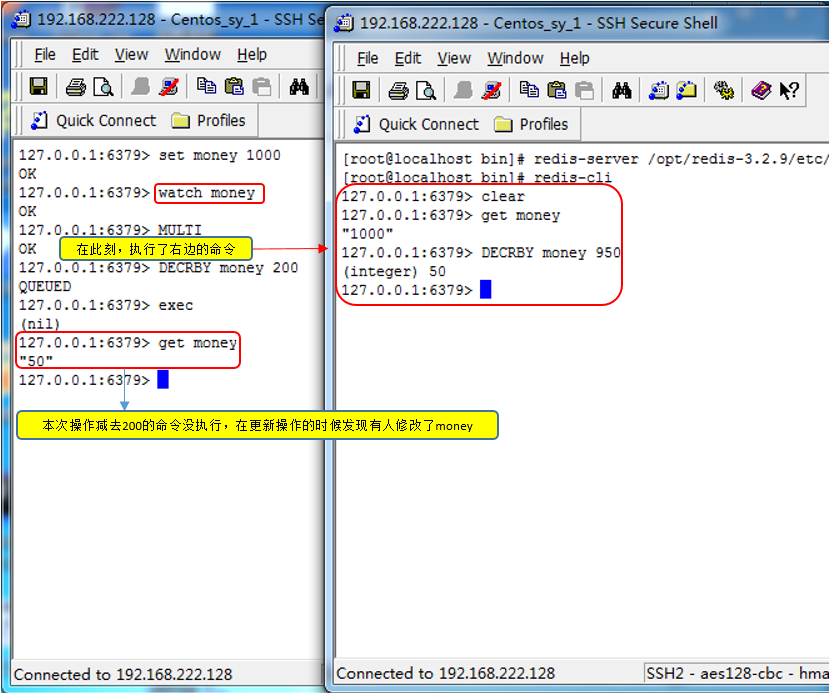
取消锁,用unwatch,还是回到刚才的实例,如果在执行exec前,又执行了unwatch,那么就会执行成功。
Redis 发布订阅
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
Redis 客户端可以订阅任意数量的频道。
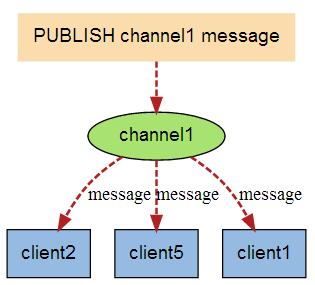
下图展示了频道 channel1 , 以及订阅这个频道的三个客户端 —— client2 、 client5 和 client1 之间的关系:
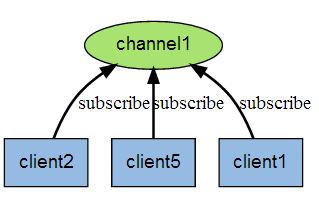
当有新消息通过 PUBLISH 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端:
实例:
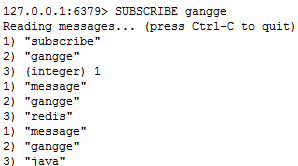
订阅刚哥频道:
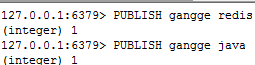
发布刚哥频道:
先订阅后发布才能收到消息:
1、可以一次性订阅多个,SUBSCRIBE c1 c2 c3
2、消息发送,PUBLISH c2 hello-redis
订阅多个,可是使用通配符*,SUBSCRIBE new*
退订使用UNSUBSCRIBE c1
Redis 主从复制
主从复制目的:
1、读写分离
2、容灾备份
怎么玩?
1、配置redis(给每个机器修改配置文件)
① 拷贝多个redis.conf文件
② 开启daemonize yes
③ 修改pid文件名字
④ 修改端口
⑤ 修改log文件名字
⑥ 修改dump.rdb名字
2、配从(库)不配主(库)
3、从库配置:slaveof 主库IP 主库端口
常用3招
1、一主二仆
我们配置一台主机和两台从机((主机端口6379,两个从机端口分别为:6380,6381)),两台从机敲入相同的命令:slaveof 127.0.0.1 6379
原则:
① 从机不能做任何写操作
② 主机挂掉,两台从机原地待命,从机不能夺权,当主机恢复后,主从关系照旧(查看主从状态命令:info replication)
③ 从机挂掉,从机再恢复,就没办法连接了,需要重新执行slaveof
2、薪火相传
还是3台机器,6380的设置命令slaveof 127.0.0.1 6379,6381设置命令slaveof 127.0.0.1 6380。
关系就是6379->6380->6381
3、反客为主
还是3台机器,假如现在6379现在挂了,我现在在6380机器使用命令 slaveof no one,6381的机器使用命令slaveof 127.0.0.1 6380
现在6380成为主,6381成为从。这时候6379回来了,对不起,没你事了。
复制原理:
1、slave启动成功连接到master后会发送一个sync命令
2、Master接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,master将传送整个数据文件到slave,以完成一次完全同步
3、全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
4、增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步
5、但是只要是重新连接master,一次完全同步(全量复制)将被自动执行
哨兵模式:
现在互联网的配置主从一般都是采用的哨兵模式。
哨兵模式:反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库
设置步骤:
1、调整结构,6379带着80、81,一主两仆
2、自定义的/myredis目录下新建sentinel.conf文件,名字绝不能错
3、配置哨兵,填写内容
① 填写内容: sentinel monitor 被监控数据库名字(自己起名字) 127.0.0.1 6379 1
② 备注:上面最后一个数字1,表示主机挂掉后salve投票看让谁接替成为主机,得票数多少后成为主机
4、启动哨兵,redis-sentinel /myredis/sentinel.conf
这样哨兵模式就启动了,一旦发现master挂了,就会立即进行投票选举找一个新的master。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号