

机器学习 Numpy库入门
2017-06-28 13:56:25
Numpy 提供了一个强大的N维数组对象ndarray,提供了线性代数,傅里叶变换和随机数生成等的基本功能,可以说Numpy是Scipy,Pandas等科学计算库的基础。
使用前需要引入numpy包,一般会给他起个别名为np。
import numpy as np
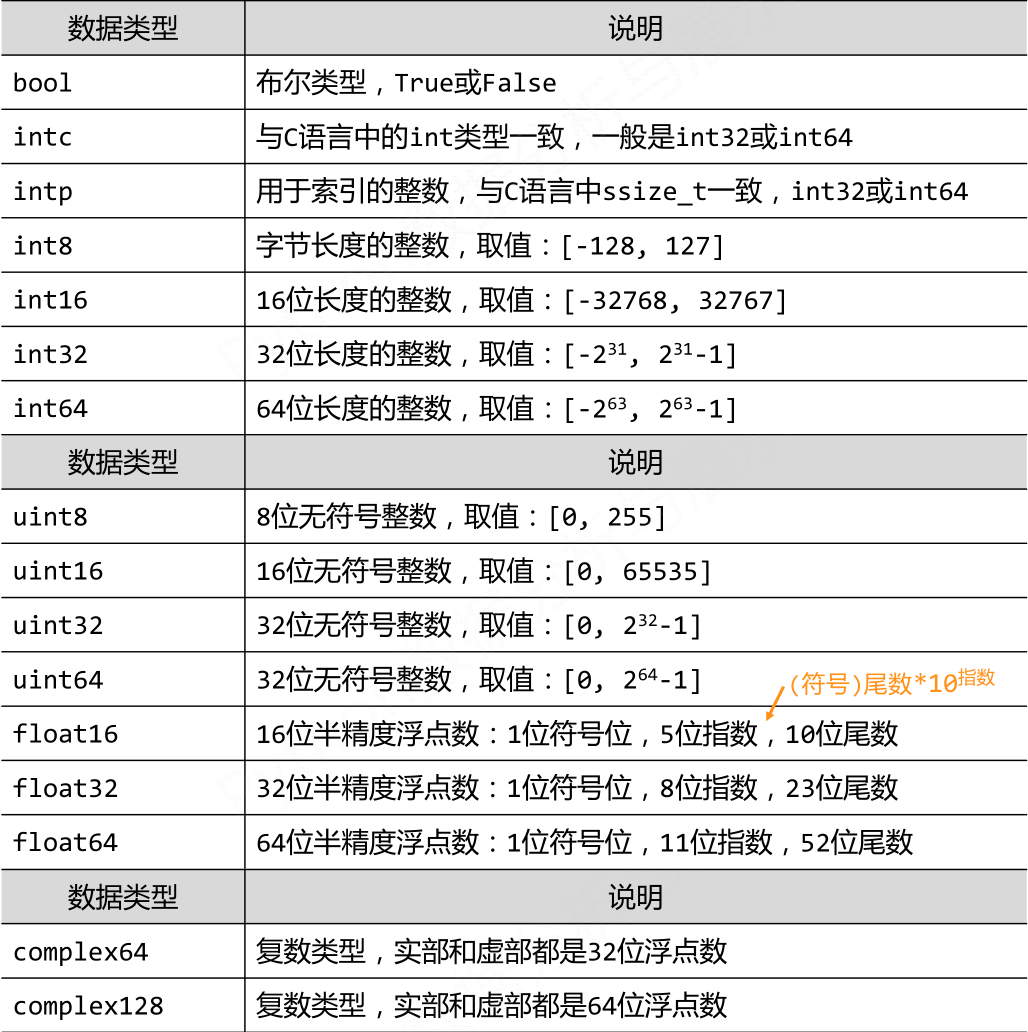
一、ndarray的元素类型
ndarray一个特点就是同构,就是说其中的元素类型是一致的。并且为了减少从存储空间和提高运行效率,ndarray的数据类型相较于python本身多了很多具体的类型。
所支持的数据类型包括整数、浮点数、复数、布尔值、字符串或是普通的 Python 对象(object)。
二、ndarray创建方法
(1)使用python自带的数据结构列表或者元组进行创建。
- x = np.array(list/tuple)
- x = np.array(list/tuple, dtype=np.float32) 当用户不指定dtype时,python编辑器会自动选择合适的数据类型
import numpy as np a=np.array([[1,2,3],[4,5,6]]) print(a)
用元组创建同理,也可以使用元组加列表的混合方式进行创建,不过,需要注意的是,这种创建需要同构,也就是首先数据类型要一致,其次每个元素中的数据个数也要一致,否则,称为异构,异构模型将不再适用numpy库中的库函数。
(2)使用Numpy中的库函数进行创建。
常用的函数:
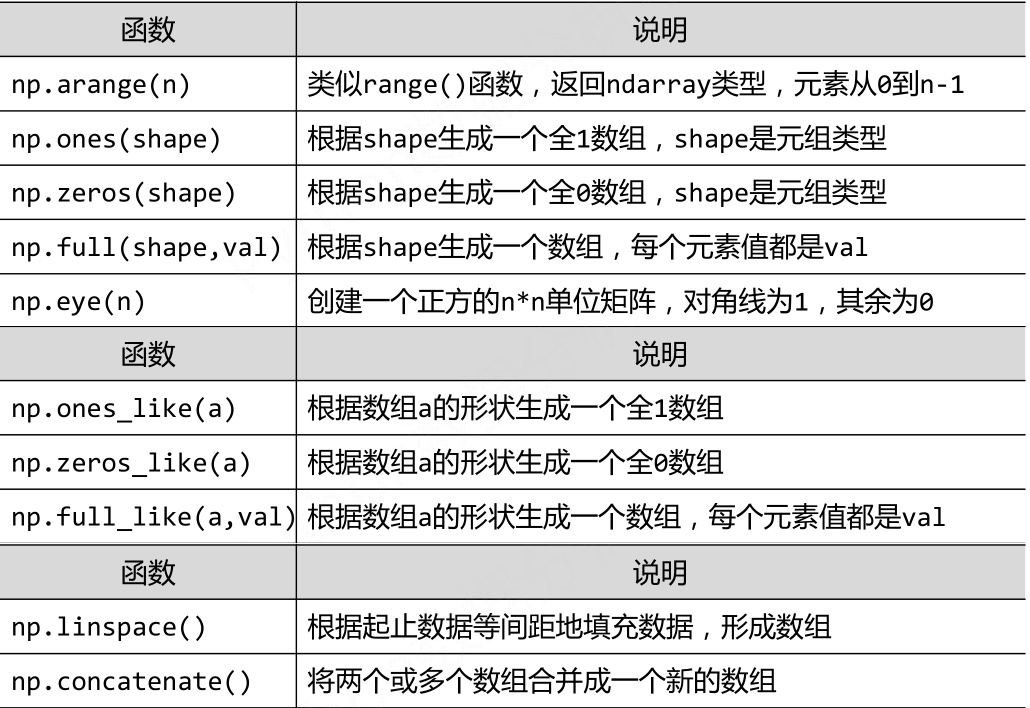
#linspace默认情况下是全闭的,有一个参数可以进行控制,即endpoint,默认情况下是True a=np.linspace(1,10,4) b=np.linspace(1,10,4,endpoint=False) print(a) print(b) #a=array([ 1. 4. 7. 10.]) #b=array([ 1. 3.25 5.5 7.75])
