
BUAA_2022_OO_task1_博客总结
OO的第一单元也算是告一段落了,尽管发布本篇博客的很大一部分原因是班级的作业废话,但是,在这一个月完成作业时的所思所想,我也很想和各位一同分享
在此,欢迎各位来看我的博客顺便也点个赞吧,呜呜
本篇博客主要分为如下几大部分:
1. 对历次作业的分析,包含度量分析,简单的设计思路,UML类图,简单的优缺点分析
2. 以第三次作业,进行详细的优缺点分析和设计思路分享
3.程序Bug分析,含对强测、互测的分析
4. 架构设计体验
5. 经验总结
6. 心得分享
第一次作业
node软件包
概览
| 类名 | 属性个数 | 方法个数 | 总代码规模 |
|---|---|---|---|
| Node | 0 | 1 | 4 |
| OperandNode | 2 | 3 | 53 |
| OperatorNode | 3 | 2 | 26 |
| OperatorAdd | 0 | 0 | 16 |
| OperatorSubtract | 0 | 0 | 16 |
| OperatorMulti | 0 | 0 | 16 |
| OperatorPow | 0 | 0 | 16 |
| Item | 1 | 5 | 121 |
| BaseItem | 2 | 7 | 73 |
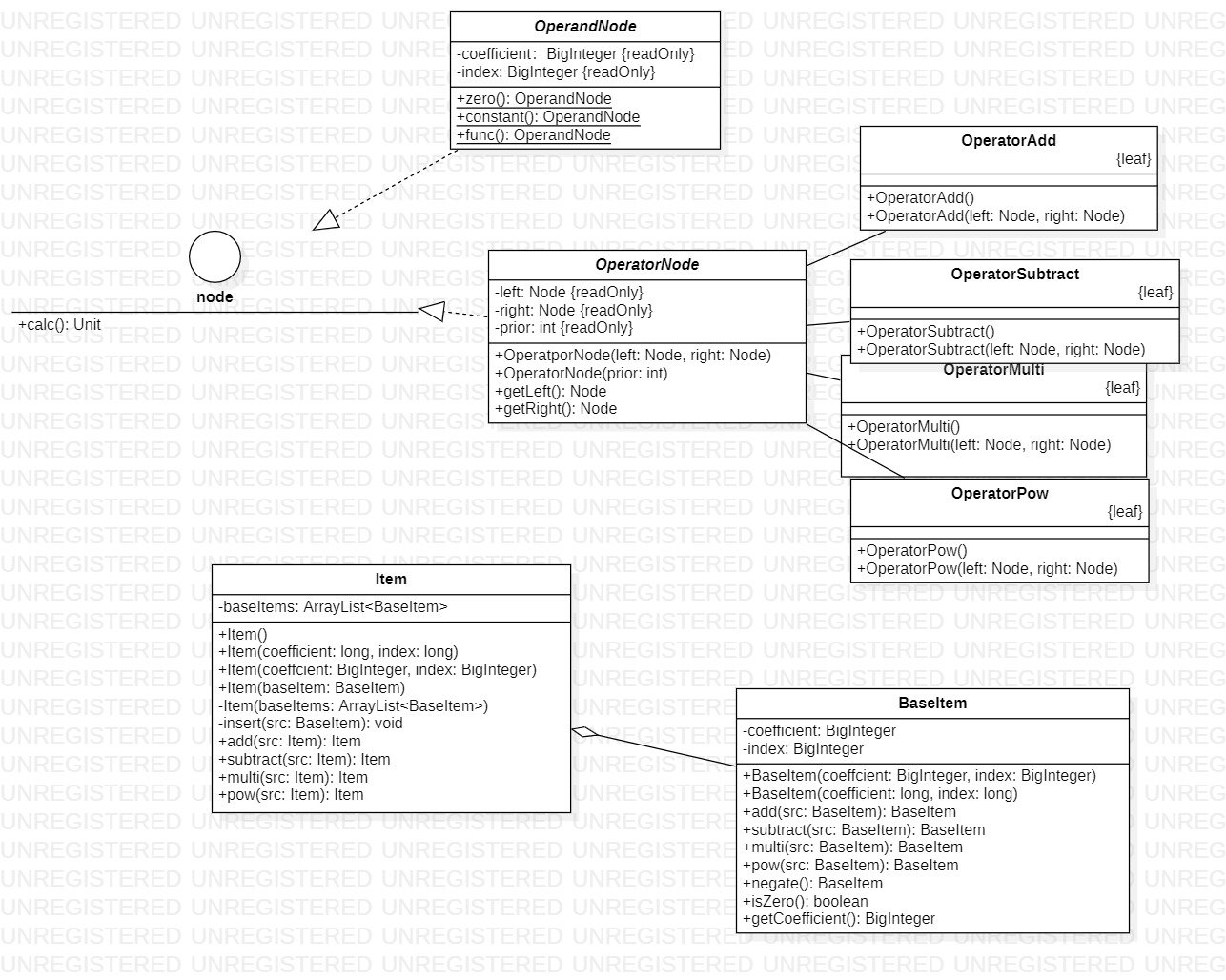
设计考虑
本软件包用于表达解析后生成的树形逻辑结构以及计算中的运算结构
各类分析
Node
本类为接口,统一软件包中的绝大部分类,提取计算节点的共同逻辑,提供计算方法
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| calc | 0 | 0 |
OperandNode
本类设计作为操作数节点
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| OperandNode | 0 | 2 | |
| zero | 0 | 1 | |
| constant | 1 | ||
| func | 0 | 1 | |
| calc | 0 | 1 | |
| toString | 4 | 28 |
OperatorNode
本类设计为所有二元操作符节点类的父类,提取子类的公共属性(左儿子和右儿子),设计为虚类,禁止实例化
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| OperatorNode | 0 | 3 | |
| OperatorNode | 0 | 3 | |
| getLeft | 0 | 1 | |
| getRight | 0 | 1 |
OperatorAdd
本类以及以下的3个类,均为普通的二元运算操作(加、减、乘、乘方)
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| OperatorAdd | 0 | 1 | |
| OperatorAdd | 0 | 1 | |
| calc | 0 | 1 | |
| toString | 0 | 1 | |
| substitude | 0 | 1 |
OperatorSubtract
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| OperatorSubtract | 0 | 1 | |
| OperatorSubtract | 0 | 1 | |
| calc | 0 | 1 | |
| toString | 0 | 1 | |
| substitude | 0 | 1 |
OperatorMulti
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| OperatorMulti | 0 | 1 | |
| OperatorMulti | 0 | 1 | |
| calc | 0 | 1 | |
| toString | 0 | 1 | |
| substitude | 0 | 1 |
OperatorPow
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| OperatorPow | 0 | 1 | |
| OperatorPow | 0 | 1 | |
| calc | 0 | 1 | |
| toString | 0 | 1 | |
| substitude | 0 | 1 |
Item
本类用于存储连续的项相加,且尽可能作为不可变类,提供唯一的且私有的修改内部属性的方法,对外提供的运算操作均返回一个全新的对象
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| Item | 0 | 1 | |
| Item | 1 | 4 | |
| Item | 1 | 4 | |
| Item | 1 | 4 | |
| Item | 0 | 1 | |
| insert | 2 | 13 | |
| add | 0 | 5 | |
| subtract | 0 | 5 | |
| multi | 1 | 10 | |
| pow | 3 | 18 | |
| toString | 4 | 27 |
BaseItem
本类用以保存连续的因子相乘后的最终结果,并作为不可变类
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| BaseItem | 0 | 2 | |
| BaseItem | 0 | 2 | |
| add | 0 | 1 | |
| subtract | 0 | 1 | |
| multi | 0 | 1 | |
| pow | 0 | 2 | |
| negate | 0 | 1 | |
| isZero | 0 | 1 | |
| getCoefficient | 0 | 1 | |
| CompareTo | 0 | 1 | |
| toString | 6 | 31 |
默认软件包
概览
| 类名 | 属性个数 | 方法个数 | 总代码规模 |
|---|---|---|---|
| Parser | 1 | 9 | 175 |
| Lexer | 6 | 10 | 100 |
| ReadKind | 0 | 0 | 1 |
| OperatorKind | 0 | 0 | 1 |
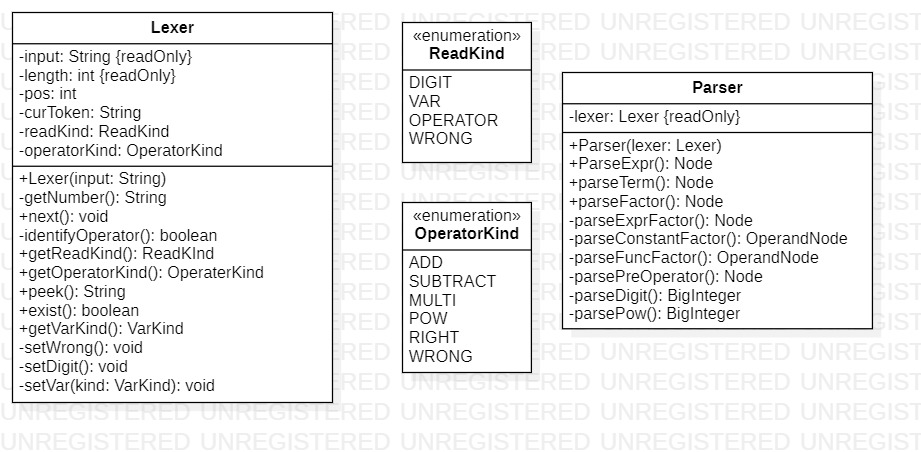
设计考虑
本软件包负责对表达式的解析和预解析
各类分析
Parser
本类负责对表达式的解析
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| Parser | 0 | 1 | |
| parseExpr | 3 | 223 | |
| parserTerm | 1 | 10 | |
| parseFactor | 7 | 32 | 本方法负责对各种因子的识别,尤其是符号等处理消耗了大量判断 |
| parseExprFactor | 1 | 12 | |
| parseConstantFactor | 2 | 14 | |
| parseFuncFactor | 1 | 7 | |
| parsePreOperator | 4 | 16 | |
| parseDigit | 1 | 7 | |
| parsePow | 3 | 12 |
Lexer
本类用于对输入的字符串进行初步解析,自动对输入字符串划分为单独的语义块,并对外提供方法获取该语义块的类型
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| Lexer | 0 | 6 | |
| getNumber | 0 | 6 | |
| next | 3 | 18 | |
| identifyOperator | 7 | 30 | 本方法用于尝试以符号方式解析,此处尝试解析的符号有'(',')','+','-','*','**' |
| peek | 0 | 1 | |
| exist | 0 | 1 | |
| getOperatorKind | 0 | 1 | |
| setDigit | 0 | 4 | |
| setVar | 0 | 2 | |
| setSplit | 0 | 2 |
ReadKind
本类为枚举类,设计用于分辨语义块的总体类型,即数字、变量、操作符、错误。
同时,此类以及接下来的另外3个枚举类共同实现了对语义块类型的两级完整划分,此时,解析方法便可通过调用lexer中的getKind等一系列方法直接获得当前语义块的类型,而不用再次解析字符的语义,定义为枚举类型而非直接的int常量进行区分提高可读性和易维护性
OperatorKind
本类为枚举类,设计用于分辨操作符类型
类间依赖度分析
| Class | Cyclic | Dcy | Dcy* | Dpt | Dpt* | PDcy | PDpt |
|---|---|---|---|---|---|---|---|
| Launch | 0 | 3 | 13 | 0 | 0 | 2 | 0 |
| Lexer | 0 | 2 | 2 | 2 | 2 | 1 | 1 |
| OperatorKind | 0 | 0 | 0 | 2 | 3 | 0 | 1 |
| Parser | 0 | 9 | 12 | 1 | 1 | 2 | 1 |
| ReadKind | 0 | 0 | 0 | 2 | 3 | 0 | 1 |
| node.BaseItem | 0 | 0 | 0 | 1 | 10 | 0 | 1 |
