
第十四次作业bug分析
从开学到现在,oo作业一直都是顺风顺水的,从构思,到代码实现一气呵成,也很少出现什么bug,强测没出过错,互测只有前两次作业有格式错误,我一直觉得那么多人吐糟的oo课也就这样吧,但是这次给了我不一样的感觉。这一单元的第二次作业可能是oo这一学期以来最纠结的一次,以前每次作业的中测都是交一次就能通过,然后优化之后再交一两次就结束了,这次足足交了九次,因为最后一个点一直wa。mid5卡了我一天半的时间,我一遍遍地读指导书,一遍遍地看着自己写的代码。
具体的分析过程是,首先新增的六条查顺序图和状态图的指令,说实话都比较直接,比较简单,只有后继结点那个我用一个邻接表存了有向图稍微用了点数据结构的东西,其他基本都是直接数umlelement。所以我把目光集中在了三个检查正确性的函数上面。在群里有同学说只写三个检查函数过不了mid5,所以我注释掉了我的三个检查函数,提交后果然过了mid5,证明了我前面的猜想,问题出在检查函数上面,而且是把正确的图误判成错误的了。首先我查出来了check002函数的一处错误,我没有考虑associationend连接的是自己还是另一个类,而是对association下面的两个associationend都判断,这样就会出现关联自己的那端和自己属性重名报错的情况。
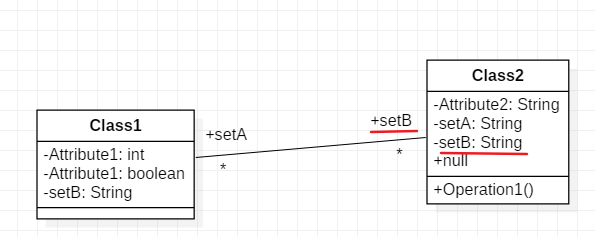
这个setB会被报错。于是我加了判断,判断associationend的reference与本类的id是否相同,选取所有不同的进行比较,但是这样就会出现自关联无法判断的情况,自关联的两端都与本类的id相同。最终我采取的方法是,如果a和b是两个关联对端,我将a的name加到b的reference命名的集合中,b的name加到a的reference命名的集合中,最后找对应的classid命名的集合就能找到所有关联对端的name。
可是这样改完之后,mid5还是没有通过。我加上这个函数,注释掉check008和check009之后提交发现mid5还是可以通过,所以问题还是没有找到,问题出现在剩下两个函数中。但是其实check008比较简单,就是一个dfs,而且只用判断继承关系,所以我首先检查check009。我原本的思路是,对每个类将他自己和所有子类实现的接口存在一个list里面,然后再遍历这个list里的接口,将它们实现的接口继续添加到list中,最后看这个list有没有重复的元素,如果有就是重复继承。但是这样做会有问题,如果一个类多次继承另一个类,父类即使没有重复实现一个接口,在list里面也会存多次。
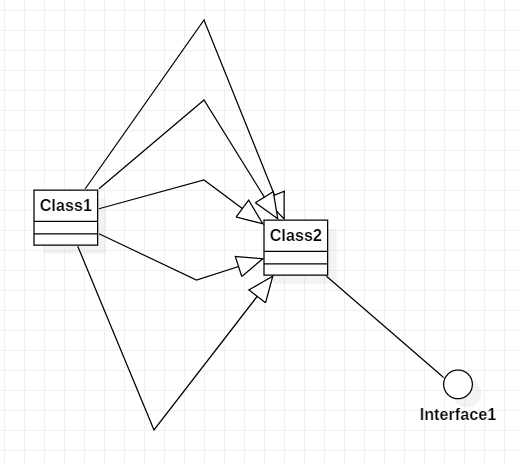
这个图本来没有重复实现接口,但用我的算法会报错,于是我对我的算法做了改进。先将类自己和所有父类,父类的父类...存在一个set中,再遍历这个set,按照前面的方法将接口存在list中判断是否有重复,这样就能有效避免类重复继承另一个类的情况,改到这里,mid5也就顺利通过了。在这次debug的痛苦经历中,我采用了逐步缩小bug范围的方法进行逐一侦查,虽说最后找到了bug,但过程中也十分绝望和疲惫,以后在写代码之前应该深思熟虑,尽量不要写完再找bug,这样得不偿失。
架构分析
第一次看到mdj文件时,我就觉得它是一个树形结构,于是我就用树来存储element,树的结构是
1 import java.util.HashSet; 2 import java.util.Objects; 3 4 import com.oocourse.uml2.models.elements.UmlElement; 5 6 public class Tree { 7 8 private UmlElement element; 9 private String id; 10 private HashSet<Tree> child; 11 12 public Tree() { 13 element = null; 14 id = null; 15 child = null; 16 } 17 18 public Tree(String id, Tree parent) { 19 this.element = null; 20 this.id = id; 21 child = null; 22 } 23 24 public Tree(UmlElement element, Tree parent) { 25 this.element = element; 