MySQL: 3、SQL语言 ②约束、事务
一、SQL 约束
1、约束的作用:
对表中的数据进行进一步的限制,从而保证数据的正确性、有效性、完整性。违反约束的不正确数据将无法插入到表中
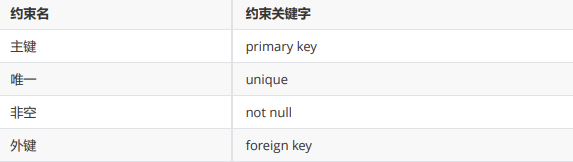
2、常见的约束:
3、主键约束:
-- 特点: 不可重复、唯一、非空
-- 作用: 用来表示数据库中的每一条记录
-- 语法格式:
添加主键: ALTER TABLE 表名 add PRIMARY KEY (主键字段)
删除主键: ALTER TABLE 表名 DROP PRIMARY KEY;
-- 案例:
方式1:直接再创建表的时候指定某个字段为主键
CREATE TABLE emp(
eid INT PRIMARY KEY, -- 指定主键
ename varchar(20)
)ENGINE = INNODB DEFAULT CHARSET = utf8;
方式2:在定义完字段之后指定主键
CREATE TABLE emp(
eid INT ,
ename varchar(20),
PRIMARY KEY(eid) -- 指定主键
)ENGINE = INNODB DEFAULT CHARSET = utf8;
方式3: 创建完表之后 再添加主键
CREATE TABLE emp(
eid INT ,
ename varchar(20)
)ENGINE = INNODB DEFAULT CHARSET = utf8;
-- 通过 DDL语句 添加主键约束
ALTER TABLE emp add PRIMARY KEY (eid);
-- 主键自增:
作用:如果主键都由我们自己添加可能出现重复,所以我们通常希望每次插入
新记录时,数据库自动生成主键的值
关键字:AUTO_INCREMENT 该关键字表示自动增长,字段类型必须是整数类型
修改主键自增的起始值:AUTO_INCREMENT 默认是从1开始自增的,如果希望修改起始值可以通过一下方式:
方式1:
CREATE TABLE emp(
eid INT PRIMARY KEY
)AUTO_INCREMENT = 100 ENGINE = INNODB DEFAULT CHARSET = utf8;
方式2:
ALTER TABLE 表名 AUTO_INCREMENT = 100;
ps: 这里需要注意的是,如果一开始你设置了主键自增的值,如果在采用方式2的话,
方式2设置的主键自增的值必须比之前的大,否着无效
4、非空约束
-- 特点:某一列不允许为空
-- 语法格式: 字段名称 字段类型 NOT NULL
-- 案例:
CREATE TABLE emp(
eid INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20) NOT NULL -- 非空约束
)ENGINE = INNODB DEFAULT CHARSET=utf8;
5、唯一约束
-- 特点:表中的某一列的值不能重复(对null不做唯一判断)
-- 语法格式:字段名 字段值 UNIQUE
-- 案例:
CREATE TABLE emp(
eid INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20) UNIQUE -- 唯一约束
)ENGINE=innodb DEFAULT CHARSET=utf8;
-- 主键约束和唯一约束的区别:
1、主键约束唯一且不能为空,唯一约束唯一但可以为空
2、一个表中只能有一个字段是主键约束,但是可以有多个字段是唯一约束
6、外键约束
-- 特点:
-- 语法格式:
7、默认值
-- 概述:用来指定某个字段的默认值
-- 语法格式: 字段名 字段类型 DEFAULT 默认值
-- 案例:
CREATE TABLE emp(
eid INT PRIMARY KEY AUTO_INCREMENT,
ename VARCHAR(20),
sex char(1) DEFAULT '女' -- 为性别设置默认值
)ENGINE=INNODB DEFAULT CHARSET=utf8;
二、数据库事务
1、什么是事务
事务是一个整体,由一条或者多条sql语句组成,这些sql语句要么都执行成功,要么都执行失败,只要有一条
sql出现异常,整个操作都会回滚,整个业务都执行失败。
回滚:即在事务运行过程中发生了某种故障,事务不能继续执行,系统将事务中对数据库的操作全部撤销,
回滚到事务开始的状态。
1.2、案例: 模拟转账操作
1)创建账户表
CREATE TABLE account(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(10),
money DOUBLE
)ENGINE = INNODB DEFAULT CHARSET = utf8;
INSERT INTO account(name,money) VALUES('tom',1000),('jack',1000); -- 添加两个账户
2)模拟tom 转账给 jack 500元钱,这样一个转账业务操作最少要执行下面两条语句:
UPDATE account SET money = money - 500 WHERE name = 'tom'; -- tom账户-500
UPDATE account SET money = money + 500 HWERE name = 'jack'; -- jack账户+500
3) 问题就出现了,假设当tom转账后-500,服务器崩溃了,这是jack的账号上并没有+500,
数据就出现了问题,我们要保证整个事务执行的完整性,要么都成功,要么失败
2、MySQL事务操作
- MySQL中可以有两种方式进行事务的操作: 手动提交事务、自动提交事务
- 手动提交:
开启事务 start transaction; 或者 BEGIN;
提交事务 commit;
回滚事务 rollback;
