
算法(一)之排序
01-冒泡排序(Bubble Sort)
原理:列表相邻的两个数,如果前面的数比后面的大,则交换这两个数,后面以此类推。
一趟排序完成后,则无序区减少一个数,有序区增加一个数。
也就是说 一趟只能归位一个数,如果有n个数,则需要进行n-1趟归位操作。
时间复杂度:![]()
import random
def bubble_sort(li):
for i in range(len(li)-1):
exchange = False
for j in range(len(li)-i-1):
if li[j] > li[j+1]:
li[j], li[j+1] = li[j+1], li[j]
exchange = True
if not exchange:
return
li = [random.randint(0, 100) for i in range(5)]
print(li)
bubble_sort(li)
print(li)
02-选择排序(Select Sort)
原理:一趟记录最小的数,放到第一个位置,再一趟记录无序区最小的数放到第二个位置。
import random
def select_sort(li):
for i in range(len(li)-1):
min_loc = i
for j in range(i+1, len(li)):
if li[j] < li[min_loc]:
min_loc = j
li[i], li[min_loc] = li[min_loc], li[i]
li = [random.randint(0, 100) for i in range(5)]
select_sort(li)
时间复杂度:![]()
03-插入排序
原理:将一个数据插入到已经排好序的有序数据中,从而得到一个新的、个数加一的有序数据,算法适用于少量数据的排序。
时间复杂度:![]()
def insert_sort(li): for i in range(1, len(li)): tmp = li[i] j = i - 1 while j >= 0 and li[j] > tmp: li[j+1] = li[j] j -= 1 li[j+1] = tmp li = [58, 61, 31, 17, 39] insert_sort(li)
04-快速排序
原理:

def partition(li, left, right): tmp = li[left] while left < right: while left < right and li[right] >= tmp: right -= 1 li[left] = li[right] while left < right and li[left] <= tmp: left += 1 li[right] = li[left] li[left] = tmp return left def quick_sort(li, left, right): if left < right: mid = partition(li, left, right) quick_sort(li, left, mid-1) quick_sort(li, mid+1, right) li = [5, 7, 4, 6, 3, 1, 2, 7, 9, 8] quick_sort(li, 0, len(li)-1) print(li)
05-堆排序
5.1 树的基础知识
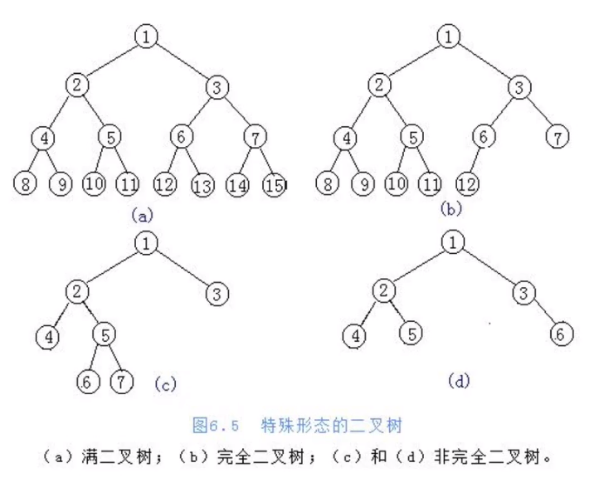
树:是一种数据结构,是一种可以递归定义的数据结构; 由n个节点组成的集合; 如果n=0,那就是一棵空树; 如果n>0,那存在1个节点作为树的根节点,其他节点可以分为m个集合,每个集合本身又是一棵树。 根节点: 叶子结点:度为0的节点,就是没有分叉的节点 树的度:一棵树中,最大的节点的度称为树的度; 孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点; 树的高度或深度:树中节点的最大层次;
5.2 二叉树的基础知识
