数据的预处理
2017-12-04 16:31:10
数据预处理(data preprocessing)是指在主要的处理以前对数据进行的一些处理。
比如缺项,噪声(工资=-100),不匹配(年龄和出生日期不匹配),冗余等等。
一、数据清洗
1)缺少数据
可能的原因有设备故障,数据没有提供,N/A不适用。
缺少数据也是有各种类别的
- 一是完全随机的缺失
- 二是某种条件下的随机缺失
- 三是必然缺失
处理方法:
- 忽略,把这些数据删除
- 手工重填,要么给用户重填,要么自己根据经验重填
- 自动重填,遇到缺项填入一个缺省值
2)异常值
如何判别Outlier,也就是离群点呢?这里给出一个算法:

这里的distancek(o)就是一个knn的距离,也就是图中的k=3时,OP3之间的距离。
lrd(A)中分母部分是A到k个近邻的距离和比上近邻数。
lofk(A)就是算的一个相对概念,也就是使用A中的k近邻的lrd和再除以A本省的lrd和来进行判别A是否是Outlier。
这也很好理解,判断一个人在班级里是否离群,不能单从他一天只和很少的同学聊天进行判定,因为如果他周围的同学都很高冷,那么也不能说他是离群的。所以是否离群从本质上来说是个相对的概念。
一个例子:
3)重复数据
一般使用滑动窗口的方法来进行去重,但是这有个前提,就是相同的数据离的很近。因此需要通过键值来排序。
键值的生成就很有讲究了,可以采用各种方法来进行定义。

4)类型转换
数据有各种类型,连续型,离散型,序列词(好,中,差),称呼(红绿蓝),字符串等。
在给数据进行编码的时候就要注意了,如果是给序列词编码,那还好,因为其本身就有一个差异,但是在给红绿蓝这类的进行编码的时候就比较麻烦了,当然了,可以简单的用1,2,3进行编码但是,这种编码会导致红蓝在维度上距离变远,有可能导致问题复杂度上升。如下图,如果调整编码方式,那么分割线就可以从曲线变成直线。


有种处理的方法是使用多维空间的方法进行简化计算,比如三种颜色,就可以使用三维来进行表示,这样三种颜色的距离就是一样的。但是这种方法的缺点也是很明显的,如果类型数目很多那么相应的维数就会爆炸。
5)不平衡数据集
在处理不平衡数据集的时候就不能单单只看正确率了,比如判断一个人是否感冒,100个人里只有一个人感冒,99个人健康,你的分类器最后收敛到全部报健康,那么正确率是99%,但是我要这样的分类器有何用呢?
所以在处理不平衡数据的时候要综合考虑。

而召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。那也有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN)。
- 0-1标准化

比如映射到0-1的话,上式中的newmax=1;newmin=0。
- Z-score 标准化
也叫标准差标准化,经过处理的数据符合标准正态分布,即均值为0,标准差为1,也是SPSS中最为常用的标准化方法,其转化函数为:

