django
Django简介
想要了解什么是Django,得从基础开始一步一步来
HTTP协议
什么是HTTP协议呢?
我们可以从http的特性,数据格式,响应码等方式来了解
什么是四大特性
http的四大特性主要有以下四点:
1.基于TCP/IP之上作用于应用层
2.基于请求响应
3.无状态 cookie session token...
无状态,指的是每次连接都被服务器当做第一次连接。那么怎么才能让服务器识别用户呢?这个时候就要用到cookie和session
4.无连接
无连接指的是每次和服务器进行信息交互一次都会断开连接
长连接 websocket(HTTP协议的大补丁)
数据格式
http的数据格式一般分为请求格式和响应格式:
请求格式
请求首行(请求方式,协议版本。。。)
请求头(一大堆k:v键值对)
\r\n
请求体(真正的数据 发post请求的时候才有 如果是get请求不会有)
响应格式
响应首行
响应头
\r\n
响应体
响应状态码
响应状态码则是用一些特殊的数字来表示和服务器连接的某种状态
常用的状态码有以下几种:
1XX:服务端已经成功接收到了你的数据 正在处理 你可以继续提交其他数据
2XX:服务端成功响应(200请求成功)
3XX:重定向
4XX:请求错误(404 请求资源不存在 403 拒绝访问)
5XX:服务器内部错误(500 )
请求方式
get请求
朝别人要数据
post请求
向别人提交数据(eg:用户登录)
纯手撸web框架
我们可以利用socket来实现简单的web框架:
import socket
server = socket.socket()
server.bind(('127.0.0.1', 8080))
server.listen(5)
"""
请求首行
b'GET /index HTTP/1.1\r\n
请求头
Host: 127.0.0.1:8080\r\n
Connection: keep-alive\r\n
Cache-Control: max-age=0\r\n
DNT: 1\r\n
Upgrade-Insecure-Requests: 1\r\n
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36\r\n
Sec-Fetch-Mode: navigate\r\n
Sec-Fetch-User: ?1\r\n
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3\r\n
Sec-Fetch-Site: none\r\n
Accept-Encoding: gzip, deflate, br\r\n
Accept-Language: zh-CN,zh;q=0.9\r\n
\r\n
请求体
'
"""
while True:
conn, addr = server.accept()
data = conn.recv(1024)
# print(data)
conn.send(b'HTTP/1.1 200 OK\r\n\r\n')
data = data.decode('utf-8')
current_path = data.split('\r\n')[0].split(' ')[1]
# print(current_path)
if current_path == '/index':
# conn.send(b'index')
with open(r'index.html','rb') as f:
conn.send(f.read())
elif current_path == '/login':
conn.send(b'login')
else:
conn.send(b'404 error')
conn.close()
python主流三大框架
Django:
大而全 自带的功能特别特别多 类似于航空母舰
有时候过于笨重
Flask
小而精 自带的功能特别特别少 类似于游骑兵
第三方的模块特别特别多,如果将flask第三方模块全部加起来 完全可以超过django
比较依赖于第三方模块
Tornado
异步非阻塞
牛逼到可以开发游戏服务器
Django简单操作
Django
版本
安装
pip安装
pip install django 安装最新版本的
pip install django==1.11.11 安装指定版本的
验证安装
直接去代码中调用django的模块
import django
print(django.get_version())
1.11.11
或者命令行使用
django-admin
创建项目
命令行注意要在文件相对应的目录创建文件
创建django项目
django-admin startproject zx1
启动django项目-测试服务器,压力很小,500左右
python manage.py runserver ctrl+c关闭
创建应用app
python manage.py startapp app01
注意
1.新创建的命令行新建的app需要自己去setting文件中注册
2.pycharm只会帮你注册第一个你用pycharm创建的应用
django目录
mysite
mysite Python包
__init__.py 项目可以作为包
settings.py 全局设置文件
urls.py 全局路由控制
wsgi.py wsgi服务器的配置文件(高并发的)
manage.py Djago项目管理
app目录
app
__init__.py 项目可以是一个包
admin.py 数据库如果希望被后台看到,需要在这个文件注册
models 创建该APP可能使用到的数据库
test 测试
views 实现对应业务的函数
配置全局路由
1.x是相当于2.x的re_path,是可以支持正则匹配的路由
2.x的path是不支持正则的
url(r'',zx1_views.index)
数据库生成命令
创建默认数据库,每次修改models.py数据模型,都要执行下面两句
python manage.py makemigrations 检查数据库差异(同步),生成迁移文件(migrations)
python manage.py migrate 根据迁移文件生成对应的SQL语句
创建admin用户
python manage.py createsuperuser
setting配置
时区和语言设置
LANGUAGE_CODE = 'zh-Hans'
TIME_ZONE = 'Asia/Shanghai'
配置app
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app01'
]
app-url配置
django
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'zx',zx1_views.index),
url(r'app01',include('app01.urls')),
# url('app01',include('app01.urls',namespace='app01'))
]
app
urlpatterns = [
url(r'login/',views.login)
]
配置数据库-mysql
主要注意
1.在django orm中没有char字段,但是django暴露给用户可以自定义char字段的功能
2.增加字段,如果数据库已经有数据,需要给新增的字段添加默认值,或者设为空(default,null=True)
__init__.py配置MYSQLdb,django默认回去使用MYSQLdb
使用pymysql代替MYSQLdb
import pymysql
pymysql.install_as_MySQLdb()
DATABASES = {
'default':{
'ENGINE':'django.db.backends.mysql',
'USER':'root',
'PASSWORD':'root',
'HOST':'127.0.0.1',
'PORT':3306,
'CHARSET':'UTF8'
}
}
id = models.AutoField(primary_key=True) 在django中,可以不指定主键字段
