
Python 爬虫-正则表达式(补)
2017-08-08 18:37:29
一、Python中正则表达式使用原生字符串的几点说明
- 原生字符串和普通字符串的不同
相较于普通字符串,原生字符串中的\就是反斜杠,并不表达转义。不过,字符串转成正则表达式的时候会将其中的\理解为转义字符,这点需要注意。
- 为什么使用原生字符串
使用原生字符串是为了更好的表达正则表达式。若采用普通字符串,将会产生两次字符串的解释。
举两个例子:
(1)在正则表达式中匹配 \
使用普通字符串:"\\\\"->'\',原因是如果使用普通字符串,那么Python会将其中的\理解为转义字符,所以传给正则表达式的其实是“\\”,此时正则表达式也会将\理解为转义字符,所以讲“\\”理解为普通的\。
使用原生字符串:r“\\”->'\',原因是使用了原生字符串,简化了第一步的转义操作,所以给正则表达式的就是“\\”, 所以正则表达式会把其解释为\。
(2)在正则表达式中使用元字符\d
众所周知\d用来匹配一个数字字符,等价于 [0-9]。
使用普通字符串:“\\d”->\d",原因其实和刚才的是一样的,Python字符串解释的时候会将反斜杠理解为转义字符,所以提交给正则表达式的时候其实是‘\d’,这样就符合要求了。
使用原生字符串:r‘\d’->'\d',使用原生字符串的话,就直接是\d就可以了,这就体现出了使用原生字符串的优势。
通过查阅资料,使用原生字符串的时候,发现需要对一些特殊字符进行转义,需要转义的特殊字符有* . ? + $ ^ [ ] ( ) { } | \ /。
二、正则表达式详细的语法说明
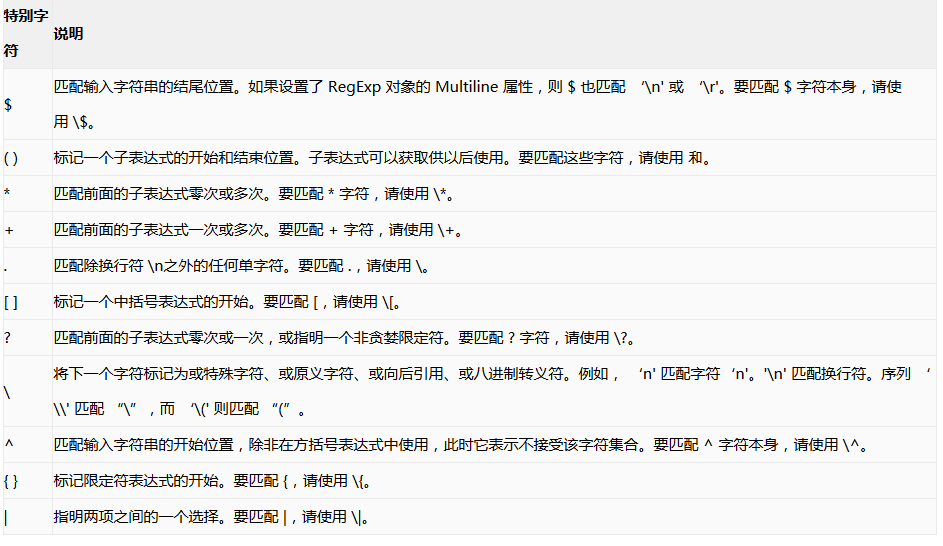






三、最小匹配问题
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。考虑这个表达式:a.*b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号?。这样.*?就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。现在看看懒惰版的例子吧:
a.*?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab(第一到第三个字符)和ab(第四到第五个字符)。
为什么第一个匹配是aab(第一到第三个字符)而不是ab(第二到第三个字符)?简单地说,因为正则表达式有另一条规则,比懒惰/贪婪规则的优先级更高:最先开始的匹配拥有最高的优先权——The match that begins earliest wins。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号