

AC自动机讲解超详细
begin:2019/5/2
update 2020/6/12 更新了LaTeX(咕了好久
感谢大家支持!
AC自动机详细讲解
AC自动机真是个好东西!之前学被指针搞晕了,所以咕了许久都不敢开AC自动机,近期学完之后,发现AC自动机并不是很难,特别是对于,个人感觉AC自动机比要好理解一些,可能是因为我对树上的东西比较敏感(实际是因为我到现在都不会)。
很多人都说AC自动机是在树上作,我不否认这一种观点,因为这确实是这样,不过对于刚开始学AC自动机的同学们就一些误导性的理解(至少对我是这样的)。是建立在一个字符串上的,现在把搬到了树上,不是很麻烦吗?实际上AC自动机只是有的一种思想,实际上跟一个字符串的有着很大的不同。
所以看这篇blog,请放下,理解好,再来学习。
前置技能
2.的思想(懂思想就可以了,不需要很熟练)
问题描述
给定个模式串和个文本串,求有多少个模式串在文本串里出现过。
注意:是出现过,就是出现多次只算一次。
默认这里每一个人都已经会了。
我们将个模式串建成一颗树,建树的方式和建完全一样。

假如我们现在有文本串。
我们用文本串在上匹配,刚开始会经过号点,发现到,成功地匹配了一个模式串,然后就不能再继续匹配了,这时我们还要重新继续从根开始匹配吗?
不,这样的效率太慢了。这时我们就要借用的思想,从上的某个点继续开始匹配。
明显在这颗上,我们可以继续从号点开始匹配,然后匹配到。
那么我们怎么确定从那个点开始匹配呢?我们称匹配失败后继续从开始匹配,是的(失配指针)。
构建Fail指针
的含义
指针的实质含义是什么呢?
如果一个点的指针指向。那么到的字符串是到的字符串的一个后缀。
举个例子:(例子来自上面的图
i:4 j:7
root到i的字符串是“ABC”
root到j的字符串是“BC”
“BC”是“ABC”的一个后缀
所以i的Fail指针指向j
同时我们发现,“”也是“”的一个后缀。
所以指针指的的深度要尽量大。
重申一下指针的含义:((最长的(当前字符串的后缀))在上可以查找到)的末尾编号。
感觉读起来挺绕口的蛤。感性理解一下就好了,没什么卵用的。知道有什么用就行了。
求
首先我们可以确定,每一个点的指针指向的点的深度一定是比小的。(Fail指的是后缀啊)
第一层的一定指的是。(比深度还浅的只有了)
设点的父亲的指针指的是,那么如果有和值相同的儿子,那么的就指向。这里可能比较难理解一点,建议画图理解,不过等会转换成代码就很好理解了。
由于我们在处理的情况必须要先处理好的情况,所以求我们使用来实现。
实现的一些细节:
-
1、刚开始我们不是要初始化第一层的指针为,其实我们可以建一个虚节点号节点,将的所有儿子指向(编号为,记得初始化),然后的指向就OK了。效果是一样的。
-
2、如果不存在一个节点,那么我们可以将那个节点设为的((值和相同)的儿子)。保证存在性,就算是也可以成功返回到根,因为的所有儿子都是根。
-
3、无论存不存在和值相同的儿子,我们都可以将的指向。因为在处理的时候已经处理好了,如果出现这种情况,的值是第种情况,也是有实际值的,所以没有问题。
-
4、实现时不记父亲,我们直接让父亲更新儿子
void getFail(){
for(int i=0;i<26;i++)trie[0].son[i]=1; //初始化0的所有儿子都是1
q.push(1);trie[1].fail=0; //将根压入队列
while(!q.empty()){
int u=q.front();q.pop();
for(int i=0;i<26;i++){ //遍历所有儿子
int v=trie[u].son[i]; //处理u的i儿子的fail,这样就可以不用记父亲了
int Fail=trie[u].fail; //就是fafail,trie[Fail].son[i]就是和v值相同的点
if(!v){trie[u].son[i]=trie[Fail].son[i];continue;} //不存在该节点,第二种情况
trie[v].fail=trie[Fail].son[i]; //第三种情况,直接指就可以了
q.push(v); //存在实节点才压入队列
}
}
}
查询
求出了指针,查询就变得十分简单了。
为了避免重复计算,我们每经过一个点就打个标记为,下一次经过就不重复计算了。
同时,如果一个字符串匹配成功,那么他的也肯定可以匹配成功(后缀嘛),于是我们就把再统计答案,同样,的也可以匹配成功,以此类推……经过的点累加,标记为。
最后主要还是和的查询是一样的。
int query(char* s){
int u=1,ans=0,len=strlen(s);
