spider【第七篇】Scrapy基本操作
通过前面的学习,我们已经能够解决90%的爬虫问题了,那么scrapy是为了解决剩下的10%的问题么,不是,scrapy框架能够让我们的爬虫效率更高
官方文档 https://scrapy-chs.readthedocs.io/zh_CN/latest/
why scrapy
爬虫是IO密集型任务,因此采用异步IO方式网络通讯效率高,scrapy内置twisted用于下载页面
scrapy可加入requests和beautifulsoup库
scrapy是框架,requests和beautifulsoup是库
scrapy方便扩展,提供了很多内置功能
scrapy内置xpath和css选择器很方便,beautifulsoup最大的缺点就是慢
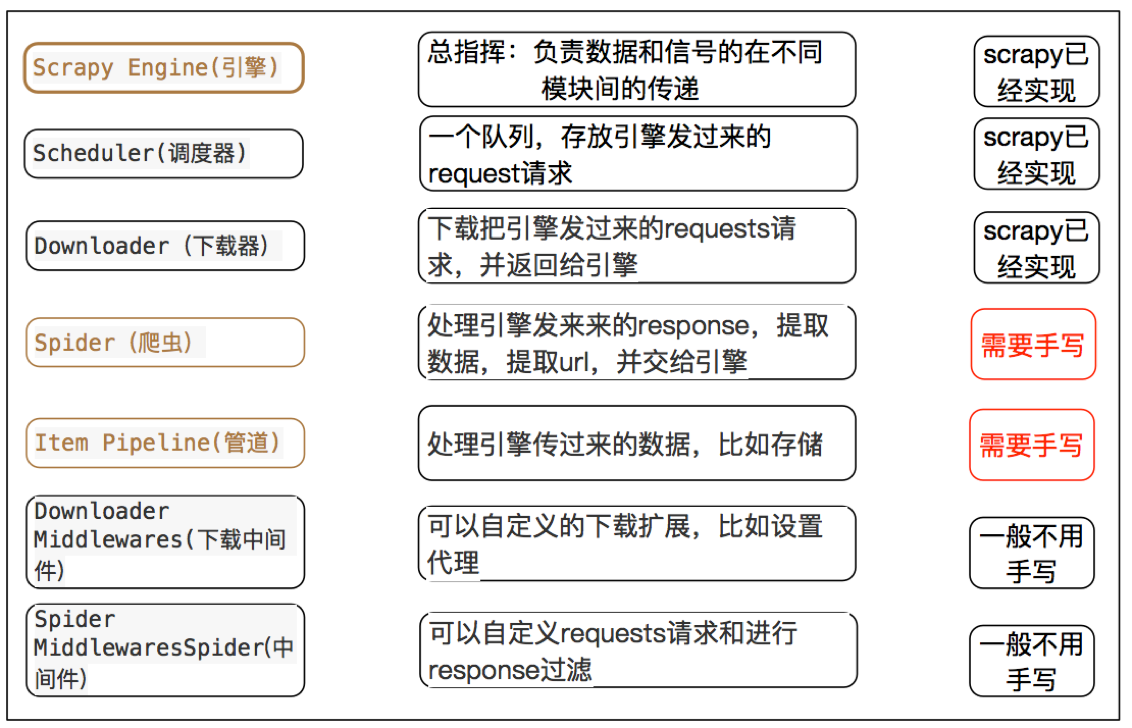
scrapy框架介绍
借鉴django设计理念
应用twisted,下载页面
HTML解析对象
代理
延迟下载
去重
深度,广度
爬虫流程
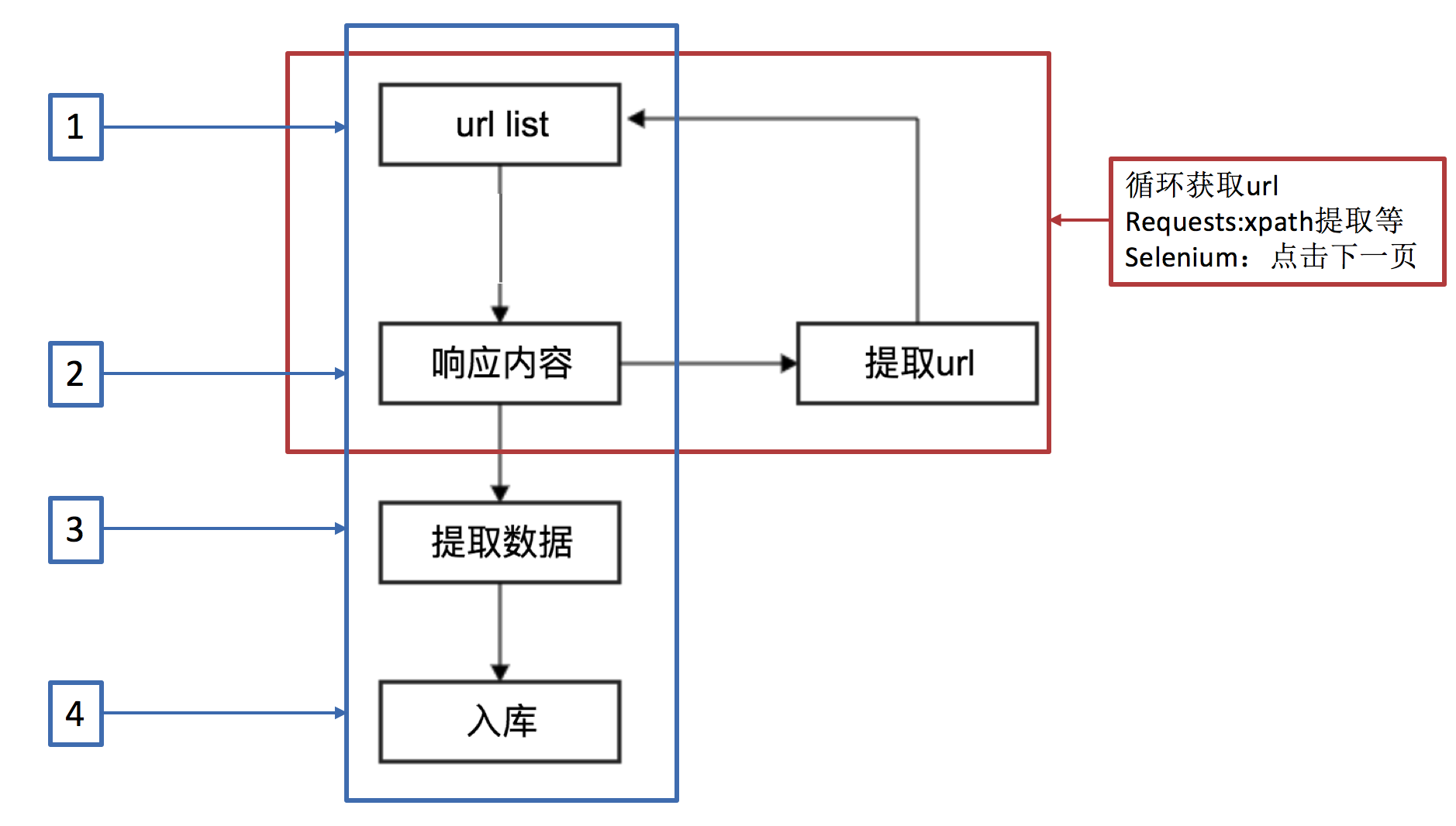
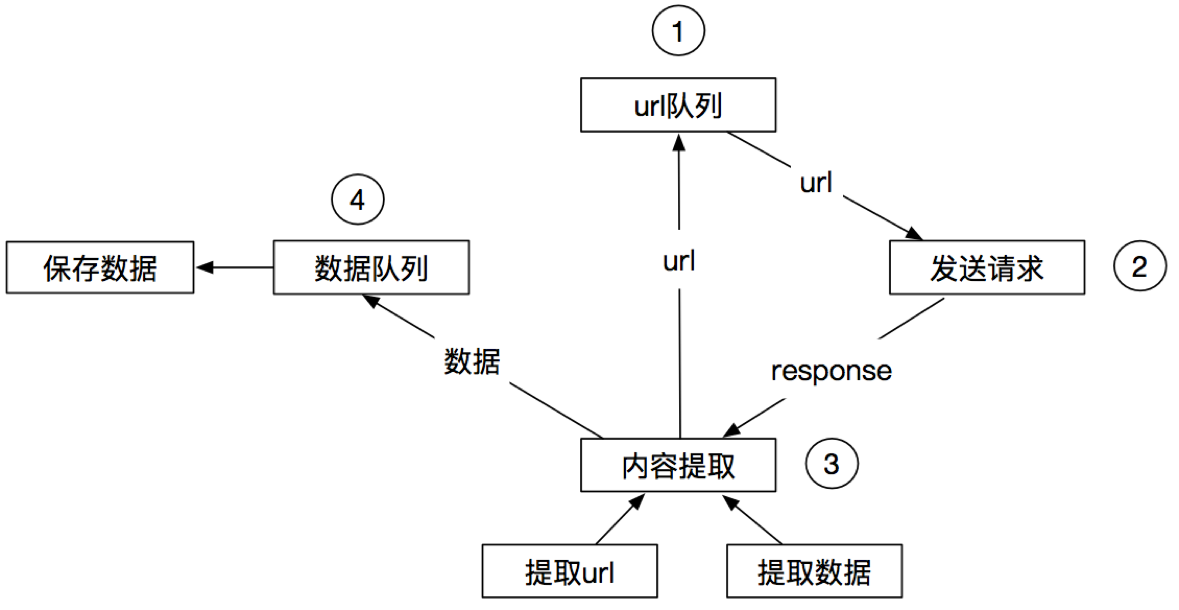
Scrapy运行流程
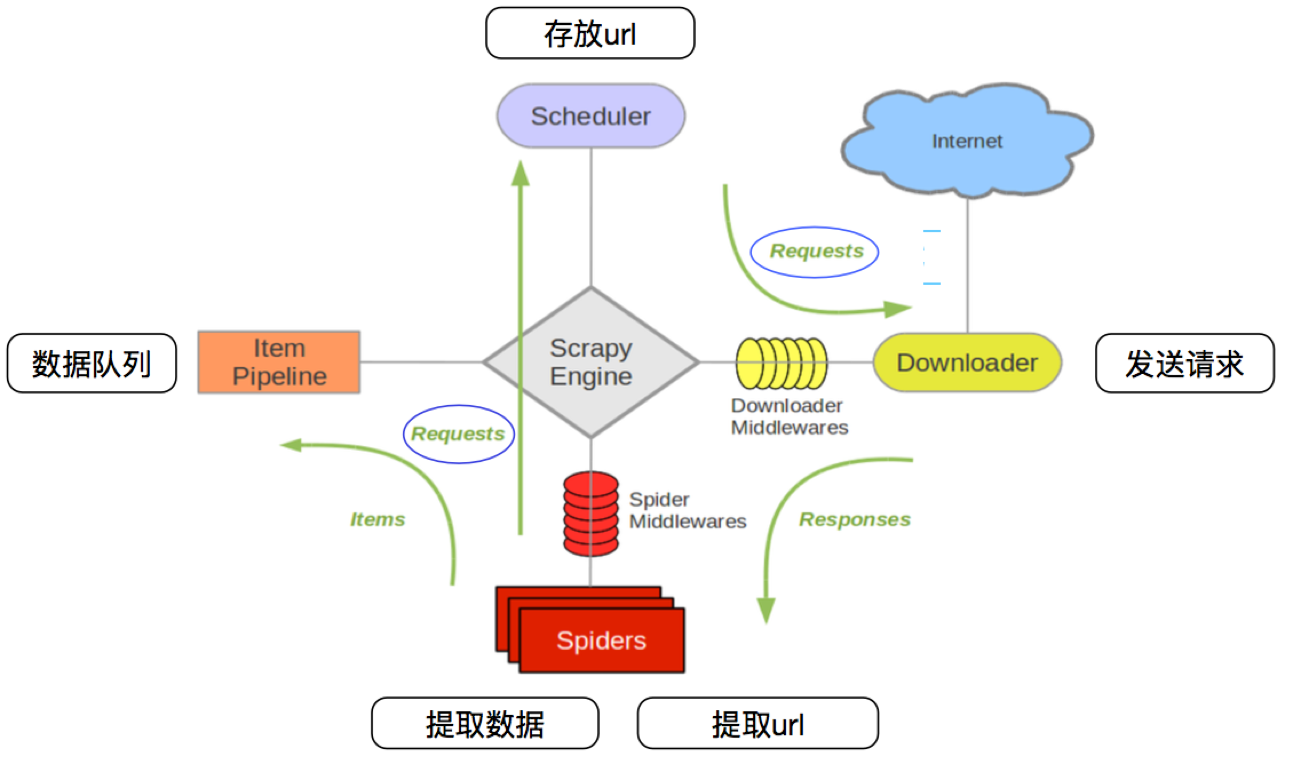
其流程可以描述如下: 调度器把requests-->引擎-->下载中间件--->下载器 下载器发送请求,获取响应---->下载中间件---->引擎--->爬虫中间件--->爬虫 爬虫提取url地址,组装成request对象---->爬虫中间件--->引擎--->调度器 爬虫提取数据--->引擎--->管道 管道进行数据的处理和保存
scrapy中每个模块的具体作用
项目结构
project_name/
scrapy.cfg
project_name/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
爬虫1.py
爬虫2.py
爬虫3.py
文件说明:
scrapy.cfg 项目的主配置信息。(真正爬虫相关的配置信息在settings.py文件中)
items.py 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines 数据处理行为,如:一般结构化的数据持久化
settings.py 配置文件,如:递归的层数、并发数,延迟下载等
spiders 爬虫目录,如:创建文件,编写爬虫规则
创建scrapy项目
创建虚拟环境
mkvirtualenv article_spider
安装scrapy
twisted不是很完美支持scrapy,需要重新安装twisted
pip install -i https://pypi.douban.com/simple scrapy
创建工程
scrapy startproject ArticleSpider
创建爬虫
scrapy genspider jobbole blog.jobbole.com
调试scrapy
pycharm调试
项目目录下新建文件如main.py,添加
import sys import os from scrapy.cmdline import execute sys.path.append(os.path.dirname(os.path.abspath(__file__))) execute(["scrapy", "crawl", "jobbole"])
scrapy的debug信息
每次程序启动后,默认情况下,终端都会出现很多的debug信息,那么下面我们来简单认识下这些信息

scrapy shell调试
scrapy shell是scrapy提供的一个终端工具,能够通过它查看scrapy中对象的属性和方法,以及测试xpath
response.url:当前响应的url地址
response.request.url:当前响应对应的请求的url地址
response.headers:响应头
response.body:响应体,也就是html代码,默认是byte类型
response.requests.headers:当前响应的请求头
eg:
scrapy shell http://blog.jobbole.com/110287/
css语法
title = response.css(".entry-header h1::text").extract_first()
xpath语法
title = response.xpath("//div[@class='entry-header']/h1/text()").extract_first()
title '2016 腾讯软件开发面试题(部分)'
item/pipeline
用于数据保存、去重等操作
使用默认pipeline保存图片