django orm会自动给当前表新建一个名为id的主键
页面资源配置
pycharm自己会创建
手动在项目下创建一个templates文件
'DIRS': [os.path.join(BASE_DIR, 'templates')],
return render(request,'login.html')
模板渲染
<h1><span>{{date}}</span>欢迎来到登录界面</h1>
today = datetime.datetime.now()
content = {'date':today}
return render(request,'login.html',content)
模板语法
变量相关:{{}}
逻辑相关:{%%}
静态资源
创建static静态资源文件夹
STATIC_PATH = os.path.join(BASE_DIR,'static')
STATICFILES_DIRS = (
STATIC_PATH,
)
STATIC_URL = '/static/' 开头,可以更改,但是要和html的对应
#引用 动态的和STATIC_URL相互对应
{% load staticfiles %}
<img src="{% static 'img/Mysql.jpg' %}" alt="">
CSRF
跳过csrf
1.{% csrf_token %}在from表单中加
2.# 'django.middleware.csrf.CsrfViewMiddleware',在setting中注释
返回数据
三板斧
from django.shortcuts import render,HttpResponse,redirect
HttpResponse # 返回字符串的
render # 返回html页面
redirect # 重定向
request
获取post请求的数据
request.POST
获取get请求携带的数据
request.GET
request.POST.get('username') 默认只取数据列表最后一个元素
如果想要取出所有的元素,就必须使用getlist()
Django中路由的作用
URL配置(URLconf)就像Django 所支撑网站的目录。它的本质是URL与要为该URL调用的视图函数之间的映射表;你就是以这种方式告诉Django,对于客户端发来的某个URL调用哪一段逻辑代码对应执行
例:
from django.urls import path
urlpatterns = [
path('articles', views.special),
]
articles这个路由对应着视图函数中special这个方法,浏览器输入这个链接,就会响应到special这个函数来执行
简单的路由配置
# urls.py
from django.conf.urls import url
# 由一条条映射关系组成的urlpatterns这个列表称之为路由表
urlpatterns = [
url(regex, view, kwargs=None, name=None), # url本质就是一个函数
]
#函数url关键参数介绍
# regex:正则表达式,用来匹配url地址的路径部分,
# 例如url地址为:http://127.0.0.1:8001/index/,正则表达式要匹配的部分是index/
# view:通常为一个视图函数,用来处理业务逻辑
# kwargs:略(用法详见有名分组)
# name:略(用法详见反向解析)
- 正则表达式:一个正则表达式字符串
- views视图函数:一个可调用对象,通常为一个视图函数或一个指定视图函数路径的字符串
- 参数:可选的要传递给视图函数的默认参数(字典形式)
- 别名:一个可选的name参数
例:
from django.conf.urls import url
from django.contrib import admin
from app01 import views # 导入模块views.py
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^index/$',views.index), # 新增一条
]
views.py文件
from django.shortcuts import render
from django.shortcuts import HttpResponse # 导入HttpResponse,用来生成响应信息
# 新增视图函数index
def index(request):
return HttpResponse('index page...')
测试:
python manage.py runserver 8001 # 在浏览器输入:http://127.0.0.1:8001/index/ 会看到 index page...
注意一:
刚刚我们在浏览器输入:http://127.0.0.1:8001/index/,Django会拿着路径部分index/去路由表中自上而下匹配正则表达式,一旦匹配成功,则立即执行其后的视图函数,不会继续往下匹配,此处匹配成功的正则表达式是 r'^index/$'。
注意二:
但是我们在浏览器输入:http://127.0.0.1:8001/index,Django同样会拿着路径部分index去路由表中自上而下匹配正则表达式,貌似并不会匹配成功任何正则表达式( r'^index/$'匹配的是必须以 / 结尾,所以不会匹配成功index),但实际上仍然会看到结果 index page...
原因如下:
在配置文件settings.py中有一个参数APPEND_SLASH,该参数有两个值True或False
当APPEND_SLASH=True(如果配置文件中没有该配置,APPEND_SLASH的默认值为True),并且用户请求的url地址的路径部分不是以 / 结尾,例如请求的url地址是 http://127.0.0.1:8001/index,Django会拿着路径部分(即index)去路由表中匹配正则表达式,发现匹配不成功,那么Django会在路径后加 / (即index/)再去路由表中匹配,如果匹配失败则会返回路径未找到,如果匹配成功,则会返回重定向信息给浏览器,要求浏览器重新向 http://127.0.0.1:8001/index/地址发送请求。
当APPEND_SLASH=False时,则不会执行上述过程,即一旦url地址的路径部分匹配失败就立即返回路径未找到,不会做任何的附加操作
分组
什么是分组、为何要分组呢?比如我们开发了一个博客系统,当我们需要根据文章的id查看指定文章时,浏览器在发送请求时需要向后台传递参数(文章的id号),可以使用 http://127.0.0.1:8001/article/?id=3,也可以直接将参数放到路径中http://127.0.0.1:8001/article/3/
针对后一种方式Django就需要直接从路径中取出参数,这就用到了正则表达式的分组功能了,分组分为两种:无名分组与有名分组
无名分组
url.py文件
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
# 下述正则表达式会匹配url地址的路径部分为:article/数字/,匹配成功的分组部分会以位置参数的形式传给视图函数,有几个分组就传几个位置参数
url(r'^aritcle/(\d+)/$',views.article),
]
views.py文件
from django.shortcuts import render
from django.shortcuts import HttpResponse
# 需要额外增加一个形参用于接收传递过来的分组数据
def article(request,article_id):
return HttpResponse('id为 %s 的文章内容...' %article_id)
测试:
python manage.py runserver 8001 # 在浏览器输入:http://127.0.0.1:8001/article/3/ 会看到: id为 3 的文章内容...
