
Selenium+python自动化-八种元素定位
自动化只要掌握四步操作:获取元素,操作元素,获取返回结果,断言(返回结果与期望结果是否一致),最后自动出测试报告。本篇主要讲如何用firefox辅助工具进行元素定位。
元素定位在这四个环节中是至关重要的,如果说按学习精力分配的话,元素定位占70%;操作元素10%,获取返回结果10%;断言10%。如果一个页面上的元素不能被定位到,那后面的操作就无法继续了。接下来就来讲webdriver提供的八种基本元素定位方法。
一、环境准备:
1.浏览器选择:Firefox
2.安装插件:Firebug和FirePath(设置》附加组件》搜索:输入插件名称》下载安装后重启浏览器)
3.安装完成后,页面右上角有个小爬虫图标
二、查看页面元素:
以百度搜索框为例,先打开百度网页
1.点右上角爬虫按钮
2.点左下角箭头
3.讲箭头移动到百度搜索输入框上,输入框高亮状态
4.下方红色区域就是单位到输入框的属性:

三、元素定位-单数:
find_element_by_id()
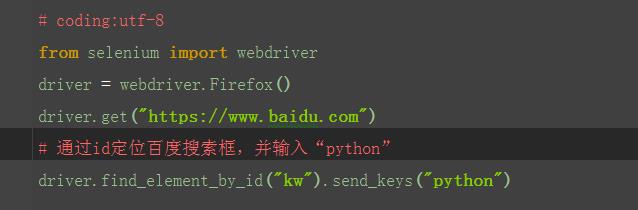
1.从上面定位到的元素属性中,可以看到有个id属性:id="search-key",这里可以通过它的id属性单位到这个元素。
2.定位到搜索框后,用send_keys()方法
find_element_by_name()
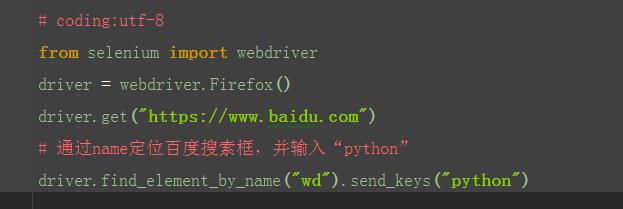
1.从上面定位到的元素属性中,可以看到有个name属性:name="wd",这里可以通过它的name属性单位到这个元素。
说明:这里运行后会报错,说明这个搜索框的name属性不是唯一的,无法通过name属性直接定位到输入框
find_element_by_class_name()
1.从上面定位到的元素属性中,可以看到有个class属性:class="s_ipt",这里可以通过它的class属性定位到这个元素。

find_element_by_tag_name()
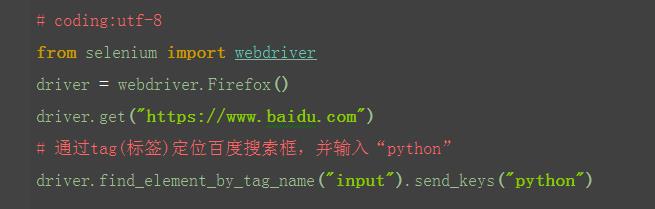
1.从上面定位到的元素属性中,可以看到每个元素都有tag(标签)属性,如搜索框的标签属性,就是最前面的input;
2.很明显,在一个页面中,相同的标签有很多,所以一般不用标签来定位。以下例子,仅供参考和理解,运行肯定报错;
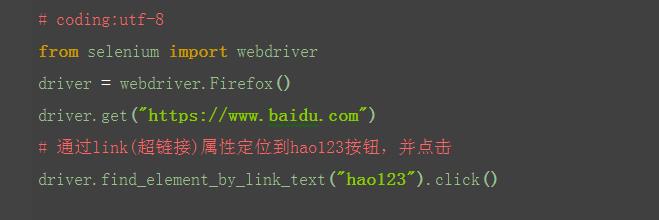
find_element_by_link_text()
1.定位百度页面上"hao123"这个按钮
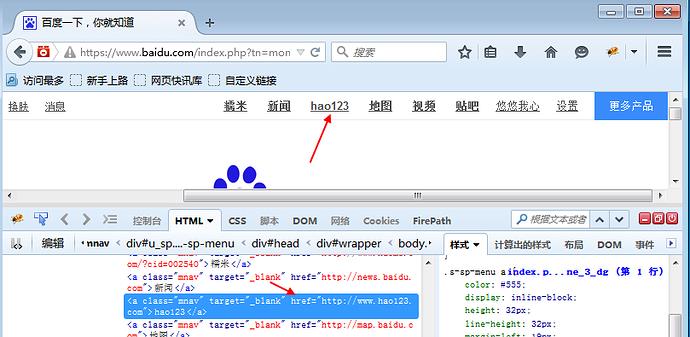
查看页面元素:
<a class="mnav" target="_blank" href="http://www.hao123.com">hao123</a>
2.从元素属性可以分析出,有个href = "http://www.hao123.com,说明它是个超链接,对于这种元素,可以用以下方法:
find_element_by_partial_link_text()
1.有时候一个超链接它的字符串可能比较长,如果输入全称的话,会显示很长,这时候可以用一模糊匹配方式,截取其中一部分字符串就可以了;
2.如“hao123”,只需输入“ao123”也可以定位到:

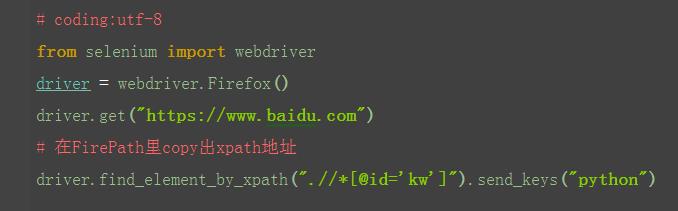
find_element_by_xpath()
1.以上定位方式都是通过元素的某个属性来定位的,如果一个元素它既没有id、name、class属性也不是超链接,这么办呢?或者说它的属性很多重复的。这个时候就可以用xpath解决;
2.xpath是一种路径语言,跟上面的定位原理不太一样,首先第一步要先学会用工具查看一个元素的xpath;
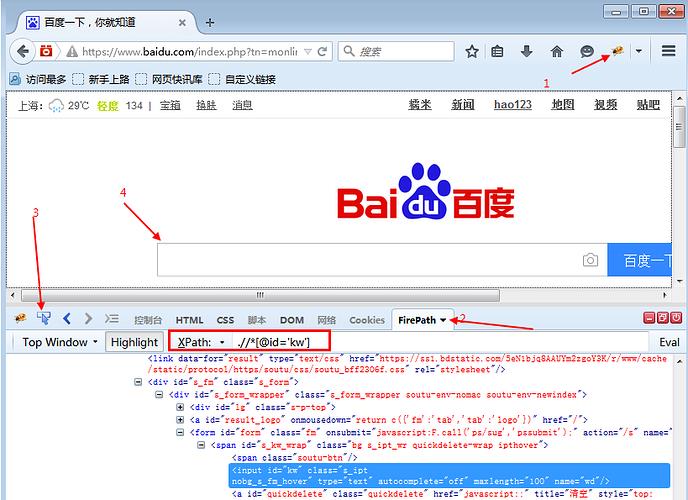
3.安装上图的步骤,在FriePath插件里copy对应的xpath地址;
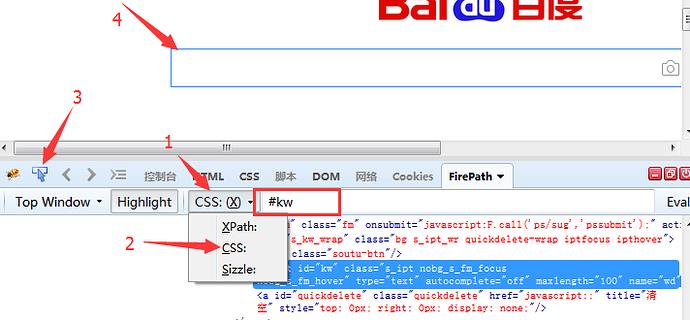
find_element_by_css_selector()
1.css是另外一种语法,比xpath更为简洁,但是不太好理解。这里先学会如何用工具查看,后续的教程再深入讲解;
2.打开FirePath插件选择css;
3.定位到后如下图红色区域显示;
四、元素定位-双数:
element和elements区别:
1.element方法定位到是是单数,是直接定位到元素;
2.elements方法是复数,这个学过英文的都知道,定位到的是一组元素,返回的是list队列;
3.可以用type()函数查看数据类型;
elements定位元素说明:
1.当一个页面上有多个属性相同的元素时,然后父元素的属性也比较模糊,不太好定位。这个时候不用怕,换个思维,别老想着一次定位到,可以先把相同属性的元素找出来,取对应的第几个就可以了。
2.如下图,百度页面上有六个class一样的元素,我要定位“地图”这个元素:

3.取对应下标即可定位了:
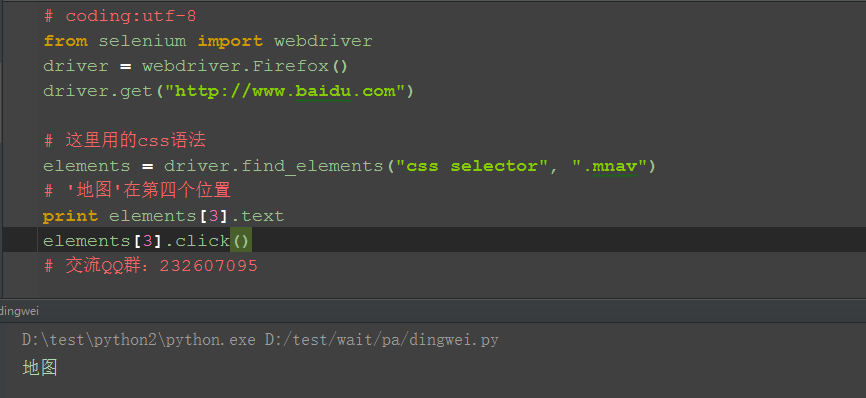
elements定位方法:
五、By定位元素:
find_element()方法只用于定位元素。它需要两个参数,第一个参数是定位方式,这个由By 提供;第二个参数是定位的值。
ID = "id"
XPATH = "xpath"
LINK_TEXT = "link text"
PARTIAL_LINK_TEXT = "partial link text"
NAME = "name"
TAG_NAME = "tag name"
CLASS_NAME = "class name"
CSS_SELECTOR = "css selector"
例子:
|
1
2
|
from selenium.webdriver.common.by import By''' 定位百度输入框 '''<br><br>find_element(By.ID,"kw") |
|
1
|
find_element(By.NAME,"wd") |
总结:
selenium的webdriver提供了八种基本的元素定位方法,前面六种是通过元素的属性来直接定位的,后面的xpath和css定位更加灵活,需要重点掌握其中一个:
1.通过id定位:find_element_by_id()
2.通过name定位:find_element_by_name()
3.通过class定位:find_element_by_class_name()
4.通过tag定位:find_element_by_tag_name()
5.通过link定位:find_element_by_link_text()
6.通过partial_link定位:find_element_by_partial_link_text()
7.通过xpath定位:find_element_by_xpath()
8.通过css定位:find_element_by_css_selector()
Class定位:
class属性有空格是多重属性,取其中一个就行。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号