

文件读写笔记
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
|
f.close() |
关闭文件,记住用open()打开文件后一定要记得关闭它,否则会占用系统的可打开文件句柄数。 |
|
f.fileno() |
获得文件描述符,是一个数字 |
|
f.flush() |
刷新输出缓存 |
|
f.isatty() |
如果文件是一个交互终端,则返回True,否则返回False。 |
|
f.read([count]) |
读出文件,如果有count,则读出count个字节。 |
|
f.readline() |
读出一行信息。 |
|
f.readlines() |
读出所有行,也就是读出整个文件的信息。 |
|
f.seek(offset[,where]) |
把文件指针移动到相对于where的offset位置。where为0表示文件开始处,这是默认值 ;1表示当前位置;2表示文件结尾。 |
|
f.tell() |
获得文件指针位置。 |
|
f.truncate([size]) |
截取文件,使文件的大小为size。 |
|
f.write(string) |
把string字符串写入文件。 |
|
f.writelines(list) |
把list中的字符串一行一行地写入文件,是连续写入文件,没有换行。 |
将xlsx文件转为csv
import pandas as pd def xlsx_to_csv_pd(): data_xls = pd.read_excel('D:\Python作业\Python成绩登记信计.xlsx', index_col=0) data_xls.to_csv('D:\Python作业\成绩登记表1.csv', encoding='gbk') if __name__ == '__main__': xlsx_to_csv_pd()
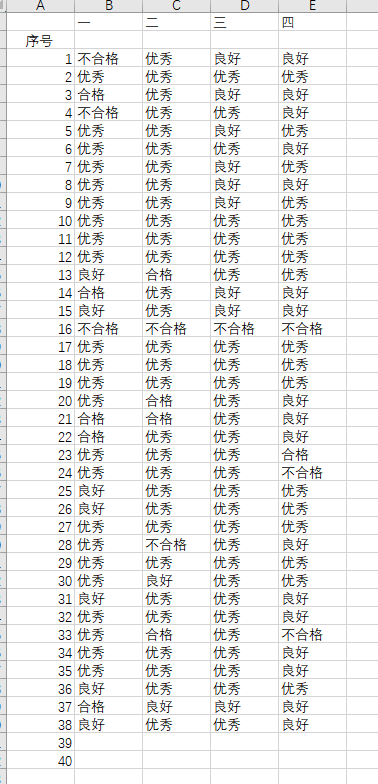
将优秀,良好,合格,不合格 替换为90分,80分,60分,0分
import os import os.path csvpath=os.getcwd()+"\\" f=open('D:\Python作业\成绩登记表.csv',encoding="gbk") content = f.read() f.close() t = content.replace("优秀","90分") t = content.replace("良好","80分") t = content.replace("合格","60分") t = content.replace("不合格","0分") with open("D:\Python作业\成绩登记表.csv","w",encoding='gbk') as f1: f1.write(t)
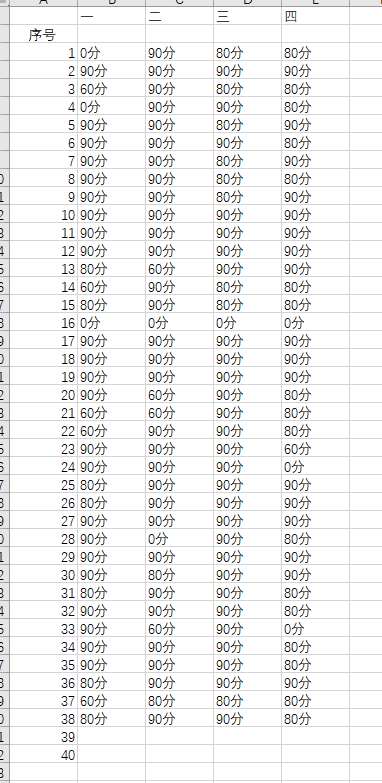
将csv文件转换为HTML文件
seg1=''' <!DOCTYPE HTML>\n<html>\n<body>\n<meta charset=gb> <h2 align=center>成绩登记表</h2> <table border='1' align="center" width=70%> <tr bgcolor='orange'>\n''' seg2="</tr>\n" seg3="</table>\n<body>\n</html>" def fill_data(locls): seg='<st><td align="center">{}</td><td align="center">\ {}</td><td align="center">{}</td><tdalign="center">\ {}</td></tr>\n'.format(*locls) return seg fr=open("D:\Python作业/成绩登记表.csv","r") ls=[] for line in fr: line=line.replace("\n","") ls.append(line.split(",")) fr.close() fw=open("D:\Python作业/成绩登记表.csv.html","w") fw.write(seg1) fw.write('''<th width="25%">{}</th>\n<th width="25%">{}</th>\n<th width="25%">{}</th>\n<th width="25%">{}</th>\n'''.format(*ls[10])) fw.write(seg2) for i in range(len(ls)-1): fw.write(fill_data(ls[i+1])) fw.write(seg3) fw.close()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号