有名分组
url.py文件
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
# 该正则会匹配url地址的路径部分为:article/数字/,匹配成功的分组部分会以关键字参数(article_id=匹配成功的数字)的形式传给视图函数,有几个有名分组就会传几个关键字参数
url(r'^aritcle/(?P<article_id>\d+)/$',views.article),
]
views.py文件
from django.shortcuts import render
from django.shortcuts import HttpResponse
# 需要额外增加一个形参,形参名必须为article_id
def article(request,article_id):
return HttpResponse('id为 %s 的文章内容...' %article_id)
测试:
python manage.py runserver 8001 # 在浏览器输入:http://127.0.0.1:8001/article/3/ 会看到: id为 3 的文章内容...
总结:有名分组和无名分组都是为了获取路径中的参数,并传递给视图函数,区别在于无名分组是以位置参数的形式传递,有名分组是以关键字参数的形式传递。
强调:无名分组和有名分组不要混合使用
路由分发
随着项目功能的增加,app会越来越多,路由也越来越多,每个app都会有属于自己的路由,如果再将所有的路由都放到一张路由表中,会导致结构不清晰,不便于管理,所以我们应该将app自己的路由交由自己管理,然后在总路由表中做分发,具体做法如下
创建两个app
# 新建项目mystie2
E:\git>django-admin startproject mysite2
# 切换到项目目录下
E:\git>cd mysite2
# 创建app01和app02
E:\git\mysite2>python3 manage.py startapp app01
E:\git\mysite2>python3 manage.py startapp app02
在每个app下手动创建urls.py文件来存放自己的路由
app01下的urls.py文件
from django.conf.urls import url
# 导入app01的views
from app01 import views
urlpatterns = [
url(r'^index/$',views.index),
]
app01下的views.py文件
from django.shortcuts import render
from django.shortcuts import HttpResponse
def index(request):
return HttpResponse('我是app01的index页面...')
app02下的urls.py文件
from django.conf.urls import url
# 导入app02的views
from app02 import views
urlpatterns = [
url(r'^index/$',views.index),
]
app02下的views.py文件
from django.shortcuts import render
from django.shortcuts import HttpResponse
def index(request):
return HttpResponse('我是app02的index页面...')
在总的urls.py文件中(mysite2文件夹下的urls.py)
from django.conf.urls import url,include
from django.contrib import admin
# 总路由表
urlpatterns = [
url(r'^admin/', admin.site.urls),
# 新增两条路由,注意不能以$结尾
# include函数就是做分发操作的,当在浏览器输入http://127.0.0.1:8001/app01/index/时,会先进入到总路由表中进行匹配,正则表达式r'^app01/'会先匹配成功路径app01/,然后include功能会去app01下的urls.py中继续匹配剩余的路径部分
url(r'^app01/', include('app01.urls')),
url(r'^app02/', include('app02.urls')),
]
测试:
python manage.py runserver 8001
# 在浏览器输入:http://127.0.0.1:8001/app01/index/ 会看到:我是app01的index页面...
# 在浏览器输入:http://127.0.0.1:8001/app02/index/ 会看到:我是app02的index页面...
反向解析
在软件开发初期,url地址的路径设计可能并不完美,后期需要进行调整,如果项目中很多地方使用了该路径,一旦该路径发生变化,就意味着所有使用该路径的地方都需要进行修改,这是一个非常繁琐的操作。
解决方案就是在编写一条url(regex, view, kwargs=None, name=None)时,可以通过参数name为url地址的路径部分起一个别名,项目中就可以通过别名来获取这个路径。以后无论路径如何变化别名与路径始终保持一致。
上述方案中通过别名获取路径的过程称为反向解析
案例:登录成功跳转到index.html页面
在urls.py文件中
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^login/$', views.login,name='login_page'), # 路径login/的别名为login_page
url(r'^index/$', views.index,name='index_page'), # 路径index/的别名为index_page
]
在views.py文件中
from django.shortcuts import render
from django.shortcuts import reverse # 用于反向解析
from django.shortcuts import redirect #用于重定向页面
from django.shortcuts import HttpResponse
def login(request):
if request.method == 'GET':
# 当为get请求时,返回login.html页面,页面中的{% url 'login_page' %}会被反向解析成路径:/login/
return render(request, 'login.html')
# 当为post请求时,可以从request.POST中取出请求体的数据
name = request.POST.get('name')
pwd = request.POST.get('pwd')
if name == 'kevin' and pwd == '123':
url = reverse('index_page') # reverse会将别名'index_page'反向解析成路径:/index/
return redirect(url) # 重定向到/index/
else:
return HttpResponse('用户名或密码错误')
def index(request):
return render(request, 'index.html')
login.html文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>登录页面</title>
</head>
<body>
<!--强调:login_page必须加引号-->
<form action="{% url 'login_page' %}" method="post">
{% csrf_token %} <!--强调:必须加上这一行,后续我们会详细介绍-->
<p>用户名:<input type="text" name="name"></p>
<p>密码:<input type="password" name="pwd"></p>
<p><input type="submit" value="提交"></p>
</form>
</body>
</html>
index.html文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>首页</title>
</head>
<body>
<h3>我是index页面...</h3>
</body>
</html>
测试:
python manage.py runserver 8001
# 在浏览器输入:http://127.0.0.1:8001/login/ 会看到登录页面,输入正确的用户名密码会跳转到index.html
# 当我们修改路由表中匹配路径的正则表达式时,程序其余部分均无需修改
总结:
在views.py中,反向解析的使用:
url = reverse('index_page')
在模版login.html文件中,反向解析的使用
{% url 'login_page' %}
如果路径存在分组的反向解析使用:
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^aritcle/(\d+)/$',views.article,name='article_page'), # 无名分组
url(r'^user/(?P<uid>\d+)/$',views.article,name='user_page'), # 有名分组
]
# 1 针对无名分组,比如我们要反向解析出:/aritcle/1/ 这种路径,写法如下
在views.py中,反向解析的使用:
url = reverse('article_page',args=(1,))
