
侠说java8--Stream流操作学习笔记,都在这里了
前言
- 首次接触到Stream的时候以为它是和InputStream、OutputStream这样的输入输出流的统称。
流和集合的前世今生
概念的差异
在开发中,我们使用最多的类库之一就是集合。集合是一种内存中的数据结构,用来保存对象数据,集合中的每个元素都得先算出来才能添加到集合中,相比之下:
集合用特定数据结构(如List,Set或Map)存储和分组数据。但是,流用于对存储的数据(例如数组,集合或I / O资源)执行复杂的数据处理操作,例如过滤,匹配,映射等。由我们可以知道:
集合主要是存储数据,而流主要关注对数据的操作。
数据修改
我们可以添加或删除集合中的元素。但是,不能添加或删除流中的元素。流是通过消费数据源的方式,对其执行操作并返回结果。它不会修改数据源头。
内部迭代和外部迭代
Java8提供的 Streams的主要特点是我们不必担心使用流时的迭代。流在后台为我们内部执行迭代。我们只需关注在数据源上需要执行哪些操作即可。
循环遍历
流只能遍历一次。如果你遍历该流一次,则将其消耗掉。要再次遍历它,必须再次从数据源中获取新的流。但是,集合可以遍历多次。
惰性求值(懒汉or饿汉)
相信大家都知道单例模式中的两种模式,懒汉式和饿汉式,在这里也可以相似的理解。
集合以饿汉式迅速的构建,即是所有元素都在开始时就进行了计算。但是,流是延迟构造的,即在调用终端操作之前不会去计算中间操作,也就是惰性求值(懒汉式)。

特性解读
两种迭代方式
上面我们提到了两种迭代的方式,内部迭代和外部迭代,怎么来理解呢?
在java8之前,我们用的for循序,其实就是外部迭代,显示的去循环集合中的每一个元素。
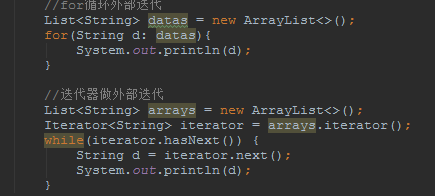
而内部迭代则是,Stream内部帮我们做了这个操作,并且它还把流的值放到了某个地方,我们只需要给出相应的指令(map/flatmap/filter),指挥它就行。

中间操作和终端操作
在java8中,我们可以把中间操作认为是工厂流水线上的一个工人,它将产品加工过后,返回一个新的东西(流),一个新的流。它会让多个操作可以连接起来,一旦流水线上触发一个终端操作就会执行处理。
惰性 求值的理解
上面提到的两种操作其实就是惰性求值的解读。
中间操作一般都可以合并起来,在终端操作时一次性全部处理求值。
在处理更大的数据或流操作很多时,惰性求值是真正的福音。
因为处理数据时,我们不确定如何使用处理后的数据。直接循环一个很大的集合将始终以性能为代价而告终,其实客户端可能只是最终会利用其中的一小部分。或者,根据某些条件过滤一下,它可能甚至不需要利用该数据。惰性求值处理基于按需 策略来帮助我们实现业务功能。
Stream操作案例
String类上提供了有两个新方法:join和chars,使用join拼接字符串非常方便。
String.join(":", "foobar", "foo", "bar");
// => foobar:foo:bar
第二种方法chars为字符串的所有字符创建流,可以对这些字符使用流操作:
"foobar:foo:bar"
.chars()
.distinct()
.mapToObj(c -> String.valueOf((char)c))
.sorted()
.collect(Collectors.joining());
// => :abfor
处理文件
Files最初是在Java 7中作为Java NIO的一部分引入的。JDK 8 API添加了一些其他方法,使我们能够对文件使用功能流。
try (Stream<Path> stream = Files.list(Paths.get(""))) {
String joined = stream
.map(String::valueOf)
.filter(path -> !path.startsWith("."))