二叉树:度不超过2的树; 每个节点最多有两个孩子; 两个孩子节点被区分为左孩子节点和右孩子节点; 满二叉树:一个二叉树,如果每一个层的节点数都达到最大值,则这个二叉树就是满二叉树。 完全二叉树:叶结点只能出现在最下层和次下层,并且最下面一层的节点都集中在该层的最左边的若干位置的二叉树。 完全二叉树的特点是: 1)只允许最后一层有空缺结点且空缺在右边,即叶子结点只能在层次最大的两层上出现; 2)对任一结点,如果其右子树的深度为j,则其左子树的深度必为j或j+1。 即度为1的点只有1个或0个
二叉树的性质: 性质1: 在二叉树的第i层上至多有2^(i-1)个结点(i>=1)。 性质2 :深度为 k 的二叉树至多有 2^k-1个结点(k≥1)。 性质3: 对任何一棵二叉树,如果其终端结点数为n0,度为2的结点数为n2,则n0=n2+1。 性质4:具有n个结点的完全二叉树的深度为[log2 n]+1。 性质5: 如果对一棵有n个结点的完全二叉树的结点按层序编号(从第1层到第【log2n】+1层,每层从左到右),则对任一结点i(1<=i<=n),有: 1)如果i=1,则结点i无双亲,是二叉树的根;如果i>1,则其双亲是结点【i/2】。 2)如果2i>n,则结点i为叶子结点,无左孩子;否则,其左孩子是结点2i。 3)如果2i+1>n,则结点i无右孩子;否则,其右孩子是结点2i+1。
二叉树的遍历方式有四种:
第一种:前序遍历。先访问根节点,再访问左子树,最后访问右子树。
第二种:中序遍历。先访问左子树,再访问根节点,最后访问右子树。
第三种:后序遍历。先访问左子树,再访问右子树,最后访问根节点。
第四种:层序遍历。一层层节点依次遍历。
5.3 二叉树的存储方式
顺序存储方式:
完全二叉树:用一组连续的存储单元依次自上而下、自左至右存储各结点元素。即将完全二叉树上编号为i 的结点的值存储在下标为 i-1 的数组元素中。结点间的关系可由公式计算得到。
完全二叉树用顺序存储既节约空间,存取也方便;

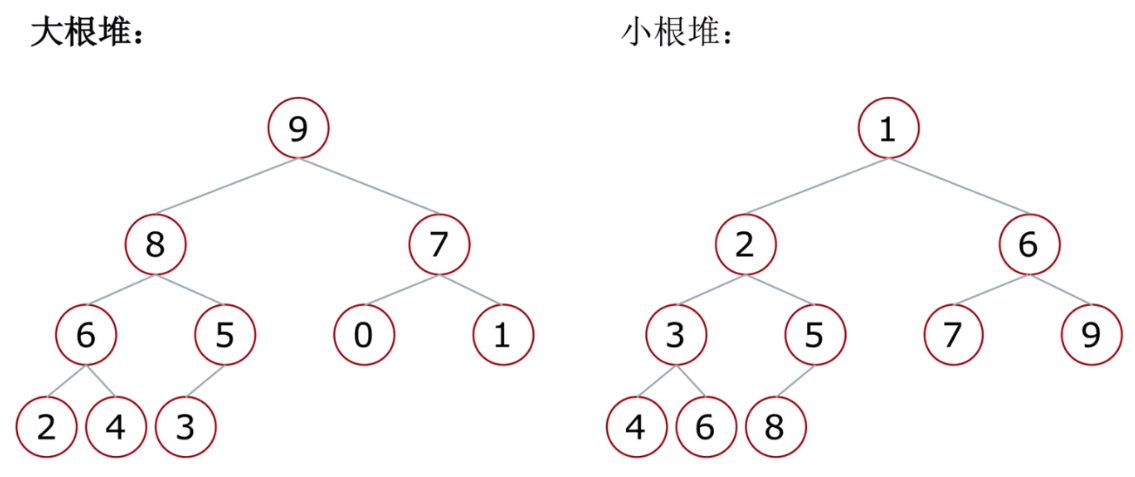
5.4 堆
堆是一种特殊的完全二叉树;
大根堆:一棵完全二叉树,满足任一节点逗比其孩子节点大;
小根堆:一棵完全二叉树,满足任一节点逗比其孩子节点小;
5.5 堆的向下调整
当根节点的左右树都是一个堆时,可以通过一次向下放入调整来将其变换成一个堆。
堆排序的过程: 1. 建立堆; 2. 得到对顶元素,为最大元素; 3. 去掉堆顶,将堆最后的一个元素放到堆顶,此时可通过一次调整重新使堆有序; 4. 堆顶元素为第二大元素; 5. 重复3,直到堆变空。
5.6 堆排序的代码实现
# 堆排序 def sift(li, low, high): """ 在已经是一个堆的前提下,调整函数 :param li: 列表 :param low: 堆的堆顶位置 :param high: 堆的最后一个元素的位置 :return: """ i = low # i最开始指向根节点 j = 2*i+1 # j开始是左孩子 tmp = li[low] # 把堆顶存下来 while j <= high: # 只要j位置有数 if j+1 <= high and li[j+1] > li[j]: # 如果右孩子有,并且比左孩子大 j = j+1 # j指向到右孩子 if li[j] > tmp: # 左孩子比堆顶大 li[i] = li[j] # 用左孩子替换堆顶 i = j j = 2*i+1 else: # tmp更大,把tmp放到i的位置上 li[i] = tmp # 把tmp放到某一级领导的位置上 break else: li[i] = tmp # 把tmp放到叶子结点的上 def head_sort(li): n = len(li) for i in range((n-2)//2, -1, -1): # i代表了建堆的时候调整的部分的根的下标 sift(li, i, n-1) # 建堆完成 for i in range(n-1, -1, -1): # i指向当前堆的最后的一个位置 li[0], li[i] = li[i], li[0] sift(li, 0, i-1) # i-1是新的high li = [i for i in range(100)] import random random.shuffle(li) print(li) head_sort(li) print('堆排序', li)
5.7 堆排序的时间复杂度
O (nlgn)
5.8 堆排序-内置模块
