

监控方法论
监控方法论-Google的4个黄金指标
Google 的四个黄金指标着眼点在服务监控,这四个指标分别是延迟、流量、错误和饱和度。
-
延迟:服务请求所花费的时间,比如用户获取商品列表页面调用的某个接口,花费30毫秒。这个指标需要区分成功请求和失败请求,因为失败的请求可能会立刻返回,延迟很小,会扰乱正常的请求延迟数据。
-
流量:HTTP 服务的话就是每秒 HTTP 请求数,RPC 服务的话就是每秒RPCCall 的数量,如果是数据库,可能用数据库系统的事务量来作为流量指标。
-
错误:请求失败的速率,即每秒有多少请求失败,比如 HTTP 请求返回了500 错误码,说明这个请求是失败的,或者虽然返回的状态码是 200,但是返回的内容不符合预期,也认为是请求失败。
-
饱和度:描述应用程序有多“满”,或者描述受限的资源,比如 CPU 密集型应用,CPU 使用率就可以作为饱和度指标
监控方法论-USE方法
USE 方法的提出者是大名鼎鼎的 Brendan Gregg
USE 是使用率(Utilization)、饱和度(Saturation)、错误(Error)的缩写,主要用于分析资源问题。什么是资源?在 Gregg 对模型的定义中,是指传统意义上的物理服务器组件,比如 CPU、硬盘等,但现在很多人已经扩展了资源的范围,把一些软件资源也包含在内。下面我们对使用率、饱和度、错误做一个更详细的解释。
- 使用率:这个我们最熟悉,比如内存使用率、CPU 使用率等,是一个百分比。
- 饱和度:资源排队工作的指标,无法再处理额外的工作。通常用队列长度表示,比如在 iostat 里看到的 aqu-sz 就是队列长度。
- 错误:资源错误事件的计数。比如 malloc() 失败次数、通过 ifconfig 看到的errors、dropped 包量。有很多错误是以系统错误日志的方式暴露的,没法直接拿到某个统计指标,此时可以进行日志关键字监控。
MySQL监控
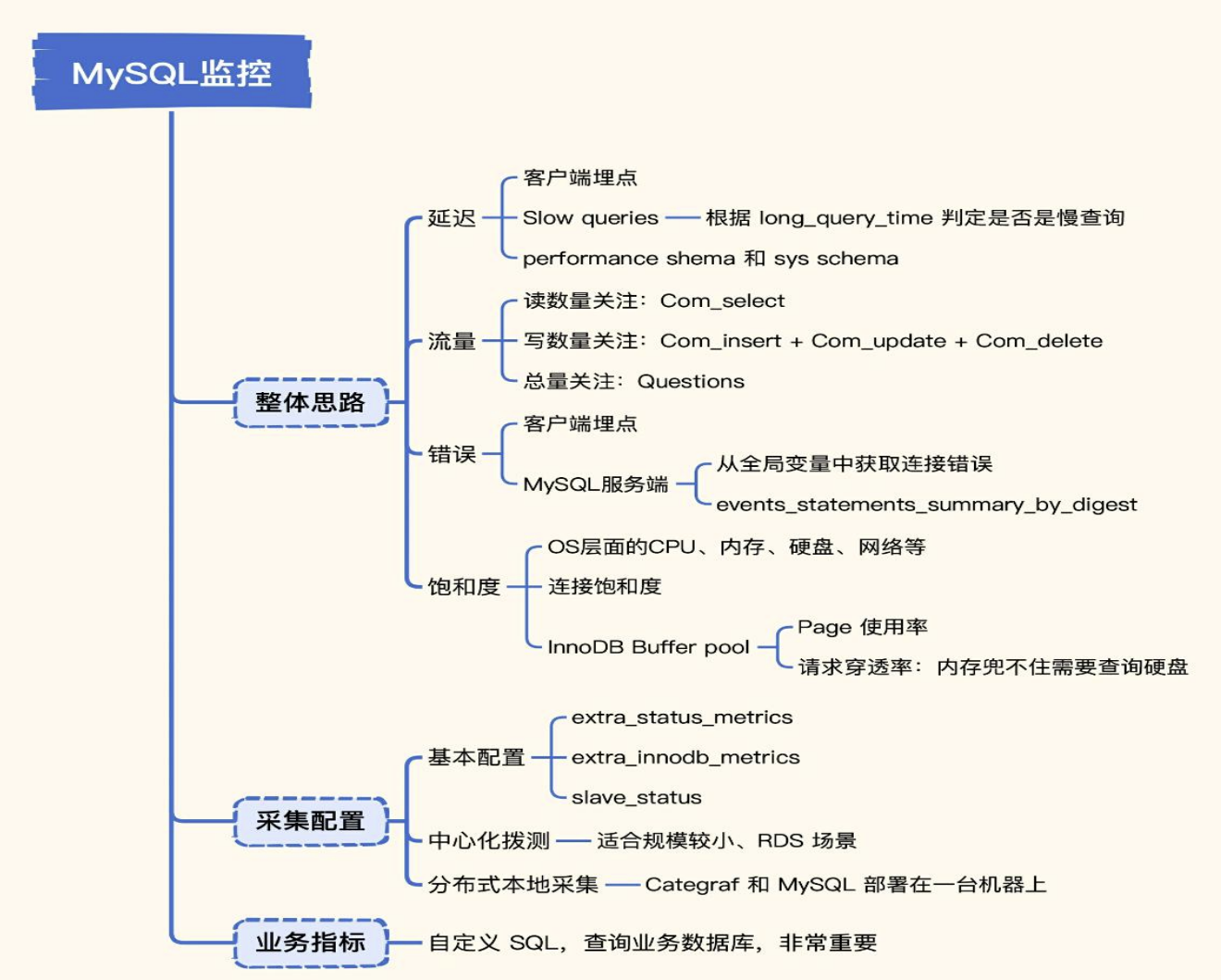
• 延迟
应用程序会向 MySQL 发起 SELECT、UPDATE 等操作,处理这些请求花费了多久,是非常关键的,甚至我们还想知道具体是哪个 SQL 最慢,这样就可以有针对性地调优。我们应该如何采集这些延迟数据呢?典型的方法有三种;
-
在客户端埋点。即上层业务程序在请求 MySQL 的时候,记录一下每个 SQL 的请求耗时,把这些数据统一推给监控系统,监控系统就可以计算出平均延迟、95 分位、99 分位的延迟数据了。不过因为要埋点,对业务代码有一定侵入性。
-
Slow queries。MySQL 提供了慢查询数量的统计指标,通过下面这段命令就可以拿到。 show global status like 'Slow_queries';
-