# -*- coding: utf-8 -*- import re import datetime import scrapy from scrapy.http import Request from urllib import parse from ArticleSpider.items import ArticleItem from ArticleSpider.utils.common import get_md5 class JobboleSpider(scrapy.Spider): name = 'jobbole' allowed_domains = ['blog.jobbole.com'] start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response): """ 1. 获取文章列表页中的文章url并交给scrapy下载后并进行解析 2. 获取下一页的url并交给scrapy进行下载, 下载完成后交给parse """ # 解析列表页中的所有文章url并交给scrapy下载后并进行解析 post_nodes = response.css("#archive .floated-thumb .post-thumb a") for post_node in post_nodes: image_url = post_node.css("img::attr(src)").extract_first("") post_url = post_node.css("::attr(href)").extract_first("") yield Request(url=parse.urljoin(response.url, post_url), meta={"front_image_url": image_url}, callback=self.parse_detail) # meta把上一个url的内容传到下一个url # urljoin作用:url有域名不加域名,没有域名则添加域名 # 提取下一页并交给scrapy进行下载 next_url = response.css(".next.page-numbers::attr(href)").extract_first("") if next_url: yield Request(url=parse.urljoin(response.url, next_url), callback=self.parse) def parse_detail(self, response): # 通过css选择器提取字段 front_image_url = response.meta.get("front_image_url", "") # 文章封面图 title = response.css(".entry-header h1::text").extract()[0] create_date = response.css("p.entry-meta-hide-on-mobile::text").extract()[0].strip().replace("·", "").strip() praise_nums = response.css(".vote-post-up h10::text").extract()[0] fav_nums = response.css(".bookmark-btn::text").extract()[0] match_re = re.match(".*?(\d+).*", fav_nums) if match_re: fav_nums = int(match_re.group(1)) else: fav_nums = 0 comment_nums = response.css("a[href='#article-comment'] span::text").extract()[0] match_re = re.match(".*?(\d+).*", comment_nums) if match_re: comment_nums = int(match_re.group(1)) else: comment_nums = 0 content = response.css("div.entry").extract()[0] tag_list = response.css("p.entry-meta-hide-on-mobile a::text").extract() tag_list = [element for element in tag_list if not element.strip().endswith("评论")] tags = ",".join(tag_list) # item功能 article_item = ArticleItem() # 实例化item article_item["url_object_id"] = get_md5(response.url) article_item["title"] = title article_item["url"] = response.url try: create_date = datetime.datetime.strptime(create_date, "%Y/%m/%d").date() except Exception as e: create_date = datetime.datetime.now().date() article_item["create_date"] = create_date article_item["front_image_url"] = [front_image_url] article_item["praise_nums"] = praise_nums article_item["comment_nums"] = comment_nums article_item["fav_nums"] = fav_nums article_item["tags"] = tags article_item["content"] = content yield article_item # yield之后item传递到pipeline中
class ArticleItem(scrapy.Item): title = scrapy.Field() create_date = scrapy.Field() url = scrapy.Field() url_object_id = scrapy.Field() front_image_url = scrapy.Field() praise_nums = scrapy.Field() comment_nums = scrapy.Field() fav_nums = scrapy.Field() tags = scrapy.Field() content = scrapy.Field()
ITEM_PIPELINES = { # 'ArticleSpider.pipelines.ArticlespiderPipeline': 300, 'scrapy.pipelines.images.ImagesPipeline': 1, # 打开images pipelines } IMAGES_URLS_FIELD = "front_image_url" # 要保存的item project_dir = os.path.dirname(__file__) IMAGES_STORE = os.path.join(project_dir, 'images') # images保存路径project_dir/images
自定义pipeline得到图片本地保存路径
class ArticleItem(scrapy.Item): title = scrapy.Field() create_date = scrapy.Field() url = scrapy.Field() url_object_id = scrapy.Field() front_image_url = scrapy.Field() front_image_path = scrapy.Field() praise_nums = scrapy.Field() comment_nums = scrapy.Field() fav_nums = scrapy.Field() tags = scrapy.Field() content = scrapy.Field()
from scrapy.pipelines.images import ImagesPipeline class ArticleImagePipeline(ImagesPipeline): def item_completed(self, results, item, info): if "front_image_url" in item: for ok, value in results: image_file_path = value["path"] item["front_image_path"] = image_file_path return item
ITEM_PIPELINES = { # 'ArticleSpider.pipelines.ArticlespiderPipeline': 300, 'ArticleSpider.pipelines.ArticleImagePipeline': 1, } IMAGES_URLS_FIELD = "front_image_url" # 要保存的item project_dir = os.path.dirname(__file__) IMAGES_STORE = os.path.join(project_dir, 'images') # images保存路径project_dir/images
保存item到json文件
自定义json文件的导出