26 id = element.getId(); 27 child = null; 28 } 29 30 public Tree addChild(String parentId, Tree tree) { 31 if (child == null) { 32 child = new HashSet<>(); 33 } 34 Tree childTree = new Tree(parentId, tree); 35 child.add(childTree); 36 return childTree; 37 } 38 39 public Tree addChild(UmlElement ele, Tree tree) { 40 if (child == null) { 41 child = new HashSet<>(); 42 } 43 Tree childTree = new Tree(ele, tree); 44 child.add(childTree); 45 return childTree; 46 } 47 48 public void addChild(Tree tree) { 49 if (child == null) { 50 child = new HashSet<>(); 51 } 52 child.add(tree); 53 } 54 55 @Override 56 public int hashCode() { 57 return Objects.hash(id); 58 } 59 60 @Override 61 public boolean equals(Object obj) { 62 if (this == obj) { 63 return true; 64 } 65 if (obj == null || getClass() != obj.getClass()) { 66 return false; 67 } 68 Tree that = (Tree) obj; 69 return Objects.equals(id, that.getId()); 70 } 71 72 public UmlElement getElement() { 73 return element; 74 } 75 76 public String getId() { 77 return id; 78 } 79 80 public HashSet<Tree> getChild() { 81 return child; 82 } 83 }
这种树结构为后面的代码提供了很大的方便,比如第一次作业要查关于类图的,就可以在child中找到所有parent_id是这个类id的element。顺序图和状态图也是一样。
第一单元的架构设计
第一单元主要是利用正则表达式将输入的表达式分解成项,项分解成因子,再对因子求导,将求导结果组合成项进而组合成表达式的过程。
第一次作业我没能很好地完成从面向过程到面向对象的转变,一共只设计了两个类,因为每个项都只有幂函数,所以可以很方便地用正则表达式来匹配每一项,于是用正则表达式将输入裁剪成项逐个处理。
第二次作业加入了三角函数部分,因为没有因子的嵌套,每一项都可以用系数、sin(x)指数、cos(x)指数和x指数来唯一确定,这就对合并同类项这一步骤产证了很大的帮助。这一次设计已经能较好的实现复用和类的继承关系了。并且尝试使用了工厂模式。
第三次作业用了递归来求,这个程序几乎没有保存任何输入数据,都是输入、求导后直接输出,这使得化简变得比较困难,所以我只化简了输出的“*0项“”和“1*”因子,性能分没有得到。这次的思路就与第一次不同了,因为用正则表达式来匹配一个可以无限嵌套的因子可以说是不可能的,因此我采用的方式是:用“+”将整个表达式分成项,在项内用“*”将其分解成因子,在因子中匹配“x”、“sin(x)”、“cos(x)”和嵌套因子,匹配到“x”、“sin(x)”和“cos(x)”时终止递归。
第二单元的架构设计
第二单元主要是多线程,要处理好线程之间的互斥问题,而且调试有一定的困难。
这一单元处理的更多是类之间的交互,我觉得是对我面向对象思维提升最大的一个单元,类之间通过消息进行相互沟通。从设计层面我也是最开始先设计架构,没有一上来就写代码,我觉得设计好了之后写代码是一件非常轻松的事情。