在模版login.html文件中,反向解析的使用
{% url 'article_page' 1 %}
# 2 针对有名分组,比如我们要反向解析出:/user/1/ 这种路径,写法如下
在views.py中,反向解析的使用:
url = reverse('user_page',kwargs={'uid':1})
在模版login.html文件中,反向解析的使用
{% url 'user_page' uid=1 %}
名称空间
命名空间(英语:Namespace)是表示标识符的可见范围。一个标识符可在多个命名空间中定义,它在不同命名空间中的含义是互不相干的。这样,在一个新的命名空间中可定义任何标识符,它们不会与任何已有的标识符发生冲突,因为已有的定义都处于其它命名空间中。
由于name没有作用域,Django在反解URL时,会在项目全局顺序搜索,当查找到第一个name指定URL时,立即返回
我们在开发项目时,会经常使用name属性反解出URL,当不小心在不同的app的urls中定义相同的name时,可能会导致URL反解错误,为了避免这种事情发生,引入了命名空间。
创建两个app
# 新建项目mystie2
E:\git>django-admin startproject mysite2
# 切换到项目目录下
E:\git>cd mysite2
# 创建app01和app02
E:\git\mysite2>python3 manage.py startapp app01
E:\git\mysite2>python3 manage.py startapp app02
在每个app下手动创建urls.py来存放自己的路由,并且为匹配的路径起别名
app01下的urls.py文件
from django.conf.urls import url
from app01 import views
urlpatterns = [
# 为匹配的路径app01/index/起别名'index_page'
url(r'^index/$',views.index,name='index_page'),
]
app02下的urls.py文件
from django.conf.urls import url
from app02 import views
urlpatterns = [
# 为匹配的路径app02/index/起别名'index_page',与app01中的别名相同
url(r'^index/$',views.index,name='index_page'),
]
在每个app下的view.py中编写视图函数,在视图函数中针对别名'index_page'做反向解析
app01下的views.py
from django.shortcuts import render
from django.shortcuts import HttpResponse
from django.shortcuts import reverse
def index(request):
url=reverse('index_page')
return HttpResponse('app01的index页面,反向解析结果为%s' %url)
app02下的views.py
from django.shortcuts import render
from django.shortcuts import HttpResponse
from django.shortcuts import reverse
def index(request):
url=reverse('index_page')
return HttpResponse('app02的index页面,反向解析结果为%s' %url)
在总的urls.py文件中(mysite2文件夹下的urls.py)
from django.conf.urls import url,include
from django.contrib import admin
# 总路由表
urlpatterns = [
url(r'^admin/', admin.site.urls),
# 新增两条路由,注意不能以$结尾
url(r'^app01/', include('app01.urls')),
url(r'^app02/', include('app02.urls')),
]
测试:
python manage.py runserver 8001
在测试时,无论在浏览器输入:http://127.0.0.1:8001/app01/index/还是输入http://127.0.0.1:8001/app02/index/ 针对别名'index_page'反向解析的结果都是/app02/index/,覆盖了app01下别名的解析。
解决这个问题的方法之一就是避免使用相同的别名,如果就想使用相同的别名,那就需要用到django中名称空间的概念,将别名放到不同的名称空间中,这样即便是出现重复,彼此也不会冲突,具体做法如下
总urls.py在路由分发时,指定名称空间
from django.conf.urls import url, include
from django.contrib import admin
# 总路由表
urlpatterns = [
url(r'^admin/', admin.site.urls),
# 传给include功能一个元组,元组的第一个值是路由分发的地址,第二个值则是我们为名称空间起的名字
url(r'^app01/', include(('app01.urls','app01'))),
url(r'^app02/', include(('app02.urls','app02'))),
]
修改每个app下的view.py中视图函数,针对不同名称空间中的别名'index_page'做反向解析
app01下的views.py
from django.shortcuts import render
from django.shortcuts import HttpResponse
from django.shortcuts import reverse
def index(request):
url=reverse('app01:index_page') # 解析的是名称空间app01下的别名'index_page'
return HttpResponse('app01的index页面,反向解析结果为%s' %url)
app02下的views.py
from django.shortcuts import render
from django.shortcuts import HttpResponse
from django.shortcuts import reverse
def index(request):
url=reverse('app02:index_page') # 解析的是名称空间app02下的别名'index_page'
return HttpResponse('app02的index页面,反向解析结果为%s' %url)
测试:
python manage.py runserver 8001
浏览器输入:http://127.0.0.1:8001/app01/index/反向解析的结果是/app01/index/
在浏览器输入http://127.0.0.1:8001/app02/index/ 反向解析的结果是/app02/index/
总结+补充
1、在视图函数中基于名称空间的反向解析,用法如下
url=reverse('名称空间的名字:待解析的别名')
2、在模版里基于名称空间的反向解析,用法如下
<a href="{% url '名称空间的名字:待解析的别名'%}">哈哈</a>
Django2.0版的re_path与path
re_path
Django2.0中的re_path与Django1.0的url一样,传入的第一个参数都是正则表达式
from django.urls import re_path # django2.0中的re_path
from django.conf.urls import url # 在django2.0中同样可以导入1.0中的url
urlpatterns = [
# 用法完全一致
url(r'^app01/', include(('app01.urls','app01'))),
re_path(r'^app02/', include(('app02.urls','app02'))),
]
path
在Django2.0中新增了一个path功能,用来解决:数据类型转换问题与正则表达式冗余问题,如下
urls.py文件
from django.urls import re_path
from app01 import views
urlpatterns = [
# 问题一:数据类型转换
# 正则表达式会将请求路径中的年份匹配成功然后以str类型传递函数year_archive,在函数year_archive中如果想以int类型的格式处理年份,则必须进行数据类型转换
re_path(r'^articles/(?P<year>[0-9]{4})/$', views.year_archive),
# 问题二:正则表达式冗余
# 下述三个路由中匹配article_id采用了同样的正则表达式,重复编写了三遍,存在冗余问题,并且极不容易管理,因为一旦article_id规则需要改变,则必须同时修改三处代码
re_path(r'^article/(?P<article_id>[a-zA-Z0-9]+)/detail/$', views.detail_view),
re_path(r'^articles/(?P<article_id>[a-zA-Z0-9]+)/edit/$', views.edit_view),
re_path(r'^articles/(?P<article_id>[a-zA-Z0-9]+)/delete/$', views.delete_view),
]
