链表
一. 什么是链表(Linked list)
- 和数组一样,链表也是一种线性表。
- 从内存来看,链表与数组的区别在于存储不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用。
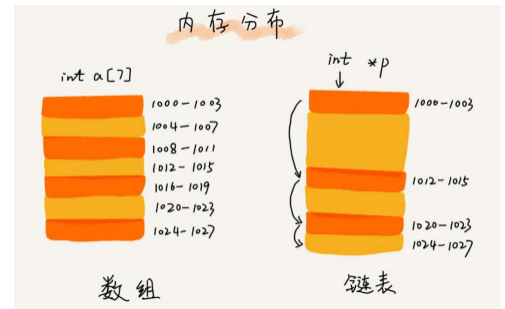
-
一般把每个零散的内存块称为链表的“结点”,为了将所有的结点串起来,每个链表的结点除了存储数据之外,还需要记录链上的下一个结点的位置,一般把这个记录下个结点地址的指针叫作后继指针next。
-
常见链表结构:单链表、双向链表、循环链表。
二. 链表的特点
-
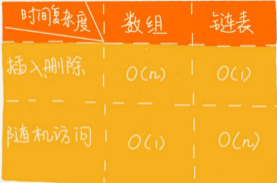
插入、删除操作高效,时间复杂度是O(1)。高效原因在于:链表中插入或者删除一个数据并不需要像数组一样为了保持内存的连续性而搬移结点。
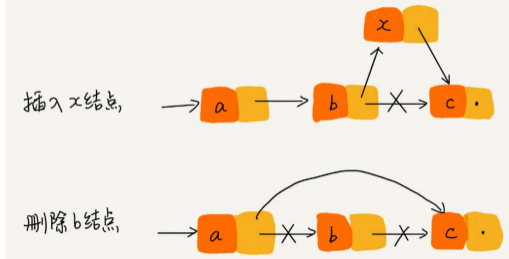
-
随机访问元素低效,时间复杂度是O(n)。低效原因在于:链表中数据并非连续存储,无法像数组那样根据首地址和下标,通过寻址公式就能直接计算出对应的内存地址,而是需要根据指针一个结点一个结点依次遍历。
三. 常见链表
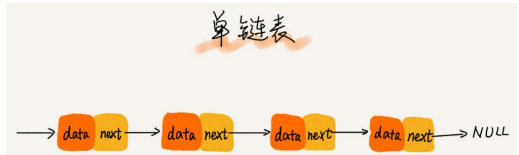
单链表
- 每个结点只包含一个指针,即后继指针。
- 两个特殊结点,头结点和尾结点。头结点是第一个结点,用来记录链表的基地址,有了它就可以遍历得到整条链表。尾结点是最后一个结点,它的后继指针指向一个空地址NULL。
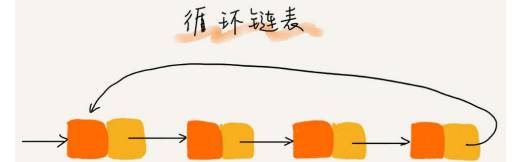
循环链表
-
循环链表是一种特殊的单链表。和单链表唯一的区别在于尾结点,循环链表的尾结点指针是指向链表的头结点。
-
和单链表相比,循环链表的优点是从链尾到链头比较方便。当要处理的数据具有环型结构特点时,就特别适合采用循环链表,比如约瑟夫问题。
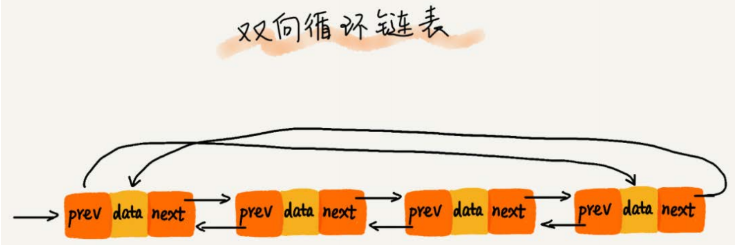
双向链表
-
单链表只有一个方向,结点只有一个后继结点next指向后面的结点。而双向链表支持两个方向,每个结点除了后继指针next指向后面的结点,还有一个前驱结点prev指向前面的结点。所以双向链表支持双向遍历。
-
双向链表首结点的前驱指针prev和尾结点的后继指针next均指向空地址NULL。
-
性能特点:
-
内存消耗比单链表高。
-
插入、删除操作比单链表效率更高,时间复杂度是O(1)。以删除为例,删除操作分为两种情况:给定数据值删除对应节点和给定节点地址删除节点。对于第一种情况,单链表和双向链表都需要从头遍历找到对应节点进行删除,加上查找定位的删除时间复杂度是O(n)。对于第二种情况,要进行删除操作必须找到前驱结点,单链表需要从头遍历找到节点p->next=q,时间复杂度是O(n);而双向链表可以根据前驱指针直接找到前驱结点,时间复杂度是O(1)。可以看到,虽然二者的删除时间复杂度都是O(1),但是加上寻找定位的时间复杂度,双向链表明显更优。
-
四. 链表和数组对比
1. 时间复杂度
2. 数组优缺点
- 优点:简单易用,实现上使用连续的内存空间,可以借助CPU缓存机制预读数组中的数据,访问效率更高。
- 缺点:大小固定,一经声明就要占用整块连续内存空间。如果声明数组过大,会导致内存不足(out of memory);如果声明数组过小,可能出现不够用情况,需要扩容,非常耗时。
3. 链表优缺点
- 优点:链表本身没有大小限制,天然支持动态扩容。
- 缺点:链表需要消耗额外存储空间来存储结点的指针,内存消耗会翻倍。对链表进行频繁的插入、删除操作,会导致频繁的内存申请和释放,容易造成内存碎片,可能会导致频繁的GC(Garbage Collection,垃圾回收)。