7)常用概率量


二、特征选择
从n个特征中选择m个特征。
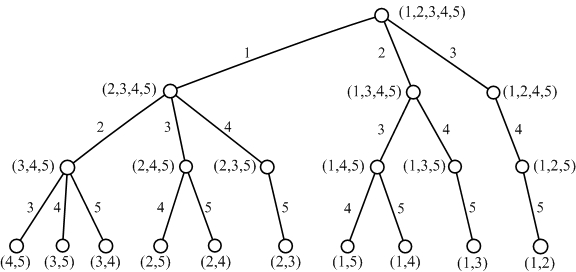
- 分支限界
比如从5个特征中选择2个特征,可以采用树的形式将所有可能进行遍历,在分支限界算法中,会对一些明显不符合要求的树进行剪枝操作,减少不必要的检索。这种方法得到的结果一定是全局最优的。
- TOP-k
将所有的特征进行排列,从中选择最优的k个特征。这种排列的依据可以是使用决策树中的信息熵的概念。也就是选择前后信息增益最大的k个特征来作为最终的属性值。
三、特征提取
特征抽取(Feature Extraction):Creatting a subset of new features by combinations of the exsiting features.也就是说,特征抽取后的新特征是原来特征的一个映射。
特征选择(Feature Selection):choosing a subset of all the features(the ones more informative)。也就是说,特征选择后的特征是原来特征的一个子集。
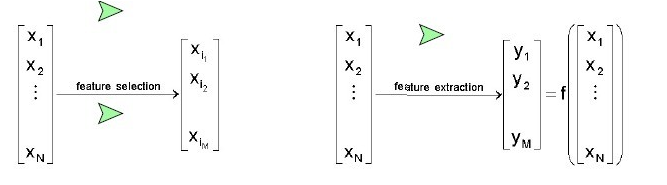
主成分分析PCA(Principal Component Analysis):
PCA(Principal Component Analysis)不仅仅是对高维数据进行降维,更重要的是经过降维去除了噪声,发现了数据中的模式。
PCA把原先的n个特征用数目更少的m个特征取代,新特征是旧特征的线性组合,这些线性组合最大化样本方差,尽量使新的m个特征互不相关。从旧特征到新特征的映射捕获数据中的固有变异性。
从数学上进行推导:

这里就是把xk进行投影到一维向量上,一维向量的单位向量为e。目标就是所有的点到投影点的距离最短。
之后可以采用Lagrange乘子法来计算最优值。

算到最后我们发现要求的最优等价于求S的最大特征值,而单位向量就是该特征值对应的特征向量。
举个例子:
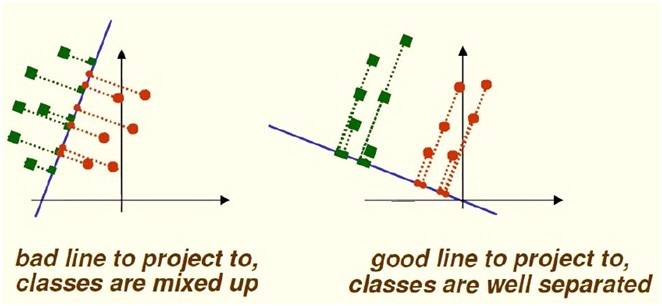
线性判别分析LDA(Linear Discriminant Analysis):
首先需要说明的是PCA算法是一种无监督的算法,也就是说,他是不考虑标签的降维方法。而LDA则是一种监督学习下的降维方法。
也就是说PCA,它主要的目的是寻找数据variance变化最大的轴。通过删去数据中variance变化不大的轴来压缩数据的维数。PCA没有办法很好的解决数据分类的问题(classification)。
LDA 是一种用于分类数据的分析方法。他的目的是寻找到一条直线,当把所有数据点投影到直线上之后,尽可能的分开不同类别的训练数据。
Fisher Criterion:

分子是均值的差的平方,分母是散度的平方和。
LDA问题本质就是求J的最大值问题:



最后依然是转换成了特征向量的问题,可以通过一些化简,避免计算特征值和特征向量,去掉相应的标量即可得到最终的结果。
以上讲的是两分类的问题,那么对于多分类该如何计算呢?
幸运的是,Fisher 准则可以很方便的推导到多类问题上:

Sw的计算没有明显的变化,Sb的计算出现了一点小的变化,就是每个均值减的是总的均值,并且前面要乘上当前类的总数。
不妨将C=2,带入计算可得:(前面的数字可以忽略,因为我们最后要求的只是一个方向)

LDA的一些限制:
因为要求Sw的逆,所以Sw不能是奇异的。如果维度大于样本数的时候就会出现奇异。
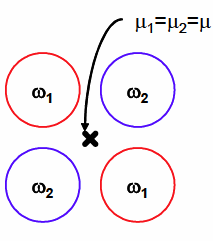
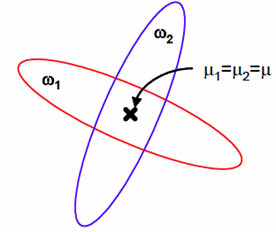
如果u1=u2的话,那么就会无法分解,因为分子为0了。