
Hadoop综合大作业
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363
Hadoop综合大作业 要求:
1.将爬虫大作业产生的csv文件上传到HDFS
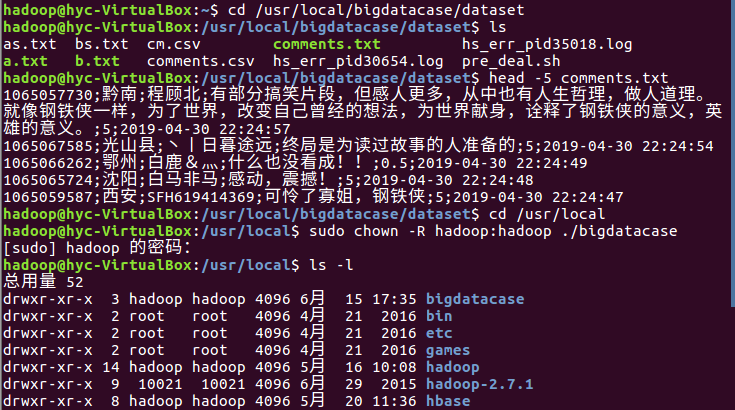
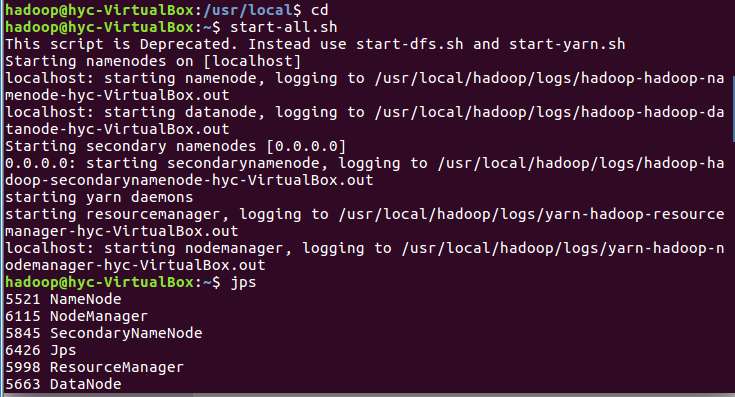
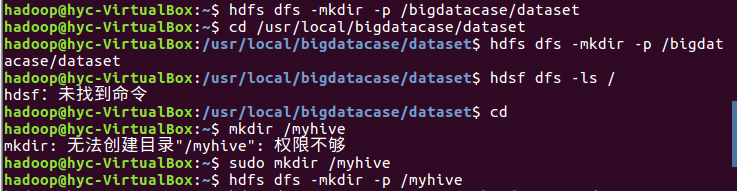
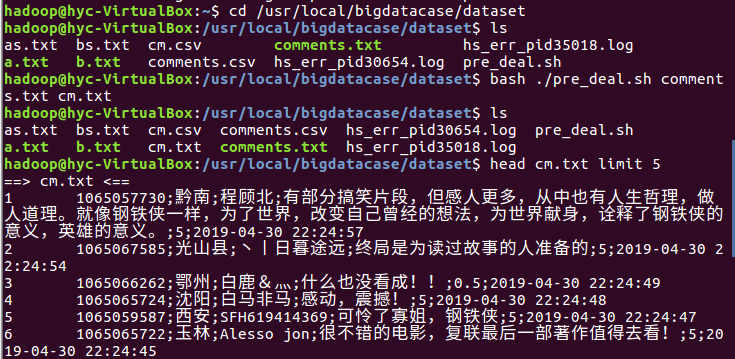
2.对CSV文件进行预处理生成无标题文本文件

