


Meta-LLaMA
LLAMA
- paper:https://readpaper.com/paper/1669077195157493760
- 模型参数:7B、13B、33B、65B
- 主要贡献:完全使用开源数据进行训练,训练完成的模型开源
Overall, our entire training dataset contains roughly 1.4T tokens after tokenization. For most of our training data, each token is used only once during training, with the exception of the Wikipedia and Books domains, over which we perform approximately two epochs.
LLAMA2
- paper:https://readpaper.com/paper/1877177868599782912
- 模型参数:7B、13B、70B
- 主要贡献:LLAMA1仅提供了pretrain版本的模型,没有在sft和rlhf上有贡献,导致研究人员很难在这些领域做出突破。LLAMA2这次不仅优化了pretrain阶段的工作还放出了进行SFT和RLHF后的模型LLAMA2-CHAT
-
LLAMA2:使用新的开源数据进行训练,整体Token数量提升40%,到达了2万亿级别的token;模型context length提升了一倍,到达了4k长度;使用grouped-query attention
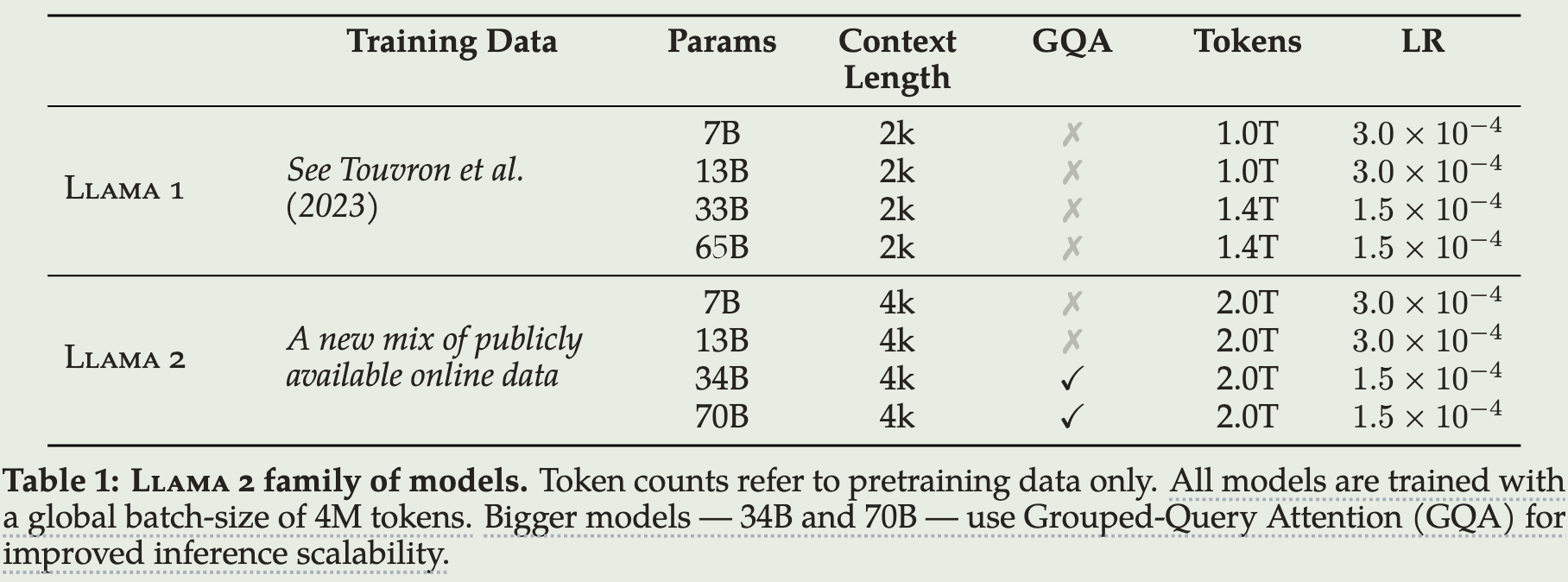
-
LLAMA2-CHAT:一个在对话数据上进行SFT和RLHF后的大模型
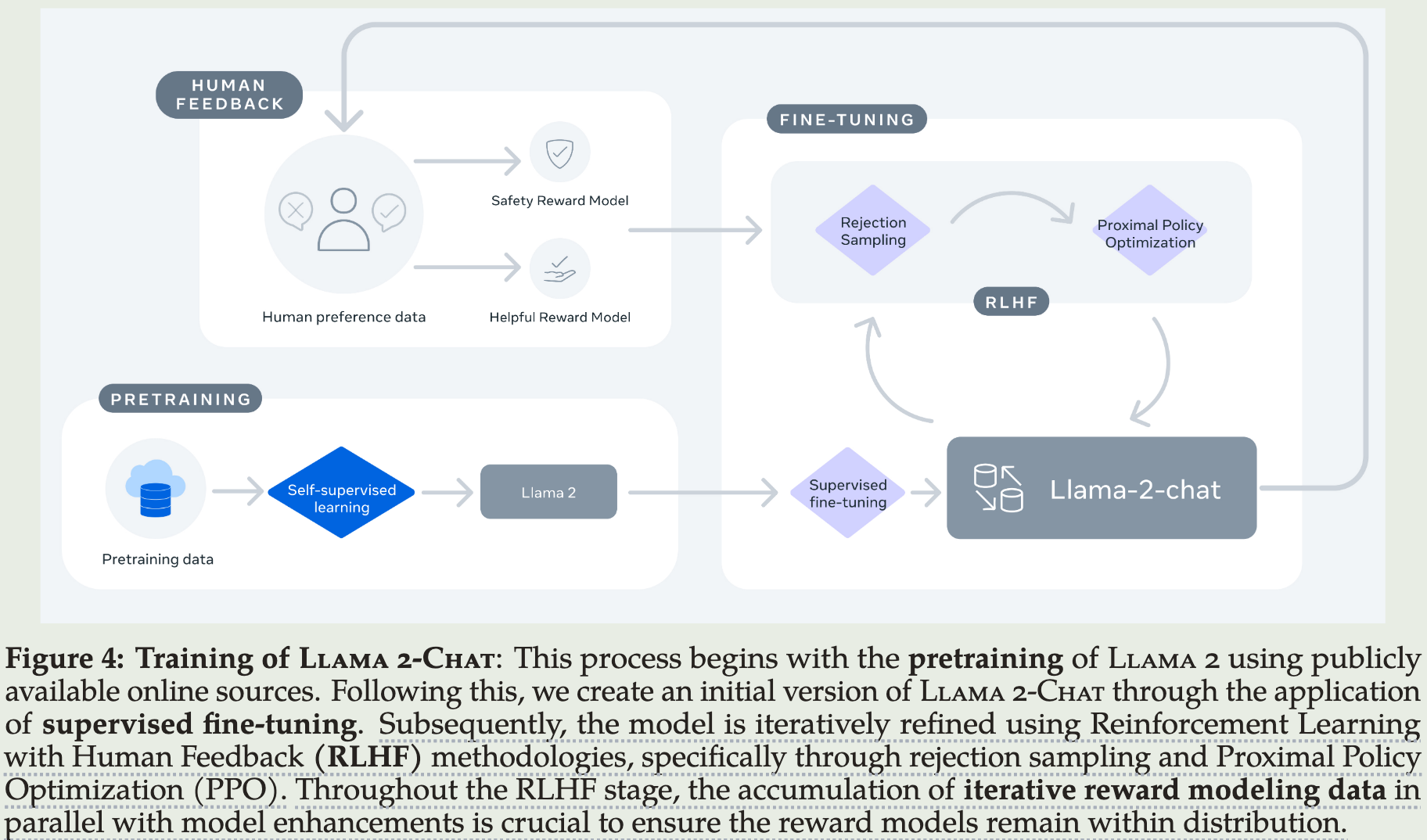
Pretraining
- Pretraining Data
在2万亿token的数据上进行预训练,对有实时来源的数据进行上采样提升模型知识记忆同时缓解幻觉现象。
We trained on 2 trillion tokens of data as this provides a good performance–cost trade-off, up-sampling the most factual sources in an effort to increase knowledge and dampen hallucinations.
SFT
Quality is all you need:少量(千级别)高质量SFT数据相比百万级别开源数据能起到更好的效果。最终模型在万级别SFT数据积累到后效果已经非常好。
在人工审查数据质量的过程中,发现LLM输出的回复和人工生产的回复相比并没有明显的劣势,建议前期投入更多精力到RLHF的标注中。
RLHF
- 数据收集
让标注同学首先写prompt,然后基于给定的标准从模型生成的两个回复中进行选择。为了使多样性最大化,这两个回复内容是由两个不同的模型在不同的温度系数等超参设置下生成的。在标注过程中,还要求给出差异的具体得分:significantly better、better、slightly better、negligibly better、unsure。
