hbase rowkey设计,以三个事例讲解
提到hbase一般无法避开rowkey的设计。Rowkey设计的优劣直接影响读写性能。
下面小咔以三个实例来讲解
一。事例一 权限控制人员角色表
权限分配时,普遍关系型数据库,一般会设计三张表,一张用户表记录用户信息;一张角色表记录角色信息;还有张用户角色表,建立用户与角色的对应关系。
那么hbase如何设计表结构
要实现以下功能:
人员有多个角色 角色优先级
角色有多个人员
人员 删除添加角色
角色 可以添加删除人员
人员 角色 删除添加
数据举例:
小明 拥有 劳动委员>体育委员
小红 拥有 学习委员>劳动委员>体育委员
解决思路:
设计2张表,一个记录个人信息,一个记录角色信息,他们之前的关系通过列族2进行记录
psn cf1(个人信息) cf2(拥有的角色)
rowkey(pid) cf1:name=…;cf2:age=… cf2:100/200/300=…
001 cf1:name=小明;cf2:age=… cf2:200=10;cf2: 100=9
002 cf1:name=小红;cf2:age=… cf2:300=10;cf2: 200=9;cf2: 100=8
role
cf1(角色信息) cf2(拥有的人员)
rowkey(rid) cf1:name=… cf2:001/002/003=…
100 cf1:name=体育委员 cf2:001=小明;cf:002=小红
200 cf1:name=劳动委员 cf2:001=小明;cf:002=小红
300 cf1:name=学习委员 cf:002=小红
二。事例二 组织架构设计
公司都有组织架构
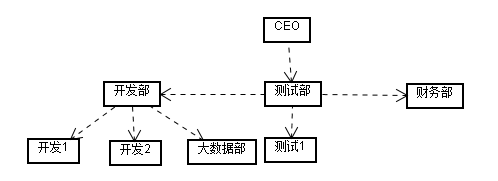
如上图ceo下面有开发部,测试部,财务部三个部门;开发部下又有3个部门。
hbase设计表,实现以下需求
查询 顶级部门
查询 每个部门的所有子部门
部门 添加,删除子部门
部门 添加删除
数据举例:
上图
解决思路:
一张表,一个列族记录部门信息,一个列族记录子部门信息
Dep
rowkey cf1(部门信息) cf2(子部门)
did cf1:name=…; cf2:002=..;cf2:003=…
001 cf1:name=CEO;cf1:up=0 cf2:002=开发部;cf2:003=测试;cf2:004=财务部
002 cf1:name=开发部;cf1:up=1 cf2:005=开发1;cf2:006=开发2;cf2:007=大数据部
005 cf1:name=开发1;cf1:up=1
006 cf1:name=开发2;cf1:up=1
007 cf1:name=大数据部;cf1:up=1
003 cf1:name=测试部;cf1:up=1 cf2:008=测试1
008 cf1:name=测试1 ;cf1:up=1
004 cf1:name=财务部;cf1:up=1
三。事例三 微博关注设计
微博大家都使用过,大多数人都关注的自己心中的他、她。如下需求:
添加、查看关注
粉丝列表
写微博
查看首页,所有关注过的好友发布的最新微博
查看某个用户发布的所有微博
数据举例:
小明001 关注小红,小绿
小红002
小黑003 关系小红
小绿 004
解决思路:
粉丝表,记录关注人与粉丝人。 列族1记录关注列表,列族2记录粉丝列表
微博表,记录所发的微博
微博收取表,按时间顺序记录发帖微博,用于查看最新微博
粉丝表
rowkey cf1(关注列表) cf2(粉丝列表)
pid cf1:001=… cf2:001=…
001 cf1:002=小红;cf1:004=小绿
002 cf2:001=小明;cf2:003=小黑
003 cf1:002=小红
004
微博表
rowkey cf1
wid(pid_max-timestamp)
002_123456 cf1:name=大数据
002_745634 cf1:name=大数据
微博收取表
rowkey cf1
pid wid
002 002_745634
001 002_123456
hbase设计的表有个缺点,大量的数据冗余。优点是单表查询数据快。rowkey设计合理查询速度就快,设计不合理还不如关系型数据库

 浙公网安备 33010602011771号
浙公网安备 33010602011771号