
构建之法第四次作业
构建之法第四次作业
一、
| 这个作业属于哪个课程 | 系统分析与设计 |
|---|---|
| 这个作业要求在哪里 | 系统分析与设计第四次作业地址 |
| Github项目地址 | WordCount |
| 队友作业地址 | 侯思其 |
二、PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| Estimate | 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 740 | 1650 |
| Analysis | 需求分析 (包括学习新技术) | 50 | 30 |
| Design Spec | 生成设计文档 | 30 | 50 |
| Design Review | 设计复审 (和同事审核设计文档) | 30 | 50 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 5 |
| Design | 具体设计 | 60 | 100 |
| Coding | 具体编码 | 500 | 885 |
| Code Review | 代码复审 | 30 | 50 |
| Test | 测试(自我测试,修改代码,提交修改) | 20 | 500 |
| Reporting | 报告 | 90 | 60 |
| Test Report | 测试报告 | 50 | 50 |
| Size Measurement | 计算工作量 | 20 | 15 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 20 |
| 无 | 合计 | 860 | 1765 |
三、模块接口的设计与实现
在查看项目需求时,发现项目主要有以下几个功能组成:
1、字符和单词数统计
2、统计单词出现频率
3、词组统计
4、参数自定义输入输出
因此我们考虑编写一个主项目(根据命令行参数输出指定内容)和三个库(dll)分别处理:文件中的字符和行数统计、统计单词数和单词出现频率、统计字符组。
本次项目中主要的算法在于从文件或字符串中获取指定的内容和排序,我们的主要思路是通过将文件读入一行后用正则表达式对符合要求的单词进行提取并小写化,然后将单词储存在List中,再将统计单词的出现的个数然后通过SortedList储存排序后的单词及单词频率。
对应的库和函数如图所示:
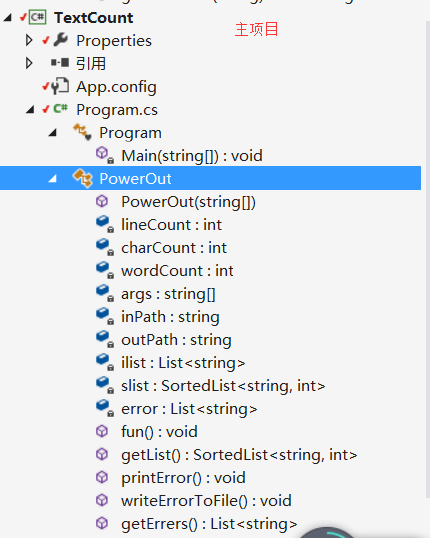
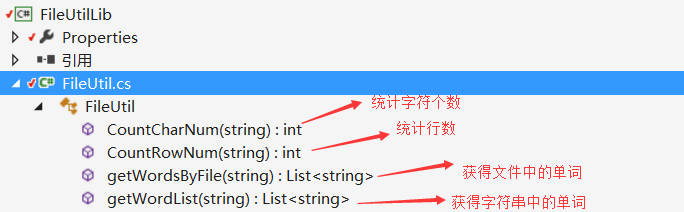
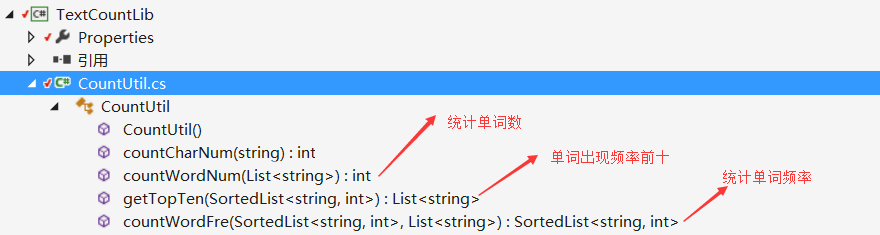

其他的功能,如-m -n等指令直接写在主项目的一个独立的类中,三个库及指令操作类既可以在本项目中使用,也可以添加到其他项目中使用,提高了代码的可复用性。
四、代码复审
在代码复审过程中,我们严格的遵守了代码复审的几项原则:编码规范、按照设计编码、尽量提高程序性能、交流和处理出现的异常、进行编码的单元测试。在代码复审过程中,一直都是我的队友担任“领航员”的角色,领到我前行,耐心的向我讲解,细心的指导,然后提高了整体程序代码的性能。问题就是思路和能力有时跟不上队友,减缓了设计和编码的进度。
五、模块接口部分的性能改进
针对排序算法,我们最后对其进行了修改,之前我们是将单词按顺序直接先排序储存,发现写的算法效率很低,因此将排序这部分放在了输出的代码里,通过SortedList的自动根据key进行排序的特性先将其安字符排序好,再根据-n值决定循环输出前n大的值,这样直接解决了相同值时再按照key字母排序问题,大大节省了时间。
修改后:

六、模块部分单元测试
对单元测试分为三大部分:
- 统计功能
- 命令参数控制
- 错误输入测试
针对两大部分设计了6个测试函数单独测试三个库的接口功能,4个测试正确输入参数的情况,4个测试错误输入命令行的执行情况。
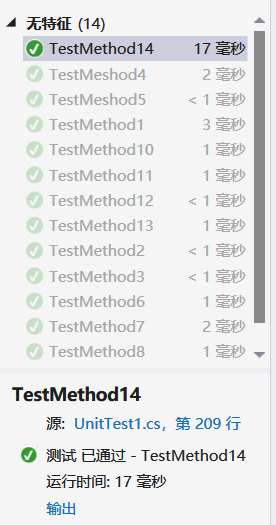
部分图:



七、异常处理
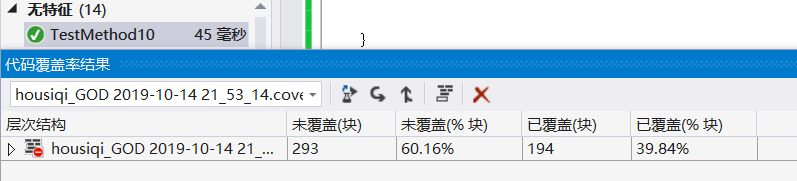
查看混合输入参数执行程序的代码覆盖率:

八、 结对感受
在此次结对编程过程中,我可以感受到结对编程的巨大魅力,“1+1>2”是正确的,而且在这个过程中,两个人可以相互监督学习,而且在设计和编码过程中,队友带动了我的编程的能力,我向他学习到了许多新编码的知识和能力,也回顾了以前的编码知识。感谢队友的耐心指导和孜孜不倦的教诲。