五. 如何更好的写出链表代码
- 理解指针或引用的含义:将某个变量赋值给指针,实际上就是将这个变量的地址赋值给指针。反过来说,指针中存储了这个变量的内存地址,指向了这个变量,通过指针就能找到这个变量。如:p->next=q,p结点中的next指针存储了q结点的内存地址。
- 警惕指针内存丢失和内存泄露:
-
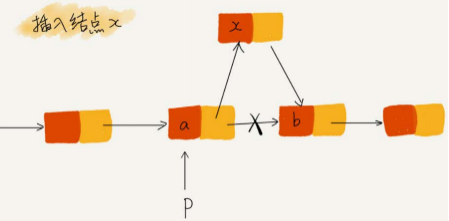
插入结点:在结点a和相邻的结点b之间插入结点x,假设当前指针p指向结点a。如果我们将代码实现变成下面这个样子,就会发生指针丢失和内存泄露。
-
1 p->next = x; // 将p的next指针指向x结点
2 x->next = p->next; // 将x的结点的next指针指向b结点
p->next指针在完成第一步操作之后,已经不再指向结点b了,而是指向结点x。第2行代码相当于将x赋值给x->next,自己指向自己。因此,整个链表也就断成了两半,从结点b往后的所有结点都无法访问到了。正确做法:
1 x->next = p->next; // 将x的结点的next指针指向b结点
2 p->next = x; // 将p的next指针指向x结点
-
利用哨兵简化实现难度:
-
- 什么是哨兵:链表中的哨兵结点是解决边界问题的,不参与业务逻辑。若引入哨兵结点,则不管链表是否为空,head指针都会指向这个哨兵结点,称为带头链表。
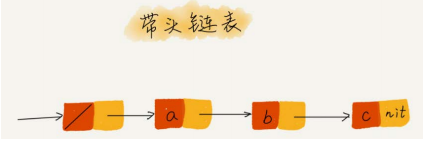
-
- 未引入哨兵的情况:
1 # 在p结点后插入一个结点
2 new_node->next = p->next
3 p->next = new_node
4
5 # 要判断是否空链表插入
6 if(head == null){ head = new_node }
7
8 # 删除结点p的后继结点
9 p->next = p->next->next
10
11 # 要判断删除的是否链表最后一个结点(链表只剩这个结点)
12 if(head->next == null){ head = null }
可以看到,针对链表的插入、删除操作,需要对插入的第一个结点和删除最后一个结点的情况进行特殊处理,显得繁琐,可以引入哨兵结点来解决问题。
-
- 引进哨兵的情况:
class Node(object): # 结点对象
def __init__(self, data, next_node=None):
self.data = data
self.next_node = next_node
class SingleLinkedList(object): # 单链表对象,属于带头链表
def __init__(self):
self.head = None # 头指针
self._head = Node(None) # 哨兵结点,不存储数据
self.head = self._head # 头指针一直指向哨兵结点
# 在p结点后插入一个结点
new_node.next_node = p.next_node
p.next_node = new_node
# 删除结点p的后继结点。当链表只剩一个结点时候也适用
p.next_node = p.next_node.next_node
在这段代码里,插入结点的第13、14行代码在当是空链表时候也适用,因为头指针指向的是头结点,也存在next_node属性。而删除结点操作的17行代码在当链表只剩下一个结点时也适用,设最后一个结点为n,此时p即为头指针,p.next_node为头结点_head,p.next_node.next_node则为n,第17行代码执行结果为头结点 _head.next_node=null,执行结果正确。
-
重点留意边界条件处理
经常用来检查链表是否正确的边界4个边界条件:
1.如果链表为空时,代码是否能正常工作?
