解决Linux终端乱码的两则例子
现象描述
我们先来说一下出现乱码的原因。
例子
先举个实际的例子,我们一般通过ssh远程到服务器上进行操作。当在终端上执行一些有输出的任务时,有可能会遇到乱码,特别是输出中有中文时。
比如,我登陆上oracle数据库服务器上,查看oracle RAC的状态:
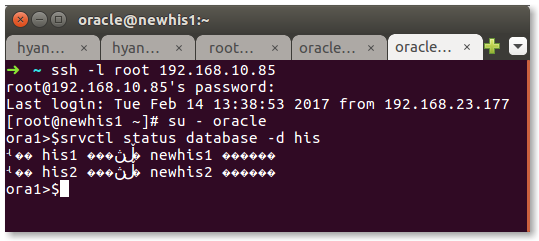
上面的例子,除了英文字母外其它的都成了乱码了。 当然这个与运行什么程序没有什么关系,你可以试一下系统自带的命令,当参数错误时也会也现乱码。

当我们在网上找问题的解决方法时,有让你修改配置文件的,有让你修改环境变量的,有让你换个客户端的,还有让你装语言包的。
有这么多答案供你选择,但都没有告诉你原因。 在给出答案之前我所先分析一下原因,为什么让我改环境变量,而不是其它的,它代表了什么?
当然为了不刨根问底,我设定一下范围,只关心系统层面,语言实现和架构层面我们就不涉及了。
原因
在Linux里面有两个概念与这个问题有关:国际化(相对应的是本地化)、编码
国际化-i18n-internationalization
在程序设计层面,输出有乱码的程序都是好程序,至少它考虑到了它的用户可能不是本国人,可能有不懂英文、德文的人在使用。
在不同的语言环境下,程序的输出会有不同。与之相关的细节则是环境变量LANG,系统命令locale等。
编码
编码是数据(文本)在计算机的内部表示。在数据存储(文件)或传输过程中会以某种规则进行编码(编码规范:UTF-8、GBK等)
题外话
可以这样理解,文本文件都是有编码的,这个概念在Windows中被弱化了。在中文版的Windows中的txt文件都是以gb2312编码的。找一个可以选择编码模式的编辑器比如“宇宙第一IDE"VSCODE,如果以utf-8打开gb2312编码的txt文件,就会显示乱码。
乱码
终于到关键点了,程序输出的乱码本质上和文件乱码是一回事。
文件乱码
以编码格式”A“写入文件,以编码格式"B“解析文件内容并显示
终端乱码
程序以系统要求(LANG)的编码格式"A"输出文本,输出的内容被”终端“程序以自己的编码格式”B"解析并显示。
”终端“程序的编码格式比较好理解,我们放几个截图就解释了。Linux系统内的约定比较不好理解,稍后我们再来看LANG, env, 以及locale.
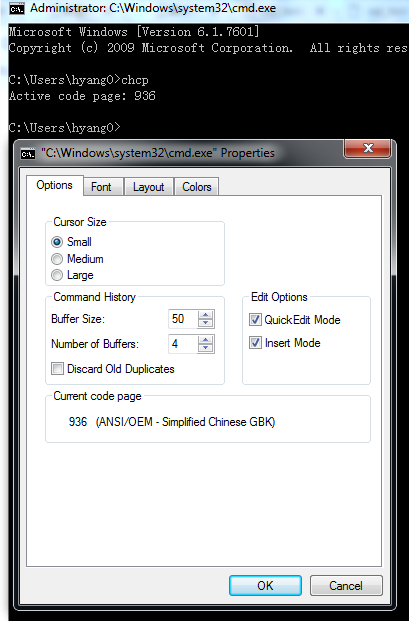
Windows下的终端程序输出的编码格式
Windows自带的cmd程序
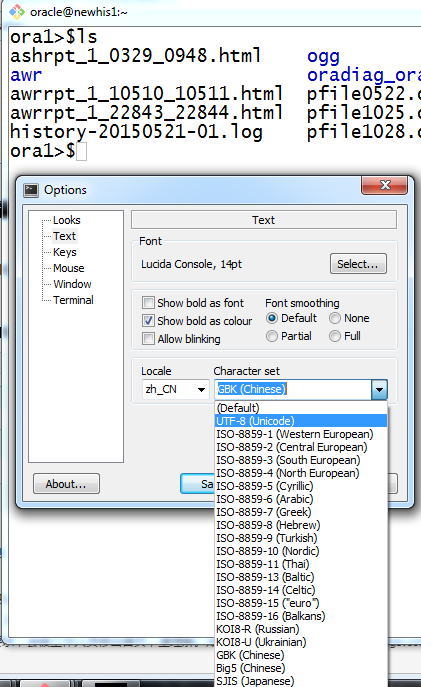
Windows版本的Git Shell程序
Linux下的终端程序输出的编码格式
Linux下的终端程序gnome-terminal
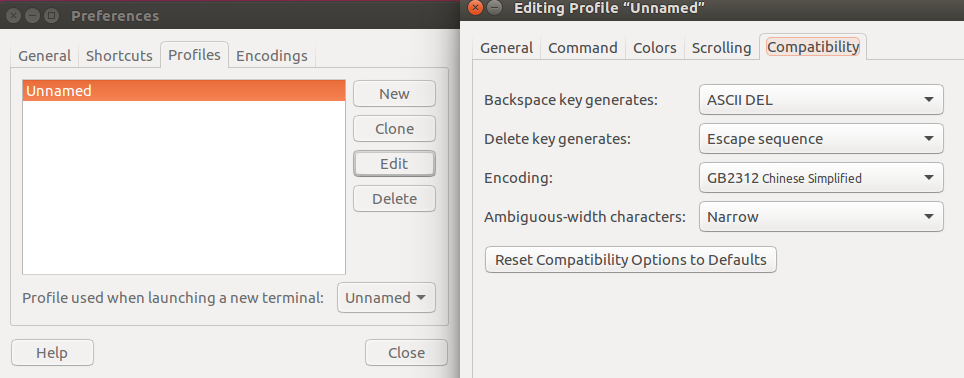
通过菜单Terminal->Preferences->Profiles->Edit->Compatibility->Encoding进入相应配置界面
除了windows自带的cmd之外,其它终端都可以更改当前程序输出的编码。
Linux系统的编码是如何设定的呢?