| node.Item | 0 | 1 | 1 | 6 | 9 | 1 | 1 |
| node.OperandNode | 0 | 2 | 3 | 1 | 2 | 1 | 1 |
| node.OperatorAdd | 0 | 3 | 4 | 1 | 2 | 1 | 1 |
| node.OperatorMulti | 0 | 3 | 4 | 1 | 2 | 1 | 1 |
| node.OperatorNode | 0 | 1 | 3 | 4 | 6 | 1 | 1 |
| node.OperatorPow | 0 | 3 | 4 | 1 | 2 | 1 | 1 |
| node.OperatorSubtract | 0 | 3 | 4 | 1 | 2 | 1 | 1 |
| Interface | Cyclic | Dcy | Dcy* | Dpt | Dpt* | PDcy | PDpt |
|---|---|---|---|---|---|---|---|
| node.Node | 0 | 1 | 2 | 8 | 8 | 1 | 2 |
优缺点分析
第一次作业较为简单,因此结构构建也较为容易,优缺点均不突出
缺点
-
软件包分类不明,默认软件包中包含有大量未分类的类,而唯一的node软件包实际应该划分为逻辑结构和运算结构
-
运行时性能不高,采取先解析为逻辑结构,再解析为运算结构,面对连续加减时将导致表达式树深度过深
优点
-
结构分明,两重结构将功能进行分离,减少了Bug出现机会
-
第二次作业
概览
| 类名 | 属性个数 | 方法个数 | 实现方法 | 总代码规模 |
|---|---|---|---|---|
| Lexer | 8 | 20 | 0 | 230 |
| ReadKind | 0 | 0 | 0 | 4 |
| FuncKind | 0 | 0 | 0 | 4 |
| OperatorKind | 0 | 0 | 0 | 4 |
| VarKind | 1 | 2 | 0 | 24 |
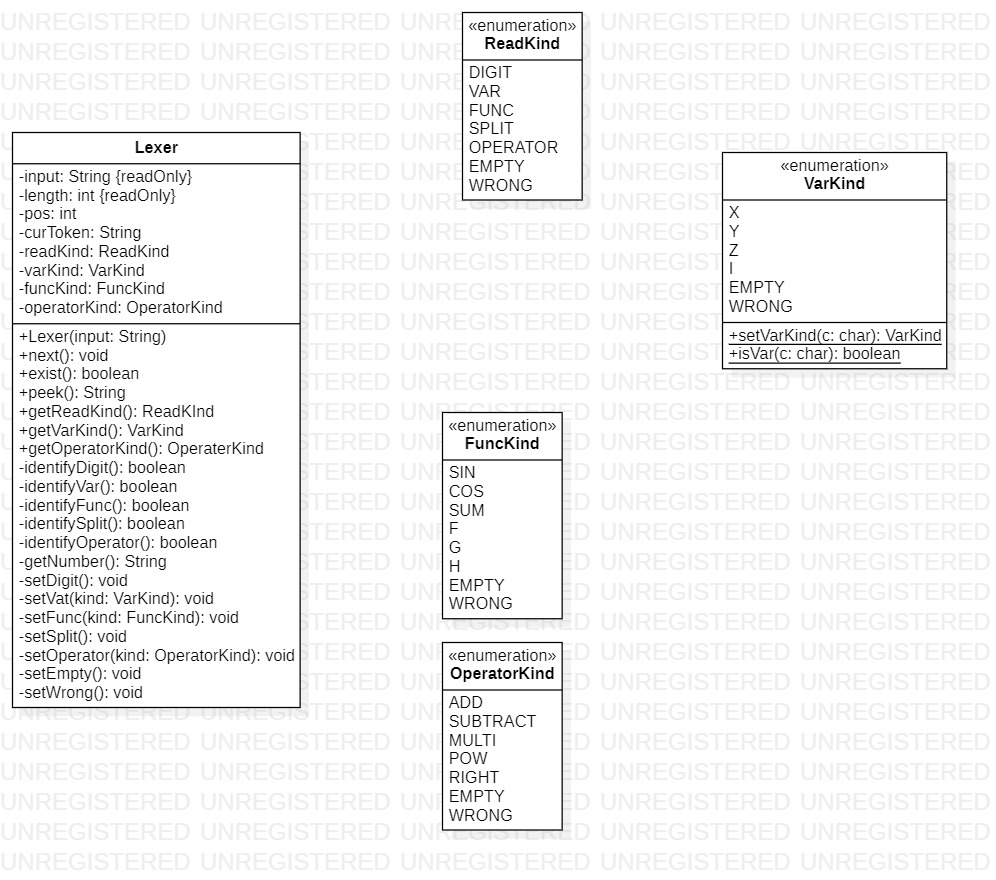
设计考虑
本软件包由一个同名类作为主题,配以四个枚举类作为辅助,主要用于对输入字符串的初步解析
各类分析
Lexer
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| Lexer | 0 | 6 | |
| next | 6 | 21 | 本方法主要用于移动并解析出下一个语义块,其中语义块分类较多 |
| exist | 0 | 1 | |
| getReadKind | 0 | 1 | |
| getVarKind | 0 | 1 | |
| getFuncKind | 0 | 1 | |
| getOperatorKind | 0 | 1 | |
| identifyDigit | 1 | 5 | |
| identifyVar | 1 | 7 | |
| identifyFunc | 6 | 53 | 本方法用于尝试以函数方式解析语义块,函数分为sum、sin、cos、f、g、h |
| identifySplit | 1 | 8 | |
| identifyOperator | 7 | 35 | 本方法用于尝试以符号方式解析,此处尝试解析的符号有'(',')','+','-','*','**' |
| getNumber | 0 | 6 | |
| setDigit | 0 | 4 | |
| setVar | 0 | 4 | |
| setSplit | 0 | 4 | |
| setOperator | 0 | 4 | |
| setEmpty | 0 | 4 | |
| setWrong | 0 | 4 |
本类用于对输入的字符串进行初步解析,自动对输入字符串划分为单独的语义块,并对外提供方法获取该语义块的类型,使解析类中的解析方法使用时可以与具体的字符串内值进行完全分离。同时,语义块整体化避免解析时逐个字符的遍历分析。设计时考虑到可能出现的异常读取(事实上最后没有此要求),如函数名称不全等,也可便于将输入表达式的非法字符异常和表达式结构异常进行区分。
ReadKind
本类为枚举类,设计用于分辨语义块的总体类型,即数字、变量、函数、分隔符、操作符、空、错误。
同时,此类以及接下来的另外3个枚举类共同实现了对语义块类型的两级完整划分,此时,解析方法便可通过调用lexer中的getKind等一系列方法直接获得当前语义块的类型,而不用再次解析字符的语义,定义为枚举类型而非直接的int常量进行区分提高可读性和易维护性
FuncKind
本类为枚举类,设计用于分辨函数类型(包括三角函数sin、cos,自定义函数f、g、h,求和函数sum
OperatorKind
本类为枚举类,设计用于分辨操作符类型
VarKind
本类为枚举类,设计用于分辨变量类型
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| setVarKind | 6 | 15 | 用于根据字符自动转化为相应枚举类型 |
node软件包
概览
| 类名 | 属性个数 | 方法个数 | 总代码规模 |
|---|---|---|---|
| Node | 0 | 2 | 6 |
| OperandNode | 1 | 1 | 11 |
| OperandDigit | 0 | 1 | 20 |
| OperandPowFunc | 1 | 0 | 52 |
| OperatorNode | 2 | 2 | 11 |
| OperatorAdd | 0 | 0 | 19 |
| OperatorSubtract | 0 | 0 | 19 |
| OperatorMulti | 0 | 0 | 19 |
| OperatorPow | 1 | 0 | 19 |
| TriNode | 0 | 0 | 4 |
| TriSin | 0 | 0 | 20 |
| TriCos | 0 | 0 | 20 |
| NodeVarKind | 0 | 1 | 14 |
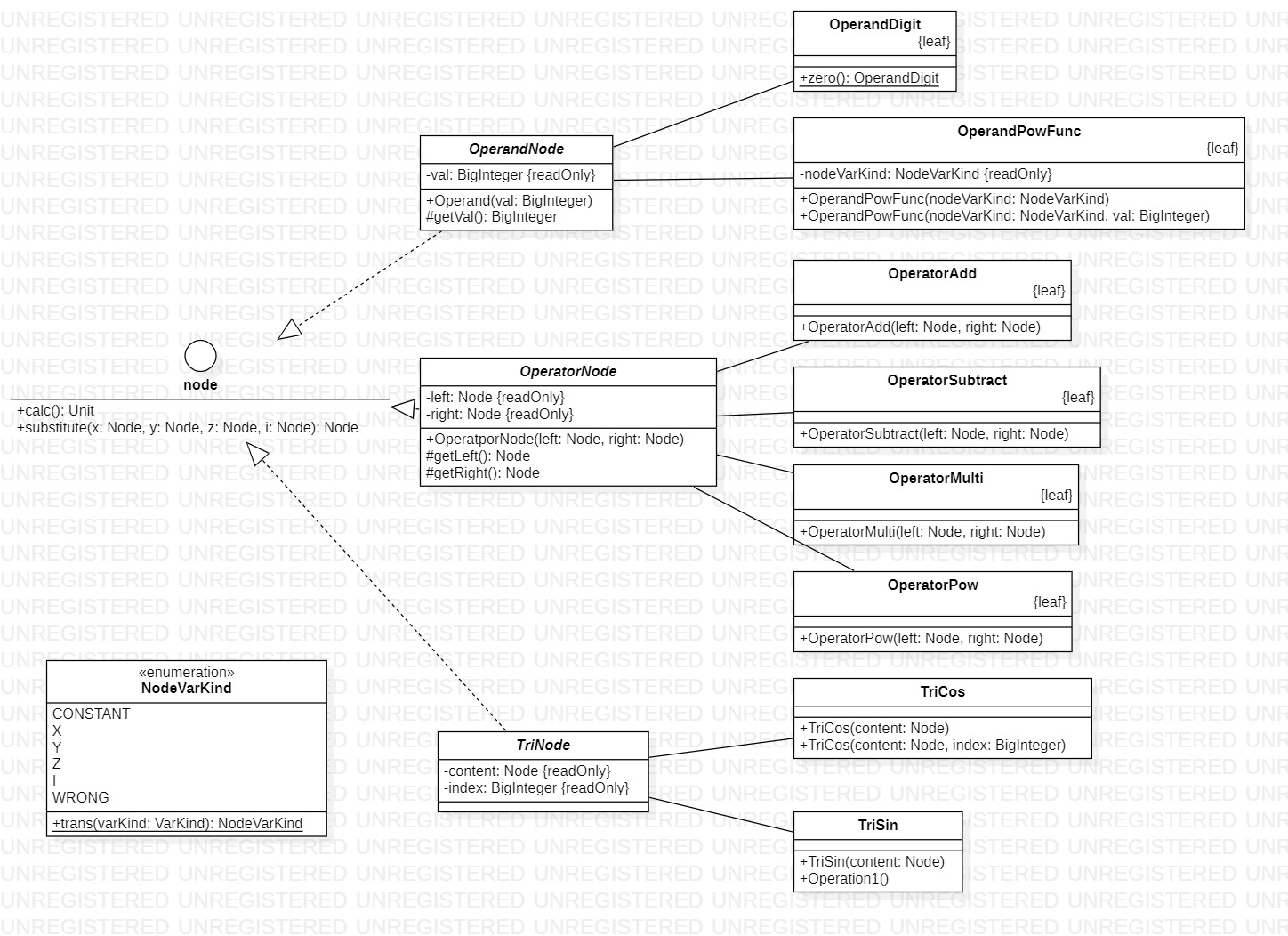
设计考虑
本软件包用于表达解析后生成的树形逻辑结构,由一个接口及实现其的众多类,配以一个枚举类组成,设计时考虑到为尽可能减少bug,将逻辑结构和计算结构分离,故设计此软件包
各类分析
Node
本类为接口,统一软件包中的绝大部分类,提取计算节点的共同逻辑,提供替换和计算两个方法,用于实现因子的代入和最终计算结果的生成
| 方法名 |
|---|
| calc() |
| substitute() |
OperandNode
本类设计作为常数节点类和幂函数节点类的父类,提取其共同属性(一个BigInteger的值),同时设计为虚类禁止实例化
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| OperandNode | 0 | 1 | |
| getVal | 0 | 1 |
OperandDigit
本类为常数节点类,作为表达式树中的常数
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| OperandDigit | 0 | 1 | |
| zero | 0 | 1 | |
| calc | 0 | 1 | |
| substitute | 0 | 1 |
OperatorPowFunc
本类为幂函数节点类,作为表达式中的幂函数,同时,其他node类实现方式均为返回自身,此类独特实现substitude方法,实现因子的代入
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| OperandPowFunc | 0 | 2 | |
| OperandPowFunc | 1 | 4 | |
| calc | 0 | 1 | |
| substitute | 6 | 27 | 需要根据节点变量类型进行替换 |
OperatorNode
本类设计为所有二元操作符节点类的父类,提取子类的公共属性(左儿子和右儿子),设计为虚类,禁止实例化
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| OperatorNode | 0 | 2 | |
| getLeft | 0 | 1 | |
| getRight | 0 | 1 |
OperatorAdd
本类以及以下的3个类,均为普通的二元运算操作(加、减、乘、乘方)
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| OperatorAdd | 0 | 1 | |
| calc | 0 | 1 | |
| toString | 0 | 1 | |
| substitude | 0 | 1 |
OperatorSubtract
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| OperatorSubtract | 0 | 1 | |
| calc | 0 | 1 | |
| toString | 0 | 1 | |
| substitude | 0 | 1 |
OperatorMulti
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| OperatorMulti | 0 | 1 | |
| calc | 0 | 1 | |
| toString | 0 | 1 | |
