第三章:ES分词简单说明
1.
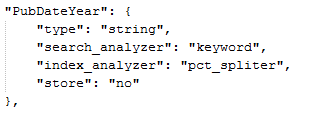
Index_Analyzer为索引时使用的分词器,search_Analyzer为搜索时使用的分词器
这个索引,对应的数据是下图:

数据格式是用%分隔的年份,"index_analyzer": "pct_spliter"分词是将这条数据索引时用%分隔掉,拆成2006和2003两个,聚类的时候会分别计数到2006和2003里一次;
"search_analyzer": "keyword"是搜索时用keyword英文分词形式将检索条件分隔,具体keyword分词算法我也不清楚,我们项目里,一般是将数字、英文字符这样的数据用keyword,那么在检索PubDateYear:2006时,凡是PubDateYear里出现“2006”的,都能检索到;
2.
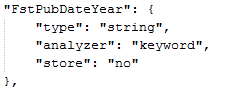
该索引对应的数据格式为:

数据格式仅为单个的年份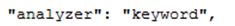 ,的写法就相当于"index_analyzer": " keyword ";"search_analyzer": "keyword"的简化写法,分词功能同上述
,的写法就相当于"index_analyzer": " keyword ";"search_analyzer": "keyword"的简化写法,分词功能同上述
3.

英文字段的索引,simple_english_analyzer分词是基于空格的简单英文分词,数据如下:

没有特殊分隔符的英文数据,检索字段包含的任意一个单词或者双引号包含的连续几个单词,都会命中该条记录;
4.

英文字段的索引,custom_snowball_analyzer分词算法跟simple_english_analyzer类似,我们的项目中是用来索引作者英文姓名字段的,这两个的具体区别不是太清楚,可以查查Lucene里的具体算法
custom_snowball_analyzer是针对西欧多种语言的分词,(记着是这样的),作者字段用这个,是担心作者名字并非全部都是英文的
5.
Mapping中的En开头的索引都是废弃不用的,他们使用的ik分词是中文分词,类似于keyword分词使用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号