

Python 爬虫-Scrapy框架基本使用
2017-08-01 22:39:50
一、Scrapy爬虫的基本命令
Scrapy是为持续运行设计的专业爬虫框架,提供操作的Scrapy命令行。
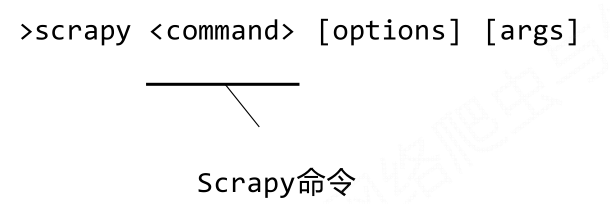
- Scrapy命令行格式
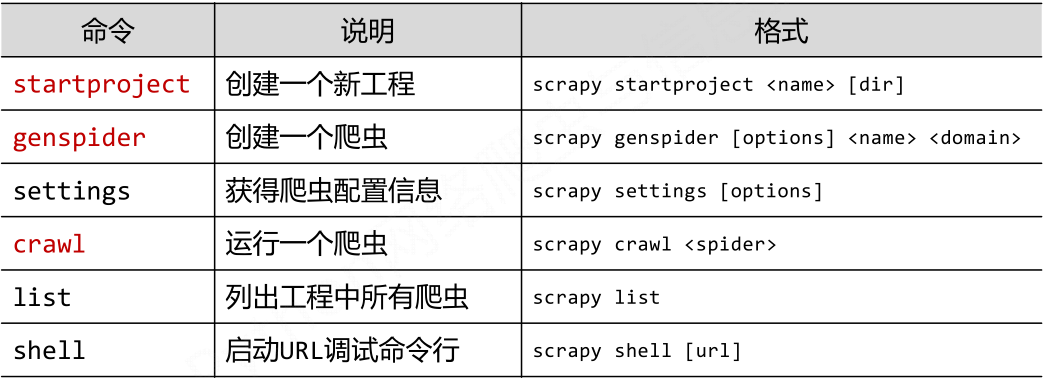
- Scrapy常用命令
- 采用命令行的原因
命令行(不是图形界面)更容易自动化,适合脚本控制本质上,Scrapy是给程序员用的,功能(而不是界面)更重要。
二、Scrapy爬虫的一个基本例子
演示HTML页面地址:http://python123.io/ws/demo.html
步骤一:建立一个Scrapy爬虫
选取一个文件夹,例如E:\python,然后执行如下命令。

此时在python文件夹下就会生成一个名为Python123demo的工程,该工程的文件结构为:


步骤二:在工程中产生一个Scrapy爬虫
使用cd进入E:\python\python123demo文件夹,然后执行如下命令。

该命令作用:
(1)生成一个名称为demo的spider
(2)在spiders目录下增加代码文件demo.py
该命令仅用于生成demo.py,该文件也可以手工生成
步骤三:配置产生的spider爬虫

demo文件是使用genspider命令产生的一个spider。
- 继承于scrapy.Spider
- name='demo'说明爬虫的名字是demo
- allowed_domains指爬取网站时只能爬取该域名下的网站链接
- star_urls是指爬取的一个或多个起始的爬取url
- parse()用于处理响应并发现新的url爬取请求
配置:(1)初始URL地址 (2)获取页面后的解析方式