简单地说它是通过环境变量LANG来设定的,系统中的所有程序(包括gnome-termial)在启动时都会读取这个值来设定当前的程序菜单、界面、输出等编码格式。
能不能显示可能的确与字体包有关,比如redhat下的rpm包fonts-chinese-3.02-12.el5。它里面主要是一些字体文件,这些在windows里也能找到。
[root@newhis1 ~]# rpm -ql fonts-chinese /usr/share/fonts/chinese/TrueType/fonts.cache-1 /usr/share/fonts/chinese/TrueType/fonts.dir /usr/share/fonts/chinese/TrueType/fonts.scale /usr/share/fonts/chinese/TrueType/ukai.ttf /usr/share/fonts/chinese/TrueType/uming.ttf /usr/share/fonts/chinese/fonts.cache-1 /usr/share/fonts/chinese/misc /usr/share/fonts/chinese/misc/fonts.alias /usr/share/fonts/chinese/misc/fonts.cache-1 /usr/share/fonts/chinese/misc/fonts.dir /usr/share/fonts/chinese/misc/fonts.scale /usr/share/fonts/chinese/misc/taipei16.pcf.gz /usr/share/fonts/chinese/misc/taipei20.pcf.gz /usr/share/fonts/chinese/misc/taipei24.pcf.gz /usr/share/fonts/chinese/misc/vga12x24.pcf.gz /usr/share/fonts/zh_TW /usr/share/fonts/zh_TW/TrueType /usr/share/fonts/zh_TW/TrueType/bsmi00lp.ttf
我们假设这些包都装过了,也就是说在装系统时的“语言支持”里面选过中文了。
Linux支持的语言编码,通过locale命令可以查看。我们只关注英文和中文,所以过滤了一下。
[root@newhis1 ~]# locale -a|grep '^[z|e][h|n]'|grep \\.|grep -v iso en_AU.utf8 en_BW.utf8 en_CA.utf8 en_DK.utf8 en_GB.utf8 en_HK.utf8 en_IE.utf8 en_IN.utf8 en_NZ.utf8 en_PH.utf8 en_SG.utf8 en_US.utf8 en_ZA.utf8 en_ZW.utf8 zh_CN.gb18030 zh_CN.gb2312 zh_CN.gbk zh_CN.utf8 zh_HK.big5hkscs zh_HK.utf8 zh_SG.gb2312 zh_SG.gbk zh_SG.utf8 zh_TW.big5 zh_TW.euctw zh_TW.utf8