第五次作业fafs电梯采用两个线程,一个输入输出线程,一个电梯线程。采用生产者消费者模式,中间的托盘为调度器,调度器中部分方法声明为synchronized。采用wait、notifyAll模式,如果请求队列为空则wait,如果输入请求或者输入null则notifyAll。输入线程结束的条件为输入null,电梯线程结束的条件为输入null且请求队列为空且电梯没有正在运行。由于是FAFS调度策略,于是请求全部保存在一个先入先出的队列中。
第六次作业als电梯,设计大体与第一次类似,加入了捎带。我的捎带策略是:
①从队列中取出一个最早来的请求作为主请求
②如果currentFloor和mainRequestFrom不是同一层,则电梯要从currentFloor到mainRequestFrom,在这个过程中捎带同方向的from和to在currentFloor和mainRequestFrom之间的请求。
③在mainRequestFrom到mainRequestTo的过程中捎带所有同方向的from在mainRequestFrom和mainRequestTo之间的请求。这种策略效果不是太好,性能分会比较低。
第七次作业ss电梯,我没有沿用第六次作业的设计,而是采用look算法,采用固定的分配与调度策略,使得性能分有部分提高。
第三单元的架构设计
第三单元是根据jml完成一个地铁线路图的查询,这一单元主要考虑的因素成为了用什么合适的数据局结构来降低复杂度。这一次有官方包的出现,我们只是填部分函数来实现需要的功能,一个函数实现一个功能,这是我对面向对象的感觉进一步加深了。
第九次作业比较简单,但是我还是经历了一次重构,最开始没有考虑到时间复杂度的问题,全部使用arrayList容器导致时间复杂度特别高。这也给我自己一个提醒,在后面的作业中格外注重时间复杂度的控制。我在add和remove之后直接计算出所有要查的东西,这样每次查询的时间复杂度都是O(1)。
第十次作业加入了最短路径的查询,我没有像第一次那样在每次add和remove之后直接计算出所有需要查询的东西,而是在每次查最短路径时才进行查询,并将查询结果保存在cache中,每次在add和remove中清除cache。
第十一次作业沿用第二次的策略,加到4个cache,采取重构图的方法。具体方法在这篇博客中。
第四单元架构设计
说实话我觉得我第四单元的架构设计并不理想,感觉又回到了面向过程的思维方式,虽然设计了五个类,但是其中两个类都是因为另一个类太长不符合代码风格要求而分出去的,也就是说如果不考虑代码风格,我完全可以用三个类解决这次的问题。我看了一个同学的设计,发现它的架构比较符合面向对象的思路,在这里向他学习一下,这是他的类图:

他的层次感特别清晰,将信息分配给不同的类进行处理,每个类各司其职,可读性和可扩展性都很高。
我的两次作业的架构差不多,对于不考虑继承关系的元素,都是直接遍历class的所有子树,对于考虑继承和接口的都采用递归的方式。
第一次作业的类图
第二次作业的类图
关于测试
这学期采用互测屋的方式,除了第一单元我曾尝试用读代码的方式来发现别人的bug,后面都是用用对拍器来找bug,在这种方式下,写一次代码还会完成一次写对拍器,有双份的提高。要想能找到别人的bug,自己也得对规则有充分的理解,并且在写代码时就会思考哪里别人有可能栽跟头,将这些样例提前保存起来,等到互测的时候使用,这样也能提高自己代码的质量。
收获
在这一学期的oo课中,我收获了很多。
1.基本完成了从面向过程到面向对象的转变,对面向对象有了自己的感悟。
2.较为熟练地掌握了java这门语言,能较好地应用。
3.掌握了一些设计模式,名且运用在作业中
4.复习了之前学过的数据结构的知识,并能较好的掌握。
5.多线程部分可以实现简单的线程间的交互,并能较好的处理同步和互斥的问题。
6.对jml的认识停留在可以看懂jml语言表达的意思,但是如果自己上手写可能还有一定的困难,尤其是语法方面不太确定。
7.uml中三种图掌握地比较熟练了,不得不说用写解析uml代码的方式来学习uml图确实是一个好办法,为了构造测试样例不得不自己画很多的uml图。
建议
1.降低进入强测得门槛,如中测通过90%即可进入强测,因为有时中测的一个点卡住进不了强测是一件十分难受的事情。
2.建议推出微信企业号,在微信上收到消息更新,而不用总是盯着网站或者水群。
3.对于上机实验,上午学习下午直接实践,没有消化的过程,感觉效果不太明显。
4.讨论课建议增加小组互动环节,根据作业情况分组,使每个小组都有abc组的人,这样同学之间的交流会更有帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号