import codecs import json from datetime import datetime, date # 解决日期类型不能序列化 class DateEncoder(json.JSONEncoder): def default(self, obj): # if isinstance(obj, datetime.datetime): # return int(mktime(obj.timetuple())) if isinstance(obj, datetime): return obj.strftime('%Y-%m-%d %H:%M:%S') elif isinstance(obj, date): return obj.strftime('%Y-%m-%d') else: return json.JSONEncoder.default(self, obj) class JsonWithEncodingPipeline(object): # 自定义json文件的导出 def __init__(self): self.file = codecs.open('article.json', 'w', encoding="utf-8") def process_item(self, item, spider): lines = json.dumps(dict(item),cls=DateEncoder, ensure_ascii=False) + "\n" self.file.write(lines) return item def spider_closed(self, spider): self.file.close()
ITEM_PIPELINES = { 'ArticleSpider.pipelines.JsonWithEncodingPipeline': 2, }
调用scrapy提供的json export导出json文件
import codecs import json class JsonExporterPipleline(object): # 调用scrapy提供的json export导出json文件 def __init__(self): self.file = open('articleexport.json', 'wb') self.exporter = JsonItemExporter(self.file, encoding="utf-8", ensure_ascii=False) self.exporter.start_exporting() def close_spider(self, spider): self.exporter.finish_exporting() self.file.close() def process_item(self, item, spider): self.exporter.export_item(item) return item
ITEM_PIPELINES = { 'ArticleSpider.pipelines.JsonExporterPipleline': 1, }
通过pipeline保存数据到mysql
安装mysql驱动
pip install mysqlclient
设计表
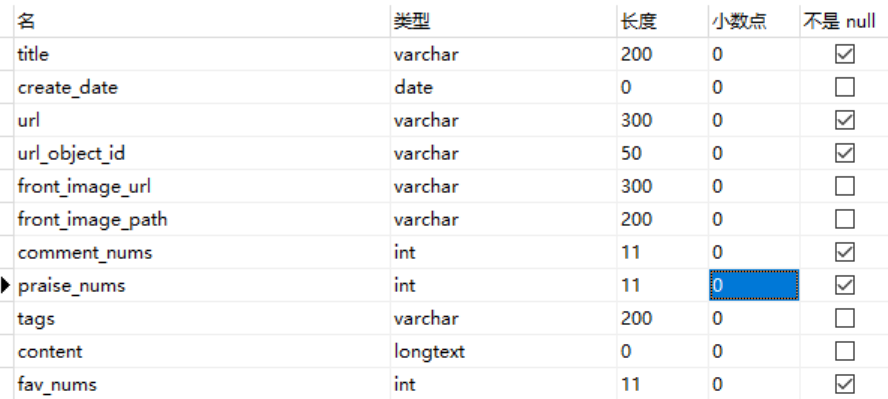
采用同步的机制写入mysql
缺点:写入速度跟不上页面解析速度会阻塞
import MySQLdb import MySQLdb.cursors class MysqlPipeline(object): # 采用同步的机制写入mysql def __init__(self): self.conn = MySQLdb.connect('127.0.0.1', 'root', 'root', 'article_spider', charset="utf8", use_unicode=True) self.cursor = self.conn.cursor() def process_item(self, item, spider): insert_sql = """ insert into jobbole_article(title, url, create_date, fav_nums) VALUES (%s, %s, %s, %s) """ self.cursor.execute(insert_sql, (item["title"], item["url"], item["create_date"], item["fav_nums"])) self.conn.commit()
ITEM_PIPELINES = { 'ArticleSpider.pipelines.MysqlPipeline': 2, }
使用twisted将mysql插入变成异步执行
import MySQLdb import MySQLdb.cursors from twisted.enterprise import adbapi class MysqlTwistedPipline(object): def __init__(self, dbpool): self.dbpool = dbpool @classmethod def from_settings(cls, settings): dbparms = dict( host=settings["MYSQL_HOST"], db=settings["MYSQL_DBNAME"], user=settings["MYSQL_USER"], passwd=settings["MYSQL_PASSWORD"], charset='utf8', cursorclass=MySQLdb.cursors.DictCursor, use_unicode=True, ) dbpool = adbapi.ConnectionPool("MySQLdb", **dbparms) return cls(dbpool) def process_item(self, item, spider): # 使用twisted将mysql插入变成异步执行 query = self.dbpool.runInteraction(self.do_insert, item) query.addErrback(self.handle_error, item, spider) # 处理异常 def handle_error(self, failure, item, spider): # 处理异步插入的异常 print(failure) def do_insert(self, cursor, item): insert_sql = """ insert into jobbole_article(title, url, create_date, fav_nums) VALUES (%s, %s, %s, %s) """ cursor.execute(insert_sql, (item["title"], item["url"], item["create_date"], item["fav_nums"]))
ITEM_PIPELINES = { 'ArticleSpider.pipelines.MysqlTwistedPipline': 1, } MYSQL_HOST = "127.0.0.1" MYSQL_DBNAME = "article_spider" MYSQL_USER = "root" MYSQL_PASSWORD = "root"
item loader
why item loader
spider只负责提取内容,其它处理逻辑交给item,spider职责更清晰作为爬取主逻辑代码少,通用性更强(适合更多的item处理)
几个重要的方法
item_loader.add_css item_loader.add_xpath item_loader.add_value
自定义item loader
import datetime import re import scrapy from scrapy.loader import ItemLoader from scrapy.loader.processors import MapCompose, TakeFirst, Join, Identity def date_convert(value): try: create_date = datetime.datetime.strptime(value, "%Y/%m/%d").date() except Exception as e: create_date = datetime.datetime.now().date() return create_date def get_nums(value): match_re = re.match(".*?(\d+).*", value) if match_re: nums = int(match_re.group(1)) else: nums = 0 return nums def remove_comment_tags(value): #去掉tag中提取的评论 if "评论" in value: return "" else: return value class ArticleItemLoader(ItemLoader): #自定义itemloader default_output_processor = TakeFirst() # 取得数组的第一个元素,因为默认得到的item类型是数组不是字符串 class JobBoleArticleItem(scrapy.Item): title = scrapy.Field() create_date = scrapy.Field( input_processor=MapCompose(date_convert), ) url = scrapy.Field() url_object_id = scrapy.Field() front_image_url = scrapy.Field( output_processor=Identity() ) front_image_path = scrapy.Field() praise_nums = scrapy.Field( input_processor=MapCompose(get_nums) ) comment_nums = scrapy.Field( input_processor=MapCompose(get_nums) ) fav_nums = scrapy.Field( input_processor=MapCompose(get_nums) ) tags = scrapy.Field( input_processor=MapCompose(remove_comment_tags), output_processor=Join(",") # tags已经是list类型,不采用默认的output_processor ) content = scrapy.Field()
