


kafka消息格式演变
主要基于下面博文进行学习与验证
一文看懂kafka消息格式演变
概述
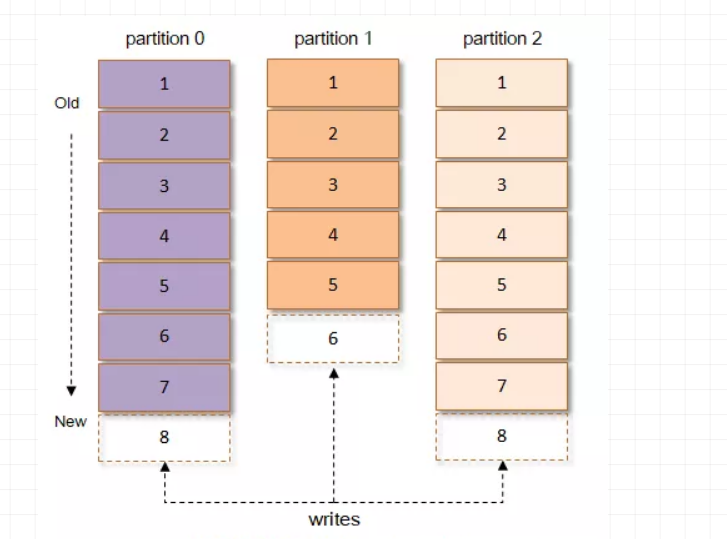
Kafka根据topic(主题)对消息进行分类,发布到Kafka集群的每条消息都需要指定一个topic,每个topic将被分为多个partition(分区)。每个partition在存储层面是追加log(日志)文件,任何发布到此partition的消息都会被追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型的数值,它唯一标记一条消息。
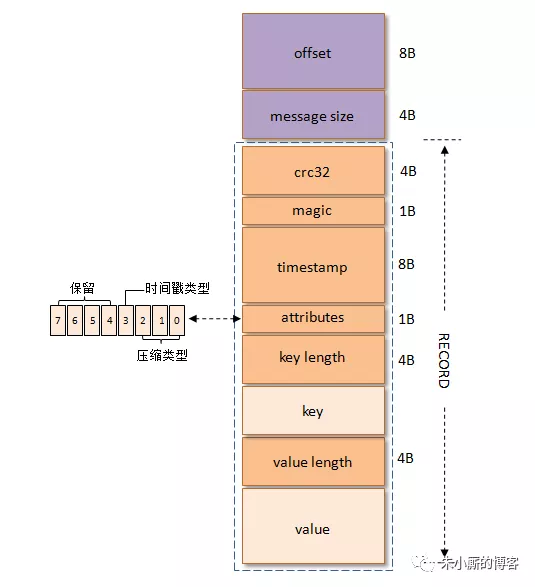
1、v0版消息格式(kafka 0.10之前的版本)