.sorted()
.collect(Collectors.joining("; "));
System.out.println("List: " + joined);
}
上面的示例列出了当前工作目录的所有文件,然后将每个路径映射到其字符串表示形式。然后将结果过滤,排序并最终加入一个字符串中。
细心的你您可能已经注意到,流的创建被包装在try / with语句中。流实现了AutoCloseable,在这种情况下,由于有IO操作支持,因此我们确实必须显式关闭流。
查找文件
Path start = Paths.get("");
int maxDepth = 5;
try (Stream<Path> stream = Files.find(start, maxDepth, (path, attr) ->
String.valueOf(path).endsWith(".js"))) {
String joined = stream
.sorted()
.map(String::valueOf)
.collect(Collectors.joining("; "));
System.out.println("Found: " + joined);
}
该方法find接受三个参数:目录路径start是初始起点,并maxDepth定义了要搜索的最大文件夹深度。第三个参数是匹配谓词,它定义搜索逻辑。在上面的示例中,我们搜索所有JavaScript文件(文件名以.js结尾)。
读写文件
List<String> lines = Files.readAllLines(Paths.get("res/nashorn1.js"));
lines.add("print('foobar');");
Files.write(Paths.get("res/nashorn1-modified.js"), lines);
用Java 8将文本文件读入内存并将字符串写入文本文件。这些方法的内存效率不是很高,因为整个文件都将被读取到内存中。文件越大,将使用越多的堆大小。
流
使用流的注意事项
注意,流只能使用一次。
public static void main(String[] args) {
String[] array = {"a", "b", "c", "d", "e"};
Stream<String> stream = Arrays.stream(array);
// 消费流
stream.forEach(x -> System.out.println(x));
// 重用流! throws IllegalStateException
long count = stream.filter(x -> "b".equals(x)).count();
System.out.println(count);
}
正确的使用方式
public static void main(String[] args) {
String[] array = {"a", "b", "c", "d", "e"};
Supplier<Stream<String>> streamSupplier = () -> Stream.of(array);
//获取新的流
streamSupplier.get().forEach(x -> System.out.println(x));
//获取另一个流
long count = streamSupplier.get().filter(x -> "b".equals(x)).count();
System.out.println(count);
}
过滤空值
Stream<String> language = Stream.of("java", "python", "node", null, "ruby", null, "php");
//List<String> result = language.collect(Collectors.toList());
//使用filter过滤空值
List<String> result = language.filter(x -> x!=null).collect(Collectors.toList());
result.forEach(System.out::println);
map映射操作
List<String> alpha = Arrays.asList("a", "b", "c", "d");
//Java8前
List<String> alphaUpper = new ArrayList<>();
for (String s : alpha) {
alphaUpper.add(s.toUpperCase());
}
System.out.println(alpha); //[a, b, c, d]
System.out.println(alphaUpper); //[A, B, C, D]
// Java 8
List<String> collect = alpha.stream().map(String::toUpperCase).collect(Collectors.toList());
System.out.println(collect); //[A, B, C, D]
// map映射操作
List<Integer> num = Arrays.asList(1,2,3,4,5);
List<Integer> collect1 = num.stream().map(n -> n * 2).collect(Collectors.toList());
System.out.println(collect1); //[2, 4, 6, 8, 10]
分组,计数、排序
//3 apple, 2 banana, others 1
List<String> items =
Arrays.asList("apple", "apple", "banana",
"apple", "orange", "banana", "papaya");
Map<String, Long> result =
items.stream().collect(
Collectors.groupingBy(
Function.identity(), Collectors.counting()
)
);
Map<String, Long> finalMap = new LinkedHashMap<>();
//map排序
result.entrySet().stream()
.sorted(Map.Entry.<String, Long>comparingByValue()
.reversed()).forEachOrdered(e -> finalMap.put(e.getKey(), e.getValue()));
System.out.println(finalMap);
总结
本篇文章记录了Stream流操作的一些知识点。来检测一下,以下问题你是不是都会了呢?
- Stream流和集合的区别?
- 解释内部循环和外部循环?
- 解释一下惰性求值?
- Stream的常用操作有哪些?
欢迎来公众号【侠梦的开发笔记】 一起交流进步