| substitude | 0 | 1 |
OperatorPow
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| OperatorPow | 0 | 1 | |
| calc | 0 | 1 | |
| toString | 0 | 1 | |
| substitude | 0 | 1 |
TriNode
本类设计为三角函数节点类的父节点,提取子类需要的两个属性(内容和指数),在逻辑上,sin和cos也均为三角函数的一种,也考虑到可能出现的其他三角函数,故设计此类,同时设计为虚类,禁止实例化
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| TriNode | 0 | 2 | |
| TriNode | 0 | 2 | |
| getContent | 0 | 1 | |
| getIndex | 0 | 1 |
TriSin
本类及TriCos类均为具体的三角函数sin、cos
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| TriSin | 0 | 2 | |
| TriSin | 0 | 2 | |
| getContent | 0 | 1 | |
| getIndex | 0 | 1 |
TriCos
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| TriCos | 0 | 2 | |
| TriCos | 0 | 2 | |
| getContent | 0 | 1 | |
| getIndex | 0 | 1 |
NodeVarKind
枚举类,用于保存幂函数节点内部变量类型
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| trans | 0 | 5 |
parser软件包
概览
| 类名 | 属性个数 | 方法个数 | 总代码规模 |
|---|---|---|---|
| Parser | 2 | 15 | 248 |
| CustomizedFuncSet | 1 | 2 | 14 |
| CustomizedFunc | 6 | 3 | 44 |
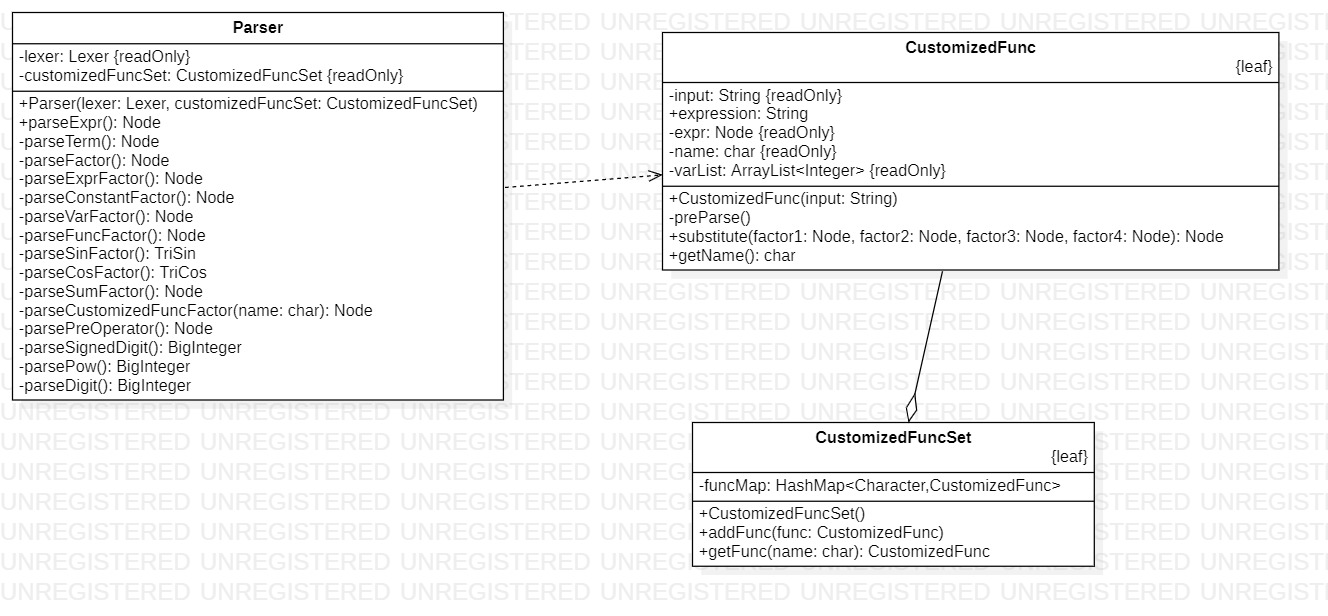
设计考虑
本软件包负责对函数、表达式的解析,将生成对应的逻辑结构
各类分析
Parser
本类负责对表达式的解析,在解析方法中,具体分为5级进行解析,包括表达式解析->项解析->因子解析->因子分类解析->辅助解析方法,辅助解析方法又分为两级:指数和带符号整数解析->无符号整数解析
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| Parser | 0 | 2 | |
| parseExpr | 2 | 22 | |
| parserTerm | 1 | 17 | |
| parseExprFactor | 4 | 12 | |
| parseConstantFactor | 1 | 7 | |
| parseVarFactor | 2 | 10 | |
| parseFuncFactor | 7 | 16 | 本方法识别函数类因子的种类,调用不同的解析方法 |
| parseSinFactor | 1 | 10 | |
| parseCosFactor | 1 | 10 | |
| parseSumFactor | 2 | 23 | |
| parseCustomizedFuncFactor | 3 | 12 | |
| parsePreOperator | 3 | 13 | |
| parseSignedDigit | 3 | 17 | |
| parsePow | 2 | 8 | |
| parseDigit | 1 | 9 |
CustomizedFuncSet
本类实际为自定义函数的集合类,负责对自定义函数集合的简单维护
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| CustomizedFuncSet | 0 | 1 | |
| addFunc | 0 | 1 | |
| getFunc | 0 | 1 |
CustomizedFunc
本类为自定义函数的解析类,用于解析并存储自定义函数的逻辑结构,提供替换方法
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| CustomizedFunc | 0 | 7 | |
| preParse | 0 | 9 | |
| substitute | 0 | 7 | |
| getName | 0 | 1 |
unit软件包
概览
| 类名 | 属性个数 | 方法个数 | 总代码规模 |
|---|---|---|---|
| Unit | 3 | 9 | 163 |
| BaseUnit | 6 | 16 | 358 |
| PowFunc | 2 | 5 | 52 |
| Constant | 4 | 12 | 55 |
| TriFunc | 0 | 0 | 0 |
| Sin | 3 | 8 | 108 |
| Cos | 3 | 5 | 96 |
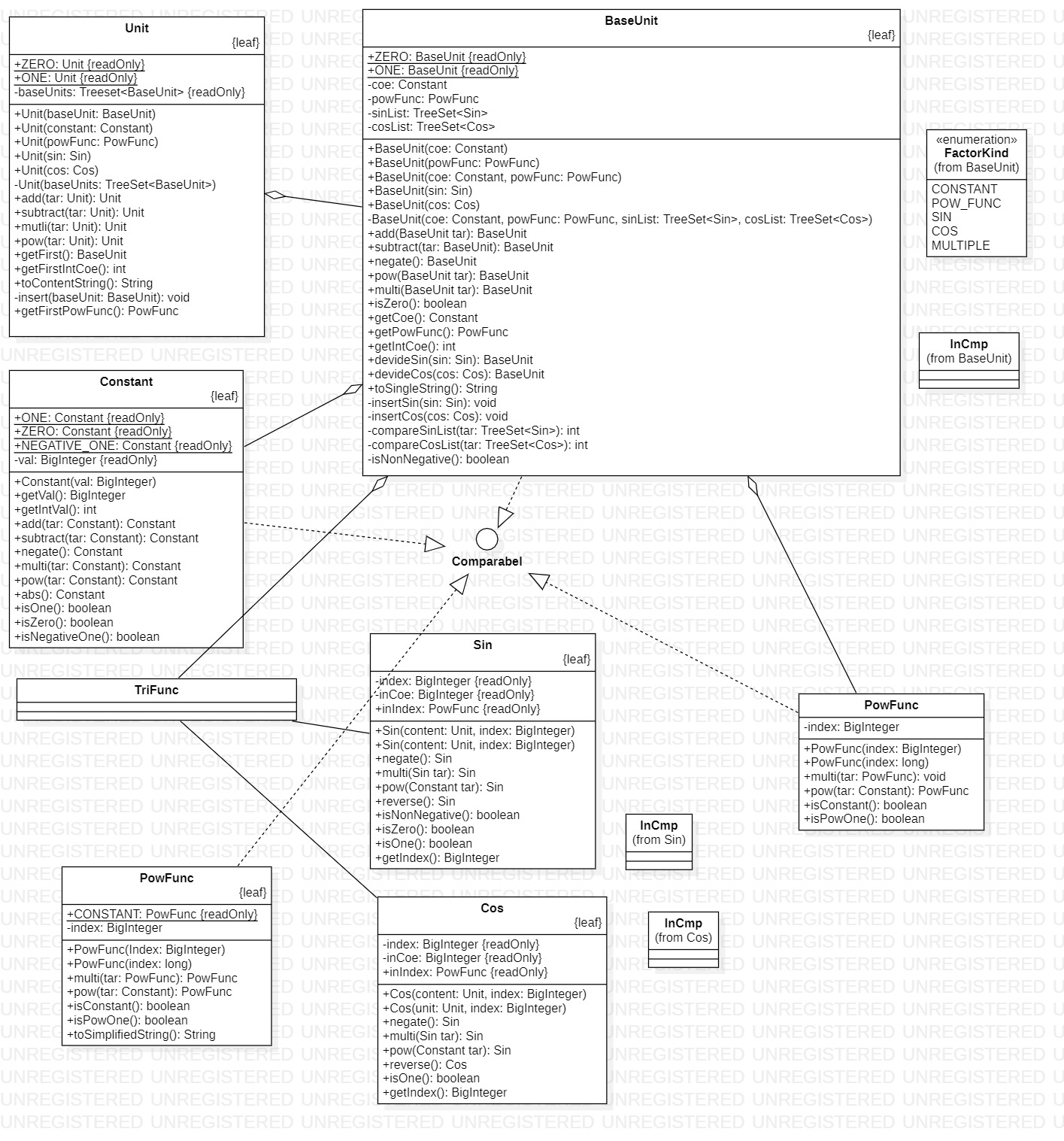
设计考虑
本软件包负责对运算过程中数据的维护,严格将运算结构分为表达式、项、因子三层,同时,这里的项和因子均已完全展开,即不会再出现表达式因子
各类分析
Unit
本类维护一个BaseUnit组成的集合,提供必要的计算方法和信息获取方法,同时,尽可能设定为不可变类,运算均创建一个新对象,提供唯一的、私有的方法用于改变必要的信息。
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| Unit | 0 | 1 | |
| Unit | 1 | 3 | |
| Unit | 1 | 4 | |
| Unit | 0 | 2 | |
| Unit | 1 | 4 | |
| Unit | 0 | 2 | |
| Unit | 0 | 2 | |
| insert | 5 | 21 | |
| add | 0 | 4 | |
| subtract | 0 | 4 | |
| multi | 1 | 9 | |
| pow | 3 | 17 | |
| getFirst | 1 | 5 | |
| getFirstIntCoe | 1 | 4 | |
| getFirstPowFunc | 1 | 5 | |
| toString | 3 | 29 |
BaseUnit
本类设计为底层因子的集合,对应为项层次,尽可能设定为不可变类,运算均创建一个新对象,提供唯二的、私有的方法用于改变必要的信息。
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| BaseUnit | 0 | 4 | |
| BaseUnit | 0 | 4 | |
| BaseUnit | 1 | 7 | |
| BaseUnit | 3 | 29 | |
| BaseUnit | 1 | 7 | |
| BaseUnit | 1 | 13 | |
| add | 0 | 1 | |
| subtract | 0 | 1 | |
| negate | 0 | 1 | |
| pow | 2 | 15 | |
| multi | 1 | 15 | |
| isSingleFactor | 0 | 1 | |
| getCoe | 0 | 1 | |
| getIntCoe | 0 | 1 | |
| divideSin | 5 | 18 | |
| divideCos | 5 | 18 | |
| insertSin | 5 | 20 | |
| insertCos | 5 | 20 | |
| compareSinList | 2 | 17 | |
| compareCosList | 2 | 17 | |
| compareTo | 3 | 16 | |
| isZero | 0 | 1 | |
| isNonNegative | 0 | 1 | |
| toString | 10 | 54 | 输出格式控制 |
PowFunc
本类负责储存幂函数,提供计算方法和两种字符串转换方法
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| PowFunc | 0 | 1 | |
| PowFunc | 0 | 1 | |
| multi | 0 | 1 | |
| pow | 0 | 1 | |
| isConstant | 0 | 1 | |
| isPowOne | 0 | 1 | |
| compareTo | 0 | 1 | |
| toSimplifiedString | 3 | 11 | |
| toString | 2 | 9 |
Constant
本类实际设计为BigIteger的包装类,选择性的实现部分功能,并扩展部分功能
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| Constant | 0 | 1 | |
| getVal | 0 | 1 | |
| getIntVal | 0 | 1 | |
| add | 0 | 1 | |
| subtract | 0 | 1 | |
| negate | 0 | 1 | |
| multi | 0 | 1 | |
| pow | 0 | 1 | |