import heapq import random li = [i for i in range(100)] random.shuffle(li) print(li) heapq.heapify(li) # 建小根堆 heapq.heappop(li) # 每次都弹出最小的数
5.9 topk问题
# 问题:现在有n个数,设计算法得到钱k大的数。(k<n) 解决方法: 排序后切片 O(nlogn) 冒泡排序,插入排序,选择排序 O(kn) 堆排序 O(mlogk) 思路: 1. 取列表钱k个元素建立一个小根堆。堆顶就是目前第k大的数; 2. 依次向后遍历原列表,对于列表中的元素,如果小于堆顶,则忽略该元素;如果大于堆顶,则将堆顶更换为该元素,并且对对进行一次调整; 3. 遍历列表所有元素后,倒序弹出堆顶。
# 代码 def sift(li, low, high): """ 在已经是一个堆的前提下,调整函数 :param li: 列表 :param low: 堆的堆顶位置 :param high: 堆的最后一个元素的位置 :return: """ i = low # i最开始指向根节点 j = 2*i+1 # j开始是左孩子 tmp = li[low] # 把堆顶存下来 while j <= high: # 只要j位置有数 if j+1 <= high and li[j+1] < li[j]: # 如果右孩子有,并且比左孩子大 j = j+1 # j指向到右孩子 if li[j] < tmp: # 左孩子比堆顶大 li[i] = li[j] # 用左孩子替换堆顶 i = j j = 2*i+1 else: # tmp更大,把tmp放到i的位置上 li[i] = tmp # 把tmp放到某一级领导的位置上 break else: li[i] = tmp # 把tmp放到叶子结点的上 def topk(li, k): heap = li[0:k] for i in range((k-2)//2, -1, -1): sift(heap, i, k-1) # 1.建堆 for i in range(k, len(li)-1): if li[i] > heap[0]: heap[0] = li[i] sift(heap, 0, k-1) # 2.遍历 for i in range(k-1, -1, -1): # i指向当前堆的最后的一个位置 li[0], li[i] = li[i], li[0] sift(li, 0, i-1) # i-1是新的high # 3.出数 return heap
li = [i for i in range(100)]
import random
random.shuffle(li)
print(topk(li, 10))
06-归并排序
归并排序(merge-sort)是利用归并的思想实现的排序方法,该算法采用经典的分治(divide-and-conquer)策略(分治法将问题分(divide)成一些小的问题然后递归求解,而治(conquer)的阶段则将分的阶段得到的各答案"修补"在一起,即分而治之)。

def merge(li, low, mid, high): i = low j = mid + 1 ltmp = [] while i <= mid and j <=high: if li[i] < li[j]: ltmp.append(li[i]) i += 1 else: ltmp.append(li[j]) j += 1 while i <= mid: ltmp.append(li[i]) i += 1 while j <= high: ltmp.append(li[j]) j += 1 li[low:high+1] = ltmp li = [2, 4, 5, 7, 1, 3, 6, 8] merge(li, 0, 3, 7) print(li)
6.1 使用归并

分解:将列表越分越小,直至分成一个元素;
终止条件:一个元素室友序的;
合并:将两个有序列表归并,列表越来越大。
