spider【第六篇】并发爬虫
单线程爬虫


''' cost time: 61s ''' # coding=utf-8 import requests from lxml import etree import time class QiuBai: def __init__(self): self.temp_url = "http://www.qiushibaike.com/text/page/{}" self.headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"} def get_url_list(self): return [self.temp_url.format(i) for i in range(1, 20)] def parse_url(self, url): print(url) response = requests.get(url, headers=self.headers) response.encoding = "utf-8" return response.text def get_content_list(self, html_str): # 提取数据 html_str = etree.HTML(html_str) div_list = html_str.xpath("//div[@id='content-left']/div") content_list = [] for div in div_list: item = {} item["user_name"] = div.xpath(".//h2/text()")[0].strip() item["content"] = [i.strip() for i in div.xpath(".//div[@class='content']/span/text()")] content_list.append(item) return content_list def save_content_list(self, content_list): # 保存 for content in content_list: print(content) def run(self): # 实现做主要逻辑 # 1. 准备url列表 url_list = self.get_url_list() # 2. 遍历发送请求,获取响应 for url in url_list: html_str = self.parse_url(url) # 3. 提取数据 content_list = self.get_content_list(html_str) # 4. 保存 self.save_content_list(content_list) if __name__ == '__main__': t1 = time.time() qiubai = QiuBai() qiubai.run() print("total cost:", time.time() - t1) v1
多线程爬虫
把爬虫中的每个步骤封装成函数,分别用线程去执行
不同的函数通过队列相互通信,函数间解耦
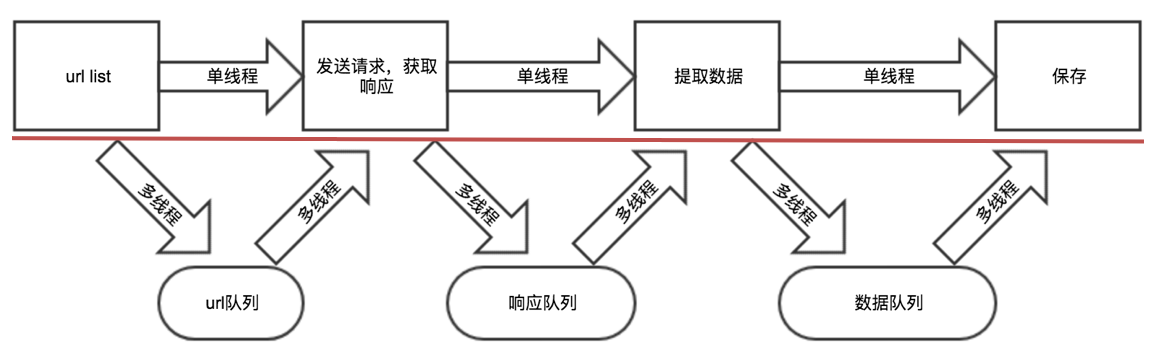
''' cost time: 17s ''' # coding=utf-8 import requests from lxml import etree from queue import Queue import threading import time class QiuBai: def __init__(self): self.temp_url = "http://www.qiushibaike.com/text/page/{}" self.headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"} self.url_queue = Queue() self.html_queue = Queue() self.content_list_queue = Queue() def get_url_list(self): # return [self.temp_url.format(i) for i in range(1,14)] for i in range(1, 100): self.url_queue.put(self.temp_url.format(i)) def parse_url(self): while True: url = self.url_queue.get() response = requests.get(url, headers=self.headers) response.encoding = "utf-8" print(response.text) if response.status_code != 200: self.url_queue.put(url) else: self.html_queue.put(response.content.decode()) self.url_queue.task_done() # 让队列的计数-1 def get_content_list(self): # 提取数据 while True: html_str = self.html_queue.get() html = etree.HTML(html_str) div_list = html.xpath("//div[@id='content-left']/div") content_list = [] for div in div_list: item = {} item["user_name"] = div.xpath(".//h2/text()")[0].strip() item["content"] = [i.strip() for i in div.xpath(".//div[@class='content']/span/text()")] content_list.append(item) self.content_list_queue.put(content_list) self.html_queue.task_done() def save_content_list(self): # 保存 while True: content_list = self.content_list_queue.get() for content in content_list: # print(content) pass self.content_list_queue.task_done() def run(self): # 实现做主要逻辑 thread_list = [] # 1. 准备url列表 t_url = threading.Thread(target=self.get_url_list) thread_list.append(t_url) # 2. 遍历发送请求,获取响应 for i in range(3): t_parse = threading.Thread(target=self.parse_url) thread_list.append(t_parse) # 3. 提取数据 t_content = threading.Thread(target=self.get_content_list) thread_list.append(t_content) # 4. 保存 t_save = threading.Thread(target=self.save_content_list) thread_list.append(t_save) for t in thread_list: t.setDaemon(True) # 把子线程设置为守护线程 t.start() for q in [self.url_queue, self.html_queue, self.content_list_queue]: q.join() # 让主线程阻塞,等待队列计数为0 if __name__ == '__main__': t1 = time.time() qiubai = QiuBai() qiubai.run() print("total cost:", time.time() - t1)