| abs | 0 | 1 | |
| isNonNegative | 0 | 1 | |
| isZero | 0 | 1 | |
| isOne | 0 | 1 | |
| isNegativeOne | 0 | 1 | |
| compareTo | 0 | 1 | |
| toString | 0 | 1 |
TriFunc
本类设计仅作为虚类,作为名义上Sin和Cos的父类,便于后续扩展
Sin
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| Sin | 3 | 26 | |
| Sin | 0 | 1 | |
| isNonNegative | 0 | 1 | |
| isZero | 0 | 1 | |
| isOne | 0 | 1 | |
| negate | 0 | 1 | |
| multi | 0 | 1 | |
| pow | 0 | 1 | |
| reverse | 0 | 1 | |
| getIndex | 0 | 1 | |
| compareTo | 0 | 1 | |
| toString | 3 | 16 |
Cos
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| Cos | 4 | 26 | |
| Cos | 0 | 1 | |
| isOne | 0 | 1 | |
| negate | 0 | 1 | |
| multi | 0 | 1 | |
| pow | 0 | 1 | |
| reverse | 0 | 1 | |
| getIndex | 0 | 1 | |
| compareTo | 0 | 1 | |
| toString | 3 | 14 |
类间依赖度分析
| Class | Cyclic | Dcy | Dcy* | Dpt | Dpt* | PDcy | PDpt |
|---|---|---|---|---|---|---|---|
| Launch | 0 | 6 | 31 | 0 | 0 | 4 | 0 |
| lexer.FuncKind | 0 | 0 | 0 | 2 | 5 | 0 | 2 |
| lexer.Lexer | 0 | 4 | 4 | 3 | 4 | 1 | 2 |
| lexer.OperatorKind | 0 | 0 | 0 | 2 | 5 | 0 | 2 |
| lexer.ReadKind | 0 | 0 | 0 | 2 | 5 | 0 | 2 |
| lexer.VarKind | 0 | 0 | 0 | 2 | 7 | 0 | 2 |
| node.NodeVarKind | 0 | 1 | 1 | 2 | 5 | 1 | 2 |
| node.OperandDigit | 0 | 4 | 12 | 2 | 5 | 2 | 2 |
| node.OperandNode | 0 | 1 | 11 | 3 | 6 | 1 | 2 |
| node.OperandPowFunc | 0 | 7 | 17 | 1 | 4 | 2 | 1 |
| node.OperatorAdd | 0 | 3 | 12 | 1 | 4 | 2 | 1 |
| node.OperatorMulti | 0 | 3 | 12 | 1 | 4 | 2 | 1 |
| node.OperatorNode | 0 | 1 | 11 | 4 | 9 | 1 | 1 |
| node.OperatorPow | 0 | 3 | 12 | 2 | 5 | 2 | 2 |
| node.OperatorSubtract | 0 | 3 | 12 | 1 | 4 | 2 | 1 |
| node.TriCos | 0 | 4 | 12 | 1 | 4 | 2 | 1 |
| node.TriNode | 0 | 1 | 11 | 2 | 6 | 1 | 1 |
| node.TriSin | 0 | 4 | 12 | 1 | 4 | 2 | 1 |
| parser.CustomizedFunc | 2 | 3 | 30 | 3 | 3 | 3 | 2 |
| parser.CustomizedFuncSet | 2 | 1 | 30 | 2 | 3 | 1 | 2 |
| parser.Parser | 2 | 17 | 30 | 2 | 3 | 3 | 2 |
| unit.BaseUnit | 6 | 6 | 9 | 2 | 22 | 1 | 1 |
| unit.BaseUnit.InCmp | 6 | 2 | 9 | 1 | 22 | 1 | 1 |
| unit.Constant | 0 | 0 | 0 | 8 | 24 | 0 | 2 |
| unit.Cos | 6 | 3 | 9 | 4 | 22 | 1 | 2 |
| unit.Cos.InCmp | 6 | 3 | 9 | 1 | 22 | 1 | 1 |
| unit.PowFunc | 0 | 1 | 1 | 8 | 23 | 1 | 2 |
| unit.Sin | 6 | 4 | 9 | 4 | 22 | 1 | 2 |
| unit.Sin.InCmp | 6 | 3 | 9 | 1 | 22 | 1 | 1 |
| unit.TriFunc | 0 | 0 | 0 | 1 | 23 | 0 | 1 |
| unit.Unit | 6 | 6 | 9 | 12 | 22 | 1 | 3 |
| Interface | Cyclic | Dcy | Dcy* | Dpt | Dpt* | PDcy | PDpt |
|---|---|---|---|---|---|---|---|
| node.Node | 0 | 1 | 10 | 14 | 15 | 1 | 3 |
优缺点分析
缺点
-
代码量过于庞大,达到了1600+行
-
类的数目过多,类中方法数目也过多,显得比较复杂
-
对于形式提取不彻底,分别处理三角函数因子和幂函数因子
优点
-
软件包分类明确,类分工明确
-
第三次作业
概览
| 类名 | 属性个数 | 方法个数 | 实现方法 | 总代码规模 |
|---|---|---|---|---|
| Lexer | 8 | 20 | 0 | 230 |
| ReadKind | 0 | 0 | 0 | 4 |
| FuncKind | 0 | 0 | 0 | 4 |
| OperatorKind | 0 | 0 | 0 | 4 |
| VarKind | 1 | 2 | 0 | 24 |
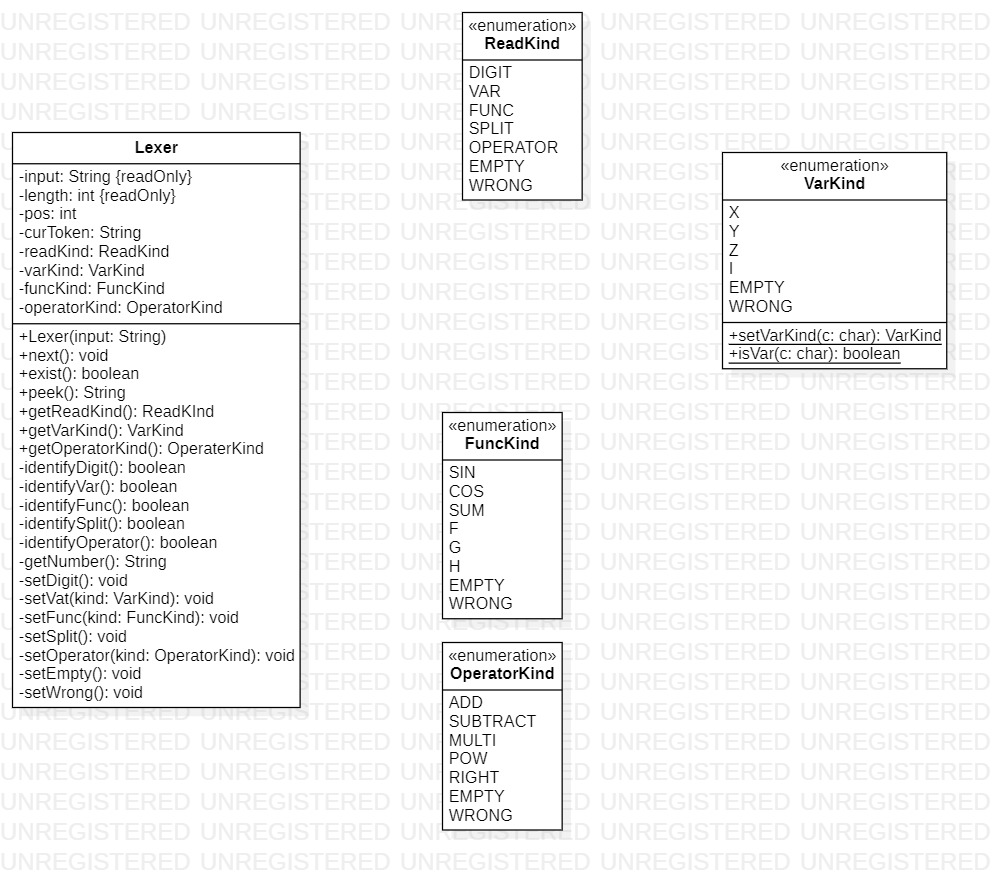
设计考虑
本软件包由一个同名类作为主题,配以四个枚举类作为辅助,主要用于对输入字符串的初步解析
各类分析
Lexer
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| Lexer | 0 | 6 | |
| next | 6 | 21 | 本方法主要用于移动并解析出下一个语义块,其中语义块分类较多 |
| exist | 0 | 1 | |
| getReadKind | 0 | 1 | |
| getVarKind | 0 | 1 | |
| getFuncKind | 0 | 1 | |
| getOperatorKind | 0 | 1 | |
| identifyDigit | 1 | 5 | |
| identifyVar | 1 | 7 | |
| identifyFunc | 6 | 53 | 本方法用于尝试以函数方式解析语义块,函数分为sum、sin、cos、f、g、h |
| identifySplit | 1 | 8 | |
| identifyOperator | 7 | 35 | 本方法用于尝试以符号方式解析,此处尝试解析的符号有'(',')','+','-','*','**' |
| getNumber | 0 | 6 | |
| setDigit | 0 | 4 | |
| setVar | 0 | 4 | |
| setSplit | 0 | 4 | |
| setOperator | 0 | 4 | |
| setEmpty | 0 | 4 | |
| setWrong | 0 | 4 |
本类用于对输入的字符串进行初步解析,自动对输入字符串划分为单独的语义块,并对外提供方法获取该语义块的类型,使解析类中的解析方法使用时可以与具体的字符串内值进行完全分离。同时,语义块整体化避免解析时逐个字符的遍历分析。设计时考虑到可能出现的异常读取(事实上最后没有此要求),如函数名称不全等,也可便于将输入表达式的非法字符异常和表达式结构异常进行区分。
ReadKind
本类为枚举类,设计用于分辨语义块的总体类型,即数字、变量、函数、分隔符、操作符、空、错误。
同时,此类以及接下来的另外3个枚举类共同实现了对语义块类型的两级完整划分,此时,解析方法便可通过调用lexer中的getKind等一系列方法直接获得当前语义块的类型,而不用再次解析字符的语义,定义为枚举类型而非直接的int常量进行区分提高可读性和易维护性
FuncKind
本类为枚举类,设计用于分辨函数类型(包括三角函数sin、cos,自定义函数f、g、h,求和函数sum
OperatorKind
本类为枚举类,设计用于分辨操作符类型
VarKind
本类为枚举类,设计用于分辨变量类型
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| setVarKind | 6 | 15 | 用于根据字符自动转化为相应枚举类型 |
node软件包