通过 performance schema 和 sys schema 拿到统计数据。比如 performance schema 的events_statements_summary_by_digest 表,这个表捕获了很多关键信息,比如延迟、错误量、查询量。我们看下面的例子,SQL 执行了 2 次,平均执行时间是 325 毫秒,表里的时间度量指标都是以皮秒
为单位。针对即时查询、诊断问题的场景,我们还可以使用 sys schema,sys schema 提供了一种组织良好、人类易读的指标查询方式,查询起来更简单。比如我们可以用下面的方法找到最慢的 SQL。这个数据在statements_with_runtimes_in_95th_percentile 表中。
SELECT * FROM sys.statements_with_runtimes_in_95th_percentile;
• 流量
关于流量,我们最耳熟能详的是统计 SELECT、UPDATE、DELETE、INSERT 等语句执行的数量。如果流量太高,超过了硬件承载能力,显然是需要监控、需要扩容的。这些类型的指标在 MySQL 的全局变量中都可以拿到。我们来看下面这个例子。
整体吞吐量主要是看 Questions 指标,但 Questions 很容易和它上面的 Queries 混淆。从例子里我们可以明显看出Questions 的数量比 Queries 少。Questions 表示客户端发给 MySQL 的语句数量,而 Queries 还会包含在存储过程中执行的语句,以及 PREPARE 这种准备语句,所以监控整体吞吐一般是看 Questions。流量方面的指标,一般我们会统计写数量(Com_insert + Com_update + Com_delete)、读数量(Com_select)、语句总量(Questions)。
• 错误
错误量这类指标有多个应用场景,比如客户端连接 MySQL 失败了,或者语句发给 MySQL,执行的时候失败了,都需要有失败计数。典型的采集手段有两种。
-
在客户端采集、埋点,不管是 MySQL 的问题还是网络的问题,亦或者中间负载均衡的问题或 DNS 解析的问题,只要连接失败了,都可以发现。缺点刚刚我们也介绍了,就是会有代码侵入性。
-
从 MySQL 中采集相关错误,比如连接错误可以通过 Aborted_connects 和 Connection_errors_max_connections 拿到。
show global status where Variable_name regexp 'Connection_errors_max_connections|Aborted_connects';
• 饱和度
对于 MySQL 而言,用什么指标来反映资源有多“满”呢?首先我们要关注 MySQL 所在机器的 CPU、内存、硬盘 I/O 、网络流量这些基础指标。