import scrapy from scrapy.http import Request from urllib import parse from ArticleSpider.items import JobBoleArticleItem, ArticleItemLoader from ArticleSpider.utils.common import get_md5 class JobboleSpider(scrapy.Spider): name = 'jobbole' allowed_domains = ['blog.jobbole.com'] start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response): """ 1. 获取文章列表页中的文章url并交给scrapy下载后并进行解析 2. 获取下一页的url并交给scrapy进行下载, 下载完成后交给parse """ # 解析列表页中的所有文章url并交给scrapy下载后并进行解析 post_nodes = response.css("#archive .floated-thumb .post-thumb a") for post_node in post_nodes: image_url = post_node.css("img::attr(src)").extract_first("") post_url = post_node.css("::attr(href)").extract_first("") yield Request(url=parse.urljoin(response.url, post_url), meta={"front_image_url": image_url}, callback=self.parse_detail) # meta把上一个url的内容传到下一个url # urljoin作用:url有域名不加域名,没有域名则添加域名 # 提取下一页并交给scrapy进行下载 next_url = response.css(".next.page-numbers::attr(href)").extract_first("") if next_url: yield Request(url=parse.urljoin(response.url, next_url), callback=self.parse) def parse_detail(self, response): front_image_url = response.meta.get("front_image_url", "") # 文章封面图 item_loader = ArticleItemLoader(item=JobBoleArticleItem(), response=response) # here item_loader.add_css("title", ".entry-header h1::text") item_loader.add_value("url", response.url) item_loader.add_value("url_object_id", get_md5(response.url)) item_loader.add_css("create_date", "p.entry-meta-hide-on-mobile::text") item_loader.add_value("front_image_url", [front_image_url]) item_loader.add_css("praise_nums", ".vote-post-up h10::text") item_loader.add_css("comment_nums", "a[href='#article-comment'] span::text") item_loader.add_css("fav_nums", ".bookmark-btn::text") item_loader.add_css("tags", "p.entry-meta-hide-on-mobile a::text") item_loader.add_css("content", "div.entry") article_item = item_loader.load_item() yield article_item # yield之后item传递到pipeline中
pipeline中的open_spider和close_spider
在管道中,除了必须定义process_item之外,还可以定义两个方法:
open_spider(spider) :能够在爬虫开启的时候执行一次
close_spider(spider) :能够在爬虫关闭的时候执行一次
所以,上述方法经常用于爬虫和数据库的交互,在爬虫开启的时候建立和数据库的连接,在爬虫关闭的时候断开和数据库的连接
下面的代码分别以操作文件和mongodb为例展示方法的使用

crawlspider
顾之前的代码中,我们有很大一部分时间在寻找下一页的url地址或者是内容的url地址上面,这个过程能更简单一些么?