概览
| 类名 | 属性个数 | 方法个数 | 总代码规模 |
|---|---|---|---|
| Node | 0 | 2 | 6 |
| OperandNode | 1 | 1 | 11 |
| OperandDigit | 0 | 1 | 20 |
| OperandPowFunc | 1 | 0 | 52 |
| OperatorNode | 2 | 2 | 11 |
| OperatorAdd | 0 | 0 | 19 |
| OperatorSubtract | 0 | 0 | 19 |
| OperatorMulti | 0 | 0 | 19 |
| OperatorPow | 1 | 0 | 19 |
| TriNode | 0 | 0 | 4 |
| TriSin | 0 | 0 | 20 |
| TriCos | 0 | 0 | 20 |
| NodeVarKind | 0 | 1 | 14 |
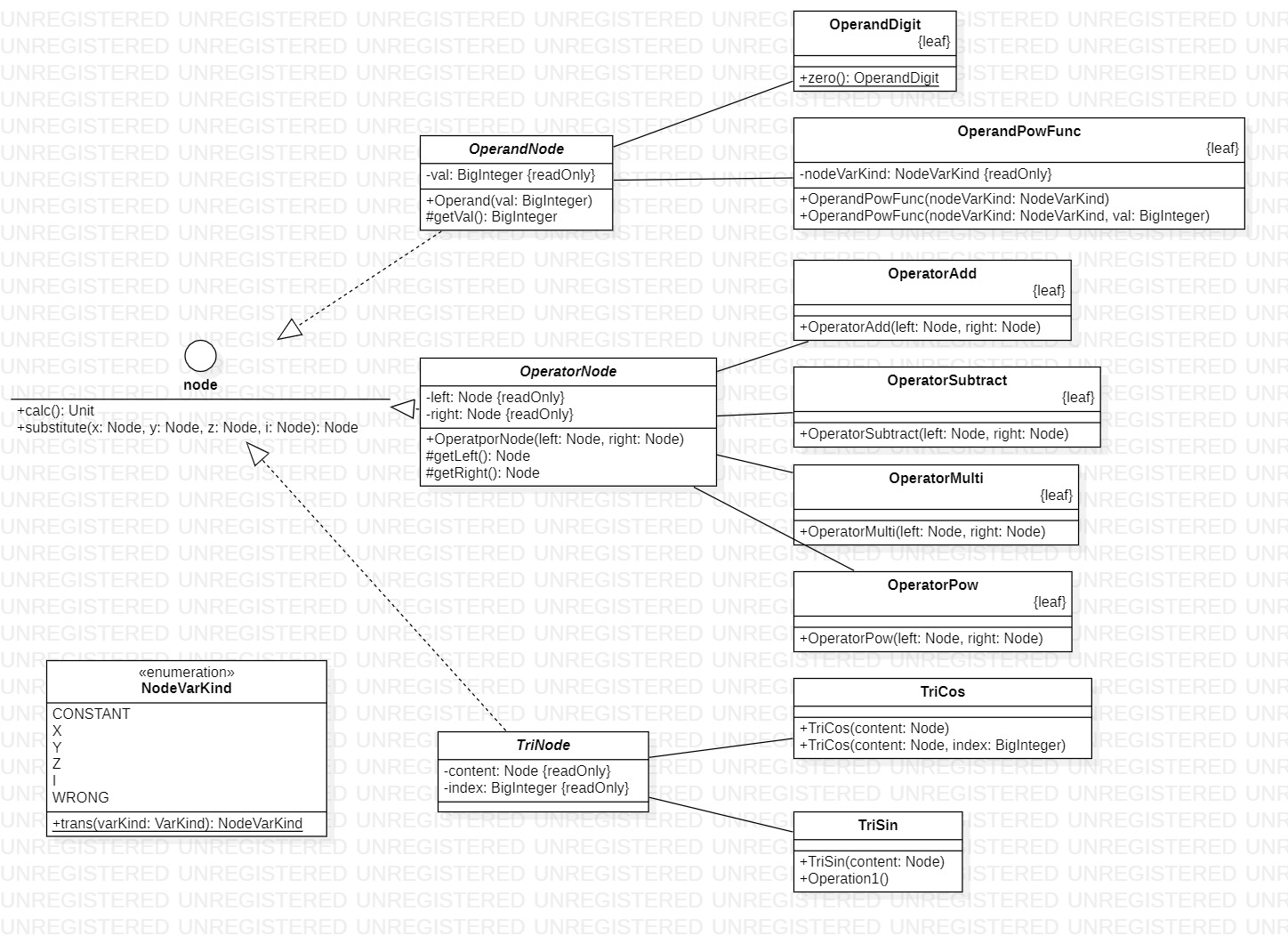
设计考虑
本软件包用于表达解析后生成的树形逻辑结构,由一个接口及实现其的众多类,配以一个枚举类组成,设计时考虑到为尽可能减少bug,将逻辑结构和计算结构分离,故设计此软件包
各类分析
Node
本类为接口,统一软件包中的绝大部分类,提取计算节点的共同逻辑,提供替换和计算两个方法,用于实现因子的代入和最终计算结果的生成
| 方法名 |
|---|
| calc() |
| substitute() |
OperandNode
本类设计作为常数节点类和幂函数节点类的父类,提取其共同属性(一个BigInteger的值),同时设计为虚类禁止实例化
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| OperandNode | 0 | 1 | |
| getVal | 0 | 1 |
OperandDigit
本类为常数节点类,作为表达式树中的常数
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| OperandDigit | 0 | 1 | |
| zero | 0 | 1 | |
| calc | 0 | 1 | |
| substitute | 0 | 1 |
OperatorPowFunc
本类为幂函数节点类,作为表达式中的幂函数,同时,其他node类实现方式均为返回自身,此类独特实现substitude方法,实现因子的代入
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| OperandPowFunc | 0 | 2 | |
| OperandPowFunc | 1 | 4 | |
| calc | 0 | 1 | |
| substitute | 6 | 27 | 需要根据节点变量类型进行替换 |
OperatorNode
本类设计为所有二元操作符节点类的父类,提取子类的公共属性(左儿子和右儿子),设计为虚类,禁止实例化
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| OperatorNode | 0 | 2 | |
| getLeft | 0 | 1 | |
| getRight | 0 | 1 |
OperatorAdd
本类以及以下的3个类,均为普通的二元运算操作(加、减、乘、乘方)
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| OperatorAdd | 0 | 1 | |
| calc | 0 | 1 | |
| toString | 0 | 1 | |
| substitude | 0 | 1 |
OperatorSubtract
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| OperatorSubtract | 0 | 1 | |
| calc | 0 | 1 | |
| toString | 0 | 1 | |
| substitude | 0 | 1 |
OperatorMulti
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| OperatorMulti | 0 | 1 | |
| calc | 0 | 1 | |
| toString | 0 | 1 | |
| substitude | 0 | 1 |
OperatorPow
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| OperatorPow | 0 | 1 | |
| calc | 0 | 1 | |
| toString | 0 | 1 | |
| substitude | 0 | 1 |
TriNode
本类设计为三角函数节点类的父节点,提取子类需要的两个属性(内容和指数),在逻辑上,sin和cos也均为三角函数的一种,也考虑到可能出现的其他三角函数,故设计此类,同时设计为虚类,禁止实例化
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| TriNode | 0 | 2 | |
| TriNode | 0 | 2 | |
| getContent | 0 | 1 | |
| getIndex | 0 | 1 |
TriSin
本类及TriCos类均为具体的三角函数sin、cos
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| TriSin | 0 | 2 | |
| TriSin | 0 | 2 | |
| getContent | 0 | 1 | |
| getIndex | 0 | 1 |
TriCos
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| TriCos | 0 | 2 | |
| TriCos | 0 | 2 | |
| getContent | 0 | 1 | |
| getIndex | 0 | 1 |
NodeVarKind
枚举类,用于保存幂函数节点内部变量类型
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| trans | 0 | 5 |
parser软件包
概览
| 类名 | 属性个数 | 方法个数 | 总代码规模 |
|---|---|---|---|
| Parser | 2 | 15 | 248 |
| CustomizedFuncSet | 1 | 2 | 14 |
| CustomizedFunc | 6 | 3 | 44 |
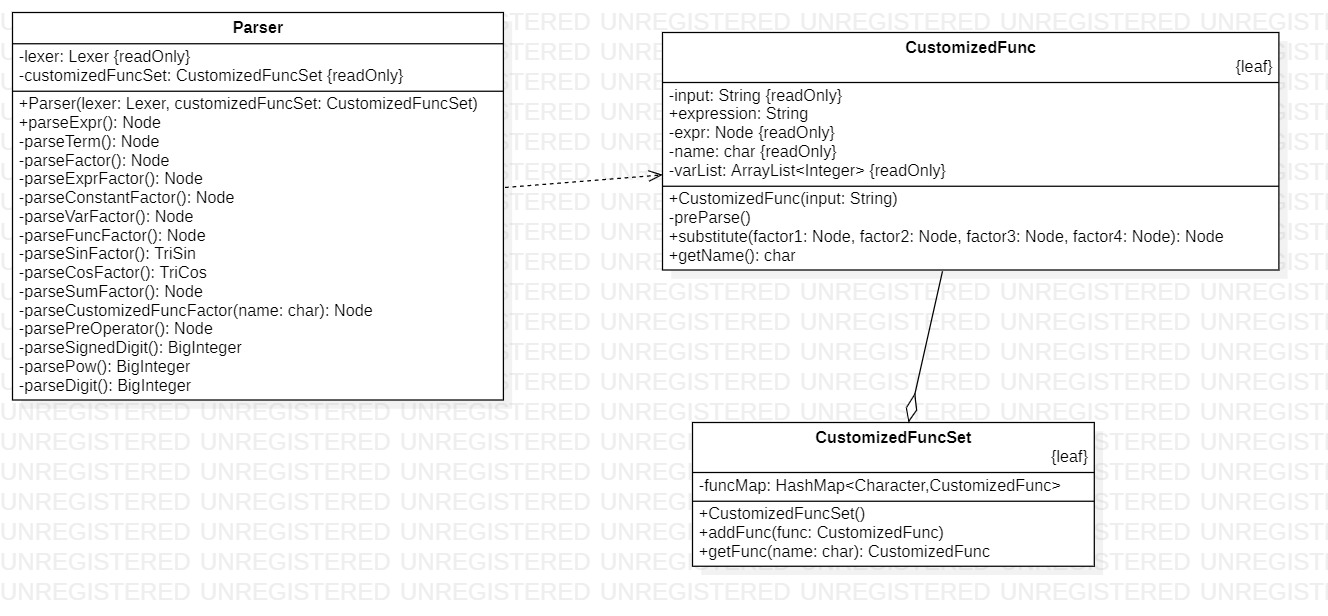
设计考虑
本软件包负责对函数、表达式的解析,将生成对应的逻辑结构
各类分析
Parser
本类负责对表达式的解析,在解析方法中,具体分为5级进行解析,包括表达式解析->项解析->因子解析->因子分类解析->辅助解析方法,辅助解析方法又分为两级:指数和带符号整数解析->无符号整数解析
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| Parser | 0 | 2 | |
| parseExpr | 2 | 22 | |
| parserTerm | 1 | 17 | |
| parseExprFactor | 4 | 12 | |
| parseConstantFactor | 1 | 7 | |
| parseVarFactor | 2 | 10 | |
| parseFuncFactor | 7 | 16 | 本方法识别函数类因子的种类,调用不同的解析方法 |
| parseSinFactor | 1 | 10 | |
| parseCosFactor | 1 | 10 | |
| parseSumFactor | 2 | 23 | |
| parseCustomizedFuncFactor | 3 | 12 | |
| parsePreOperator | 3 | 13 | |
| parseSignedDigit | 3 | 17 | |
| parsePow | 2 | 8 | |
| parseDigit | 1 | 9 |
CustomizedFuncSet
本类实际为自定义函数的集合类,负责对自定义函数集合的简单维护
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| CustomizedFuncSet | 0 | 1 | |
| addFunc | 0 | 1 | |
| getFunc | 0 | 1 |
CustomizedFunc
本类为自定义函数的解析类,用于解析并存储自定义函数的逻辑结构,提供替换方法
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| CustomizedFunc | 0 | 7 | |
| preParse | 0 | 9 | |
| substitute | 0 | 7 | |
| getName | 0 | 1 |
unit软件包
概览
| 类名 | 属性个数 | 方法个数 | 总代码规模 |
|---|---|---|---|
| CalcJudge | 0 | 3 | 6 |
| Unit | 3 | 10 | 215 |
| BaseUnit | 6 | 17 | 404 |
