

| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018SE1/homework/11250 |
|---|---|
| 作业目标 | 学习并使用 网络爬虫 |
| 作业源代码 | https://gitee.com/hu-yubin/pair-work |
| 胡玉彬 | 211806319 |
| 张恒 | 211806423 |
时间
| 代码行数 | 171+54 |
| 需求分析时间 | 120分钟 |
| 代码实现时间 | 10小时 |
结对的过程
结对照片
结对感受
张恒:我擅长的方面不多,跟队友一起进行编码可以让我学习到更多的东西。
胡玉彬:上学期的东西我快忘完了,有个小伙伴一起写代码,还能交流想法,蛮不错的。
思路
1.先将网站的中找到我们所需要的的cookie和url(cookie有很多,别找错了)

2.设计一个pojo类student来传递数据
3.我们进入班课以后,班课里有很多的活动,每个活动的url都不一样,我们需要将每个课堂完成部分的url给爬下来,有14个
4.我们需要把每个活动的url里的源代码爬出来,并将里面我们需要的学号姓名和成绩解析出来
5.然后将每个活动里每个同学的分数相加,并进行排序,变成一个集合
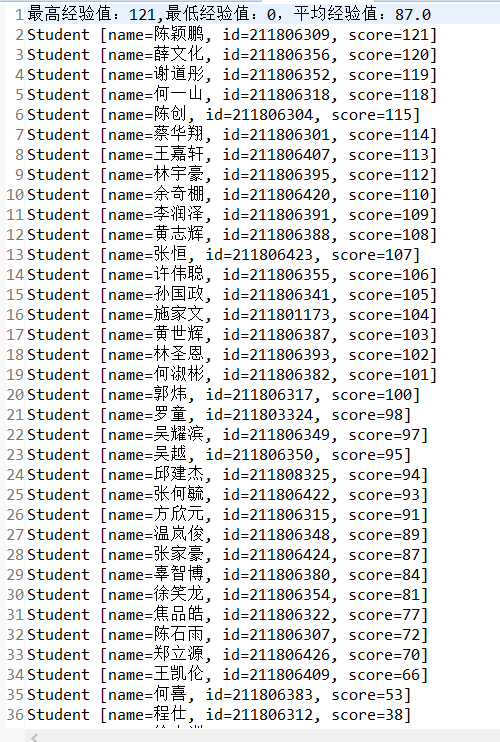
6.按照老师的要求,用IO流进行输出,进入score.txt文件
代码实行
1.解析配置文件,并用cookie进入云班课

2.将每个课堂完成部分的URI爬下来
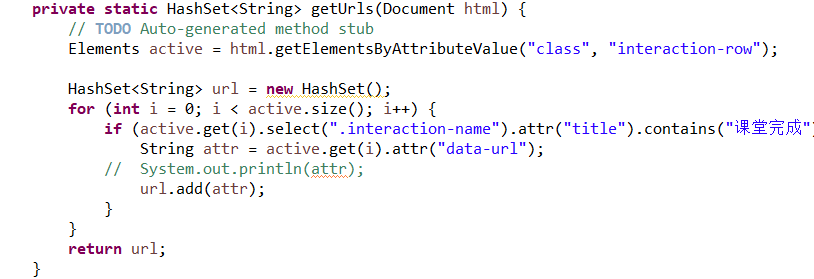
3.设置两个集合和两个类,对每个活动里的url的内容进行爬取
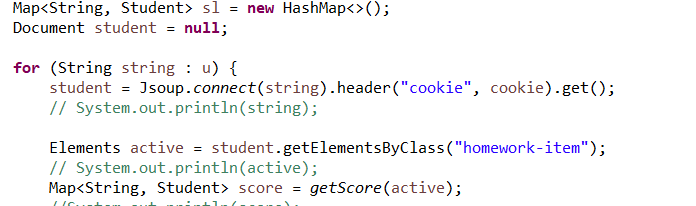
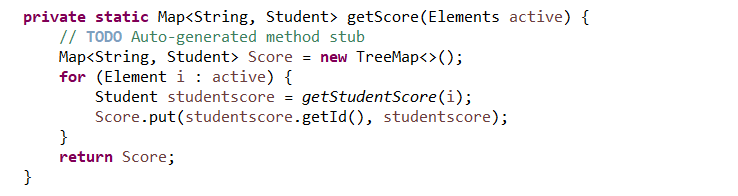
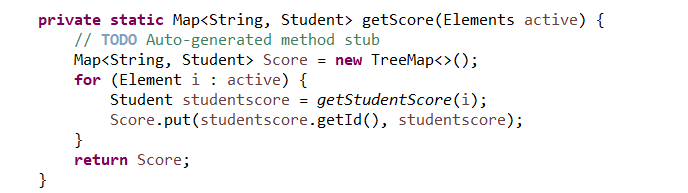
4.将两个集合进行合并,并进行排序


5.最后用IO流将数据输入进文档

问题
1.爬取每个活动的url,算法出错,一直输出同一个值。
2.对cookie不了解,花了相当多的时间来学习。
3.我还是太缺乏锻炼,开始写的时候没有明确的方向。
新知识
1.学会了网络爬虫,以及遇到登录注册时怎么办
2.更加了解joup包的使用
参考网站
1.https://jsoup.org/apidocs/
2.https://blog.csdn.net/qwe86314/article/details/91450098
3.https://v.youku.com/v_show/id_XMjcyNTIzNDcyNA==