环境变量LANG的内容的格式为: <语言>_<地域>.<字符集>
环境变量LANGUAGE的格式为:<语言>_<地域>
还有命令locale输出的LC_开头的环境变量,它们会对程序的输出和界面产生响应。
细节可以参考网文:locale的设定中LANG、LC_ALL、LANGUAGE环境变量的区别
为了防止链接损坏打不开,我抄一小段:
locale把按照所涉及到的文化传统的各个方面分成12个大类,这12个大类分别是: 1、语言符号及其分类(LC_CTYPE) 2、数字(LC_NUMERIC) 3、比较和排序习惯(LC_COLLATE) 4、时间显示格式(LC_TIME) 5、货币单位(LC_MONETARY) 6、信息主要是提示信息,错误信息,状态信息,标题,标签,按钮和菜单等(LC_MESSAGES) 7、姓名书写方式(LC_NAME) 8、地址书写方式(LC_ADDRESS) 9、电话号码书写方式(LC_TELEPHONE) 10、度量衡表达方式 (LC_MEASUREMENT) 11、默认纸张尺寸大小(LC_PAPER) 12、对locale自身包含信息的概述(LC_IDENTIFICATION)。 Locale是软件在运行时的语言环境, 它包括语言(Language), 地域 (Territory) 和字符集(Codeset)。一个locale的书写格式为: 语言[_地域[.字符集]]。完全的locale表达方式是 [语言[_地域][.字符集] [@修正值]。zh_CN.GB2312=中文_中华人民共和国+国标2312字符集。 locale的设定: LC_ALL和LANG优先级的关系:LC_ALL > LC_* >LANG 1、如果需要一个纯中文的系统的话,设定LC_ALL= zh_CN.XXXX,或者LANG=zh_CN.XXXX都可以。 2、如果只想要一个可以输入中文的环境,而保持菜单、标题,系统信息等等为英文界面,那么只需要设定 LC_CTYPE=zh_CN.XXXX,LANG=en_US.XXXX就可以了。 3、假如什么也不做的话,也就是LC_ALL,LANG和LC_*均不指定特定值的话,系统将采用POSIX作为lcoale,也就是C locale。 LANG和LANGUAGE的区别: LANG - Specifies the default locale for all unset locale variables LANGUAGE - Most programs use this for the language of its interface LANGUAGE是设置应用程序的界面语言。而LANG是优先级很低的一个变量,它指定所有与locale有关的变量的默认值
结论
当环境变量LANG, LANGUAGE, 和LC_开头的变量的设定与terminal程序的设定不一致或字符集不包含时就会出现乱码。
比如,LANGUAGE设定程序的输出为zh_TW即台湾繁体,如果terminal用来编码的字符集是gb2312(简体中文),则输出会是乱码.
例子
前面铺垫了那么多,当然不会就甩出一句A!=B就结束了,说好的两则例子呢?