MySQL 本身也有一些指标来反映饱和度,比如刚才我们讲到的连接数,当前连接数(Threads_connected)除以最大连接数(max_connections)可以得到连接数使用率,是一个需要重点监控的饱和度指标。另外就是 InnoDB Buffer pool 相关的指标,一个是 Buffer pool 的使用率,一个是 Buffer pool 的内存命中率。Buffer pool 是一块内存,专门用来缓存 Table、Index 相关的数据,提升查询性能。对 InnoDB 存储引擎而言,Buffer pool 是一个非常关键的设计。我们查看一下 Buffer pool 相关的指标。
这里有 4 个指标我重点讲一下。
- Innodb_buffer_pool_pages_total 表示 InnoDB Buffer pool 的页总量,页(page)是 Buffer pool 的一个分配单位,默认的 page size 是 16KiB,可以通过 show variables like "innodb_page_size" 拿到。
- Innodb_buffer_pool_pages_free 是剩余页数量,通过 total 和 free 可以计算出 used,用 used 除以 total 就可以得到使用率。当然,使用率高并不是说有问题,因为 InnoDB 有 LRU 缓存清理机制,只要响应得够快,高使用率也不是问题
- Innodb_buffer_pool_read_requests 和 Innodb_buffer_pool_reads 是另外两个关键指标。read_requests 表示向 Buffer pool 发起的查询总量,如果 Buffer pool 缓存了相关数据直接返回就好,如果 Buffer pool 没有相关数据,就要穿透内存去查询硬盘了。有多少请求满足不了需要去查询硬盘呢?这就要看 Innodb_buffer_pool_reads 指标统计的数量。所以,reads 这个指标除以 read_requests 就得到了穿透比例,这个比例越高,性能越差,一般可以通过调整 Buffer pool 的大小来解决。
Redis监控
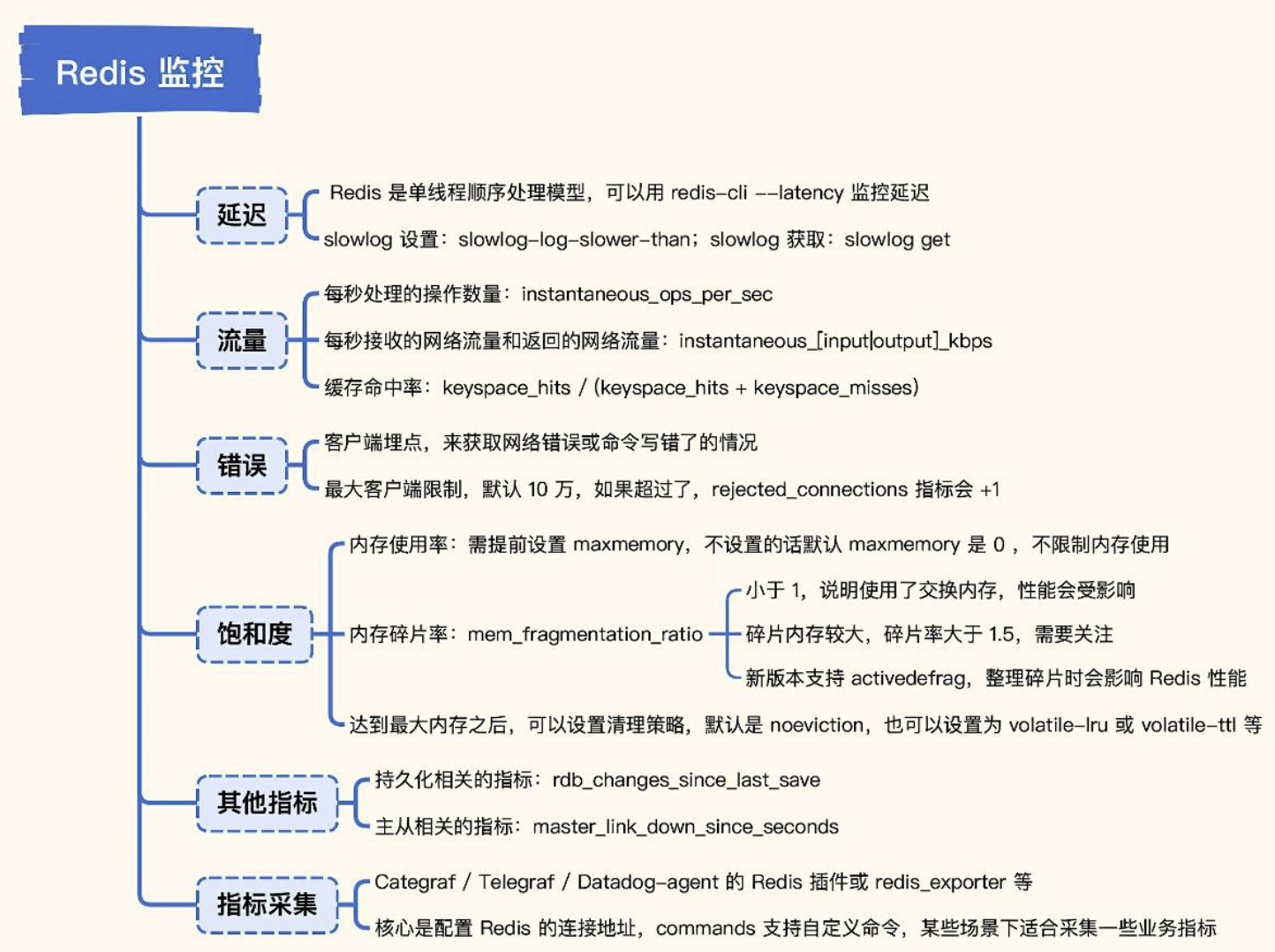
• 延迟
在软件工程架构中,之所以选择 Redis 作为技术堆栈的一员,大概率是想要得到更快的响应速度和更高的吞吐量,所以延迟数据对使用 Redis 的应用程序至关重要。通常我们会通过下面这两种方式来监控延迟。
-
客户端应用程序埋点。比如某个 Java 或 Go 的程序在调用 Redis 的时候,计算一下各个命令花费了多久,然后把耗时数据推给监控系统即可。这种方式好处是非常灵活,想要按照什么维度统计就按照什么维度统计,缺点自然是代码侵入性,和客户端埋点监控 MySQL 的原理是一样的。
-