for(int i=0;i<len;i++){
int v=s[i]-'a';
int k=trie[u].son[v]; //跳Fail
while(k>1&&trie[k].flag!=-1){ //经过就不统计了
ans+=trie[k].flag,trie[k].flag=-1; //累加上这个位置的模式串个数,标记 已 经过
k=trie[k].fail; //继续跳Fail
}
u=trie[u].son[v]; //到儿子那,存在性看上面的第二种情况
}
return ans;
}
代码
#include<bits/stdc++.h>
#define maxn 1000001
using namespace std;
struct kkk{
int son[26],flag,fail;
}trie[maxn];
int n,cnt;
char s[1000001];
queue<int >q;
void insert(char* s){
int u=1,len=strlen(s);
for(int i=0;i<len;i++){
int v=s[i]-'a';
if(!trie[u].son[v])trie[u].son[v]=++cnt;
u=trie[u].son[v];
}
trie[u].flag++;
}
void getFail(){
for(int i=0;i<26;i++)trie[0].son[i]=1; //初始化0的所有儿子都是1
q.push(1);trie[1].fail=0; //将根压入队列
while(!q.empty()){
int u=q.front();q.pop();
for(int i=0;i<26;i++){ //遍历所有儿子
int v=trie[u].son[i]; //处理u的i儿子的fail,这样就可以不用记父亲了
int Fail=trie[u].fail; //就是fafail,trie[Fail].son[i]就是和v值相同的点
if(!v){trie[u].son[i]=trie[Fail].son[i];continue;} //不存在该节点,第二种情况
trie[v].fail=trie[Fail].son[i]; //第三种情况,直接指就可以了
q.push(v); //存在实节点才压入队列
}
}
}
int query(char* s){
int u=1,ans=0,len=strlen(s);
for(int i=0;i<len;i++){
int v=s[i]-'a';
int k=trie[u].son[v]; //跳Fail
while(k>1&&trie[k].flag!=-1){ //经过就不统计了
ans+=trie[k].flag,trie[k].flag=-1; //累加上这个位置的模式串个数,标记已经过
k=trie[k].fail; //继续跳Fail
}
u=trie[u].son[v]; //到下一个儿子
}
return ans;
}
int main(){
cnt=1; //代码实现细节,编号从1开始
scanf("%d",&n);
for(int i=1;i<=n;i++){
scanf("%s",s);
insert(s);
}
getFail();
scanf("%s",s);
printf("%d\n",query(s));
return 0;
}
updata:2019/5/7 AC自动机的应用
AC自动机的一些应用
先拿P3796 【模板】AC自动机(加强版)来说吧。
无疑,作为模板2,这道题的解法也是十分的经典。
我们先来分析一下题目:输入和模板1一样
1、求出现次数最多的次数
2、求出现次数最多的模式串
明显,我们如果统计出每一个模式串在文本串出现的次数,那么这道题就变得十分简单了,那么问题就变成了如何统计每个模式串出现的次数。
做法:AC自动机
首先题目统计的是出现次数最多的字符串,所以有重复的字符串是没有关系的。(因为后面的会覆盖前面的,统计的答案也是一样的)
那么我们就将标记模式串的设为当前是第几个模式串。就是下面插入时的变化:
trie[u].flag++;
变为
trie[u].flag=num; //num表示该字符串是第num个输入的
求指针没有变化,原先怎么求就怎么求。
查询:我们开一个数组,表示第个字符串出现的次数。
因为是重复计算,所以不能标记为了。
我们每经过一个点,如果有模式串标记,就将。然后继续跳fail,原因上面说过了。
这样我们就可以将每个模式串的出现次数统计出来。剩下的大家应该都会QwQ!