我们分别以Linux下的gnome-terminal和Windows下的Git-shell为例演示一下上面的命令行报错的示例
例一
Linux gnome-terminal
我们先确认一下当前终端使用的编码,在菜单Terminal->Preferences->Profiles->Edit->Compatibility->Encoding下。我们要演示正常的和不正常的。我们演示大家都能看懂的编码,以英文、中文简体、中文繁体及乱码为例来演示。
先查看一下terminal的编码选择的字符集:

ssh在传输过程中可能会带入一些变量,可以打开verbose模式查看细节。
bash$ ssh -l root 192.168.10.85 -v debug1: Sending environment. debug1: Sending env LC_IDENTIFICATION = en_US.UTF-8 debug1: Sending env LC_TIME = en_US.UTF-8 debug1: Sending env LC_NUMERIC = en_US.UTF-8 debug1: Sending env LC_PAPER = en_US.UTF-8 debug1: Sending env LC_MEASUREMENT = en_US.UTF-8 debug1: Sending env LC_ADDRESS = en_US.UTF-8 debug1: Sending env LC_MONETARY = en_US.UTF-8 debug1: Sending env LANG = en_US.UTF-8 debug1: Sending env LC_NAME = en_US.UTF-8 debug1: Sending env LC_TELEPHONE = en_US.UTF-8 debug1: Sending env LC_CTYPE = en_US.UTF-8 Last login: Tue Feb 14 15:36:45 2017 from 192.168.23.208 Try `df --help' for more information. [root@newhis1 ~]#
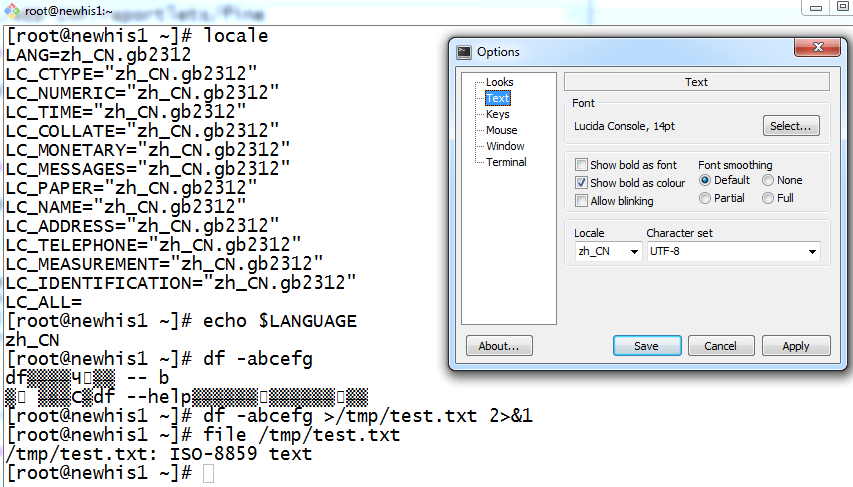
当更改LANGUAGE等变量时,系统自带的命令的输出也会变:
[root@newhis1 ~]# LANGUAGE=zh_TW [root@newhis1 ~]# df -abcdefg df: 不適用的選項 -- b 請嘗試執行‘df --help’來獲取更多資訊。 [root@newhis1 ~]# LANGUAGE=zh_CN [root@newhis1 ~]# df -abcdefg df:无效选项 -- b 请尝试执行“df --help”来获取更多信息。 [root@newhis1 ~]# LANGUAGE=en_US [root@newhis1 ~]# df -abcdefg df: invalid option -- b Try `df --help' for more information. [root@newhis1 ~]#
当Terminal的字符集包含以上输出所含的字符时,就可以显示正常。无法显示时,就会出现乱码。
比如Terminal选的是gb2312,而LANGUAGE选择的是zh_TW,程序输出为:

其中打?号的部分就是乱码,繁体字超出了gb2312字符集所能表达的范围,gb2312只能用来表达简体字。
同理,如果terminal选的是UTF-8,这个字符集包含了全球可见字符,所以中文、德文都能显示。
比如:
[root@newhis1 ~]# cat a.sh LANG=ru_UA.utf8 LANGUAGE=ru_UA LC_CTYPE=ru_UA.utf8 LC_NUMERIC=ru_UA.utf8 LC_TIME=ru_UA.utf8 LC_COLLATE="ru_UA.utf8" LC_MONETARY=ru_UA.utf8 LC_MESSAGES="ru_UA.utf8" LC_PAPER=ru_UA.utf8 LC_NAME=ru_UA.utf8 LC_ADDRESS=ru_UA.utf8 LC_TELEPHONE=ru_UA.utf8 LC_MEASUREMENT=ru_UA.utf8 LC_IDENTIFICATION=ru_UA.utf8 [root@newhis1 ~]# source a.sh

例二
Windows Git-shell
先查看当前的terminal程序所有的编码:
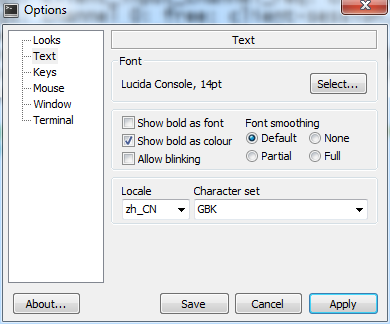
因为是Windows客户端,通过ssh登陆服务器时不会重写LANG设置,可以通过ssh -v选项打开调试查看登陆过程.这点与Linux上的客户端不一样.