start transaction: 这个语句显示地标记一个事务的起始点
commit: 表示提交事务,即提交事务的所有操作,具体地说,就是将事务中所有对数据地更新都写到磁
盘上地物理数据库中, 事务正常结束。
rollback: 表示撤销事务,即在事务运行地过程中发生了某种故障,事务不能继续执行,系统将事务中对
数据库地所有已完成的操作全部撤销,回滚到事务开始的状态
- 自动提交:
MySQL默认每一条DML(增删改)语句都是一个单独的事务,每条语句都会自动开启一个事务,语句执行
完毕自动提交事务,MySQL默认是自动提交事务
- 查看autocommit 自动提交状态:
SHOW VARIABLES LIKE 'autocommit';
on: 自动提交 off:手动提交
- 修改autocommit 自动提交状态:
SET @@autocommit = off;
3、事务的四大特点 ACID
原子性:每个事务都是一个整体,不可再拆分,事务中所有的SQL语句要么都执行成功,要么都失败
一致性:事务在执行前数据库的状态与执行后数据库的状态保持一致,如:转账前2个人的总金额在2000,
转账后2个人总金额也是2000
隔离性:事务与事务之间不应该相互影响,执行时保持隔离的状态
持久性:一旦事务执成功,对数据库的修改是持久的,就算关机,数据也要保存下来的
4、并发访问会产生的问题
1.数据并发访问
一个数据库有可能拥有多个访问客户端,这些客户端都可以并发方式访问数据库,数据库的相同数据可能被
多个事务同时访问,如果不采取隔离措施,就会导致各种问题,破坏数据的完整性。
2.并发访问会产生的问题
事务在操作的理想状态:所有的事务之间保持隔离,互不影响,因为并发操作,多个用户同时访问同一个数据,
可能引发并发访问的问题
并发访问的问题:脏读、不可重复读、幻读
脏读:是指一个事务读取到另一个事务中尚未提交的数据
不可重复读:不可重复读是指在一个事务内根据同一个条件对行记录进行多次查询,但是查询出来的结果却不一致
例如事务a读取一个数据2次, 此时事务b也访问该数据,并且在事务a两次读取数据之间进行了修改
导致事务a在多次读取到的数据不一样。这种就叫做不可重复读
幻读:幻读是指同一个事务内多次查询返回的结果集不一样,例如事务a对表中的数据进行修改,这种修改涉及到表
中的全部数据。同时,第二个事务也修改了这个表中的数据,这种修改是向表中插入一行新的数据,那么,
操作第一个事务的用户就会发现表中还有没有修改的数据行,就好像发生了幻觉一样,这就叫做幻读
不可重复读和幻读的区别:
不可重复读的重点是修改,同样的条件,你读取过的数据,再次读取出来发现值不一样
幻读的重点在于新增或者删除,同样的条件,第一次喝第二次读取出来的记录数不一样
举例加深:
脏读:
1.Mary的原工资为1000, 财务人员将Mary的工资改为了8000(但未提交事务)
2.Mary读取自己的工资 ,发现自己的工资变为了8000,欢天喜地!
3.而财务发现操作有误,回滚了事务,Mary的工资又变为了1000像这样,Mary记取
的工资数8000是一个脏数据。
不可重复读:
1.在事务1中,Mary 读取了自己的工资为1000,操作并没有完成
2.在事务2中,这时财务人员修改了Mary的工资为2000,并提交了事务.
3.在事务1中,Mary 再次读取自己的工资时,工资变为了2000
幻读:
目前工资为1000的员工有10人。
1.事务1,读取所有工资为1000的员工。
2.这时事务2向employee表插入了一条员工记录,工资也为1000
3.事务1再次读取所有工资为1000的员工 共读取到了11条记录
5、数据库事务的隔离级别
- 通过设置隔离级别,可以防止以上三种并发问题。 ✔会出现问题 ✘不会出现问题
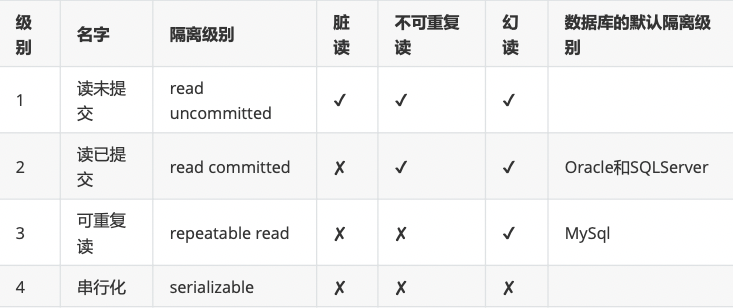
- 查看隔离级别 : select @@tx_isolation;
mysql的默认隔离级别是repeatable read 可重复读,可以防止脏读与不可重复读。
设置事务隔离级别后需要退出MySQL重新登录才能看到隔离级别的变化
- 设置事务隔离级别:
set [session | global] transaction isolation level 事务隔离级别;
session:
全局事务隔离级别,该命令不会影响当前已连接的会话的事务隔离级别,对于以后的连接会话生效
global:
当前会话的事务隔离级别,该命令只对 当前 会话生效,不影响其他会话和全局的事务隔离级别配置
两个都不加:
下一次事务隔离级别,该命令只对 下一次 事务生效,不会影响会话本身设置的事务隔离级别
6、隔离性问题演示
前提数据:数据表使用上面转账案例的account表,有两用户tom,jack,金额都为1000
脏读:一个事务读取到另一个事务中尚未提交的数据
1. 打开窗口登录mysql,设置全局的隔离级别为最低
1)登录mysql,然后选择一个数据库 略。
2)设置隔离级别为最低:读未提交
set global transaction isolation level read uncommitted;
3) 关闭窗口,开启一个新的窗口a,再次查询隔离级别可以发现已经是修改后的 read uncommitted
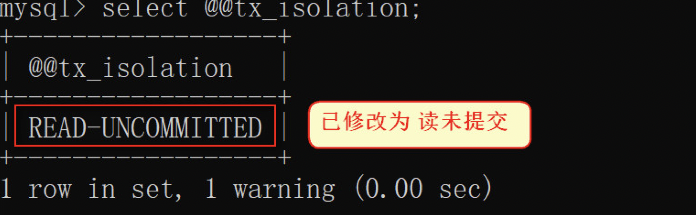
2. 再次开启一个新窗口 b,并登录数据库,选择对应的数据库。
1)开启事务:start transaction;
3. 窗口a也选择同样的数据库
1) 开启事务:start transaction;
2) 执行修改操作:
update account set money = money - 500 where name = 'tom'; -- tom 账户 -500元
update account set money = money + 500 where name = 'jack'; -- jack 账户 +500元
4. 窗口b查询数据
1)查询账户信息:select * from account;

