
条件随机场 CRF
2019-09-29 15:38:26
问题描述:请解释一下NER任务中CRF层的作用。
问题求解:
在做NER任务的时候,神经网络学习到了文本间的信息,而CRF学习到了Tag间的信息。
- 加入CRF与否网络的差别
首先对于不加CRF层的NER网络,往往每个输出的Tag是贪心的进行选取到的,如下图所示:
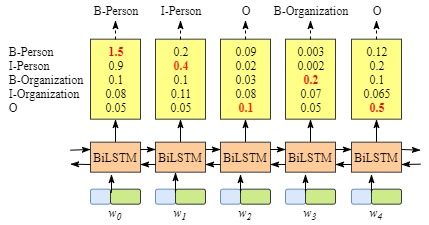
这种方案的结果没有考虑到Tag之间的关系,往往会造成最后的结果是不符合正常模式的,比如出现B-Person,B-Person的情况。
加入CRF层后,CRF层会根据训练语料去学习其中存在的模式,比如B-Person,B-Person这种情况是不会出现的,其网络结构如下:
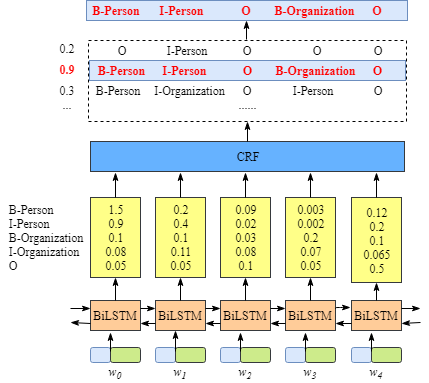
- CRF层的训练机制
CRF有两个概念,发射分数(Emission score)和转移分数(Transition score)。
Emission score:神经网络输出的各个Tag的置信度;
Transition score:CRF层中各个Tag之前的转移概率;
加入CRF层后,Loss Function为:
![]()
所以我们需要定义的就是这里的Path Score如何计算,另外真实的Path Score应该是占比最高的。
以Path Score Real举例,Path Score Real = Emission score + Transition score。
Take the real path, “START B-Person I-Person O B-Organization O END”, we used before, for example:
- We have a sentence which has 5 words, w1,w2,w3,w4,w5w1,w2,w3,w4,w5
- We add two more extra words which denote the start and the end of a sentence, w0,w6w0,w6
- SiSi consists of 2 parts: Si=EmissionScore+TransitionScoreSi=EmissionScore+TransitionScore (The emission and transition score are expanined in section 2.1 and 2.2)
Emission Score:
EmissionScore=x0,START+x1,B−Person+x2,I−Person+x3,O+x4,B−Organization+x5,O+x6,ENDEmissionScore=x0,START+x1,B−Person+x2,I−Person+x3,O+x4,B−Organization+x5,O+x6,END
xindex,labelxindex,label is the score if the indexthindexth word is labelled by labellabel
These scores x1,B−Personx1,B−Person x2,I−Personx2,I−Person x3,Ox3,O x4,Organizationx4,Organization x5,Ox5,O are from the previous BiLSTM output.
As for the x0,STARTx0,START and x6,ENDx6,END, we can just set them zeros.
Transition Score:
TransitionScore=TransitionScore=
tSTART−>B−Person+tB−Person−>I−Person+tSTART−>B−Person+tB−Person−>I−Person+
tI−Person−>O+t0−>B−Organization+tB−Organization−>O