总代码
//AC自动机加强版
#include<bits/stdc++.h>
#define maxn 1000001
using namespace std;
char s[151][maxn],T[maxn];
int n,cnt,vis[maxn],ans;
struct kkk{
int son[26],fail,flag;
void clear(){memset(son,0,sizeof(son));fail=flag=0;}
}trie[maxn];
queue<int>q;
void insert(char* s,int num){
int u=1,len=strlen(s);
for(int i=0;i<len;i++){
int v=s[i]-'a';
if(!trie[u].son[v])trie[u].son[v]=++cnt;
u=trie[u].son[v];
}
trie[u].flag=num; //变化1:标记为第num个出现的字符串
}
void getFail(){
for(int i=0;i<26;i++)trie[0].son[i]=1;
q.push(1);trie[1].fail=0;
while(!q.empty()){
int u=q.front();q.pop();
int Fail=trie[u].fail;
for(int i=0;i<26;i++){
int v=trie[u].son[i];
if(!v){trie[u].son[i]=trie[Fail].son[i];continue;}
trie[v].fail=trie[Fail].son[i];
q.push(v);
}
}
}
void query(char* s){
int u=1,len=strlen(s);
for(int i=0;i<len;i++){
int v=s[i]-'a';
int k=trie[u].son[v];
while(k>1){
if(trie[k].flag)vis[trie[k].flag]++; //如果有模式串标记,更新出现次数
k=trie[k].fail;
}
u=trie[u].son[v];
}
}
void clear(){
for(int i=0;i<=cnt;i++)trie[i].clear();
for(int i=1;i<=n;i++)vis[i]=0;
cnt=1;ans=0;
}
int main(){
while(1){
scanf("%d",&n);if(!n)break;
clear();
for(int i=1;i<=n;i++){
scanf("%s",s[i]);
insert(s[i],i);
}
scanf("%s",T);
getFail();
query(T);
for(int i=1;i<=n;i++)ans=max(vis[i],ans); //最后统计答案
printf("%d\n",ans);
for(int i=1;i<=n;i++)
if(vis[i]==ans)
printf("%s\n",s[i]);
}
}
update:2019/5/9
AC自动机的优化
topo建图优化
让我们了分析一下刚才那个模板2的时间复杂度,算了不分析了,直接告诉你吧,这样暴力去跳的最坏时间复杂度是。
为什么?因为对于每一次跳我们都只使深度减,那样深度是多少,每一次跳的时间复杂度就是多少。那么还要乘上文本串长度,就几乎是 的了。
那么模板1的时间复杂度为什么就只有。因为每一个上的点都只会经过一次(打了标记),但模板2每一个点就不止经过一次了(重复算,不打标记),所以时间复杂度就爆炸了。
那么我们可不可以让模板2的上每个点只经过一次呢?
嗯~,还真可以!
题目看这里:P5357 【模板】AC自动机(二次加强版)
做法:拓扑排序
让我们把上的都想象成一条条有向边,那么我们如果在一个点对那个点进行一些操作,那么沿着这个点连出去的点也会进行操作(就是跳),所以我们才要暴力跳去更新之后的点。
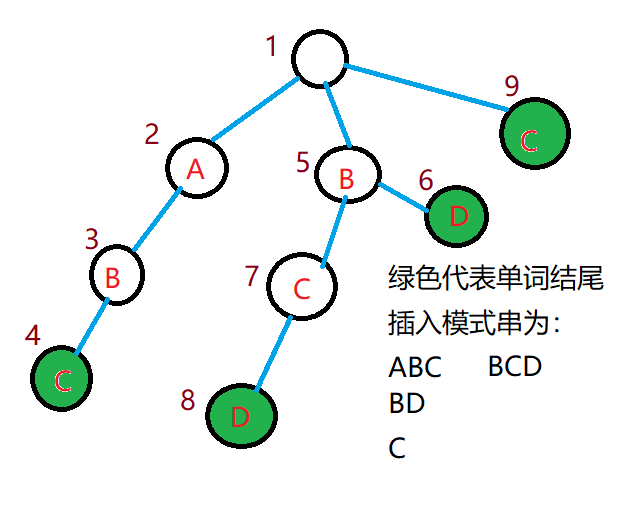
我们还是用上面的图,举个例子解释一下我刚才的意思。
我们先找到了编号这个点,编号的连向编号这个点,编号的连向编号这个点。那么我们要更新编号这个点的值,同时也要更新编号和编号,这就是暴力跳的过程。
我们下一次找到编号这个点,还要再次更新编号,所以时间复杂度就在这里被浪费了。
那么我们可不可以在找到的点打一个标记,最后再一次性将标记全部上传 来 更新其他点的。例如我们找到编号,在编号这个点打一个标记为,下一次找到了编号,又在编号这个点打一个标记为,那么最后,我们直接从编号开始跳,然后将标记上传,((点i的fail)的ans)加上(点i的ans),最后使编号的为,编号的为,编号的为,这样的答案和暴力跳是一样的,并且每一个点只经过了一次。
最后我们将有标记的传到数组里,就求出了答案。
em……,建议先消化一下。
那么现在问题来了,怎么确定更新顺序呢?明显我们打了标记后肯定是从深度大的点开始更新上去的。
怎么实现呢?拓扑排序!