| PowFunc | 2 | 5 | 52 |
| Constant | 4 | 9 | 55 |
| TriFunc | 2 | 5 | 45 |
| Sin | 0 | 4 | 57 |
| Cos | 0 | 3 | 54 |
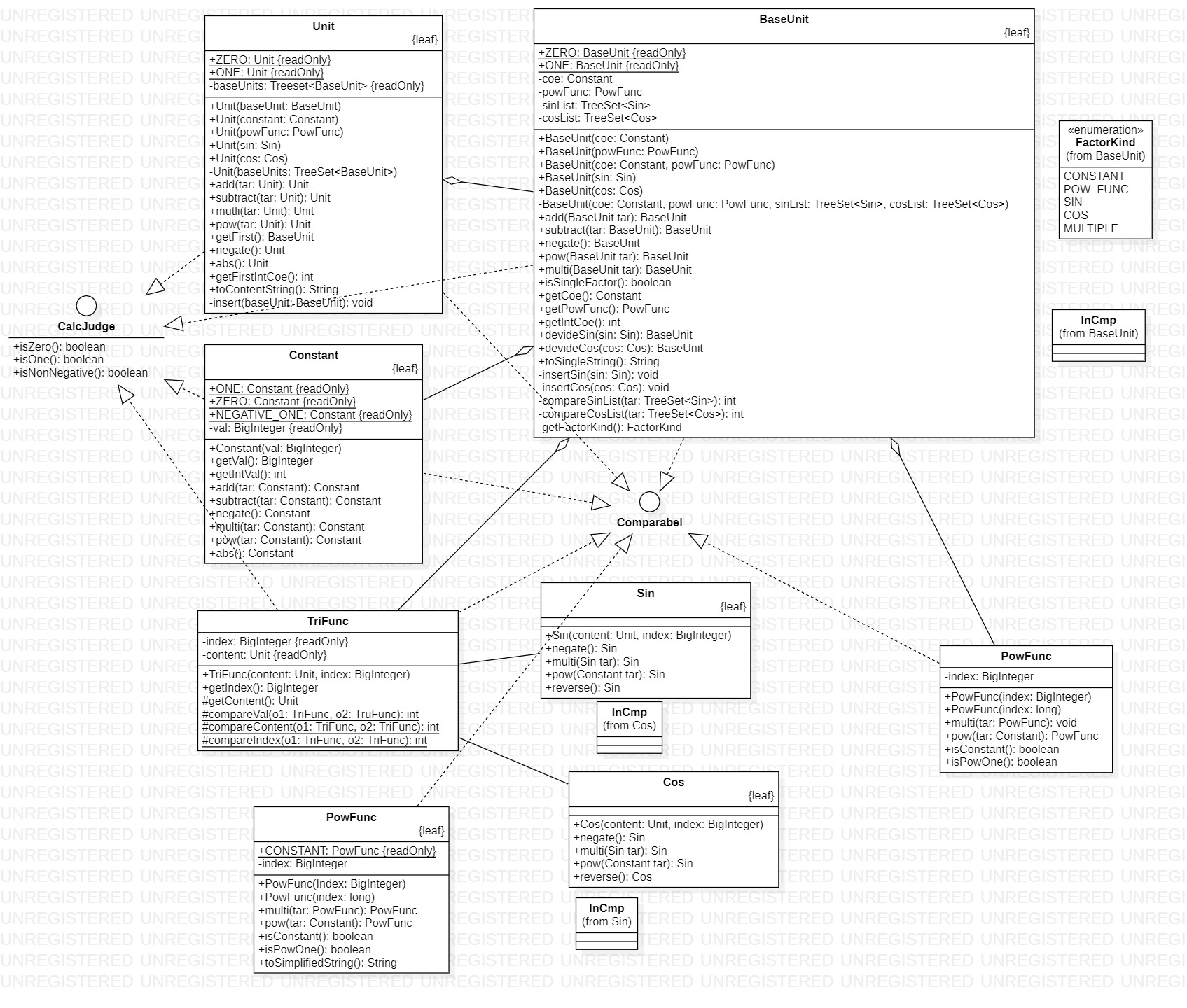
设计考虑
本软件包负责对运算过程中数据的维护,严格将运算结构分为表达式、项、因子三层,同时,这里的项和因子均已完全展开,即不会再出现表达式因子
各类分析
CalcJudge
本类设计为接口,含三个公有方法,限定实现其的类必须通过三个方法提供相应的信息
Unit
本类维护一个BaseUnit组成的集合,提供必要的计算方法和信息获取方法,同时,尽可能设定为不可变类,运算均创建一个新对象,提供唯一的、私有的方法用于改变必要的信息。
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| Unit | 0 | 1 | |
| Unit | 1 | 3 | |
| Unit | 1 | 4 | |
| Unit | 0 | 2 | |
| Unit | 1 | 4 | |
| Unit | 0 | 2 | |
| Unit | 0 | 2 | |
| add | 0 | 4 | |
| subtract | 0 | 4 | |
| multi | 1 | 9 | |
| pow | 3 | 17 | |
| getFirst | 1 | 5 | |
| abs | 1 | 4 | |
| getFirstIntCoe | 1 | 4 | |
| toContentString | 1 | 4 | |
| insert | 5 | 21 | |
| isZero | 0 | 1 | |
| isOne | 2 | 9 | |
| isNonNegative | 1 | 5 | |
| compareTo | 2 | 13 | |
| toString | 3 | 29 |
BaseUnit
本类设计为底层因子的集合,对应为项层次,尽可能设定为不可变类,运算均创建一个新对象,提供唯二的、私有的方法用于改变必要的信息。
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| BaseUnit | 0 | 4 | |
| BaseUnit | 0 | 4 | |
| BaseUnit | 1 | 7 | |
| BaseUnit | 3 | 29 | |
| BaseUnit | 1 | 7 | |
| BaseUnit | 1 | 13 | |
| add | 0 | 1 | |
| subtract | 0 | 1 | |
| negate | 0 | 1 | |
| pow | 2 | 15 | |
| multi | 1 | 15 | |
| isSingleFactor | 0 | 1 | |
| getCoe | 0 | 1 | |
| getIntCoe | 0 | 1 | |
| divideSin | 5 | 18 | |
| divideCos | 5 | 18 | |
| toSingleString | 5 | 12 | |
| insertSin | 3 | 20 | |
| insertCos | 3 | 20 | |
| compareSinList | 2 | 17 | |
| compareCosList | 2 | 17 | |
| getFactorKind | 6 | 20 | 负责对因子类型的判断(如单常数、单幂函数、单sin、单cos、多因子) |
| compareTo | 3 | 16 | |
| isZero | 0 | 1 | |
| isOne | 0 | 1 | |
| isNonNegative | 0 | 1 | |
| toString | 10 | 64 | 输出格式控制 |
PowFunc
本类负责储存幂函数,提供计算方法和两种字符串转换方法
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| PowFunc | 0 | 1 | |
| PowFunc | 0 | 1 | |
| multi | 0 | 1 | |
| pow | 0 | 1 | |
| isConstant | 0 | 1 | |
| isPowOne | 0 | 1 | |
| compareTo | 0 | 1 | |
| toSimplifiedString | 3 | 11 | |
| toString | 2 | 9 |
Constant
本类实际设计为BigIteger的包装类,选择性的实现部分功能,并扩展部分功能
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| Constant | 0 | 1 | |
| getVal | 0 | 1 | |
| getIntVal | 0 | 1 | |
| add | 0 | 1 | |
| subtract | 0 | 1 | |
| negate | 0 | 1 | |
| multi | 0 | 1 | |
| pow | 0 | 1 | |
| abs | 0 | 1 | |
| isNonNegative | 0 | 1 | |
| isZero | 0 | 1 | |
| isOne | 0 | 1 | |
| isNegativeOne | 0 | 1 | |
| compareTo | 0 | 1 | |
| toString | 0 | 1 |
TriFunc
本类设计为两个三角函数类的父类,提取了子类共有的两个属性、比较方法,并设定了一个构造方法,用于保证特定数值(如content为0,1时,index取定制)下定义为相同信息
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| TriFunc | 3 | 19 | |
| getIndex | 0 | 1 | |
| getContent | 0 | 1 | |
| compareVal | 1 | 6 | |
| compareContent | 0 | 1 | |
| compareIndex | 0 | 1 |
Sin
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| Sin | 0 | 1 | |
| isNonNegative | 0 | 1 | |
| isZero | 0 | 1 | |
| isOne | 0 | 1 | |
| negate | 0 | 1 | |
| multi | 0 | 1 | |
| pow | 0 | 1 | |
| reverse | 0 | 1 | |
| compareTo | 0 | 1 | |
| toString | 3 | 16 |
Cos
| 方法名 | 控制分支数目 | 方法规模 | 备注(控制分支较多、规模较大原因) |
|---|---|---|---|
| Cos | 0 | 1 | |
| isNonNegative | 0 | 1 | |
| isZero | 0 | 1 | |
| isOne | 0 | 1 | |
| negate | 0 | 1 | |
| multi | 0 | 1 | |
| pow | 0 | 1 | |
| reverse | 0 | 1 | |
| compareTo | 0 | 1 | |
| toString | 3 | 14 |
类间依赖度分析
| Class | Cyclic | Dcy | Dcy* | Dpt | Dpt* | PDcy | PDpt |
|---|---|---|---|---|---|---|---|
| Launch | 0 | 6 | 33 | 0 | 0 | 4 | 0 |
| lexer.FuncKind | 0 | 0 | 0 | 2 | 5 | 0 | 2 |
| lexer.Lexer | 0 | 4 | 4 | 3 | 4 | 1 | 2 |
| lexer.OperatorKind | 0 | 0 | 0 | 2 | 5 | 0 | 2 |
| lexer.ReadKind | 0 | 0 | 0 | 2 | 5 | 0 | 2 |
| lexer.VarKind | 0 | 0 | 0 | 2 | 7 | 0 | 2 |
| node.NodeVarKind | 0 | 1 | 1 | 2 | 5 | 1 | 2 |
| node.OperandDigit | 0 | 4 | 14 | 2 | 5 | 2 | 2 |
| node.OperandNode | 0 | 1 | 13 | 3 | 6 | 1 | 2 |
| node.OperandPowFunc | 0 | 7 | 19 | 1 | 4 | 2 | 1 |
| node.OperatorAdd | 0 | 3 | 14 | 1 | 4 | 2 | 1 |
| node.OperatorMulti | 0 | 3 | 14 | 1 | 4 | 2 | 1 |
| node.OperatorNode | 0 | 1 | 13 | 4 | 9 | 1 | 1 |
| node.OperatorPow | 0 | 3 | 14 | 2 | 5 | 2 | 2 |
| node.OperatorSubtract | 0 | 3 | 14 | 1 | 4 | 2 | 1 |
| node.TriCos | 0 | 4 | 14 | 1 | 4 | 2 | 1 |