步骤四:运行爬虫,获取网页
执行如下代码:

demo爬虫被执行,捕获页面存储在demo.html
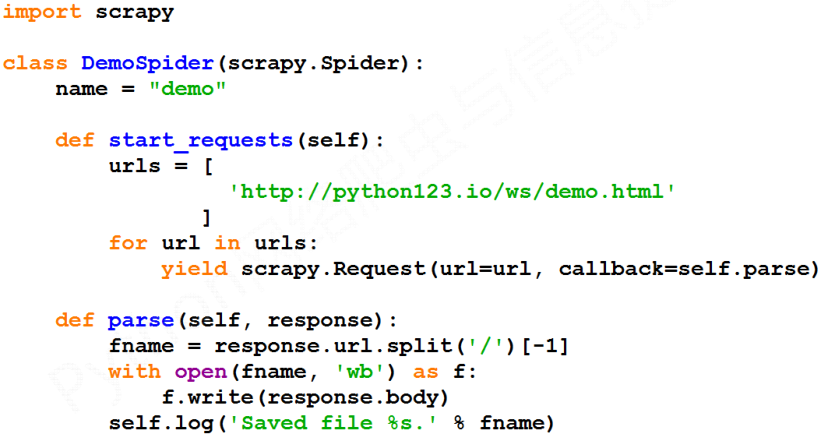
还有一种等价的表达方式:
三、Scrapy爬虫的基本使用
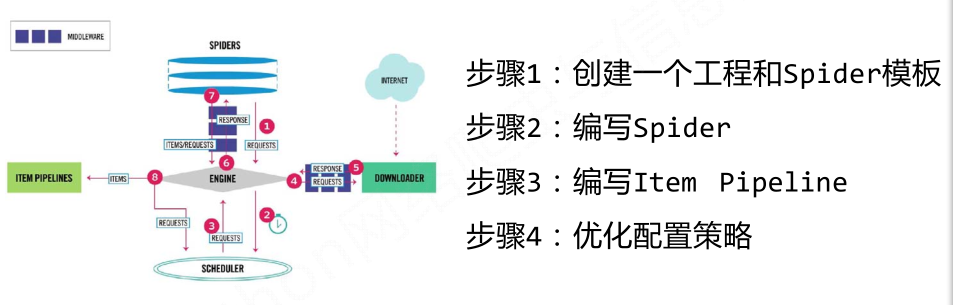
这四个步骤会涉及到三个类:Request类、Response类、Item类;
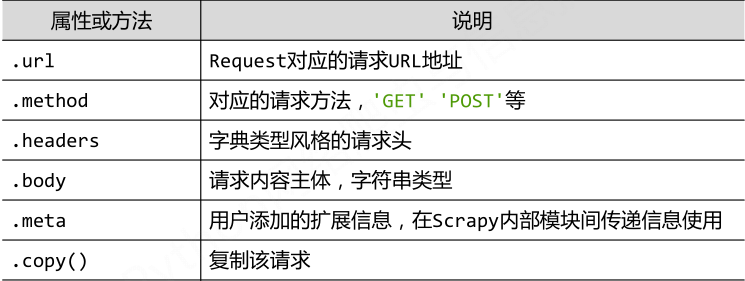
- Request类
class scrapy.http.Request():Request对象表示一个HTTP请求,由Spider生成,由Downloader执行。
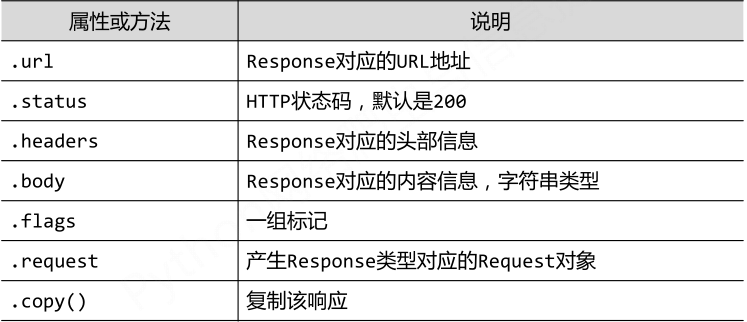
- Response类
class scrapy.http.Response():Response对象表示一个HTTP响应;由Downloader生成,由Spider处理。
- Item类
class scrapy.item.Item():Item对象表示一个从HTML页面中提取的信息内容;由Spider生成,由Item Pipeline处理;Item类似字典类型,可以按照字典类型操作。

