


Python爬取百度贴吧图片
一、获取URL
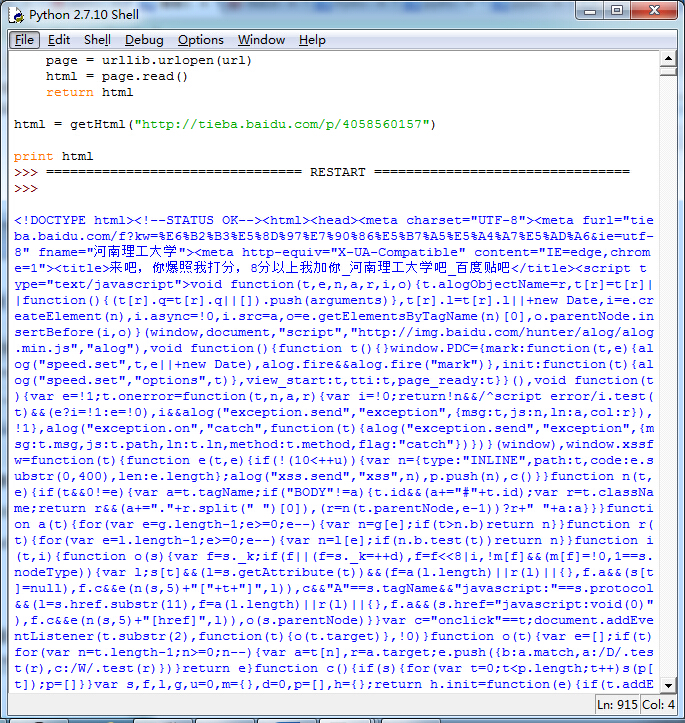
Urllib 模块提供了读取web页面数据的接口,我们可以像读取本地文件一样读取www和ftp上的数据。首先,我们定义了一个getHtml()函数:
urllib.urlopen()方法用于打开一个URL地址。
read()方法用于读取URL上的数据,向getHtml()函数传递一个网址,并把整个页面下载下来。执行程序就会把整个网页打印输出。
二、查看图片地址
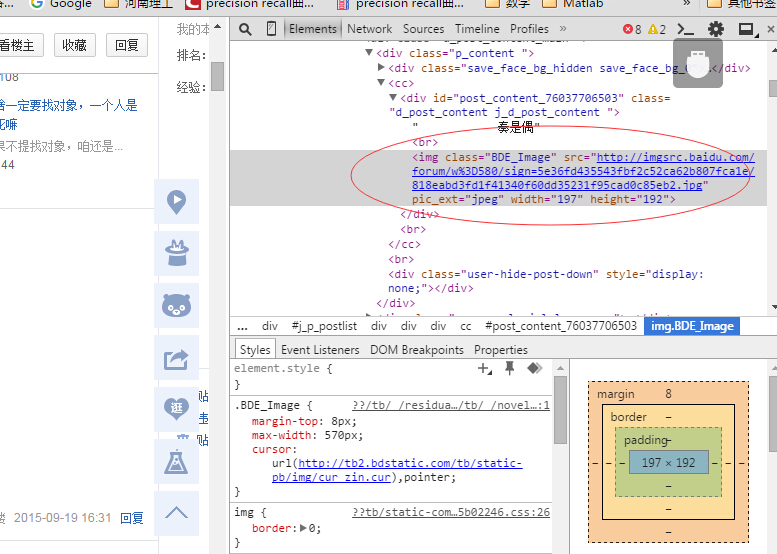
我们又创建了getImg()函数,用于在获取的整个页面中筛选需要的图片连接。re模块主要包含了正则表达式:
re.compile() 可以把正则表达式编译成一个正则表达式对象.
re.findall() 方法读取html 中包含 imgre(正则表达式)的数据。
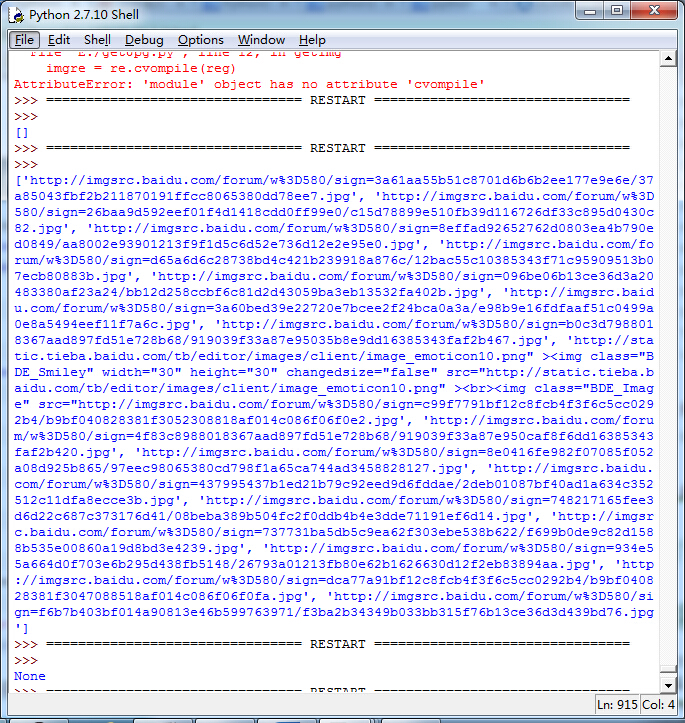
运行脚本将得到整个页面中包含图片的URL地址。
下面是图片url。
三、保存数据到本地
import urllib
import re
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
# 原来 pic-ext前面少了个空格打印出来 []
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%d.jpg' %x)
x+=1
html = getHtml("http://tieba.baidu.com/p/4058560157")
print getImg(html)
保存的图片在该py文件的桶一目录,如何设置其他保存路径呢,在urlretrieve的最后%x那设置,然后,我不知道怎么设置。
作者:火星十一郎
本文版权归作者火星十一郎所有,欢迎转载和商用,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利.