| node.TriNode | 0 | 1 | 13 | 2 | 6 | 1 | 1 |
| node.TriSin | 0 | 4 | 14 | 1 | 4 | 2 | 1 |
| parser.CustomizedFunc | 2 | 3 | 32 | 3 | 3 | 3 | 2 |
| parser.CustomizedFuncSet | 2 | 1 | 32 | 2 | 3 | 1 | 2 |
| parser.Parser | 2 | 17 | 32 | 2 | 3 | 3 | 2 |
| unit.BaseUnit | 7 | 9 | 11 | 2 | 23 | 1 | 1 |
| unit.BaseUnit.FactorKind | 0 | 0 | 0 | 1 | 24 | 0 | 1 |
| unit.BaseUnit.InCmp | 7 | 2 | 11 | 1 | 23 | 1 | 1 |
| unit.Constant | 0 | 1 | 1 | 6 | 25 | 1 | 2 |
| unit.Cos | 7 | 3 | 11 | 4 | 23 | 1 | 2 |
| unit.Cos.InCmp | 7 | 2 | 11 | 1 | 23 | 1 | 1 |
| unit.PowFunc | 0 | 1 | 2 | 4 | 24 | 1 | 2 |
| unit.Sin | 7 | 3 | 11 | 4 | 23 | 1 | 2 |
| unit.Sin.InCmp | 7 | 2 | 11 | 1 | 23 | 1 | 1 |
| unit.TriFunc | 7 | 2 | 11 | 5 | 23 | 1 | 1 |
| unit.Unit | 7 | 7 | 11 | 13 | 23 | 1 | 3 |
| Interface | Cyclic | Dcy | Dcy* | Dpt | Dpt* | PDcy | PDpt |
|---|---|---|---|---|---|---|---|
| node.Node | 0 | 1 | 12 | 14 | 15 | 1 | 3 |
| unit.CalcJudge | 0 | 0 | 0 | 4 | 26 | 0 |
第二部分
在先前的度量分析中,简单介绍了各类的设计考虑,现在将进一步的对各类以及总体设计思路进行详细的分析,由于最终第三次作业为最终成品,能最大限度展示设计时的思考,此处便集中对第三次作业进行分析
基本设计思路
-
本单元的作业采用分级架构思想,总体采取三级模式:1. 预解析;2. 解析; 3、计算,在各模式内部,又进行分层处理,最终层层嵌套,形成最终的模式。
-
-
第二条自然导出此条,对于任何类尽可能设置为不可变类,至少不能提供public的修改类中信息的方法
-
功能的尽可能切分,单一方法执行单一功能
预解析
预解析将负责对原始的表达式字符串处理为一个语义块序列,将属于同一个语义块内的字符或者字符集统一化处理,如左括号、右括号、称号、乘方号、sin、cos、sum等,同时对语义块的类型进行完整的分级定义限定,避免解析时涉及对字符串的处理和解析操作。通过对解析的分级来提高可靠性
预解析功能的类集中在lexer软件包
ReadKind、OperatorKind、VarKind、FuncKind
先前提到,预解析将会分类语义块以此避免解析方法直接对字符串的解析操作,因此,解析方法势必需要从预解析即lexer类中获取语义块类型信息,然而考虑到
-
直接定义为int常量作为区分代码可读性较差,难以维护
-
多个常量后期调整顺序时(如将最后一个提升至第一个),需要同时修改多个常量
因此,此处将类型定义为枚举
同时,又考虑到
-
语义块类型自身也具有明显的层级,如果直接仅提供一级,可能导致种类过多,
-
如果只需要明确大致类型(如是否为操作符)时,也会导致if的可能性过多
于是,最终采取ReadKind枚举类控制总体类型,OperatorKind、VarKind、FuncKind实现对类型的细分
此外,注意到
-
字符串预解析结束时,也因停止解析,但不进行额外处理的话,解析方法每次还需向lexer类获取当前是否停止读入的信息,
-
后期可能涉及异常输入,导致语义块解析错误
统一在各枚举类中增设EMPTY和WRONG常量,用于记录如上情况,因此,如果解析方法要求下一个语义块需要为特定类型时,只需获取该类型判断是否为指定类型即可
lexer
本类即为预解析的实际操作类,
-
为了避免外界对内部字符串的过多干扰,仅对外提供next()方法用于切换语义块,peek()方法获取当前语义块的内容,getKind类方法(含getReadKind等)获取当前语义块类型
-
考虑到解析语义块类型本身也具有分类和分层结构,对每一种分类和每一个分层单独定义解析方法
-
考虑到语义块类型应当进行统一修改,如一旦设定为左括号,那么readKind应为OPERATOR,OperatorKind应为LEFT,而其余应置为EMPTY,定义了设定特定语义块类型的一系列setKind类方法,统一进行设定,也使得类中各方法功能尽可能独立和完整
-
解析
解析即将语义块序列解析成为一个逻辑结构,此处采用树形结构进行存储,将逻辑结构与运算结构分离,也是为了降低Bug发生几率,同时也更容易定位Bug,而且,逻辑结构与运算结构分离,也有利于自定义函数的实现
在解析中,自定义函数虽然实际也为表达式,但与表达式不同的是,它会涉及替换操作,此处的替换包含两方面,一是待展开表达式中因子对其的替换,而是将上一次替换的结果替换待展开表达式。
-
如果采取字符串替换的暴力方式,此处实现并不麻烦,然而,字符窜替换相当于忽略了一部分结构信息,极易产生Bug,这与整体设计思路不符。
-
逻辑结构和运算结构实际上几乎完全分离,运算结构上实现替换较为困难,而逻辑结构的树形结构替换较为容易,完全可以将替换操作转移至逻辑结构中进行
-
函数解析时完全可以复用解析类的操作,记录最终逻辑结构树的头结点,替换时返回头结点递归替换后产生的新表达式树的头结点即可
解析主要包括两个软件包,分别为解析方法类和解析后的结构类
Node
考虑到
-
结点类确实有公有的方法如计算和替换,提出作为接口并非不可
-
解析类方法的返回值需要一个统一的类型
因此此处设定一个Node的公共接口
对于所有实现Node的类,均设定为不可变类(非最终类至少值不可变),以此来保证安全性
OperandNode
分析可知,对于幂函数和常数,实际只需要记录一个val值即可,为了提高层次性,与OperatorNode对应,设置了此虚类
OperatorNode
考虑到所有的二元操作符均需要记录其两个儿子节点,设置了此虚类
TriNode
三角函数节点与操作符节点不同,如果以运算符视角看待,三角函数节点为一元运算符,但同时,为了减少树的深度,此处不仅记录其内容,也同时记录其指数值,所有的三角函数均会有以上两个公共属性,为了层次的对应和后期的扩展,设置了此虚类
OperandDigit、OpertorAdd、OperatorSubtract、OperatorMulti、OperatorPow、TriCos、TriSin
此部分均各自为以上三个虚类其中之一的子类,实现运算方法时根据其自身性质调用运算结构的方法即可,对于替换方法,即返回其本身或其儿子节点替换按原关系后构成的同一类型节点即可
OperandPowFunc
虽然同为以上三个虚类其中之一的子类,但幂函数类本身直接包括了变量,为替换方法实现的真正节点,因此,此类必须保存自身的变量类型信息
NodeVarKind
枚举类,选用枚举类的理由基本不变,此类便是OperandPowFunc用来记录变量类型信息的类型
CustomizedFunc
用于解析和储存自定义函数的类,对外提供一个统一的替换函数
该类复用了解析类即Parser类用于构建自己的逻辑结构
CustomizedFuncSet
本质上即为CustomizedFunc的容器,内部使用HashMap实现。
为了防止外界对容器的过多非必要或者不安全操作,此处选择将容器单独提取出来使用一个类进行包装,仅提供唯一的加入函数和取出函数功能
Parser
本类即为实现解析功能的类,考虑到:
-
作业中以形式化描述作为最终依据,递归下降法与之十分契合
-
本身表达式分层明显的逻辑结构,适合使用递归下降法
-
与正则表达式相比,递归下降法有着更高的可靠性,尤其是大正则,很容易导致爆栈等的发生
最终,选择递归下降法作为解析方法
与逻辑结构相对应的,内部方法也进行层次化处理,
第一层是parseExpr,解析表达式,也是唯一的public方法
第二层是parseTerm,解析项,
第三层是parseFactor,预解析因子,根据因子特征分类调用不同的解析方法
第四层是parseConstantFactor、parseVarFactor、parseFuncFactor,此处将涉及三角函数、自定义函数和sum函数的因子解析再次增加一层作为预解析,
第五层是parseSinFactor,parseCosFactor,parseSumFactor,parseCustomizedFuncFactor
以上五层均为逻辑上的分层
第六层parseSignedDigit、parsePow
第七层parseDigit
上两层即为解析的辅助方法
计算
计算其实很大程度上依赖于实现存储计算数据的数据结构,在课堂上老师提供了一种优秀的架构,即将三角函数等函数均视为一个不同底数,带有指数的一个因子,然而,我并未采取这种结构,反而采取更为复杂的方式,主要是处于如下考虑:
-
合并同类项时需要判断两项是否能进行合并,但如果直接进行遍历比较,将具有较高的复杂度,
-
容器内各项的位置不可控,这点也将极大的影响到后续的相等比较
-
以此法线性容器维护也不够安全