views.py
from django.shortcuts import render,HttpResponse
# Create your views here.
def year_archive(request,year):
print(year,type(year))
return HttpResponse('year_archive page')
def detail_view(request,article_id):
print(article_id, type(article_id))
return HttpResponse('detail_view page')
def edit_view(request,article_id):
print(article_id, type(article_id))
return HttpResponse('edit_view page')
def delete_view(request,article_id):
print(article_id, type(article_id))
return HttpResponse('delete_view page')
Django2.0中的path如何解决上述的两个问题呢
例:
from django.urls import path,re_path
from app01 import views
urlpatterns = [
# 问题一的解决方案:
path('articles/<int:year>/', views.year_archive), # <int:year>相当于一个有名分组,其中int是django提供的转换器,相当于正则表达式,专门用于匹配数字类型,而year则是我们为有名分组命的名,并且int会将匹配成功的结果转换成整型后按照格式(year=整型值)传给函数year_archive
# 问题二解决方法:用一个int转换器可以替代多处正则表达式
path('articles/<int:article_id>/detail/', views.detail_view),
path('articles/<int:article_id>/edit/', views.edit_view),
path('articles/<int:article_id>/delete/', views.delete_view),
]
注意:
- path与re_path或者1.0中的url的不同之处是,传给path的第一个参数不再是正则表达式,而是一个完全匹配的路径,相同之处是第一个参数中的匹配字符均无需加前导斜杠
- 使用尖括号(<>)从url中捕获值,相当于有名分组
- <>中可以包含一个转化器类型(converter type),比如使用 使用了转换器int。若果没有转化器,将匹配任何字符串,当然也包括了 / 字符
path转换器
Django默认支持五种转换器(path converters)
str,匹配除了路径分隔符(/)之外的非空字符串,这是默认的形式
int,匹配正整数,包含0。
slug,匹配字母、数字以及横杠、下划线组成的字符串。
uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。
path,匹配任何非空字符串,包含了路径分隔符(/)(不能用?)
例:
path('articles/<int:year>/<int:month>/<slug:other>/', views.article_detail)
# 针对路径http://127.0.0.1:8000/articles/2009/123/hello/,path会匹配出参数year=2009,month=123,other='hello'传递给函数article_detail
自定制转换器
在app01下新建文件path_converters.py,文件名可以随意命名
class MonthConverter:
regex='\d{2}' # 属性名必须为regex
def to_python(self, value):
return int(value)
def to_url(self, value):
return value # 匹配的regex是两个数字,返回的结果也必须是两个数字
在urls.py中,使用register_converters将其注册到URL配置中
from django.urls import path,register_converter
from app01.path_converts import MonthConverter
register_converter(MonthConverter,'mon')
from app01 import views
urlpatterns = [
path('articles/<int:year>/<mon:month>/<slug:other>/', views.article_detail, name='aaa'),
]
views.py中的视图函数article_detail
from django.shortcuts import render,HttpResponse,reverse
def article_detail(request,year,month,other):
print(year,type(year))
print(month,type(month))
print(other,type(other))
print(reverse('xxx',args=(1988,12,'hello'))) # 反向解析结果/articles/1988/12/hello/
return HttpResponse('xxxx')
测试:
# 1、在浏览器输入http://127.0.0.1:8000/articles/2009/12/hello/,path会成功匹配出参数year=2009,month=12,other='hello'传递给函数article_detail
# 2、在浏览器输入http://127.0.0.1:8000/articles/2009/123/hello/,path会匹配失败,因为我们自定义的转换器mon只匹配两位数字,而对应位置的123超过了2位
Django-视图层
三板斧
from django.shortcuts import render,HttpResponse,redirect
HttpResponse # 返回字符串的
render # 返回html页面,可以传值
redirect # 重定向
返回的底层其实都是HttpResponse对象
JsonResponse
给前端返回json字符串
from django.http import JsonResponse
zx = {'username': 'zx 我好喜欢哦~', 'pwd': 'zx123'}
return JsonResponse(zx)
底层调用的就是json模块
data = json.dumps(data, cls=encoder, **json_dumps_params)
ensure_ascii=True
但是默认会把字符串转成ascii,所以要把
return JsonResponse(zx,json_dumps_params={'ensure_ascii':False})
注意:JsonResponse默认只支持序列化字典 如果你想序列化其他类型(json能够支持的类型) 你需要将safe参数由默认的True改成False
l = [1,2,3,4,5,5,6]
return JsonResponse(l,safe=False)
序列化和反序列化
JSON.stringify 序列化 >>> json.dumps
JSON.parse 反序列 >>> json.loads
图片上传
前端
注意:提交方式必须是post,post是不限制大小的,还要修改entype属性
后端request直接把数据这块和POST的数据区分开了,拿取文件数据的时候要用FILES
if request.method == 'POST':
file_obj = request.FILES.get('zx')
print(file_obj.name)#文件名
with open(file_obj.name,'wb')as fw:
for line in file_obj:
fw.write(line)
模板语法
{{}} 变量相关
{%%} 逻辑相关
模板{{}}传值
注意
1.函数对象渲染会执行函数,把返回值传到界面
2.不支持函数传递带参
3.对于容器和对象元素只能通过点取值
过滤器|
看add源码
@register.filter(is_safe=False)
def add(value, arg):
"""Adds the arg to the value."""
