
字符串操作、文件操作,英文词频统计预处理
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2684
1.字符串操作:
- 解析身份证号:生日、性别、出生地等。
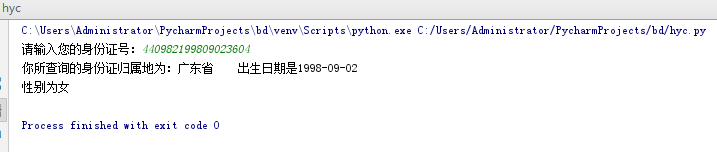
# -*- coding: utf-8 -*- """ Spyder Editor This is a temporary script file. """ #获取身份证号中的出生日期与性别 ID=input("请输入您的身份证号:"); while(len(ID)!=18): print("您的身份证号码输入错误"); ID = input("请重新输入您的身份证号:"); year=ID[6:10]; month=ID[10:12]; day=ID[12:14]; province=ID[0:2]; area={'11':'北京市','12':'天津市','13':'河北省','14':'山西省','15':'内蒙古自治区','21':'辽宁省','22':'吉林省','23':'黑龙江省','31':'上海市','32':'江苏省','33':'浙江省','34':'安徽省','35':'福建省','36':'江西省','37':'山东省','41':'河南省','42':'湖北省','43':'湖南省','44':'广东省','45':'广西壮族自治区','46':'海南省','50':'重庆市','51':'四川省','52':'贵州省','53':'云南省','54':'西藏自治区','61':'陕西省','62':'甘肃省','63':'青海省','64':'宁夏回族自治区','65':'新疆维吾尔自治区','71':'台湾省','81':'香港特别行政区','82':'澳门特别行政区'} print("你所查询的身份证归属地为:"+area.get(province), " 出生日期是{}-{}-{}".format(year,month,day)); sex=ID[-2]; if int(sex)%2==0: print("性别为女"); else: print("性别为男")
运行结果截图:
- 凯撒密码编码与解码
def encryption():
str_raw = input("请输入明文:")
k = int(input("请输入位移值:"))
str_change = str_raw.lower()
str_list = list(str_change)
str_list_encry = str_list
i = 0
while i < len(str_list):
if ord(str_list[i]) < 123-k:
str_list_encry[i] = chr(ord(str_list[i]) + k)
else:
str_list_encry[i] = chr(ord(str_list[i]) + k - 26)
i = i+1
print ("加密结果为:"+"".join(str_list_encry))
def decryption():
str_raw = input("请输入密文:")
k = int(input("请输入位移值:"))
str_change = str_raw.lower()
str_list = list(str_change)
str_list_decry = str_list
i = 0
while i < len(str_list):
if ord(str_list[i]) >= 97+k:
str_list_decry[i] = chr(ord(str_list[i]) - k)
else:
str_list_decry[i] = chr(ord(str_list[i]) + 26 - k)
i = i+1
print ("解密结果为:"+"".join(str_list_decry))
while True:
print (u"1. 加密")
print (u"2. 解密")
choice = input("请选择:")
if choice == "1":
encryption()
elif choice == "2":
decryption()
else:
print (u"您的输入有误!")
运行结果截图:

- 网址观察与批量生成
for i in range(3,8): url='http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i) print(url)
运行结果截图:

2.英文词频统计预处理
- 下载一首英文的歌词或文章或小说。
- 将所有大写转换为小写
- 将所有其他做分隔符(,.?!)替换为空格
- 分隔出一个一个的单词
- 并统计单词出现的次数。
代码如下:
#英文歌词:
str1='''I will not make the same mistakes that you did
I will not let myself cause my heart so much misery
I will not break the way you did
You fell so hard
I learned the hard way, to never let it get that far
-
Because of you
I never stray too far from the sidewalk
Because of you
I learned to play on the safe side
So I don't get hurt
Because of you
I find it hard to trust
Not only me, but everyone around me
Because of you
I am afraid
-
I lose my way
And it's not too long before you point it out
I cannot cry
Because I know that's weakness in your eyes
I'm forced to fake a smile, a laugh
Every day of my life
My heart can't possibly break
When it wasn't even whole to start with
-
Because of you
I never stray too far from the sidewalk
Because of you
I learned to play on the safe side
So I don't get hurt
Because of you
I find it hard to trust
Not only me, but everyone around me
Because of you
I am afraid
-
I watched you die
I heard you cry
Every night in your sleep
I was so young
You should have known better than to lean on me
You never thought of anyone else
You just saw your pain
And now I cry
In the middle of the night
Over the same damn thing
-
Because of you
I never stray too far from the sidewalk
Because of you
I learned to play on the safe side so I don't get hurt
Because of you
I tried my hardest just to forget everything
Because of you
I don't know how to let anyone else in
Because of you
I'm ashamed of my life because it's empty
Because of you
I am afraid
-
Because of you'''
#把单词全部变成小写
s1=str1.lower()
print(s1)
#去掉空格
str1=str1.lstrip()
print(str1)
#将歌词的每个单词分隔组成列表形式
print("将歌词的每个单词分隔组成列表形式:")
strList=str1.split()
print(strList)
#计算单词出现的次数
print("计算单词出现的次数:")
strSet=set(strList)
for word in strSet:
print(word,strList.count(word))
运行结果截图:

3.文件操作
- 词频统计:下载一首英文的歌词或文章或小说,保存为utf8文件。从文件读入文本进行处理。
代码如下:
print("词频统计")
file = open("E:\\Shape of you.txt")
soy=file.read();
file.close();
s=",.?!"
for i in s:
soy=soy.replace(i," ")
lyric=soy.lower().split()
print(soy)
count={}
for i in lyric:
try:
count[i]=count[i]+1
except KeyError:
count[i]=1
print(count)
运行结果截图:

4.函数定义
- 加密函数
-
12345678
def get_text():plaincode ='abcd'cipher=''foriinplaincode:cipher=cipher+chr(ord(i) + 3)returncipherbigstr = get_text()print(bigstr) - 解密函数
-
12345678
def get_text():plaincode ='defg'cipher=''foriinplaincode:cipher=cipher+chr(ord(i) -3)returncipherbigstr = get_text()print(bigstr) - 读文本函数
-
123456
def get_text():with open('yw.txt','r', encoding='utf8',errors='ignore')asf:text = f.read()returntextbigstr = get_text()print(bigstr)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号