Java之路 Java WEB 【第一篇】XML
XML作用
xml和html类似,xml元素、属性可以自定义
1. 可以用来保存数据(用的少) 2. 可以用来做配置文件 3. 数据传输载体
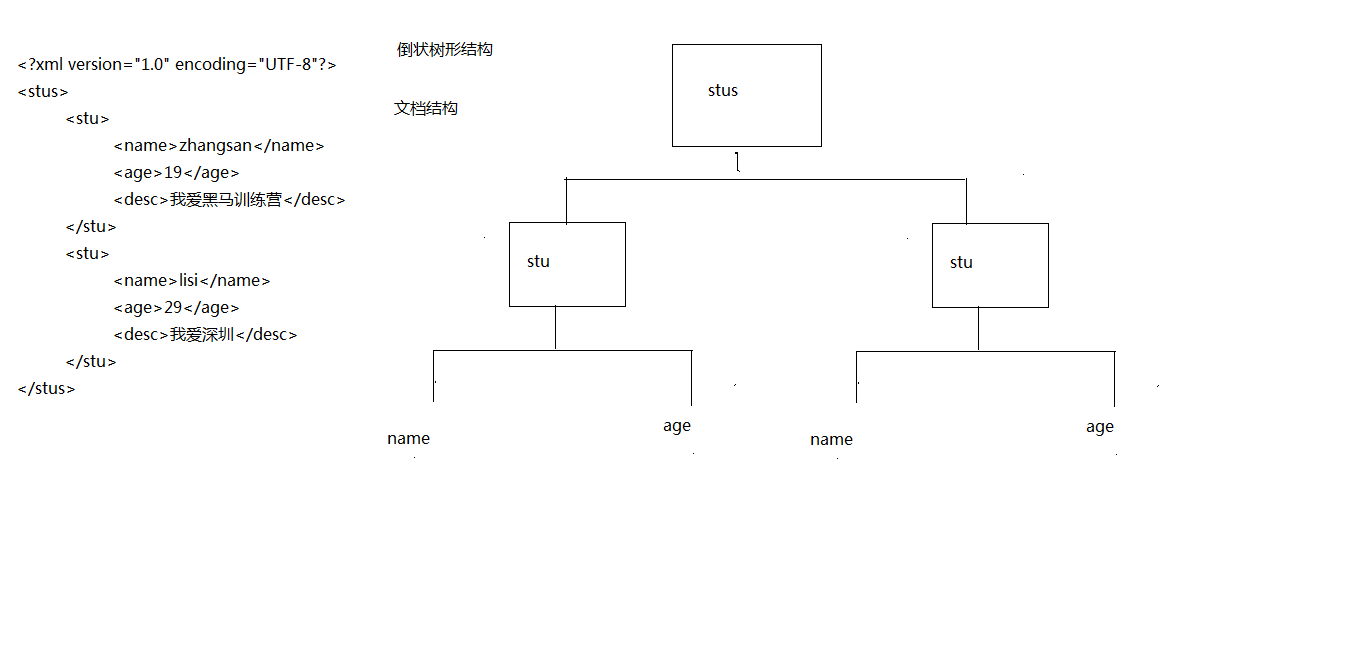
XML文档的树形结构
文档声明
简单声明, version : 解析这个xml的时候,使用什么版本的解析器解析 <?xml version="1.0" ?> encoding : 解析xml中的文字的时候,使用什么编码来翻译 <?xml version="1.0" encoding="gbk" ?> standalone : no - 该文档会依赖关联其他文档 , yes-- 这是一个独立的文档 <?xml version="1.0" encoding="gbk" standalone="no" ?>
XML解析
常用的有2种
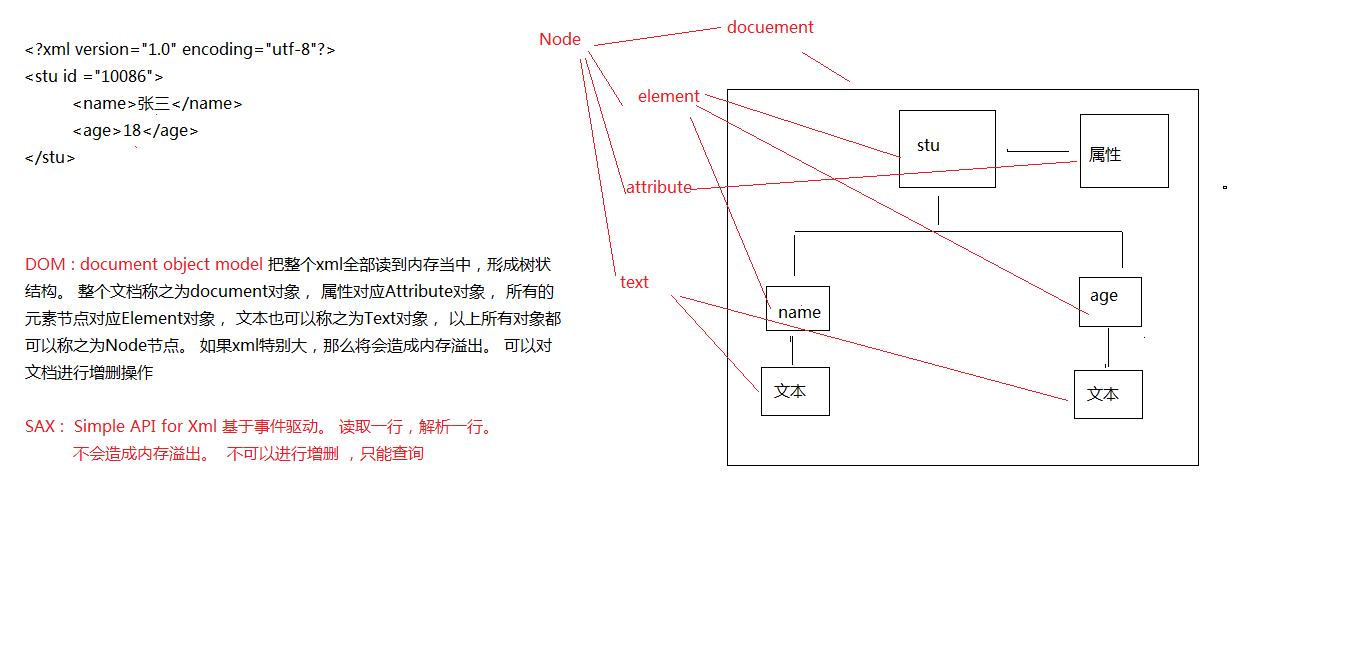
DOM SAX
两种解析方式的API
jaxp sun公司。 比较繁琐 jdom dom4j 使用比较广泛
Dom4j基本用法
1. 创建SaxReader对象 2. 指定解析的xml 3. 获取根元素。 4. 根据根元素获取子元素或者下面的子孙元素
依赖包 dom4j


package com.mingren; import java.io.File; import java.util.List; import org.dom4j.Document; import org.dom4j.Element; import org.dom4j.io.SAXReader; public class HelloWorld { /** * @param args */ public static void main(String[] args) { // TODO Auto-generated method stub System.out.println("hello world"); try { // 1. 创建sax读取对象 SAXReader reader = new SAXReader(); // jdbc -- classloader // 2. 指定解析的xml源 Document document = reader.read(new File("src/xml/stus.xml")); // 3. 得到元素 // 得到根元素 Element rootElement = document.getRootElement(); // 获取根元素下面的子元素 age // rootElement.element("age") // System.out.println(rootElement.element("stu").element("age").getText()); // 获取根元素下面的所有子元素 。 