try:
return int(value) + int(arg)
except (ValueError, TypeError):
try:
return value + arg
except Exception:
return ''
{{zx|filesizeformat}}文件大小
{{w|truncatechars:10}}截取10个字符...也算
{{w|truncateword:10}}按照空格...不算
{{xxx|default:"这个值为空"}}有值就拿值 没值就用后面默认的
{{zx|slice'0,5,2'}}切片
{{ctime|date:'Y-m-d'}}日期格式化
{{ss|safe}}转义 前端代码可以在后端写好
逻辑{%%}模板
if-elif-else-endif
{% if zx %}
zx不为空
{% elif zx1 %}zx1不为空
{% else %}全为空
{% endif %} for基础用法简单用法
{% for l in lis %}
{{ l }}
字典用法
{% for foo in d.items %}
{{ foo }}
{% for foo in d.keys %}
{{ foo }}
{% for foo in d.values %}
{{ foo }}
{% endfor %}
for高级用法
直接打印forloop,可以给列表加标号
{% for l in zx %}
{{ forloop }}
{% endfor %}
{'parentloop': {}, 'counter0': 1, 'counter': 2, 'revcounter': 5, 'revcounter0': 4, 'first': False, 'last': False}
{'parentloop': {}, 'counter0': 2, 'counter': 3, 'revcounter': 4, 'revcounter0': 3, 'first': False, 'last': False}
{'parentloop': {}, 'counter0': 3, 'counter': 4, 'revcounter': 3, 'revcounter0': 2, 'first': False, 'last': False}
{'parentloop': {}, 'counter0': 4, 'counter': 5, 'revcounter': 2, 'revcounter0': 1, 'first': False, 'last': False}
{'parentloop': {}, 'counter0': 5, 'counter': 6, 'revcounter': 1, 'revcounter0': 0, 'first': False, 'last': True}
用法
{% for foo in zx %}
{% if forloop.first %}
这是我的第一次
{% elif forloop.last %}
这是最后一次了啊
{% else %}
我在中间~
{% endif %}
注意当xo为空是可以进入for的,而且可以和{% empty %}一起用
{% for l in zx %}
不是空啊
{% empty %}
空啊
{% endfor %}
取别名{%with%}
{% with yyy.user_list.2.username.1 as dsb %}
{{ dsb }}
{{ yyy.user_list.2.username.1 }}
{{ dsb }}
{% endwith %}
自定义过滤器、标签
步骤
1 在应用名下面新建一个templatetags文件夹(必须叫这个名字)
2 在改文件夹下 新建一个任意名称的py文件
3 在该py文件内 固定先写两行代码
from django.template import Library
register = Library()
案例
from django.template import Library
register = Library()
@register.filter(name='myplus')
def index(a,b):
return a + b
@register.simple_tag(name='mysm')
def login(a,b,c,d):
return '%s/%s/%s/%s'%(a,b,c,d)
使用时注意添加
{% load my_tag %}
自定义
{{ 123|myplus:123 }}
{{ 123|myplus:'[1,2,3,4,5,6,7,8,]' }}这样可以在函数内拆分字符串实现,列表内数字取出应用
{% load my_tag %}
{% mysm 1 2 3 4 %}
区别
区别 标签不能再if中使用
{% if 0|myplus:123 %} 可以用
有值
{% endif %}{% if mysm 1 2 3 4 %} 不能用
有值
{% endif %} 模板继承 定义{% block 区域名字 %}
{% endblock %}
母模板
事先需要在母模板中 通过block划定区域
{% endblock %}
{% block content %}
<div class="jumbotron">
<h1>Hello, world!</h1>
<p>...</p>
<p><a class="btn btn-primary btn-lg" href="#" role="button">Learn more</a></p>
</div>
{% endblock %}
{% block js %}
{% endblock %}
子继承
{% extends '模板的名字'%}
{% block css %}
css
{% endblock %}
{% block content %}
html
{% endblock %}
{% block js %}
js
{% endblock %}
一个页面上 block块越多 页面的扩展性越高
通常情况下 都应该有三片区域
{% endblock %}
{% block content %}
{% endblock %}
{% block js %}
{% endblock %}
子板中还可以通过
{{ block.super }} 来继续使用母版的内容,注意是放在block块里面使用,而且可以叠加
模板的导入
当你写了一个特别好看的form表单 你想再多个页面上都使用这个form表单
你就可以将你写的form表单当作模块的形式导入 导入过来之后 就可以直接展示
AJAX准备知识:JSON
什么是 JSON ?
- JSON 指的是 JavaScript 对象表示法(JavaScript Object Notation)
- JSON 是轻量级的文本数据交换格式
- JSON 独立于语言 *
- JSON 具有自我描述性,更易理解
* JSON 使用 JavaScript 语法来描述数据对象,但是 JSON 仍然独立于语言和平台。JSON 解析器和 JSON 库支持许多不同的编程语言。
啥都别多说了,上图吧!