从response中提取所有的满足规则的url地址 自动的构造自己requests请求,发送给引擎
创建crawlspdier爬虫的命令
scrapy genspider –t crawl tencent hr.tencent.com/
观察爬虫内的默认内容
spider中默认生成的内容如下,其中重点在rules中
rules是一个元组或者是列表,包含的是Rule对象
Rule表示规则,其中包含LinkExtractor,callback和follow
LinkExtractor:连接提取器,可以通过正则或者是xpath来进行url地址的匹配
callback :表示经过连接提取器提取出来的url地址响应的回调函数,可以没有,没有表示响应不会进行回调函数的处理
follow:表示进过连接提取器提取的url地址对应的响应是否还会继续被rules中的规则进行提取,True表示会,Flase表示不会
通过crawlspider爬取腾讯招聘的详情页的招聘信息,url:http://hr.tencent.com/position.php
思路分析:
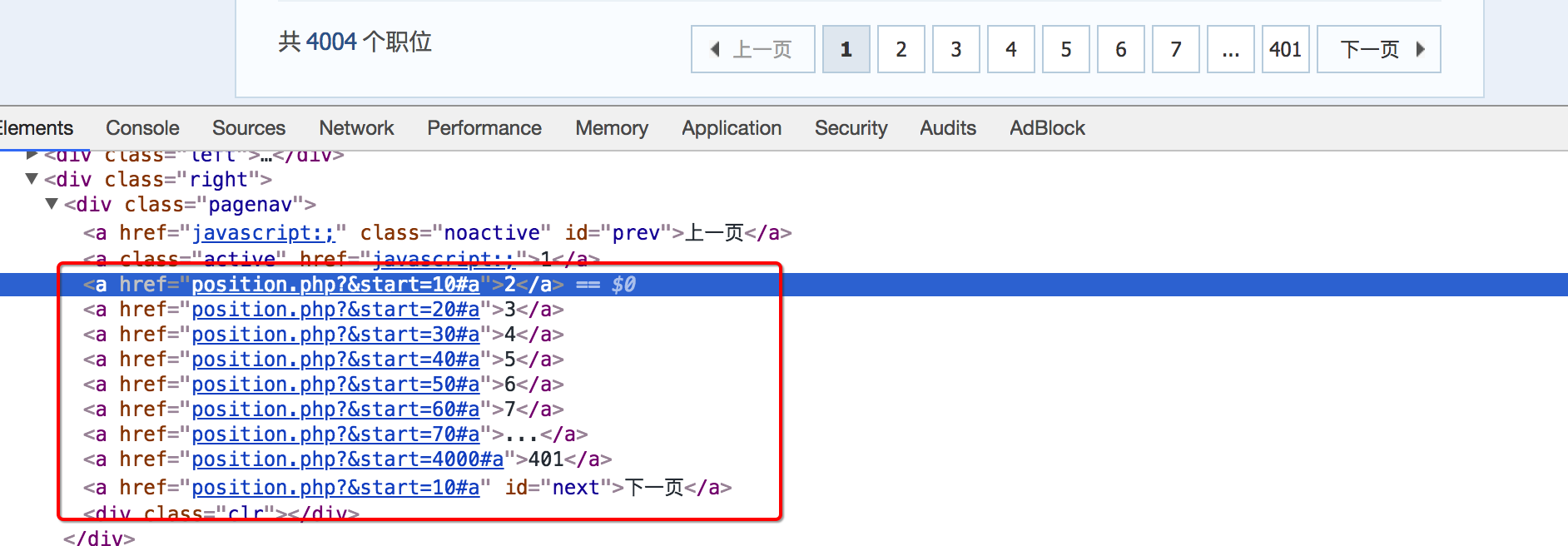
1.列表页翻页
定义一个规则,来进行列表页的翻页,follow需要设置为True,列表页url地址的规律如下
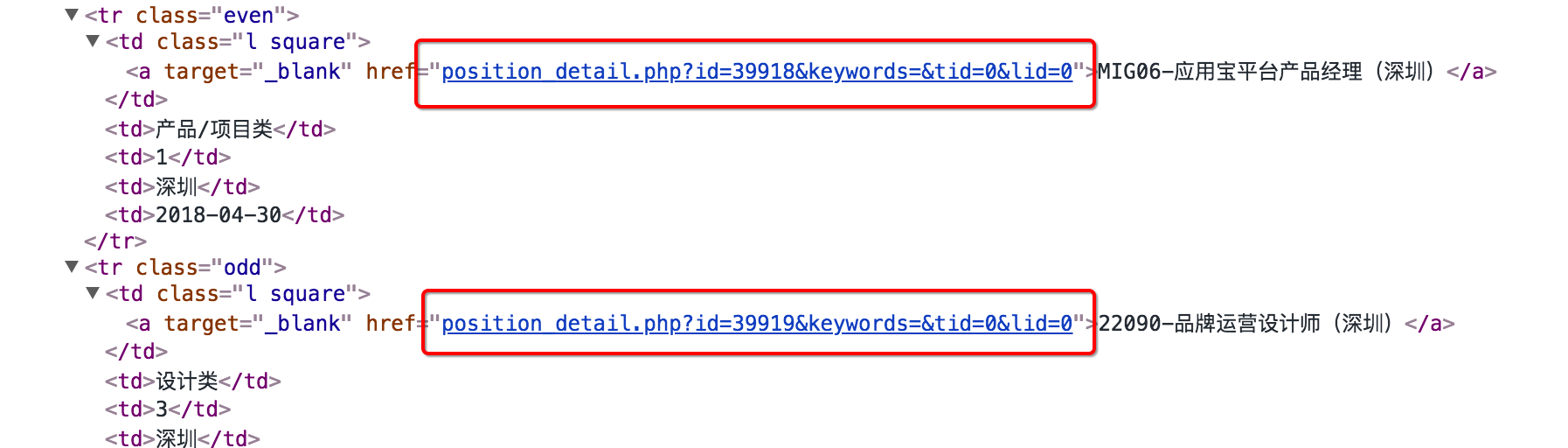
2.详情页翻页
定义一个规则,实现从列表页进入详情页,并且指定回调函数
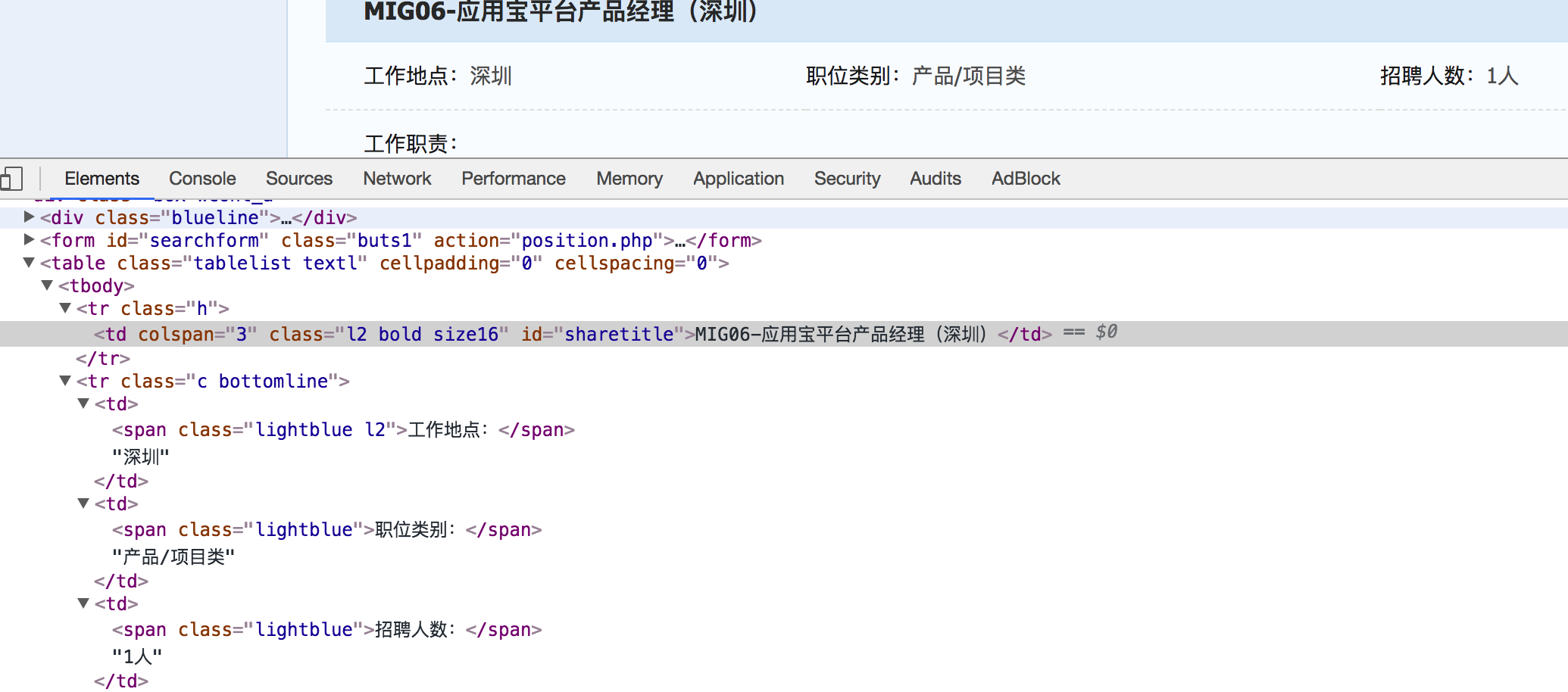
3.详情页数据的提取
在详情页url地址对应的回调函数中,实现数据提取
crawlspider使用的注意点

crawlspider的补充知识点(了解)

https://github.com/ecithy/tencentHR2
scrapy进行模拟登陆
scrapy来说,有两个方法模拟登陆:
1、直接携带cookie 2、找到发送post请求的url地址,带上信息,发送请求
import scrapy import re class RenrenSpider(scrapy.Spider): name = 'renren' allowed_domains = ['renren.com'] start_urls = ['http://www.renren.com/941954027/profile'] def start_requests(self): cookie_str = "cookie_str" cookie_dict = {i.split("=")[0]:i.split("=")[1] for i in cookie_str.split("; ")} yield