因此,如果能实现排序,那么容器内元素位置确定,不仅在合并时可以进行二分查找,极大的提升效率,还可以极大的简化两个容器的比较——容器size相等,按序遍历相等。
但是,较高的抽象数据层次导致很难实现排序的要求。例如,对于不同的子类,需要赋予不同的优先级,增加了操作的复杂度,然后,同一子类之间的内部还需自定义新的比较函数(此处还无法通过重写compareTo实现),同时,合并同类项时能否合并和最终的排序依据本身不同(例如sin(x)**2和 sin(x)**3不能视为相等,然而却在乘法时可以合并),导致此处排序更难实现。
然而,如果在储存时选择将不同因子分类储存,不仅直接避免了不同因子排序的要求,避免了因子类型的转换,而且,相对而言,对于完全确定种类的因子,合并操作时安全性也会更高。
因此,我最终选择以系数、幂函数、sinList、cosList方式储存
而对于排序本来期望实现的二分插入等功能,选择TreeSet这一容器进行维护,也是出于如下考虑:
-
TreeSet作为官方提供的类,进行二分查找时显然比自己手写更快也更安全
-
TreeSet进行比较时可以不以实现CompareTo方式定义比较方式,CompareTo本身尽可能应将所有有必要比较元素作为比较依据,然而合并时显然只选择了一部分,但是更高层次比较时,又需要子元素的全属性比较,TreeSet可以传入一个指定的比较器,而比较器可以通过静态内部类的方式实现在Sin和Cos类的内部
-
TreeSet能自动维护顺序,节省了代码量
计算主要为Unit软件包
calcUnit
本接口的方法用于判断类中保存因子或项的情况,便于合并和检查元素的合法性
事实上,此处接口的设立完全是处于统一方法的目的,本身不会利用父类与子类间相互转换的关系,而且,对于某些类而言,特定方法的值永远是定值(如cos类不可能返回0值)。
Unit
本类设计为BaseUnit的集合容器,内部以TreeSet作为实际的保存容器。考虑到Java的类传递的均为引用,如果此类提供给外界修改信息的方法将是极为危险的,即使是私有的修改方法由于编写者的书屋也会导致不确定性。同时,本类中储存元素也有极大的要求,为了便于合并,0元素将不会被保存,如果仅有0元素,那么容器将为空,外界的直接修改极有可能破坏这一要求。
因此,本类的设计向着不可变类的方向前进,至少保证就提供的公共方法而言,本类保存的信息不可修改
-
构造方法:公共的构造方法为针对不同单因子种类的构造方法,构造方法中会严格判断传入的因子是否为0,私有的构造方法用于复制,来源为Unit类,可以不用检查
-
运算函数:add、subtract等计算均返回一个新类,且保证与原类无关
-
私有的insert方法,本方法为唯一的可修改类中信息的方法,用于维护容器中的元素和合并操作,insert方法会检查传入值和最终计算值的可靠性。除此方法外,其他试图修改信息的方法必须调用此方法。
BaseUnit
本类保存的值实质上为系数 * 幂函数 * sin * cos,系数和幂函数单独保存为属性,sin和cos以list形式保存,同Unit类设计考虑相同,均会尽可能保证信息的不可变性
Constant
本类实际上包装了一个BigInteger的值,考虑到:
-
需要提供0,-1,1三种常量值,而BigInteger仅能提供0和1
-
需要实现calcJudge中限定的几种判定
-
限制意外的操作
因此封装了BigInteger类
PowFunc
就本质而言,PowFunc保存也是一个BigInteger的值,但考虑到:
-
需要提供幂函数为常数(即index=0)的值
-
需要提供判断是否为常数的方法
-
乘方时的实际操作与BigIntger的pow操作不同
最终构建了此类
TriFunc
本类作为三角函数类的父类,
-
三角函数因子有着均由内容和指数构成,有公共属性
-
三角函数因子可能不止有sin和cos两种
-
同类三角函数的比较实质上只需要比较内容和指数即可,无需重复实现
-
三角函数在其中内容为0和指数为0时值均为常数,即为特殊状态,内容为0时指数任意(不为0),指数为0时内容任意,这导致可能出现三角函数值相同,但由于指数或内容不同而能够判定大小,需要统一限定特殊状态下的属性值,因此需要公共的构造函数维护这一特殊情况
因此构建了此类
Sin、Cos
设置为不可变类即可
优缺点总结
缺点
-
代码量过于庞大,大量的冗余操作,类中方法数过多,虽然追求的是可靠性,但这也会带来新的风险
-
抽象层次不够,虽然有各种各样的理由没有对因子进行足够的抽象,但这始终是一大痛点
-
过于追求层次性,功能切分可能过细,这点也变相的导致了第一个缺点的发生
优点
-
逻辑清晰,维护和迭代时思考负担较小
-
第三部分
强测
本单元连续三次作业在公测和互测时均未发现Bug,仅在自我检测时发现了诸如代码敲错,程序迭代时代码复制部分不全等低级错误
互测
幸运的是,三次作业均未被hack
对方
1
首次作业时成功hack了两个目标,其中一位同学在试图合并连续符号时遗漏一种情况,另一位同学在合并时,合并出的0项并未移除,并且在接下来的合并中将始终判定为可以与新项合并,导致了Bug
2
第二次作业仅hack了一个目标,其在解析三角函数因子时,其中的带符号整数错误的仅用无符号整数的方法进行解析
3
第三次作业hack了三个目标,Bug分析如下:
-
输出格式错误,包含三角函数内必须为因子,三角函数外不能有括号,且有括号项不能带指数
-
sum使用int存储上下限
-
sum下限大于上限时,默认计算了一次因子
-
sum中合并时哈希出错
-
未考虑到项之间的连续三个符号
分析
程序的Bug实际上主要来源于两个方向
-
自身程序编写时遗漏了语句,如第一次互测时,尽管未移除0项可能导致结果偏长,但本质上是因为漏写了一条break语句(Bug发生在乘方,正好比加减合并时漏了一个break)
-
题目分析不够,典型的便是对于sum的处理,sum中的上下限可以超出int,同时下限大于上限时题目上明显强调了必须为0,三角函数内可能出现的带符号整数也是同理
架构设计体验
迭代日志
在第一次构建中,奠定了整个架构三层处理的模型,初步完成了逻辑结构、运算结构的建立,以及解析方法的实现
第二次构建是一单元作业中代码量增大最多的一次,主要做了如下工作
-
解析方法的增加和细化,但基本上没有改变原有的解析方法
-
预解析方法的增加和细化
-
逻辑结构增加替换方法的实现和三角函数节点,幂函数节点额外保存变量种类的信息
-
运算结构是本次改变最大的方面,修改了类的命名,对于原有的BaseItem类(现在为BaseUnit)类,增添了属性和方法。增加了幂函数、常数和三角函数类
第三次构建基本上没有变化,简单调整了运算结构,将sin和cos中的部分属性和方法提升至TriFunc,提取共有方法为calcJudge类,改变了sin和cos保存的属性类型,为Unit实现了排序接口
迭代体会
三层处理的架构实际上导致迭代时更多的增添新方法而非修改旧方法,尽管第二次相比第一次代码量基本上翻倍,但其实并不痛苦,第三次基本上完全是简单的修改。因此给我体验最深的就是第一次作业向第二次作业的迭代
在第二次作业时,最初选择的是字符串替换的思路并完成了第一版(基本无Bug),然而考虑到字符串替换的可靠性实在是不怎么可靠,此时又考虑到虽然运算结构实现替换十分痛苦(几层的嵌套容器遍历判断,因子需要保存变量类型等等),但逻辑结构由于其树的形式,替换难度至多为二叉树节点的更新,最终产生了第二版,而且,逻辑结构和运算结构的分离还使得第二版仅需修改逻辑结构的方法(运算结构的修改已经在第一版中完成了!
自我架构评价
无论是互测时看到的别人的代码,还是直接看到的朋友的代码,我的代码量无疑都是最为庞大的,尤其是类的数量和方法的数量可谓是冠绝群雄,但是,我仍然对我的架构相当满意(就是写uml图和度量分析时累的吐血)。庞大但不臃肿,精细但足够安全这便是我对自己架构的感想,从上面的分析可以看出,我对于功能的划分相当细,类中的方法也要实现分层处理,分组编写,严格要求也使得每个方法和类的编写目的和要求也是足够清晰,无论是迭代的增删、代码逻辑的复查、Bug的修改都十分清楚。而这种严密的感觉也是最令我着迷的。
第五部分
-
良好的架构始终是重中之重,我的架构自认为不算完美,代码量的庞大注定这个架构不够优雅,不够高效,但是足够的安全,也有相当的可扩展性,而这我自认为是最为重要的;
-
心得体会
从第一次作业的完成到不断迭代,尽管摆脱了理论上迭代,实质上重构的危险,一路上实质上也是颇为坎坷。相比于代码的编写我觉得更是思维的转变和心态的纠结
-
简洁与可靠的冲突——越简洁显然越可靠,然而可靠性的实现也意味着必须放弃很大一部分的简洁性,如避免类的修改选择生成新类导致大量构造方法必须构建,私有属性导致大量get方法的出现等等
-
性能与可靠的冲突——这是本次作业最让我纠结的一点,修改时新类的生成,容器中元素的修改为了安全必须先删除再插入等等,这些都让我在构造架构时极为的犹豫和纠结。可以说,每敲出一个方法的都是在妥协(最终底线——至少插入和合并同类项时得用二分,O(n^2)的复杂度实在受不了。。。)
-
”面向对象强迫症“——面向对象的思想实质上我并非首次接触,无论是之前自学C++和上学期的Java课,面向对象已经运用在了我的代码编写中了——比如上学期CO的评测机,但是,这也导致了我的强迫症,但凡有一个能提取的方法和公共属性,我一定要提取出一个父类
优缺点分析
第一次作业较为简单,因此结构构建也较为容易,优缺点均不突出
缺点
-
软件包分类不明,默认软件包中包含有大量未分类的类,而唯一的node软件包实际应该划分为逻辑结构和运算结构
-
运行时性能不高,采取先解析为逻辑结构,再解析为运算结构,面对连续加减时将导致表达式树深度过深
优点
-
结构分明,两重结构将功能进行分离,减少了Bug出现机会
-
