



Base64编码
2017-08-17 14:40:27
Base64是一种用64个可见字符来表示任意二进制数据的方法。
一、使用Base64编码的原因
X.509公钥证书也好,电子邮件数据也好,经常要用到Base64编码,那么为什么要作一下这样的编码呢?
我们知道在计算机中任何数据都是按ascii码存储的,而ascii码的128~255之间的值是不可见字符。而在网络上交换数据时,比如说从A地传到B地,往往要经过多个路由设备,由于不同的设备对字符的处理方式有一些不同,这样那些不可见字符就有可能被处理错误,这是不利于传输的。所以就先把数据先做一个Base64编码,统统变成可见字符,这样出错的可能性就大降低了。
对证书来说,特别是根证书,一般都是作Base64编码的,因为它要在网上被许多人下载。电子邮件的附件一般也作Base64编码的,因为一个附件数据往往是有不可见字符的。
用记事本打开exe、jpg、pdf这些文件时,我们都会看到一大堆乱码,因为二进制文件包含很多无法显示和打印的字符,所以,如果要让记事本这样的文本处理软件能处理二进制数据,就需要一个二进制到字符串的转换方法。Base64是一种最常见的二进制编码方法。
3x8=24bit,划为4组,每组正好6个bit,之后在这6bit前加上两位0,会得到4个字节的数据流。
然后查表,获得相应的4个字符,就是编码后的字符串。
所以,Base64编码会把3字节的二进制数据编码为4字节的文本数据,长度增加33%,好处是编码后的文本数据可以在邮件正文、网页等直接显示。
如果要编码的二进制数据不是3的倍数,最后会剩下1个或2个字节怎么办?Base64用\x00字节在末尾补足后,再在编码的末尾加上1个或2个=号,表示补了多少字节,解码的时候,会自动去掉。
具体例子:
转码过程例子:3*8=4*6内存1个字节占8位转前: s 1 3先转成ascii:对应 115 49 512进制: 01110011 00110001 001100116个一组(4组) 011100110011000100110011然后才有后面的 011100 110011 000100 110011然后计算机是8位8位的存数 6不够,自动就补两个高位0了所有有了 高位补0科学计算器输入 00011100 00110011 00000100 00110011得到 28 51 4 51查对下照表 c z E z
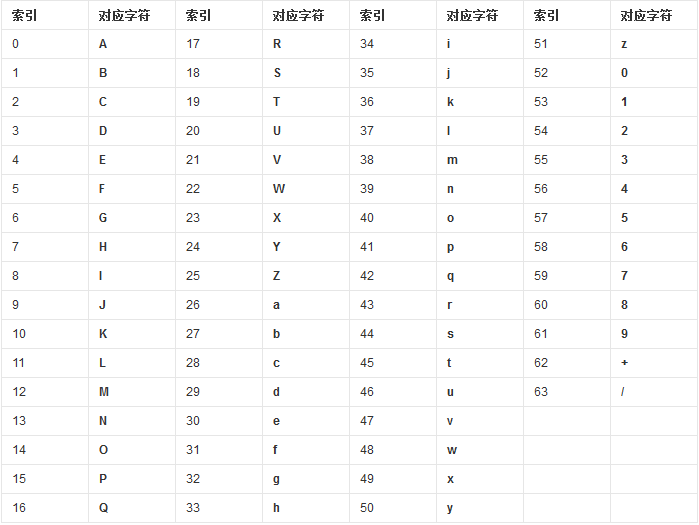
由于标准的Base64编码后可能出现字符+和/,在URL中就不能直接作为参数,所以又有一种"url safe"的base64编码,其实就是把字符+和/分别变成-和_。
还可以自己定义64个字符的排列顺序,这样就可以自定义Base64编码,不过,通常情况下完全没有必要。
Base64是一种通过查表的编码方法,不能用于加密,即使使用自定义的编码表也不行。
Base64适用于小段内容的编码,比如数字证书签名、Cookie的内容等。
由于=字符也可能出现在Base64编码中,但=用在URL、Cookie里面会造成歧义,所以,很多Base64编码后会把=去掉。
三、在Python中进行base64的编码与解码
使用Python自带的base64库可以直接进行base64的编解码。
import base64 temp = "jiangsu".encode('ascii') s = base64.b64encode(temp) print(s) # b'amlhbmdzdQ==' # 显然jiangsu不是3的倍数,所以最后会进行补零处理 # 由于补了两个零,所以在编码后的字符串中有两个==
url_safe的编码:
import base64 temp = "i\xb7\x1d\xfb\xef\xff".encode("utf-8") s = base64.b64encode(temp) print(s) s = base64.urlsafe_b64encode(temp) print(s) # b'acK3HcO7w6/Dvw==' # b'acK3HcO7w6_Dvw==' # 由于超出了128,所以改用了utf-8编码

