【转载】写有效率的SQL查询(VI)
转载:本文转自cnblogs上Nineteen@newsmth的博客
我们先看NestedLoop和MergeJoin的算法(以下为引用,见RicCC的《通往性能优化的天堂-地狱 JOIN方法说明》):
==================================
NestedLoop:
foreach rowA in tableA where tableA.col2=?
{
search rowsB from tableB where tableB.col1=rowA.col1 and tableB.col2=? ;
if(rowsB.Count<=0)
discard rowA ;
else
output rowA and rowsB ;
}
MergeJoin:
两个表都按照关联字段排序好之后,merge join操作从每个表取一条记录开始匹配,如果符合关联条件,则放入结果集中;否则,将关联字段值较小的记录抛弃,从这条记录对应的表中取下一条记录继续进行匹配,直到整个循环结束。
==================================
我们通过最简单的情况来计算NestedLoop和MergeJoin的消耗:
两张表A、B,分别有m、n行数据(m < n),占用基础表物理存储空间分别为a、b页,聚集索引树非叶节点都是两层(一层根节点,一层中间级节点),A、B的聚集索引建在A.col1、B.col1上。一条查询语句:
select A.col1, B.col2 from A inner join B where A.col1 = B.col1。
执行NestedLoop操作:
A作为outer input,B作为inner input时:A带来的IO为a;每次通过clustered index seek执行内部循环,花费3(一个根节点、一个中间集结点、一个叶节点。当然也可能直接从根节点就拿到要的数据,我们只考虑最坏的情况),这样执行整个嵌套循环过程消耗IO为a + 3*m。如果B作为inner input,A作为outer input分析类似。
执行MergeJoin:
MergeJoin要把A、B两张表做个Scan,然后进行Merge操作。所以A、B分别带来IO为a + b就是总的逻辑IO开销。
从上述分析来看,若a + 3*m << a + b,即3*m << b,那么NestedLoop性能是极佳的。当然,我们比较A表的行和B表所占数据页大小看上去有点夸张,但是量化分析确实如此。在这里,我们没有计算NestedLoop和MergeJoin本身的cpu计算开销,特别是后者,这部分并不能完全忽略,但是也来得有限。
OK,现在我们试图执行实际的语句验证我们的观点,看看能发现什么。
我有两张表,一张表charge,聚集索引在charge_no上,它是个int identity(1,1),共10万行,数据页582张,聚集索引非叶节点2层。一张表A,聚集索引在col1上(唯一),共999行,数据页2张,聚集索引两层。min(A.col1) = min(charge.charge_no)、Max(A.col1) < max(charge.charge_no)。
我们在set statistics io on和set statistics time on之后,执行语句:
select A.col1, charge.member_no from A inner join charge
on A.col1 = charge.charge_no
option(loop join) -–执行NestedLoop
go
select A.col1, charge.member_no from A inner join charge
on A.col1 = charge.charge_no
option(merge join)--执行MergeJoin。
结果集都是999行,而且我们看到消息窗口中输出为:
(图1)
从上图中我们注意到几点比较和最初分析不同的地方:
- Nested Loop时,表A的逻辑读是4,而不是预计中的表A数据页大小2;charge逻辑读2096,而不是预计中的3×999。
- Merge Join时,表Charge的逻辑读只有8。
对1来说,表A的逻辑读是4是因为clustered index scan需要从聚集索引树根节点开始去找最开始的那张数据页,表A的聚集索引树深度为2,所以多了两个非页节点的IO。不是3×999是因为有些记录(设为n)直接从根节点就能找到,也就是说有些是2×n + (999-n)* 3
对2来说,MergeJoin时,表Charge并不是从头到尾扫描,而是从A表的最大最小值圈定的范围之内进行扫描,所以实际上它只读取了6张数据页。
OK ,为了验证对2的解释,我们在表A中插入一条col1 > max(charge.charge_no)的记录,然后执行:
select A.col1, charge.member_no from A inner join charge
on A.col1 = charge.charge_no
option(merge join)--执行MergeJoin。

(图2)
现在charge逻辑读成了582 + 2 = 584,验证了我们的想法。
那么如果min(A.col1) > min(charge.charge_no),max(A.col1) = max(charge.charge_no)时SQLServer会不会聪明到再次选择一个较小的扫描范围呢?很遗憾,不会-_-….不知道MS这里基于什么考虑。
========================================
我们现在回到图1,实际上我们从图1中还能发现SQL的分析编译占用时间相对执行占用时间不仅不能忽略,还占了很大比重,所以能避免编译、重编译,还是要尽可能的避免。
========================================
OK,现在我们开始分析分析执行计划,看看SQLServer如何在不同的执行计划之间做选择。
我们首先把A表truncate掉,然后里面就填充一条数据,update statistics A之后,看看执行计划: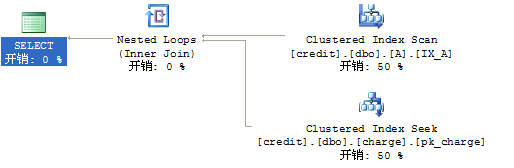
(图3:NestedLoop的执行计划)
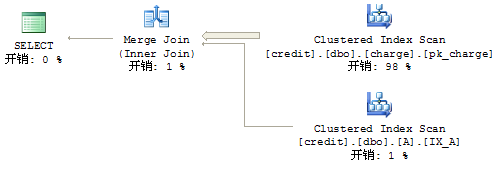
(图4:MergeJoin的执行计划)
我们把鼠标分别移到图3和图4中A表的Clustered Index Scan上,会看到完全一样的tip: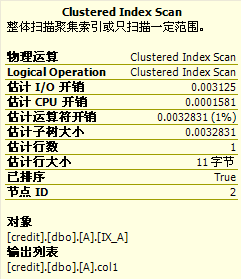
这个“I/O开销”就是两个逻辑IO的开销(就一条记录,自然是一个聚集索引根节点页,一个数据页,所以是2);估计行数为1,很准确,我们就1行记录。
现在我们把鼠标分别移动到图3、图4中charge表的Clustered Index Scan上,看到的则略有不同
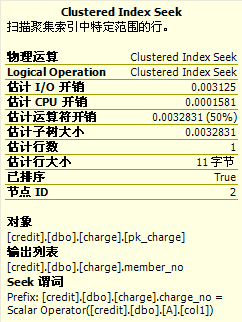
(图5:NestedLoop)
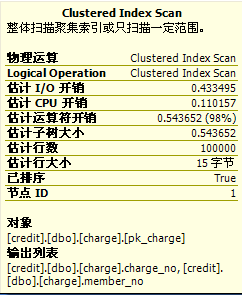
(图6:Merge Join)
Nested Loop中的开销评估看起来还算正常,运算符开销=(估计IO开销 + 估计CPU开销)×估计行数。(注意,NestedLoop中,大表是作为内存循环存在的,计算运算符开销别忘了乘上估计行数)。
但是Merge Join中我们发现“估计行数”很不正常,居然是总行数(相应的,估计IO开销和估计CPU开销自然都是全表扫描的开销,这个可以跟select * from charge的执行计划做个对比)。显然,执行计划中显示的和实际执行情况非常不同,实际情况按照我们上面的分析,应该就读取3张数据页,估计行数应该为1。误差是非常巨大的,3IO直接给估算成了584IO。翻了翻在pk_charge上的统计信息,采样行数10w,和总行数相同,再加上第二个结果集提供的信息,已经足够采取优化算法去评估查询计划。不知道MS为什么没有做。
好吧,我们假设执行计划的评估总是估算最坏的情况。由于Merge Join算法比较简单,后面我们只关注NestedLoop.
我们首先给A表增加一行(值为2),然后再来分析执行计划。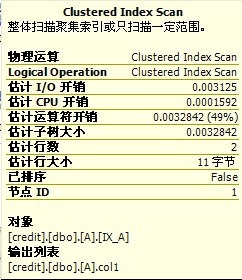
(图7:A表NestedLoop)

(图8:charge表NestedLoop)
我们从图7上可以看到,IO开销没有增加,CPU开销略微增加,这很容易理解,A表只增加了一行,其占用索引页和数据页和原来一样。但是由于行数略有增加,cpu消耗一定会略有增加。
奇怪的是图8显示的charge表上的seek.对比图5,运算符开销并没有像我们预料的那样增加一倍,而是增加了0.003412 – 0.003283 = 0.000129.这个数值远小于IO开销。为了多对比一次,这次我们再往A表里面插入一条记录(值为3),再来看看charge表上的运算:

(图9,charge表NestedLoop)
这次我们又发现,这次增加的消耗是0.0035993 – 0.003412 = 0.0001873,仍然远远小于一次的IO开销。
好吧,那么我们假设执行计划估算算法认为,如果某一页缓存被读到SQL Engine中之后就不会再被重复读取。为了验证它,我们试试把A表连续地增加到1000行,然后看看执行计划:
(图10,charge表NestedLoop)
我们假设每次进行clustered index seek消耗的cpu是相同的,那么我们可以计算出来查询计划认为的IO共有:(运算符开销 – cpu开销*1000)/ IO开销 = 5.81984。要知道charge表数据页总数为582,1000行恰好是100000的百分之一,1000行恰好占用了5.82页……(提醒一把,这1000行是连续值)
