

Trie树
2018-09-06 16:19:17
Trie树,也被称为单词查找树,是一种树形结构。典型应用是用于统计和排序大量的字符串(但不限于字符串),所以经常被搜索引擎用于文本的词频统计。它的优点是可以最大限度的减少无谓字符的比较,查询效率比较高。
Trie的核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
它有3个基本性质:
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符。
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
- 每个节点的所有子节点包含的字符都不相同。
问题描述:
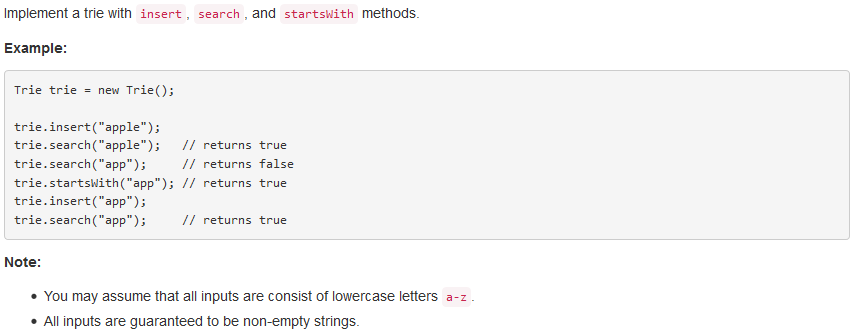
问题求解:
public class Trie {
TrieNode root;
/**
* Initialize your data structure here.
*/
public Trie() {
root = new TrieNode(' ');
}
/**
* Inserts a word into the trie.
*/
public void insert(String word) {
TrieNode cur = root;
for (int i = 0; i < word.length(); i++) {
if (cur.next[word.charAt(i) - 'a'] == null) {
cur.next[word.charAt(i) - 'a'] = new TrieNode(word.charAt(i));
}
cur = cur.next[word.charAt(i) - 'a'];
}
cur.isWord = true;
}
/**
* Returns if the word is in the trie.
*/
public boolean search(String word) {
TrieNode cur = root;
for (int i = 0; i < word.length(); i++) {
if (cur.next[word.charAt(i) - 'a'] == null) return false;
cur = cur.next[word.charAt(i) - 'a'];
}
return cur.isWord;
}
/**
* Returns if there is any word in the trie that starts with the given prefix.
*/
public boolean startsWith(String prefix) {
TrieNode cur = root;
for (int i = 0; i < prefix.length(); i++) {
if (cur.next[prefix.charAt(i) - 'a'] == null) return false;
cur = cur.next[prefix.charAt(i) - 'a'];
}
return true;
}
}
class TrieNode {
public char val;
public boolean isWord;
public TrieNode[] next;
public TrieNode(char c) {
this.val = c;
this.isWord = false;
next = new TrieNode[26];
}
}
/**
* Your Trie object will be instantiated and called as such:
* Trie obj = new Trie();
* obj.insert(word);
* boolean param_2 = obj.search(word);
* boolean param_3 = obj.startsWith(prefix);
*/
一、Add and Search Word - Data structure design
问题描述:
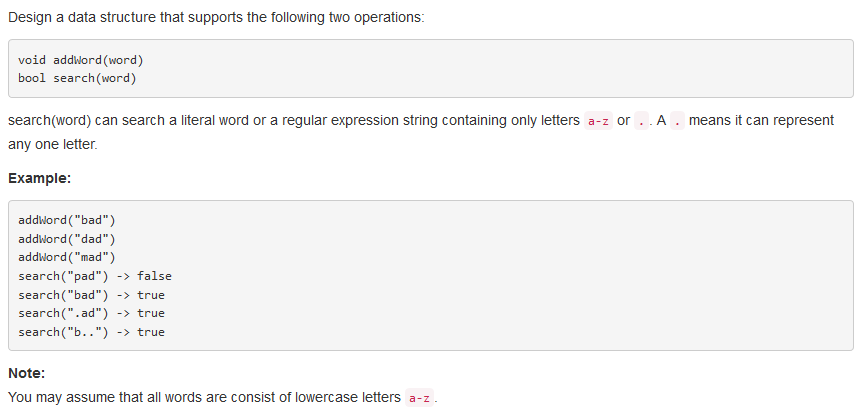
问题求解:
public class WordDictionary {
public class TrieNode {
public TrieNode[] children = new TrieNode[26];
public boolean isWord = false;
}
private TrieNode root = new TrieNode();
public void addWord(String word) {
TrieNode node = root;
for (char c : word.toCharArray()) {
if (node.children[c - 'a'] == null) {
node.children[c - 'a'] = new TrieNode();
}
node = node.children[c - 'a'];
}
node.isWord = true;
}
public boolean search(String word) {
return match(word.toCharArray(), 0, root);
}
private boolean match(char[] chs, int k, TrieNode node) {
if (k == chs.length) return node.isWord;
if (chs[k] != '.') {
return node.children[chs[k] - 'a'] != null && match(chs, k + 1, node.children[chs[k] - 'a']);
} else {
for (int i = 0; i < node.children.length; i++) {
if (node.children[i] != null) {
if (match(chs, k + 1, node.children[i])) {
return true;
}
}
}
}
return false;
}
}
/**
* Your WordDictionary object will be instantiated and called as such:
* WordDictionary obj = new WordDictionary();
* obj.addWord(word);
* boolean param_2 = obj.search(word);
*/