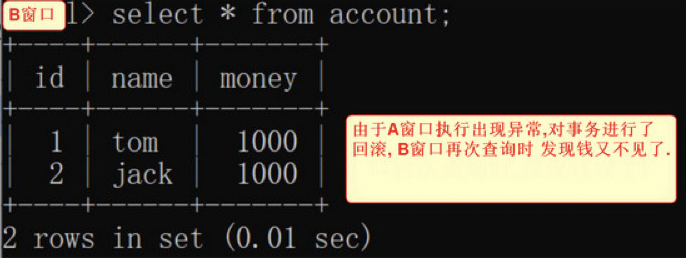
5. 窗口a 转账异常进行回滚操作:
1) rollback;
6. 窗口b再次查询账户
1)select * from account;
7.解决脏读:将全局的隔离级别提升为: read committed
1)在窗口a设置全局隔离级别为:read committed
set global transaction isolation level read committed;
2)重启窗口a ,查看是否设置成功: select @@tx_isolation;
3)关闭之前窗口b然后重新开启一个窗口b,a和b选择数据库后都开启事务

4) 窗口a 只是更新两个人的账户,但不提交事务
update account set money = money - 500 where name = 'tom'; -- tom 账户 -500元
update account set money = money + 500 where name = 'jack'; -- jack 账户 +500元
5)窗口b进行查询,没有查询到未提交的数据:select * from account;