OMG…这次执行计划算法明显的比实际算法聪明。看上去像是,NestedLoop在每次Loop时都会缓存本次Loop中读取的数据页,这样当下次Loop时,如果目标数据页已经读取过,就不再读取,而直接从Engine内存中取。
=========================================================
从上面的讨论可以看出,有时候执行计划挺聪明,有时候实际的执行又很聪明,总之,咱是不知道为啥微软不让执行计划和实际的执行一样聪明,或者一样愚蠢。这样,至少SQL引擎在评估查询计划的时候可以比较准确。
btw:接着图10的例子,各位安达还可以自己去试试insert 一条大于max(charge.charge_no)的记录到表A里,然后试试看看charge表运算符上有什么变化。
==================================================
回到最初的主题,根据我们看到的SQL引擎实际执行看,只有A表行集远远小于charge_no的时候,SQLServer为我们选择的NestedLoop才是非常高效的;为了保证更小的IO,当(B表索引树深度*A表行数>B表数据页+B表索引树深度)的时候,就可以考虑是否要指定MergeJoin。
值得一提的是,经过多次的实验,SQL这样评估MergeJoin和NestedLoop,最后选择它认为更优的查询计划,居然多数情况下都是正确的……我是晕了,不知道你晕了没有。
==================
刚才(22:00)本子待机了一次,然后再开机的时候我没办法重现SQLServer自己选择NestedLoop总是比MergeJoin的cpu占用时间短了。现在的情况是:SQLServer每次都错误的选择了NestedLoop,导致的结果是IO相差20 ~ 30倍,执行时间多了百分之50。
============================
俺也不知道有多少人读到了这里,呵呵。
So盼望有人可以解释以上这些东西。
博主按:
有内涵回复摘录:
其实用这么简单的语句来考验optimizer不是太合适。Optimizer的规则其实相对来说是挺简单的,因为编译的时间不能太久,尤其是复杂的语句的时候,常常只能找到一个次优解。要SQL得到一个最优解不太现实。
缓存页的问题,Storage Engine一定是先去内存里找那个PAGE,找不到才去读硬盘。
像join column上有clustered index,且只有两个表join的这种完美条件出现的概率太小了。说完美是因为这样会留下太多可优化的空间,总有optimizer想不到的。
博主按:
有内涵回复摘录:
执行计划是排除了缓存的, 就是为了我们优化时不被缓存所迷惑
从分析结果上看,对NestedLoop,SQL用于评估执行计划的算法非常优秀,它尽可能的不去做IO。但是实际执行并不是这样,它该IO还是IO。
这并不另人迷惑,因为事实就是那样。稍微有点猥琐的是MS为什么不用评估执行计划的算法去执行实际操作。
博主按:
有内涵回复摘录:
1.
--引用:
...聚集索引树非叶节点都是两层(一层根节点,一层中间级节点)...
--引用结束
SQL Server中的索引是按B树结构组织的,B树分为三个级别:根、中间级、叶
级。但是B树的深度并非就是3。简单的说,当你建一个聚集表,表的数据很小的
时候,这个表可能只有一个数据页(你可以认为它就是一个根页),随着数据增
加,SQL Server 对B树维护进行拆分这时候B树的深度为2:只有根页和叶级页
而没有中间级的情况。当数据量再次增长一个根页无法完成查询的需要的时候
(即无法包含所有叶级数据的信息时候),中间级出现了,这时B数的深度是3,
此时中间级只有一层。那么当数据再次增长时,一层中间级无法满足需要的
时候中间级又会被拆分成两层,此时B数的深度为4
一般的情况,索引的深度基本是2或者3 ,大于3的比较少基本上是非常非常大的
表。
2.
--引用:
...每次通过clustered index seek执行内部循环,花费3(一个根节点、一个中
间集结点、一个叶节点。当然也可能直接从根节点就拿到要的数据,我们只考虑
最坏的情况)...
--引用结束
SQL Server 在执行index seek操作(注意这里讲的是搜索一个特定值,SQL语
句就是 字段=某个值,要区别于非等同比较 例如:字段 > 某个值)的时候是始
终从根页开始搜索,然后跳转到下一层直到最终的叶层。所以对于每个要查找的
数据值(位于叶级)到根节点的距离是相等的即B树的深度。
"直接从根节点就拿到要的数据" 这个说法是不正确的。我想不出只从根节点就能
完成seek操作的情景。要知道除了叶级页(即根页和所有中间级)都是不包含完
整的数据的索引行,只有索引的key值的信息在其中。
3.