有一点需要注意的是这些默认函数,除了arange()已经规定了生成整数外,其他的默认生成的都是浮点型的数据。
(3)从csv文件中读取生成ndarray
np.savetxt(frame, array, fmt='%.18e', delimiter=None)
- frame : 文件、字符串或产生器,可以是.gz或.bz2的压缩文件
- array : 存入文件的数组
- fmt : 写入文件的格式,例如:%d %.2f %.18e
- delimiter : 分割字符串,默认是任何空格,如果是存成csv格式,所以最后一个参数需要写成‘,’
np.loadtxt(frame, dtype=np.float, delimiter=None, unpack=False)
- frame : 文件、字符串或产生器,可以是.gz或.bz2的压缩文件
- dtype : 数据类型,可选
- delimiter : 分割字符串,默认是任何空格
- unpack : 如果True,读入属性将分别写入不同变量
import numpy as np a=np.ones((3,2)) np.savetxt("e:/ee.csv",a,fmt="%d",delimiter=',') b=np.loadtxt("e:/ee.csv",dtype=np.int,delimiter=',') print(b)
三、narray的一些属性
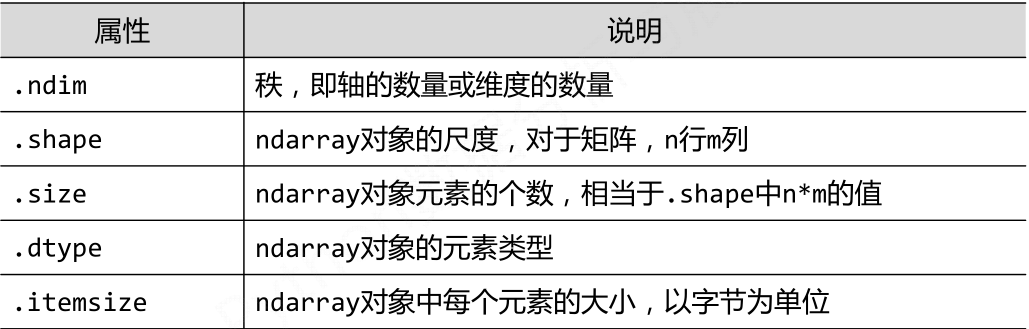
这些是narray的成员数据值,可以直接使用成员访问符进行查看。
import numpy as np a = np.array([[1,2,3],[4,5,6],[7,8,9]]) print(a.shape) print(a.size) print(a.dtype) print(a.ndim) # output: # (3, 3) # 9 # int32 # 2