通过以下脚本设置相关环境变量,将语言设置为简体中文:
#!/bin/bash lang_input=zh_CN.gb2312 LANG=$lang_input LANGUAGE=`echo $LANG|awk -F. '{print $1}'` LC_CTYPE=$lang_input LC_NUMERIC=$lang_input LC_TIME=$lang_input LC_COLLATE="$lang_input" LC_MONETARY=$lang_input LC_MESSAGES="$lang_input" LC_PAPER=$lang_input LC_NAME=$lang_input LC_ADDRESS=$lang_input LC_TELEPHONE=$lang_input LC_MEASUREMENT=$lang_input LC_IDENTIFICATION=$lang_input
测试将LANGUAGE设置为简体中文和繁体中文时的输出:
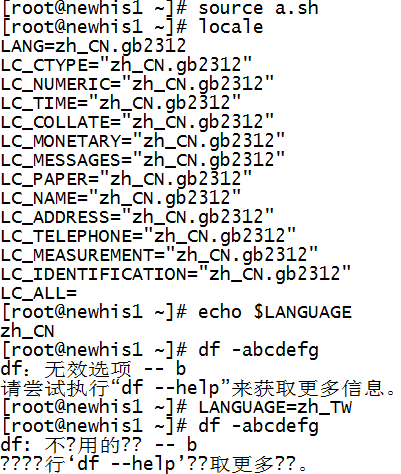
LANGUAGE变量会影响到程序的输出,当系统编码与terminal程序使用的编码一致的情况下,比如都是gb2312.如果程序输出的语言超出了编码所选用的字符集所能表达的范围时也会出现乱码.如果termial程序和Linux系统选用的编码不一致,则中文会出现乱码.
比如,terminal选用的是ISO-8859-1(Western European),Linux系统选用的是zh_CN.GB18030
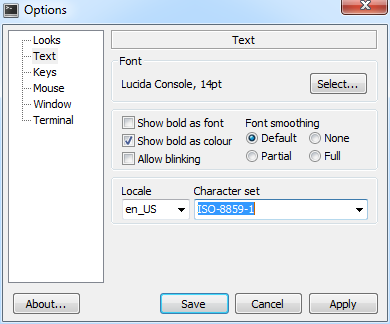
固定linux的设置不变,windows终端分别在设置为GBK和ISO-8859-1时,我们将这两个截图对比一下:
Terminal Encoding:
分别在GBK和ISO-8859-1时,在ssh上查看相同的命令输出:
Linux System Encoding

对照一下乱码情况:

正常的是都选用的中文编码的情况,出现乱码的是terminal选ISO-8859-1(Western European),Linux系统选zh_CN.GB18030
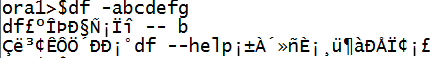
输出乱码的成因
超出字符集表示范围
还是用例子来说明,程序输出为繁体,但你使用的字符集不含繁体,则出现乱码.
编码格式不一致
举例,Linux系统选择的是gb2312的编码格式,terminal程序选择的是utf8来解析.读出来的就是乱码.这个体现在程序输出上就是看到的内容变成乱码.如果把程序输出重定向到文件,查看文件编码类型.文件的编码类型就是LANG格式中<语言>_<地域>.<字符集>的最后一个字段.可以使用file命令或vi下:set fileencoding查看.
如果深究各种编码,可以查看网文:关于文件编码格式的一点探讨
例子截图
posted on 2017-02-14 18:11 Digital_life 阅读(39077) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号