【Java IO流】对象的序列化和反序列化
对象的序列化和反序列化
1)对象序列化,就是将Object对象转换成byte序列,反之叫对象的反序列化。
2)序列化流(ObjectOutputStream),是字节的过滤流—— writeObject()方法
反序列化流(ObjectInputStream)—— readObject()方法
3)序列化接口(Serializable)
对象必须实现序列化接口,才能进行序列化,否则将出现异常。
注:这个接口,没有任何方法,只是一个【标准】
一、最基本的序列化和反序列过程
序列化和反序列都是以Object对象进行操作的,这里通过一个简单的案例来给大家演示一下对象序列化和反序列化的过程。
1)新建一个Student类(测试类)
注意:需要实现序列化接口的类才能进行序列化操作!!


1 @SuppressWarnings("serial") 2 public class Student implements Serializable{ 3 private String stuno;//id 4 private String stuna;//姓名 5 private int stuage;//年龄 6 public String getStuno() { 7 return stuno; 8 } 9 public void setStuno(String stuno) { 10 this.stuno = stuno; 11 } 12 public String getStuna() { 13 return stuna; 14 } 15 public void setStuna(String stuna) { 16 this.stuna = stuna; 17 } 18 public Student() { 19 super(); 20 // TODO Auto-generated constructor stub 21 } 22 public Student(String stuno, String stuna, int stuage) { 23 super(); 24 this.stuno = stuno; 25 this.stuna = stuna; 26 this.stuage = stuage; 27 } 28 @Override 29 public String toString() { 30 return "Student [stuno=" + stuno + ", stuna=" + stuna + ", stuage=" + stuage + "]"; 31 } 32 public int getStuage() { 33 return stuage; 34 } 35 public void setStuage(int stuage) { 36 this.stuage = stuage; 37 } 38 }
2)将Student类的实例序列化成文件
基本操作步骤如下:
- 指定序列化保存的文件
- 构造ObjectOutputStream类
- 构造一个Student类
- 使用writeObject方法序列化
- 使用close()方法关闭流
1 String file="demo/obj.dat"; 2 //对象的序列化 3 ObjectOutputStream oos=new ObjectOutputStream( 4 new FileOutputStream(file)); 5 //把Student对象保存起来,就是对象的序列化 6 Student stu=new Student("01","mike",18); 7 //使用writeObject方法序列化 8 oos.writeObject(stu); 9 oos.close();
运行结果:可以看到demo目录下生成了obj.dat的序列化文件
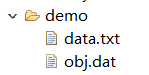
3)将文件反序列化读出Student类对象
基本操作步骤如下:
- 指定反序列化的文件
- 构造ObjectInputStream类
- 使用readObject方法反序列化
- 使用close方法关闭流
1 String file="demo/obj.dat"; 2 ObjectInputStream ois =new ObjectInputStream( 3 new FileInputStream(file)); 4 //使用readObject()方法序列化 5 Student stu=(Student)ois.readObject();//强制类型转换 6 System.out.println(stu); 7 ois.close();
运行结果:

注意:在文件反序列化时,readObject方法取出的对象默认都是Object类型,必须强制转换为相应的类型。
二、transient及ArrayList源码分析
在日常编程过程中,我们有时不希望一个类所有的元素都被编译器序列化,这时该怎么办呢?
Java提供了一个transient关键字来修饰我们不希望被jvm自动序列化的元素。下面简单来讲解一下这个关键字。
transient 关键字:被transient修饰的元素,该元素不会进行jvm默认的序列化,但可以自己完成这个元素的序列化。
注意:
1)在以后的网络编程中,如果有某些元素不需要传输,那就可以用transient修饰,来节省流量;对有效元素序列化,提高性能。
2)可以使用writeObject自己完成这个元素的序列化。
ArrayList就是用了此方法进行了优化操作。ArrayList最核心的容器Object[] elementData使用了transient修饰,但是在writeObject自己实现对elementData数组的序列化。只对数组中有效元素进行序列化。readObject与之类似。