stu元素 List<Element> elements = rootElement.elements(); // 遍历所有的stu元素 for (Element element : elements) { // 获取stu元素下面的name元素 String name = element.element("name").getText(); String age = element.element("age").getText(); System.out.println("name=" + name + "==age+" + age); } } catch (Exception e) { e.printStackTrace(); } } }
Xpath
dom4j里面支持Xpath的写法。 xpath其实是xml的路径语言,支持我们在解析xml的时候,能够快速的定位到具体的某一个元素。
依赖包 jaxen
package com.mingren; import java.io.File; import org.dom4j.Document; import org.dom4j.Element; import org.dom4j.io.SAXReader; public class HelloWorld { /** * @param args */ public static void main(String[] args) { // TODO Auto-generated method stub System.out.println("hello world"); try { // 1. 创建sax读取对象 SAXReader reader = new SAXReader(); // jdbc -- classloader // 2. 指定解析的xml源 Document document = reader.read(new File("src/xml/stus.xml")); // 3. 得到元素 // 得到根元素 Element rootElement = document.getRootElement(); Element nameElement = (Element) rootElement .selectSingleNode("//name"); Element ageElement = (Element) rootElement .selectSingleNode("//age"); System.out.println("name=" + nameElement.getText() + "==age+" + ageElement.getText()); } catch (Exception e) { e.printStackTrace(); } } }
谢谢

 浙公网安备 33010602011771号
浙公网安备 33010602011771号