我们使每一个点向它的指针连一条边,明显,每一个点的出度为(只有一个),入度可能很多,所以我们就不需要像拓扑排序那样先建个图了,直接往指针跳就可以了。
最后我们根据指针建好图后(想象一下,程序里不用实现),一定是一个,具体原因不解释(很简单的),那么我们就直接在上面跑拓扑排序,然后更新就可以了。
代码实现:
首先是这里,记得将的入度更新。
trie[v].fail=trie[Fail].son[i]; in[trie[v].fail]++; //记得加上入度
然后是,不用暴力跳了,直接打上标记就行了,很简单吧
void query(char* s){
int u=1,len=strlen(s);
for(int i=0;i<len;++i)
u=trie[u].son[s[i]-'a'],trie[u].ans++; //直接打上标记
}
最后是拓扑,解释都在注释里了OwO!
void topu(){
for(int i=1;i<=cnt;++i)
if(in[i]==0)q.push(i); //将入度为0的点全部压入队列里
while(!q.empty()){
int u=q.front();q.pop();vis[trie[u].flag]=trie[u].ans; //如果有flag标记就更新vis数组
int v=trie[u].fail;in[v]--; //将唯一连出去的出边fail的入度减去(拓扑排序的操作)
trie[v].ans+=trie[u].ans; //更新fail的ans值
if(in[v]==0)q.push(v); //拓扑排序常规操作
}
}
应该还是很好理解的吧,实现起来也没有多难嘛!
对了还有重复单词的问题,和下面讲的"P3966[TJOI2013]单词"的解决方法一样的,不讲了吧。
习题讲解
这道题和上面那道题没有什么不同,文本串就是将模式串用神奇的字符(例如"♂")隔起来的串。
但这道题有相同字符串要统计,所以我们用一个数组存这个字符串指的是中的那个位置,最后把输出就OK了。
下面是P5357【模板】AC自动机(二次加强版)的代码(套娃?大雾),剩下的大家怎么改应该还是知道的吧。
#include<bits/stdc++.h>
#define maxn 2000001
using namespace std;
char s[maxn],T[maxn];
int n,cnt,vis[200051],ans,in[maxn],Map[maxn];
struct kkk{
int son[26],fail,flag,ans;
}trie[maxn];
queue<int>q;
void insert(char* s,int num){
int u=1,len=strlen(s);
for(int i=0;i<len;++i){
int v=s[i]-'a';
if(!trie[u].son[v])trie[u].son[v]=++cnt;
u=trie[u].son[v];
}
if(!trie[u].flag)trie[u].flag=num;
Map[num]=trie[u].flag;
}
void getFail(){
for(int i=0;i<26;i++)trie[0].son[i]=1;
q.push(1);
while(!q.empty()){
int u=q.front();q.pop();
int Fail=trie[u].fail;
for(int i=0;i<26;++i){
int v=trie[u].son[i];
if(!v){trie[u].son[i]=trie[Fail].son[i];continue;}
trie[v].fail=trie[Fail].son[i]; in[trie[v].fail]++;
q.push(v);
}
}
}
void topu(){
for(int i=1;i<=cnt;++i)
if(in[i]==0)q.push(i); //将入度为0的点全部压入队列里
while(!q.empty()){
int u=q.front();q.pop();vis[trie[u].flag]=trie[u].ans; //如果有flag标记就更新vis数组
int v=trie[u].fail;in[v]--; //将唯一连出去的出边fail的入度减去(拓扑排序的操作)
trie[v].ans+=trie[u].ans; //更新fail的ans值
if(in[v]==0)q.push(v); //拓扑排序常规操作
}
}
void query(char* s){
int u=1,len=strlen(s);
for(int i=0;i<len;++i)
u=trie[u].son[s[i]-'a'],trie[u].ans++;
}
int main(){
scanf("%d",&n); cnt=1;
for(int i=1;i<=n;++i){
scanf("%s",s);
insert(s,i);
}getFail();scanf("%s",T);
query(T);topu();
for(int i=1;i<=n;++i)printf("%d\n",vis[Map[i]]);
}
广告:学完来学PAM吧 PAM学习小结
To be continue……
本文作者:Hastieyua
本文链接:https://www.cnblogs.com/hyfhaha/p/10802604.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步