似乎RM数据量越多越好,另外需要与SFT模型迭代同频,因为RM对于没有见过的分布准确率会迅速下降,最终收集了100w pair数据。
As we collected more preference data, our reward models improved, and we were able to train progressively better versions for Llama 2-Chat。Llama 2-Chat improvement also shifted the model's data distribution. Since reward model accuracy can quickly degrade if not exposed to this new sample distribution, i.e., from hyper-specialization (Scialom et al., 2020b), it is important before a new Llama 2-Chat tuning iteration to gather new preference data using the latest Llama 2-Chat iterations. This step helps keep the reward model on-distribution and maintain an accurate reward for the latest model.
在最终使用的时候,将开源数据也加入进来提升模型的鲁棒性。
We note that in the context of RLHF in this study, the role of reward signals is to learn human preference for Llama 2-Chat outputs rather thanany model outputs. However, in our experiments, we do not observe negative transfer from the open-source preference datasets. Thus, we have decided to keep them in our data mixture, as they could enable better generalization for the reward model and prevent reward hacking, i.e. Llama 2-Chat taking advantage of some weaknesses of our reward, and so artificially inflating the score despite performing less well.
- Reward Modeling
从SFT Model初始化,loss设计上加入了margin逻辑,针对明确不同的回复采用大的margin,对于相似的回复用小尺度的margin。
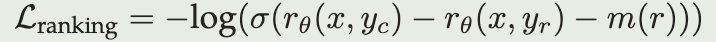



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
2018-09-15 最大的矩形面积 Maximal Rectangle