# coding=utf-8 import requests from lxml import etree import time from queue import Queue from multiprocessing.dummy import Pool class QiuBai: def __init__(self): self.temp_url = "http://www.qiushibaike.com/text/page/{}" self.headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"} self.queue = Queue() self.pool = Pool(5) self.is_running = True self.total_request_num = 0 self.total_response_num = 0 self.proxies = {"http": "http://58.247.179.94:8060"} def get_url_list(self): for i in range(1, 14): self.queue.put(self.temp_url.format(i)) self.total_request_num += 1 def parse_url(self, url): # response = requests.get(url,headers=self.headers,proxies=self.proxies) response = requests.get(url, headers=self.headers) print(response) return response.content.decode() def get_content_list(self, html_str): # 提取数据 html = etree.HTML(html_str) div_list = html.xpath("//div[@id='content-left']/div") content_list = [] for div in div_list: item = {} item["user_name"] = div.xpath(".//h2/text()")[0].strip() item["content"] = [i.strip() for i in div.xpath(".//div[@class='content']/span/text()")] content_list.append(item) return content_list def save_content_list(self, content_list): # 保存 for content in content_list: # print(content) pass def _execete_request_content_save(self): # 进行一次url地址的请求,提取,保存 url = self.queue.get() html_str = self.parse_url(url) # 3. 提取数据 content_list = self.get_content_list(html_str) # 4. 保存 self.save_content_list(content_list) self.total_response_num += 1 def _callback(self, temp): if self.is_running: self.pool.apply_async(self._execete_request_content_save, callback=self._callback) def run(self): # 实现做主要逻辑 # 1. 准备url列表 self.get_url_list() for i in range(3): # 设置并发数为3 self.pool.apply_async(self._execete_request_content_save, callback=self._callback) while True: time.sleep(0.0001) if self.total_response_num >= self.total_request_num: self.is_running = False break if __name__ == '__main__': t1 = time.time() qiubai = QiuBai() qiubai.run() print("total cost:", time.time() - t1)
多进程爬虫
# coding=utf-8 import requests from lxml import etree # from queue import Queue # import threading from multiprocessing import Process from multiprocessing import JoinableQueue as Queue import time class QiuBai: def __init__(self): self.temp_url = "http://www.qiushibaike.com/text/page/{}" self.headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"} self.url_queue = Queue() self.html_queue = Queue() self.content_list_queue = Queue() self.proxies = None # {"http": "http://58.247.179.94:8060"} def get_url_list(self): # return [self.temp_url.format(i) for i in range(1,14)] for i in range(1, 14): self.url_queue.put(self.temp_url.format(i)) def parse_url(self): while True: url = self.url_queue.get() response = requests.get(url, headers=self.headers, proxies=self.proxies) print(response) if response.status_code != 200: self.url_queue.put(url) else: self.html_queue.put(response.content.decode()) self.url_queue.task_done() # 让队列的计数-1 def get_content_list(self): # 提取数据 while True: html_str = self.html_queue.get() html = etree.HTML(html_str) div_list = html.xpath("//div[@id='content-left']/div") content_list = [] for div in div_list: item = {} item["user_name"] = div.xpath(".