3.把hdfs中的文本文件最终导入到数据仓库Hive中


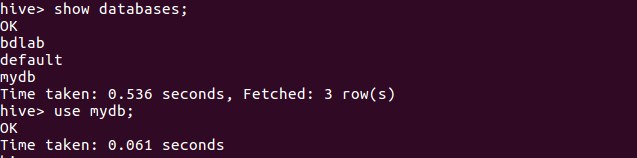
4.在Hive中查看并分析数据

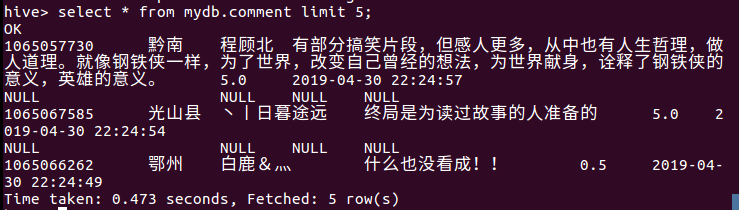
5.用Hive对爬虫大作业产生的进行数据分析,写一篇博客描述你的分析过程和分析结果。(10条以上的查询分析)
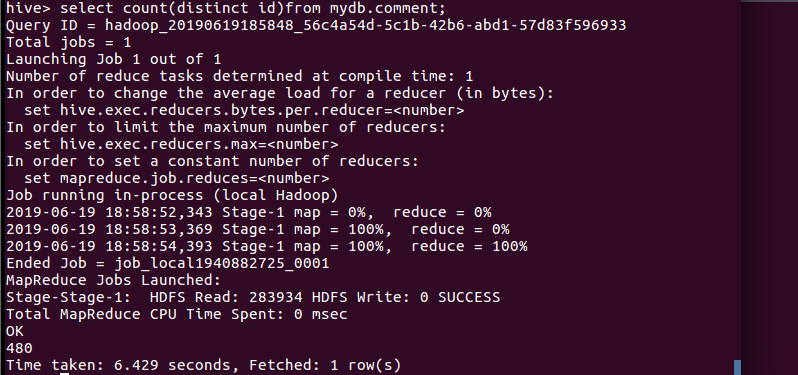
(1)查询不重复id的评论数
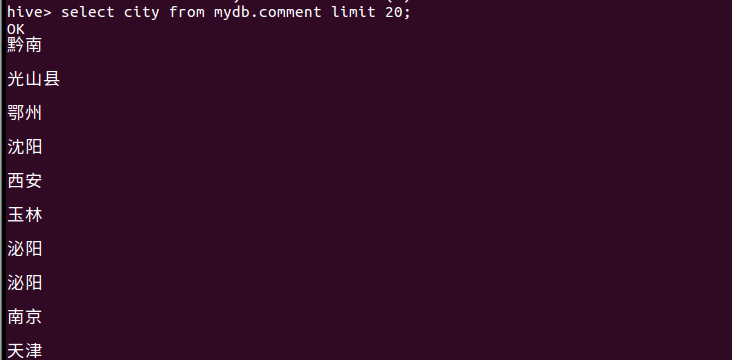
(2)查询前十条信息的所属城市
(3)查询前二十条信息的评论时间

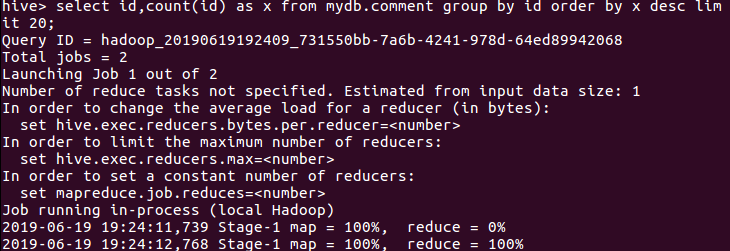
(4)查询评论次数最多的20个用户
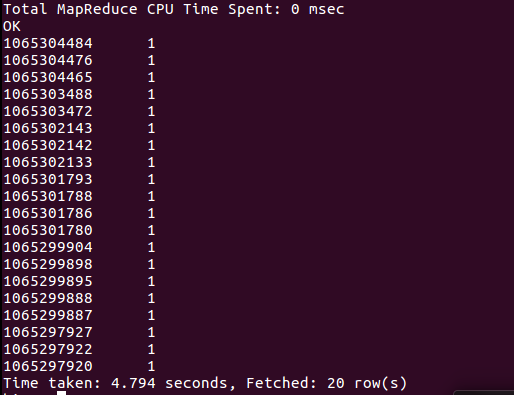
(5)查询城市中评分为5分的数量最多的前20名