合格的json对象(json只认双引的字符串格式):
["one", "two", "three"]
{ "one": 1, "two": 2, "three": 3 }
{"names": ["张三", "李四"] }
[ { "name": "张三"}, {"name": "李四"} ]
不合格的json对象:
[ ](javascript:void(0)😉
](javascript:void(0)😉
{ name: "张三", 'age': 32 } // 属性名必须使用双引号
[32, 64, 128, 0xFFF] // 不能使用十六进制值
{ "name": "张三", "age": undefined } // 不能使用undefined
{ "name": "张三",
"birthday": new Date('Fri, 26 Aug 2011 07:13:10 GMT'),
"getName": function() {return this.name;} // 不能使用函数和日期对象
}
[](javascript:void(0)😉
stringify与parse方法
JavaScript中关于JSON对象和字符串转换的两个方法:
JSON.parse(): 用于将一个 JSON 字符串转换为 JavaScript 对象(json只认双引的字符串格式)
JSON.parse('{"name":"Howker"}');
JSON.parse('{name:"Stack"}') ; // 错误
JSON.parse('[18,undefined]') ; // 错误
JSON.stringify(): 用于将 JavaScript 值转换为 JSON 字符串。
JSON.stringify({"name":"Tonny"})
和XML的比较
JSON 格式于2001年由 Douglas Crockford 提出,目的就是取代繁琐笨重的 XML 格式。
JSON 格式有两个显著的优点:书写简单,一目了然;符合 JavaScript 原生语法,可以由解释引擎直接处理,不用另外添加解析代码。所以,JSON迅速被接受,已经成为各大网站交换数据的标准格式,并被写入ECMAScript 5,成为标准的一部分。
XML和JSON都使用结构化方法来标记数据,下面来做一个简单的比较。
用XML表示中国部分省市数据如下:
 XML格式数据
XML格式数据
用JSON表示如下:
JSON格式数据
由上面的两端代码可以看出,JSON 简单的语法格式和清晰的层次结构明显要比 XML 容易阅读,并且在数据交换方面,由于 JSON 所使用的字符要比 XML 少得多,可以大大得节约传输数据所占用得带宽。
AJAX简介
AJAX(Asynchronous Javascript And XML)翻译成中文就是“异步的Javascript和XML”。即使用Javascript语言与服务器进行异步交互,传输的数据为XML(当然,传输的数据不只是XML)。
AJAX 不是新的编程语言,而是一种使用现有标准的新方法。
AJAX 最大的优点是在不重新加载整个页面的情况下,可以与服务器交换数据并更新部分网页内容。(这一特点给用户的感受是在不知不觉中完成请求和响应过程)
AJAX 不需要任何浏览器插件,但需要用户允许JavaScript在浏览器上执行。
- 同步交互:客户端发出一个请求后,需要等待服务器响应结束后,才能发出第二个请求;
- 异步交互:客户端发出一个请求后,无需等待服务器响应结束,就可以发出第二个请求。
示例
页面输入两个整数,通过AJAX传输到后端计算出结果并返回。
HTML部分代码
views.py
urls.py
AJAX****常见应用情景
搜索引擎根据用户输入的关键字,自动提示检索关键字。
还有一个很重要的应用场景就是注册时候的用户名的查重。
其实这里就使用了AJAX技术!当文件框发生了输入变化时,使用AJAX技术向服务器发送一个请求,然后服务器会把查询到的结果响应给浏览器,最后再把后端返回的结果展示出来。
- 整个过程中页面没有刷新,只是刷新页面中的局部位置而已!
- 当请求发出后,浏览器还可以进行其他操作,无需等待服务器的响应!
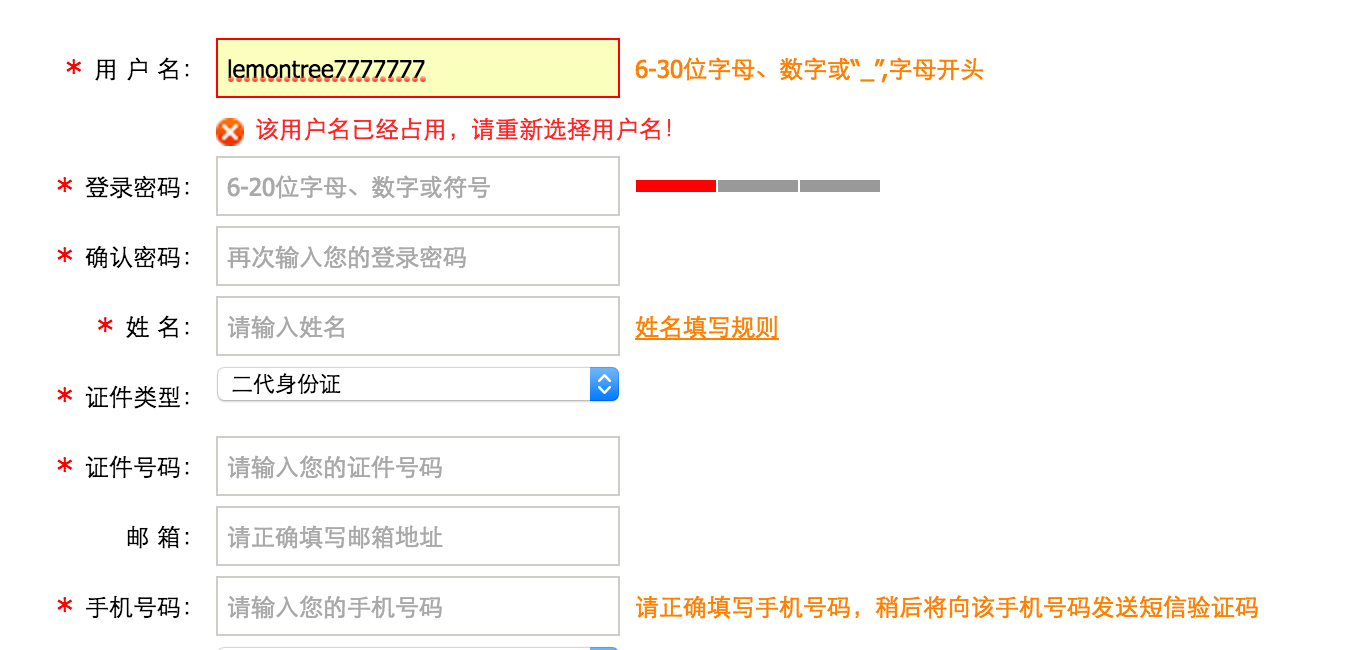
当输入用户名后,把光标移动到其他表单项上时,浏览器会使用AJAX技术向服务器发出请求,服务器会查询名为lemontree7777777的用户是否存在,最终服务器返回true表示名为lemontree7777777的用户已经存在了,浏览器在得到结果后显示“用户名已被注册!”。
- 整个过程中页面没有刷新,只是局部刷新了;
- 在请求发出后,浏览器不用等待服务器响应结果就可以进行其他操作;
AJAX****的优缺点
优点:
- AJAX使用JavaScript技术向服务器发送异步请求;
- AJAX请求无须刷新整个页面;
- 因为服务器响应内容不再是整个页面,而是页面中的部分内容,所以AJAX性能高;
- 两个关键点:1.局部刷新,2.异步请求
jQuery实现的AJAX
最基本的jQuery发送AJAX请求示例:
请一定点开看一看
views.py:
views.py
$.ajax参数
data参数中的键值对,如果值值不为字符串,需要将其转换成字符串类型。
[](javascript:void(0)😉
$("#b1").on("click", function () {
$.ajax({
url:"/ajax_add/",
type:"GET",
data:{"i1":$("#i1").val(),"i2":$("#i2").val(),"hehe": JSON.stringify([1, 2, 3])},
success:function (data) {
$("#i3").val(data);
}
})
})
[](javascript:void(0)😉
JS实现AJAX(了解)
View Code
AJAX请求如何设置csrf_token
不论是ajax还是谁,只要是向我Django提交post请求的数据,都必须校验csrf_token来防伪跨站请求,那么如何在我的ajax中弄这个csrf_token呢,我又不像form表单那样可以在表单内部通过一句{% csrf_token %}就搞定了......