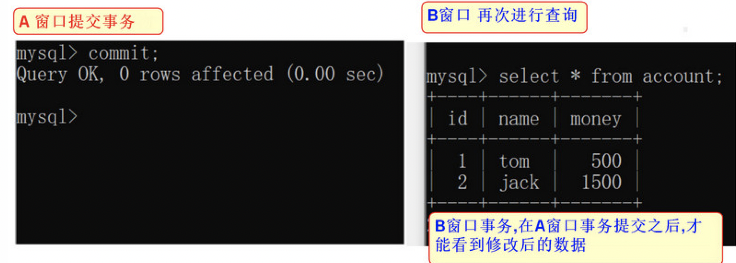
6)窗口acommit提交数据: commit;
7)窗口b查看数据:select * from account;
-----------------------------------------------------------------------------------------------------
不可重复读:同一个事务中进行查询操作,但每次读取的数据内容是不一的
1、恢复数据,将tom 、jack的金额恢复至1000
2、打开两个窗口 a、b ,选择数据库之后开启事务
3、窗口b开启事务,先查询一下数据
1) select * from account;
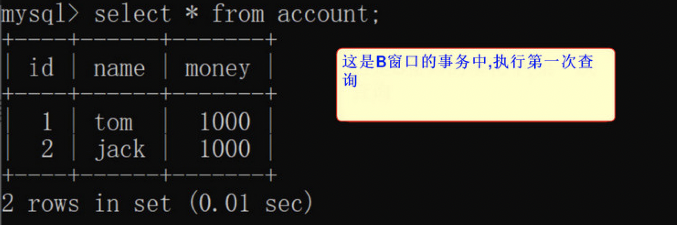
4、切换到a窗口,将用户tom的账户+500,然后提交事务
1)update account set money = money + 500 where name = 'tom;
2) commit;
5、窗口b再次查询数据:select * from account;