(6)查询城市中评低于3分的前20名
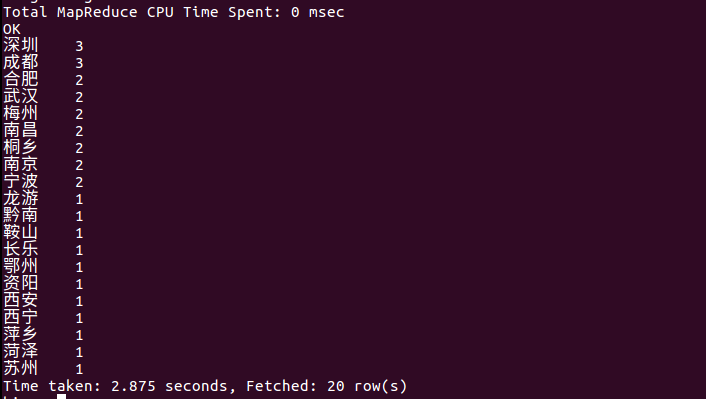
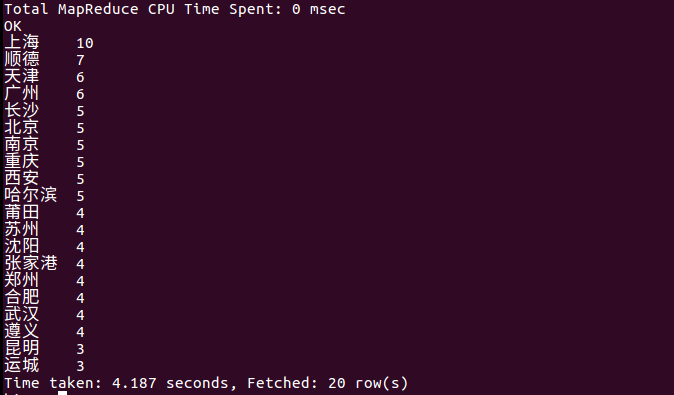
(7)查询评论数前20名的城市

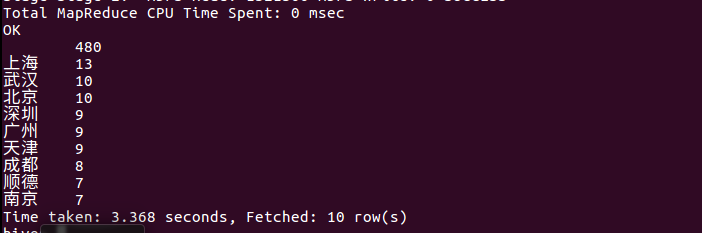
(8)查询不重复昵称的评论数

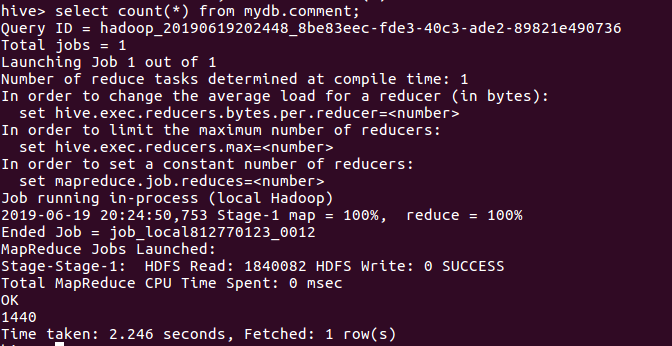
(9)计算出表内一共有几条评论数据
(10)查看评论里各评分的评论数

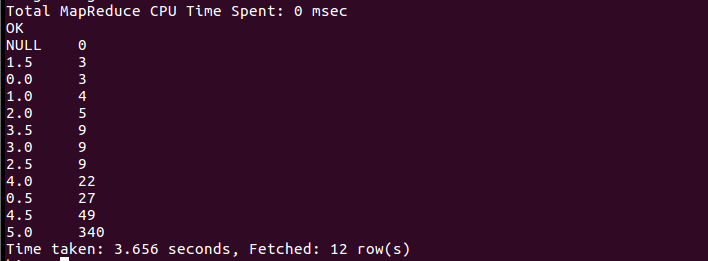
总结分析:在第一次上传文件到hive的时候发现并没有预想中的按列排序,后来把pre_deal.sh文件中默认的分列符改了之后就可以了。通过数据分析出来的结果,可以看出北京上海这些一些城市与观看评论的时间都比较靠前,而且评分也相对较高。通过对评论打分的数目分析也可以看出,打分4分以上的人数很多,占很大的比重,证明这也一部很精彩很受人喜欢的电影。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号