crc32(4B):crc32校验值。校验范围为magic至value之间。
magic(1B):消息格式版本号,此版本的magic值为0。
attributes(1B):消息的属性。总共占1个字节,低3位表示压缩类型:0表示NONE、1表示GZIP、2表示SNAPPY、3表示LZ4(LZ4自Kafka 0.9.x引入),其余位保留。
key length(4B):表示消息的key的长度。如果为-1,则表示没有设置key,即key=null。
key:可选,如果没有key则无此字段。
value length(4B):实际消息体的长度。如果为-1,则表示消息为空。
value:消息体。可以为空,比如tomnstone消息。
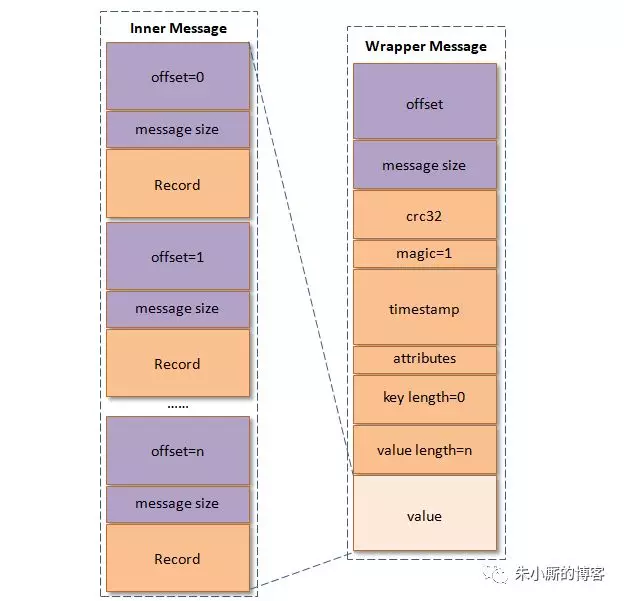
2、v1版本(从0.10.0版本开始到0.11.0版本之前的版本)
v1版本比v0版本多一个8B的timestamp字段;
timestamp字段作用:
内部而言:影响日志保存、切分策略;
外部而言:影响消息审计、端到端延迟等功能的扩展
2.1 消息压缩
常见的压缩算法是数据量越大压缩效果越好,一条消息通常不会太大,这就导致压缩效果并不太好。而kafka实现的压缩方式是将多条消息一起进行压缩,这样可以保证较好的压缩效果。而且在一般情况下,生产者发送的压缩数据在kafka broker中也是保持压缩状态进行存储,消费者从服务端获取也是压缩的消息,消费者在处理消息之前才会解压消息,这样保持了端到端的压缩。
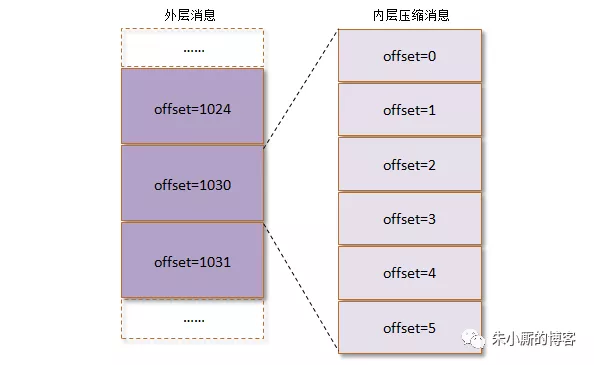
3、v2版本(0.11.0版本及之后的版本)
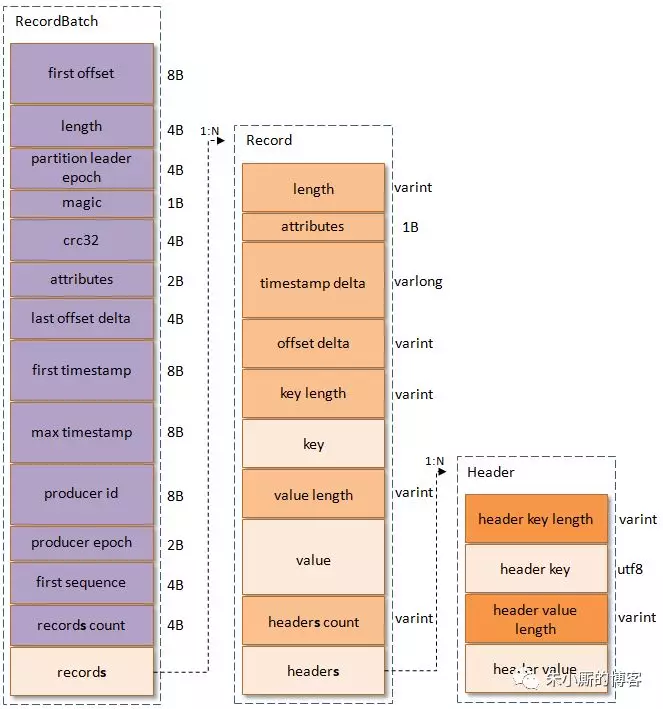
相对v0和v1改动较大,引入了变长整形Varints和ZigZag编码。
Varints作用:根据数值的大小,调整占用的字节数,数值越小,占用的字节数就越小
0-63之间的数字占1个字节,64-8191之间的数字占2个字节,8192-1048575之间的数字占3个字节
kafka broker的配置message.max.bytes的默认大小为1000012(Varints编码占3个字节)
ZigZag编码:使绝对值较小的负数仍然享有较小的Varints编码值
V2版本消息集称为Record Batch(v0和v1称为Message Set),相较于V0、V1版本
(1)将多个消息(Record)打包存放到单个RecordBatch中,v2版本的单个Record Batch Header相较于v0、v1版本的多个Log_OVERHEAD(每个Record都会有1个LOG_OVERHEARD),会节省空间;
(2)引入变长整形Varints和ZigZag编码,能够灵活的节省空间
附录
1、日志消息格式验证
(1)新建一个分区为1、副本为1的topic,名称为msg_format_v0
bin/kafka-topics.sh --create --zookeeper hadoop1:2181,hadoop2:2181,hadoop3:2181 --replication-factor 1 --partitions 1 --topic msg_format_v0
(2)向topic中写入key="key", value="value"消息
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class TestProducer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "hadoop1:9092,hadoop2:9092,hadoop3:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<>("msg_format_v0", "key", "value"));
producer.close();
}
}
pom依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<!-- 根据测试的kafka版本,需用不同版本的依赖 -->
<version>0.8.2.1</version>
</dependency>
(3)日志消息大小预期与验证
预期
TotalSzie = LOG_OVERHEAD + RECORD_OVERHEAD_V0 + 3B的key + 5B的value = 12B + 14B + 3B + 5B = 34B
验证
root@hadoop2 kafka_2.10-0.8.2.1]# bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files /data/kafka-logs/msg_format_v0-0/00000000000000000000.log
Dumping /data/kafka-logs/msg_format_v0-0/00000000000000000000.log
Starting offset: 0
offset: 0 position: 0 isvalid: true payloadsize: 5 magic: 0 compresscodec: NoCompressionCodec crc: 592888119 keysize: 3

(4)向topic中写入key=null, value="value"消息
Producer<Object, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<>("msg_format_v0", "value"));
(5)日志消息大小预期与验证
预期
TotalSize = pre_size + LOG_OVERHEAD + RECORD_OVERHEAD_V0 + 0B的key + 5B的value = 34 + 12 + 14 + 5 = 65B
验证
[root@hadoop2 kafka_2.10-0.8.2.1]# bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files /data/kafka-logs/msg_format_v0-0/00000000000000000000.log
Dumping /data/kafka-logs/msg_format_v0-0/00000000000000000000.log
Starting offset: 0
offset: 0 position: 0 isvalid: true payloadsize: 5 magic: 0 compresscodec: NoCompressionCodec crc: 592888119 keysize: 3
offset: 1 position: 34 isvalid: true payloadsize: 5 magic: 0 compresscodec: NoCompressionCodec crc: 2898297856