6、两次查询到的结果不同,到底哪次是对的?很多人认为 当然是后面为准,的确,但是我们可以考虑
这样一种情况:
比如银行程序需要将查询结果分别输出到电脑屏幕和发短信给客户,结果在一个事务中针对不同的输出
目的地进行的两次查询不一致,导致短信和屏幕中的结果不一致,银行工作人员就不知道以哪个为准了
7、解决不可重复读的问题:
将全局隔离级别提升为:repeatable read
8、恢复数据: update account set money = 1000;
9、打开窗口a,设置隔离级别为: repeatable read
1) set global transaction isolation level repeatable read;
10、重新开启 ab窗口,选择数据库并同时开启事务
11、窗口b 先进行第一次查询:select * from account;
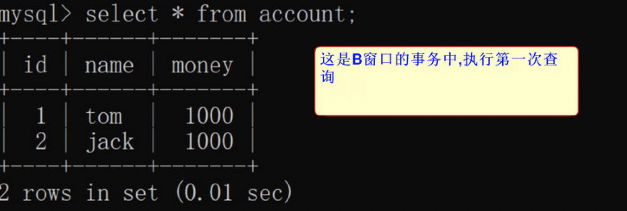
12、窗口a更新数据,然后提交事务
1)update account set money = money + 500 where name = 'tom';
2) commit;
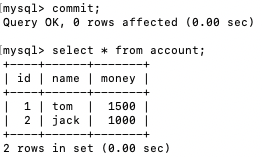
13、窗口b再次查询:select * from account;

- 同一个事务中为了保证多次查询数据一致,必须使用 repeatable read 隔离级别及以上的
14、只有当窗口b提交事务commit之后,再次查询才能查到更新后的数据
-----------------------------------------------------------------------------------------------------
幻读:幻读是指同一个事务内多次查询返回的结果集不一样
1、打开 ab窗口 选择数据库 开启事务

2、 窗口a 先执行一次查询操作
1)假设要再添加一条id为3的数据,再添加之前先判断是否存在
select * from account where id = 3;

3、窗口b插入一条数据 并提交事务
1)insert into account values(2,'lucy',1000);
2) commit;
4、窗口a 执行插入操作发现报错,出现幻读,见鬼,窗口a刚才读取到的结果明明可以支持我
进行这样的操作呀,为什么现在不可以?

5、幻读问题解决: 将事务隔离级别设置为最高的 serializable
ps: 如果一个事务使用了 serializable 可串行化隔离级别时,在这个事务没有被提交之前,其他的线程,
只能等到当前操作完了之后才能进行操作,这样会非常耗时,而且影响数据库性能,数据库一般
不推荐使用这种隔离级别
1) 恢复数据:delete from account where id = 3;
2) 打开窗口a将数据隔离级别提升至最高:serializable

3)关闭ab窗口后再重新打开ab窗口,选择数据库并开启事务
4)窗口a先执行一次查询操作: select * from account where id = 3;
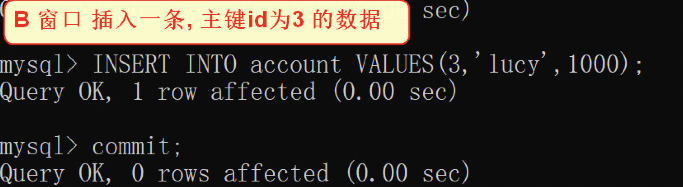
5)窗口b插入一条数据:isnert into account values(3,'lucy',1000);

6) 窗口a执行插入操作,提交事务,数据插入成功
1) insert into account values(3,'lucy',1000);
2) commit;
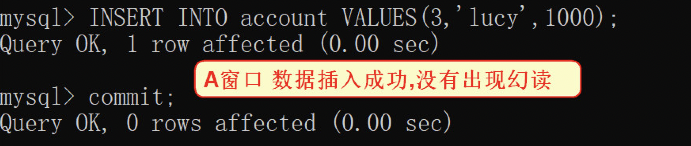
7) 窗口b在窗口a提交事务之后,再执行,但是会发现主键冲突从而出现错误

8) 总结:serializable串行化可以彻底解决幻读,但是事务只能排队执行,严重影响效率,
数据库一般不会使用这种隔离级别

 浙公网安备 33010602011771号
浙公网安备 33010602011771号