# 代码 def merge(li, low, mid, high): i = low j = mid + 1 ltmp = [] while i <= mid and j <=high: if li[i] < li[j]: ltmp.append(li[i]) i += 1 else: ltmp.append(li[j]) j += 1 while i <= mid: ltmp.append(li[i]) i += 1 while j <= high: ltmp.append(li[j]) j += 1 li[low:high+1] = ltmp def merge_sort(li, low, high): if low < high: # 至少有两个元素 mid = (low+high)//2 merge_sort(li, low, mid) merge_sort(li, mid+1, high) merge(li, low, mid, high) li = list(range(1000)) import random random.shuffle(li) print(li) merge_sort(li, 0, len(li)-1) print(li)
6.2 归并时间复杂度
O(nlogn)
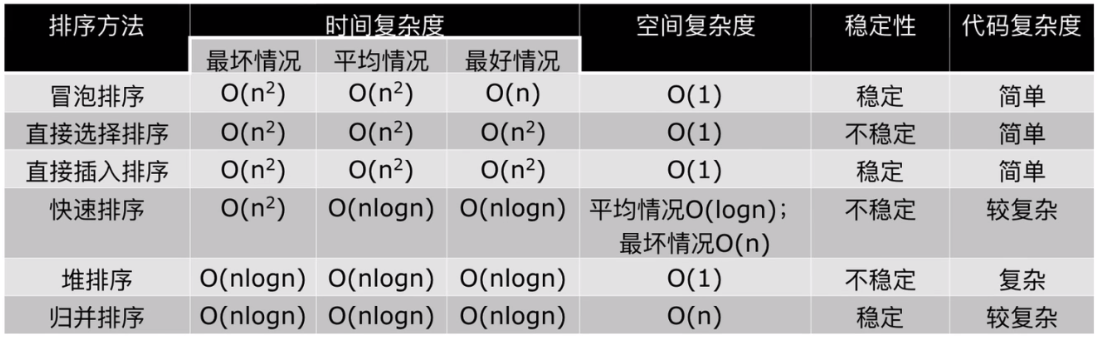
# 小结: 快速排序、归并排序、堆排序 1. 三种排序算法的时间复杂度都是 O(nlogn) 2. 一般情况下,就运行时间而言: 快速排序 < 归并排排序 < 堆排序 3. 三种排序算法的缺点: 快速排序:极端情况下排序效率最低 归并排排序:需要额外的内存开销 堆排序:在快的排序算法中,相对较慢
07-希尔排序
希尔排序(Shell Sort)是插入排序的一种。也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本,
该方法的基本思想是:先将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,
然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,
再对全体元素进行一次直接插入排序。因为直接插入排序在元素基本有序的情况下(接近最好情况),效率是很高的,
因此希尔排序在时间效率比直接插入排序有较大提高。
# 代码def insert_sort_gap(li, gap): for i in range(gap, len(li)): tmp = li[i] j = i - gap while j >= 0 and li[j] > tmp: li[j+gap] = li[j] j -= gap li[j+gap] = tmp def shell_sort(li): d = len(li)//2 while d >= 1: insert_sort_gap(li, d) d //= 2
08-计数排序
运行时间为O(n)
def count_sort(li, max_count=100): count = [0 for _ in range(max_count+1)] for val in li: count[val] += 1 li.clear() for index, val in enumerate(count): for i in range(val): li.append(index)
09-桶排序
首先将元素分布在不同的桶中,在对每个桶中的元素排序。

10-基数排序
时间复杂度:O(kn)
空间复杂度:O(k+n)
# 基数排序 def radix_sort(li): max_num = max(li) it = 0 while 10 ** it <= max_num: buckets = [[] for i in range(10)] for var in li: digit = (var // 10 ** it) % 10 buckets[digit].append(var) # 分桶完成 li.clear() for buc in buckets: li.extend(buc) # 把数重新写回li it += 1 import random li = list(range(1000)) random.shuffle(li) print(li) radix_sort(li) print(li)
11-相关习题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号