2.如果链表只包含一个节点时,代码是否能正常工作?
3.如果链表只包含两个节点时,代码是否能正常工作?
4.代码逻辑在处理头尾节点时是否能正常工作? -
画图思考
六. 链表习题与代码实现
1. python 实现单链表
class Node(object): # 结点对象
def __init__(self, data, next_node=None):
self._data = data
self._next_node = next_node # 后继结点
@property
def data(self):
# @property修饰,data相当于_data的代理,该函数类比Node.get_data(),不过可以直接Node.data方式调用,方法转属性.
return self._data
@data.setter
def data(self, data):
# 由上@property修饰器生成@data.setter,该函数类比Node.set_data(),不过可以直接Node.data=xx方式使用.
self._data = data
@property
def next_node(self):
return self._next_node
@next_node.setter
def next_node(self, next_node):
self._next_node = next_node
def __str__(self):
next_data = str(self._next_node.data) if self._next_node != None else "None"
return "data:" + str(self._data) + " next_node:" + next_data
class SingleLinkedList(object):
def __init__(self):
self._head = None # 头指针
self._tail = None # 尾指针
self.len = 0
def find_by_value(self, value):
'''
根据值查找链表中结点
:param value:
:return: Node
'''
if self.len == 0:
return None
if self._tail.data == value:
return self._tail
tmp = self._tail.data
self._tail.data = value # 设立哨兵
node = self._head
while node.data != value: # 因为有哨兵,这里每次循环都少做一次判断(是否已经到链表尾部),如果链表很长就能提高一些性能
node = node.next_node
self._tail.data = tmp
if node != self._tail:
return node
else:
return None
def find_by_index(self, index):
'''
根据索引查找链表中结点
:param index:
:return: Node
'''
index = (self.len + index) % self.len # 和长度相加再取模,可以支持负数的操作,如index=-1
if index >= self.len or index < 0:
raise IndexError("singleLinkedList index out of range...")
if self.len == 0:
return None
pos = 0
node = self._head
while pos != index:
node = node.next_node
pos += 1
return node
def insert_to_head(self, data):
'''
头部插入节点.分两种情况,一是链表为空,二是链表不为空
:param data:
:return:
'''
node = Node(data)
if self.len == 0:
self._tail = node
node.next_node = self._head
self._head = node
self.len += 1
def append(self, data):
'''
链表尾部添加结点
:param data:
:return:
'''
node = Node(data)
if self.len == 0:
self._head = node
self._tail = node
else:
self._tail.next_node = node
self._tail = node
self.len += 1
def insert(self, node, data):
'''
插入
:param node: 在这个结点后面插入新结点
:param data: 新结点的存储值
:return:
'''
if node is None:
return
new_node = Node(data)
new_node.next_node = node.next_node
node.next_node = new_node
self.len += 1
def delete_by_index(self, index):
'''
根据索引删除链表中结点
:param index:
:return:
'''
node = self.find_by_index(index)
if node:
if node == self._head:
self._head = node.next_node
else:
pre_node = self.find_by_index(index - 1)
pre_node.next_node = node.next_node
if pre_node.next_node is None:
self._tail = pre_node
self.len -= 1
def delete_by_value(self, value):
'''
根据值删除链表中结点,从头遍历,找到第一个等于该值的结点并删除
:param value:
:return:
'''
node = self.find_by_value(value)
if node:
if node == self._head:
self._head = node.next_node
else:
pre_node = self._head
while pre_node.next_node != node:
pre_node = pre_node.next_node
pre_node.next_node = node.next_node
if pre_node.next_node is None:
self._tail = pre_node
self.len -= 1
def delete_by_node(self, node):
'''
删除结点
:param node:
:return:
'''
if self.len == 0:
return
if node:
if node == self._head:
self._head = node.next_node
else:
pre_node = self._head
while pre_node.next_node != node:
pre_node = pre_node.next_node
pre_node.next_node = node.next_node
if pre_node.next_node is None:
self._tail = pre_node
self.len -= 1
def __str__(self):
if self.len == 0:
return None
node = self._head
res = ''
while node.next_node is not None:
res = res + str(node.data) + '->'
node = node.next_node
res = res + str(node.data) + '->None; len:' + str(self.len)
return res