//h2/text()")[0].strip() item["content"] = [i.strip() for i in div.xpath(".//div[@class='content']/span/text()")] content_list.append(item) self.content_list_queue.put(content_list) self.html_queue.task_done() def save_content_list(self): # 保存 while True: content_list = self.content_list_queue.get() for content in content_list: # print(content) pass self.content_list_queue.task_done() def run(self): # 实现做主要逻辑 thread_list = [] # 1. 准备url列表 t_url = Process(target=self.get_url_list) thread_list.append(t_url) # 2. 遍历发送请求,获取响应 for i in range(13): t_parse = Process(target=self.parse_url) thread_list.append(t_parse) # 3. 提取数据 t_content = Process(target=self.get_content_list) thread_list.append(t_content) # 4. 保存 t_save = Process(target=self.save_content_list) thread_list.append(t_save) for process in thread_list: process.daemon = True # 把子线程设置为守护线程 process.start() for q in [self.url_queue, self.html_queue, self.content_list_queue]: q.join() # 让主线程阻塞,等待队列计数为0 if __name__ == '__main__': t1 = time.time() qiubai = QiuBai() qiubai.run() print("total cost:", time.time() - t1)
协程爬虫
# coding=utf-8 import gevent.monkey gevent.monkey.patch_all() from gevent.pool import Pool import requests from lxml import etree import time from queue import Queue class QiuBai: def __init__(self): self.temp_url = "http://www.qiushibaike.com/text/page/{}" self.headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"} self.queue = Queue() self.pool = Pool(5) self.is_running = True self.total_request_num = 0 self.total_response_num = 0 self.proxies = {"http": "http://58.247.179.94:8060"} def get_url_list(self): for i in range(1, 14): self.queue.put(self.temp_url.format(i)) self.total_request_num += 1 def parse_url(self, url): # response = requests.get(url,headers=self.headers,proxies=self.proxies) response = requests.get(url, headers=self.headers) return response.content.decode() def get_content_list(self, html_str): # 提取数据 html = etree.HTML(html_str) div_list = html.xpath("//div[@id='content-left']/div") content_list = [] for div in div_list: item = {} item["user_name"] = div.xpath(".//h2/text()")[0].strip() item["content"] = [i.strip() for i in div.xpath(".//div[@class='content']/span/text()")] content_list.append(item) return content_list def save_content_list(self, content_list): # 保存 for content in content_list: print(content) pass def _execete_request_content_save(self): # 进行一次url地址的请求,提取,保存 url = self.queue.get() html_str = self.parse_url(url) # 3. 提取数据 content_list = self.get_content_list(html_str) # 4. 保存 self.save_content_list(content_list) self.total_response_num += 1 def _callback(self, temp): if self.is_running: self.pool.apply_async(self._execete_request_content_save, callback=self._callback) def run(self): # 实现做主要逻辑 # 1. 准备url列表 self.get_url_list() for i in range(3): # 设置并发数为3 self.pool.apply_async(self._execete_request_content_save, callback=self._callback) while True: time.sleep(0.0001) if self.total_response_num >= self.total_request_num: self.is_running = False break if __name__ == '__main__': t1 = time.time() qiubai = QiuBai() qiubai.run() print("total cost:", time.time() - t1)
谢谢

 浙公网安备 33010602011771号
浙公网安备 33010602011771号