scrapy.Request( self.start_urls[0], callback=self.parse, cookies=cookie_dict, # headers={"Cookie":cookie_str} ) def parse(self, response): ret = re.findall("新用户287",response.text) print(ret) yield scrapy.Request( "http://www.renren.com/941954027/profile?v=info_timeline", callback=self.parse_detail ) def parse_detail(self,response): ret = re.findall("新用户287",response.text) print(ret)
#spider/github.py # -*- coding: utf-8 -*- import scrapy import re class GithubSpider(scrapy.Spider): name = 'github' allowed_domains = ['github.com'] start_urls = ['https://github.com/login'] def parse(self, response): authenticity_token = response.xpath("//input[@name='authenticity_token']/@value").extract_first() utf8 = response.xpath("//input[@name='utf8']/@value").extract_first() commit = response.xpath("//input[@name='commit']/@value").extract_first() yield scrapy.FormRequest( "https://github.com/session", formdata={ "authenticity_token":authenticity_token, "utf8":utf8, "commit":commit, "login":"noobpythoner", "password":"***" }, callback=self.parse_login ) def parse_login(self,response): ret = re.findall("noobpythoner",response.text,re.I) print(ret)
更多示例
腾讯招聘
https://github.com/ecithy/tencentHR
阳光政务平台
https://github.com/ecithy/spider-yangguang

 浙公网安备 33010602011771号
浙公网安备 33010602011771号