

卷积神经网络-AlexNet
AlexNet
一些前置知识
top-1 和top-5错误率
top-1错误率指的是在最后的n哥预测结果中,只有预测概率最大对应的类别是正确答案才算预测正确。
top-5错误率指的是在最后的n个预测结果中,只要预测概率最大的前五个中含有正确答案就算预测正确。
max-pooling层
最大池化又叫做subsampling,其主要作用是减少图像的高度和长度而深度(宽度)则不会改变。下面是一个列子:

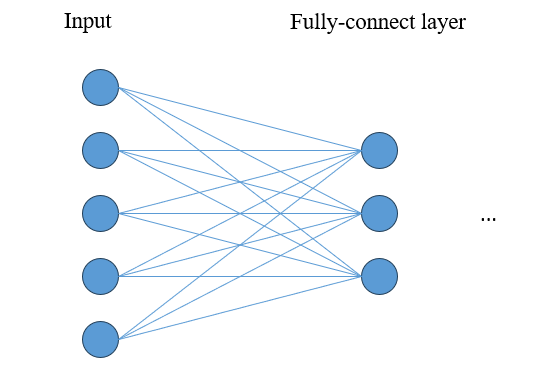
fully-connect层
在全连接层中,其每个神经元都与前一层的所有神经元相连接,每个连接都有一个权重用于调节信息传递的强度,并且每个神经元还有一个偏置项。
1000-way softmax
它其实也属于全连接层,这个层原本包含1000个未归一化的输出,而softmax将这个向量转换为概率分布。计算方式如下:
non-saturating neurons
非饱和神经元是深度学习中一种设计神经元的理念,目的是避免神经元在训练过程中出现饱和现象。饱和现象会导致梯度消失,进而使得模型难以训练。下面是一些常见的非饱和激活函数:
- ReLU
- Leaky ReLU
- ELU
- SELU
dropout
在训练时以一定的概率将输入置0,输出时接受所有神经元的输出,但要乘以概率(1-p)。使得模型在每次前向和反向传播时都使用不同的子网络进行训练,从而提高模型的泛化能力。这种方法有效地减少了神经元之间的共适应性(co-adaptation),迫使网络的每个神经元在更具鲁棒性的特征上进行学习。
缺点:收敛速度可能变慢。
网络结构
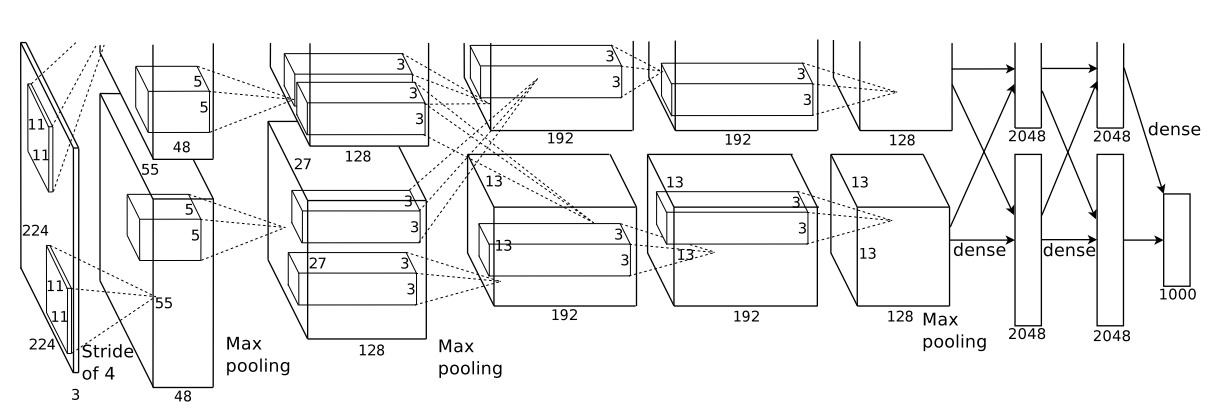
由于这篇文章在提出时没有很好的GPU,估计显存不够?所有采用了双GPU训练的方法。具体来说上下两块GPU分别负责一般的参数,但是这其中也有信息的融合,比如第3、6,7层。其次这里输出的图像维度应该有误,应更正为2252253
算法实现
import torch.nn as nn
import torch
class AlexNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步