-------引用:
执行MergeJoin:
MergeJoin要把A、B两张表做个Scan,然后进行Merge操作。所以A、B分别带
来IO为a + b就是总的逻辑IO开销。
从上述分析来看,若a + 3*m << a + b,即3*m << b.....
--引用结束
这样的描述是不严谨的,别人会这样理解:Scan和merge join是两个执行有先
后次序的操作实际上它们是交替(alternate)执行的。而且单纯a + b这样的公式
来表示mj的io开销个人觉得也是不妥的。情况并非那么简单用个公式来表达的。
单纯的从io数来推断性能的好坏是不客观的。还要考虑这些io的访问模式
例如:1000个有序io 要比500个随机io 更有效率
4.
-------引用:
对1来说,表A的逻辑读是4是因为clustered index scan需要从聚集索引树根节
点开始去找最开始的那张数据页,表A的聚集索引树深度为2,
所以多了两个非页节点的IO。不是3×999是因为有些记录(设为n)直接从根节
点就能找到,也就是说有些是2×n + (999-n)* 3
--引用结束
a)
不太清楚表A的实际的结构,姑且认为是这样建立的吧:
create table A(col1 int not null)
create unique clustered index IX_A on A(col1)
这样的表插入999条记录,可以测试一下聚集索引的深度为2
即根页和叶级(没有中间级),一共有3页(一张根页,两张数据页)
b)
index scan操作并不一定是从根页开始的,而且通常情况下是通过IAM页来定位
叶级的第一张数据页的,这样做更有效率。
个人觉得只要明白原理就OK了,并不一定要精确的分析这些逻辑读到底是如何
得来的,没有这个必要,只要大差不差就可以了。你会发现在一些时候
statistics io的输出并不是很精确的,往往会高于实际发生的值这和SQL Server的内部处理和索引的物理分布(索引碎片)都有关系的,真正的
细节我们是无从知晓的。
c)根据上述第2点的分析,这里的3×999的分析是没有依据。
这里我有点的怀疑,charge表上的clustered index的B数深度楼主确认一下到
底是2还是3,我估计应该是2因为2*999=1998 这个和2069很接近。
5.
-------引用:
那么如果min(A.col1) > min(charge.charge_no),max(A.col1) = max
(charge.charge_no)时SQLServer会不会聪明到再次选择一个较小的扫描范围
呢?很遗憾,不会-_-….不知道MS这里基于什么考虑。
--引用结束
a)
min(A.col1) = min(charge.charge_no)
max(A.col1) < max(charge.charge_no)
这是文中示例的第一种情况,此时charge表需要扫描的页很少的,
因为当A.col1=999匹配charge.charge_no=999之后A表没有记录了
所以mj操作结束,charge剩下的charge_no都是>999的记录。
b)
min(A.col1) = min(charge.charge_no)
max(A.col1) > max(charge.charge_no)
假设:max(A.col1)=10000 max(charge.charge_no) =2000
这是文中示例的第二种情况
因为当A.col1=999匹配charge.charge_no=999之后A表扫描到下一条记录
(10000)charge表扫描到下一条值为1000的记录,mj匹配失败,丢弃小值继续
扫描charge表因为max(charge.charge_no)<10000,所以charge表将被全部
扫描完(即584个逻辑读)
c)
min(A.col1) > min(charge.charge_no)
max(A.col1) = max(charge.charge_no)
为什么不会,这是由mj的算法决定的。
参与mj操作的两个输入流,始终(必须)是从小到大的次序来扫描的。
(否则这个丢弃较小值的算法就不成立了)理解这点很重要。
所以SQL server并不会从min(A.col1)这个值开始扫描charge表
而必须是从min(charge.charge_no)开始扫描(即从头扫描)。
6.
-------引用:
Nested Loop中的开销评估看起来还算正常,......
但是Merge Join中我们发现“估计行数”很不正常,居然是总行数....不知道MS为什么没有做
--引用结束
要注意charge表在两种连接中的操作方式是不同的:
NL 中charge表是seek操作,对于一个unique index 一个seek操作的“估计行
数”自然是1。mj 中charge表是scan操作,而且是个没有任何谓词的scan操
作,“估计行数”的自然是表的总记录数
不是不做,而是没有必要做。把scan操作“估计行数”估算的再精确,对于查询
实际的执行是没有任何影响(不会因为估算的准确,实际的执行就会变快),也是没有意义的。因为它并不能改变使用scan这样的处理方式而用其他的什么操作,
反而会增加查询编译的消耗。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号