--------------自己序列化的方式---------------
在要序列化的类中加入两个方法(这两个方法都是从ArrayList源码中提取出来的,比较特殊的两个方法):
1 private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException{ 2 s.defaultWriteObject();//把jvm能默认序列化的元素进行序列化操作 3 s.writeInt(stuage);//自己完成被transient修饰的元素的序列化 4 } 5 private void readObject(java.io.ObjectInputStream s) throws java.io.IOException,ClassNotFoundException{ 6 s.defaultReadObject();//把jvm能默认反序列化的元素进行反序列化操作 7 this.stuage=s.readInt();//自己完成stuage的反序列化操作 8 }
加入这两个方法后,即使被transient修饰的元素也能像刚刚那样进行序列化和反序列化了,jvm会自动使用这两个方法帮助我们完成这动作。
这里又有个问题,为什么还需要手动去完成序列化和反序列化呢,有什么意义呢?
这个问题得再从ArrayList的源码中去分析:


可以看出ArrayList源码中自己序列化的目的:ArrayList底层为数组,自己序列化可以过滤数组中无效的元素,只序列化数组中有效的元素,从而提高性能。
因此,实际编程过程中我们可以根据需要来自己完成序列化以提高性能。
三、序列化中子父类构造函数问题
在类的序列化和反序列化中,如果存在子类和父类的关系时,序列化和反序列化的过程又是怎么样的呢?
这里我写一个测试类来测试子类和父类实现序列化和反序列化时构造函数的实现变化。
1 public static void main(String[] args) throws IOException { 2 // TODO Auto-generated method stub 3 String file="demo/foo.dat"; 4 ObjectOutputStream oos=new ObjectOutputStream( 5 new FileOutputStream(file)); 6 Foo2 foo2 =new Foo2(); 7 oos.writeObject(foo2); 8 oos.flush(); 9 oos.close(); 10 } 11 12 } 13 class Foo implements Serializable{ 14 public Foo(){ 15 System.out.println("foo"); 16 } 17 } 18 class Foo1 extends Foo{ 19 public Foo1(){ 20 System.out.println("foo1"); 21 } 22 23 } 24 class Foo2 extends Foo1{ 25 public Foo2(){ 26 System.out.println("foo2"); 27 } 28 }
运行结果:这是序列化时递归调用了父类的构造函数
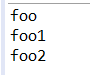
接来下看看反序列化时,是否递归调用父类的构造函数。
1 ObjectInputStream ois=new ObjectInputStream( 2 new FileInputStream(file)); 3 Foo2 foo2=(Foo2)ois.readObject(); 4 ois.close();
运行结果:控制台没有任何输出。
那么这个结果是否证明反序列化过程中父类的构造函数就是始终不调用的呢?
然而不能证明!!
因为再看下面这个不同的测试例子:
1 class Bar { 2 public Bar(){ 3 System.out.println("bar"); 4 } 5 } 6 class Bar1 extends Bar implements Serializable{ 7 public Bar1(){ 8 System.out.println("bar1"); 9 } 10 } 11 class Bar2 extends Bar1{ 12 public Bar2(){ 13 System.out.println("bar2"); 14 } 15 }
我们用这个例子来测试序列化和反序列化。
序列化结果:

反序列化结果:没实现序列化接口的父类被显示调用构造函数

【反序列化时】,向上递归调用构造函数会从【可序列化的一级父类结束】。即谁实现了可序列化(包括继承实现的),谁的构造函数就不会调用。
总结:
1)父类实现了serializable接口,子类继承就可序列化。
子类在反序列化时,父类实现了序列化接口,则不会递归调用其构造函数。
2)父类未实现serializable接口,子类自行实现可序列化
子类在反序列化时,父类没有实现序列化接口,则会递归调用其构造函数。
本文如果对大家的学习有帮助,请点击下方的“推荐”或者“收藏”!您的支持将是我最大的动力,谢谢✧⁺⸜(●˙▾˙●)⸝⁺✧再来一个不要脸的求“关注”
作者: 云开的立夏
出处: http://www.cnblogs.com/hysum/>
关于作者:本人目前还在上学,小白一枚,希望能把学过的知识与大家分享,请多多赐教!
版权声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出 原文链接
大家写文都不容易,请尊重劳动成果~这里谢谢大家啦(*/ω\*) 如有问题, 可邮件(hysum626@162.com)咨询.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号