方式1
通过获取隐藏的input标签中的csrfmiddlewaretoken值,放置在data中发送。
[](javascript:void(0)😉
$.ajax({
url: "/cookie_ajax/",
type: "POST",
data: {
"username": "Tonny",
"password": 123456,
"csrfmiddlewaretoken": $("[name = 'csrfmiddlewaretoken']").val() // 使用JQuery取出csrfmiddlewaretoken的值,拼接到data中
},
success: function (data) {
console.log(data);
}
})
[](javascript:void(0)😉
方式2
通过获取返回的cookie中的字符串 放置在请求头中发送。
注意:需要引入一个jquery.cookie.js插件。
View Code
方式3
或者用自己写一个getCookie方法:
View Code
每一次都这么写太麻烦了,可以使用$.ajaxSetup()方法为ajax请求统一设置。
[](javascript:void(0)😉
function csrfSafeMethod(method) {
// these HTTP methods do not require CSRF protection
return (/^(GET|HEAD|OPTIONS|TRACE)$/.test(method));
}
$.ajaxSetup({
beforeSend: function (xhr, settings) {
if (!csrfSafeMethod(settings.type) && !this.crossDomain) {
xhr.setRequestHeader("X-CSRFToken", csrftoken);
}
}
});
[](javascript:void(0)😉
将下面的文件配置到你的Django项目的静态文件中,在html页面上通过导入该文件即可自动帮我们解决ajax提交post数据时校验csrf_token的问题,(导入该配置文件之前,需要先导入jQuery,因为这个配置文件内的内容是基于jQuery来实现的)
更多细节详见:Djagno官方文档中关于CSRF的内容
练习(用户名是否已被注册)
功能介绍
在注册表单中,当用户填写了用户名后,把光标移开后,会自动向服务器发送异步请求。服务器返回这个用户名是否已经被注册过。
案例分析
- 页面中给出注册表单;
- 在username input标签中绑定onblur事件处理函数。
- 当input标签失去焦点后获取 username表单字段的值,向服务端发送AJAX请求;
- django的视图函数中处理该请求,获取username值,判断该用户在数据库中是否被注册,如果被注册了就返回“该用户已被注册”,否则响应“该用户名可以注册”。
答案就在前面的示例中,看你能不能找到了......
序列化
Django内置的serializers
什么意思呢?就是我的前段想拿到由ORM得到的数据库里面的一个个用户对象,我的后端想直接将实例化出来的数据对象直接发送给客户端,那么这个时候,就可以用Django给我们提供的序列化方式
[](javascript:void(0)😉
def ser(request):
#拿到用户表里面的所有的用户对象
user_list=models.User.objects.all()
#导入内置序列化模块
from django.core import serializers
#调用该模块下的方法,第一个参数是你想以什么样的方式序列化你的数据
ret=serializers.serialize('json',user_list)
return HttpResponse(ret)
[](javascript:void(0)😉

补充一个SweetAlert插件示例

[](javascript:void(0)😉
$("#b55").click(function () {
swal({
title: "你确定要删除吗?",
text: "删除可就找不回来了哦!",
type: "warning",
showCancelButton: true, // 是否显示取消按钮
confirmButtonClass: "btn-danger", // 确认按钮的样式类
confirmButtonText: "删除", // 确认按钮文本
cancelButtonText: "取消", // 取消按钮文本
closeOnConfirm: false, // 点击确认按钮不关闭弹框
showLoaderOnConfirm: true // 显示正在删除的动画效果
},
function () {
var deleteId = 2;
$.ajax({
url: "/delete_book/",
type: "post",
data: {"id": deleteId},
success: function (data) {
if (data.code === 0) {
swal("删除成功!", "你可以准备跑路了!", "success");
} else {
swal("删除失败", "你可以再尝试一下!", "error")
}
}
})
});
})
[](javascript:void(0)😉
上面这个二次确认的动态框样式,你也可以直接应用到你的项目中
提醒事项:
1.上述的样式类部分渲染的样式来自于bootstrap中,所有建议在使用上述样式时,将bootstrap的js和css也导入了,这样的情况下,页面效果就不会有任何问题
2.弹出的上述模态框中,可能字体会被图标掩盖一部分,可通过调整字体的上外边距来解决


 浙公网安备 33010602011771号
浙公网安备 33010602011771号