使用 redis-cli 的 --latency 命令,这个原理比较简单,就是客户端连上 redis-server,然后不断发送 ping 命令,统计耗时。我在远端机器对某个 redis-server 做探测,你可以看一下探测的结果。
如果我们发现 Redis 变慢了,应该怎么找到那些执行得很慢的命令呢?这就要求助于 slowlog 了。
• 流量
Redis 每秒处理多少请求,每秒接收多少字节、返回多少字节,在 Redis 里都内置了相关指标,通过redis-cli 连上 Redis,执行 info all 命令可以看到很多指标,绝大部分监控系统,都是从 info 命令的返回内容中提取的指标。ops_per_sec 表示每秒执行多少次操作,input_kbps 表示每秒接收多少 KiB,output_kbps 表示每秒返回多少 KiB。如果把 Redis 当做缓存来使用,我们还需关注 keyspace_hits 和 keyspace_misses 两个指标。
• 错误
Redis 在响应客户端请求时,通常不会有什么内部错误产生,毕竟只是操作内存,依赖比较少,出问题的概率就很小了。如果客户端操作 Redis 返回了错误,大概率是网络问题或命令写错了导致的。最好是做客户端埋点监控,自己发现了然后自己去解决。
Redis 对客户端的数量也有一个最大数值的限制,默认是 10 万,如果超过了这个数量,rejected_connections 指标就会 +1。和 MySQL 不一样的是,Redis 使用过程中,应该很少遇到超过最大连接数(maxclients) 的情况,不过谨慎起见,也可以对 rejected_connections 做一下监控。
• 饱和度
Redis 重度使用内存,内存的使用率、碎片率,以及因为内存不够用而清理的 Key 数量,都是需要重点关注的。我们通过 info memory 命令查看一下这几个关键指标。
- 饱和度的度量方面,还有一个指标是 evicted_keys,表示当内存占用超过了 maxmemory 的时候,Redis清理的 Key 的数量。实际上,内存达到 maxmemory 的时候,具体是怎么一个处理策略,是可以配置的,默认的策略是 noeviction。
- 其他常见策略有:volatile-lru,表示从已设置过期时间的内存数据集里,挑选最近最少使用的数据淘汰掉;volatile-ttl,表示从已设置过期时间的内存数据集里,挑选即将过期的数据淘汰。
- 还有一些指标虽然短期不会影响上游服务,但是如果不及时处理未来也会出现大麻烦,这类指标通常用于衡量 Redis 内部的一些运行工况,比如:
- 持久化相关的指标:rdb_changes_since_last_save 表示自从上次落盘以来又有多少次变更。
- 主从相关的指标:master_link_down_since_seconds 表示主从连接已经断开的时长。
Kafka监控
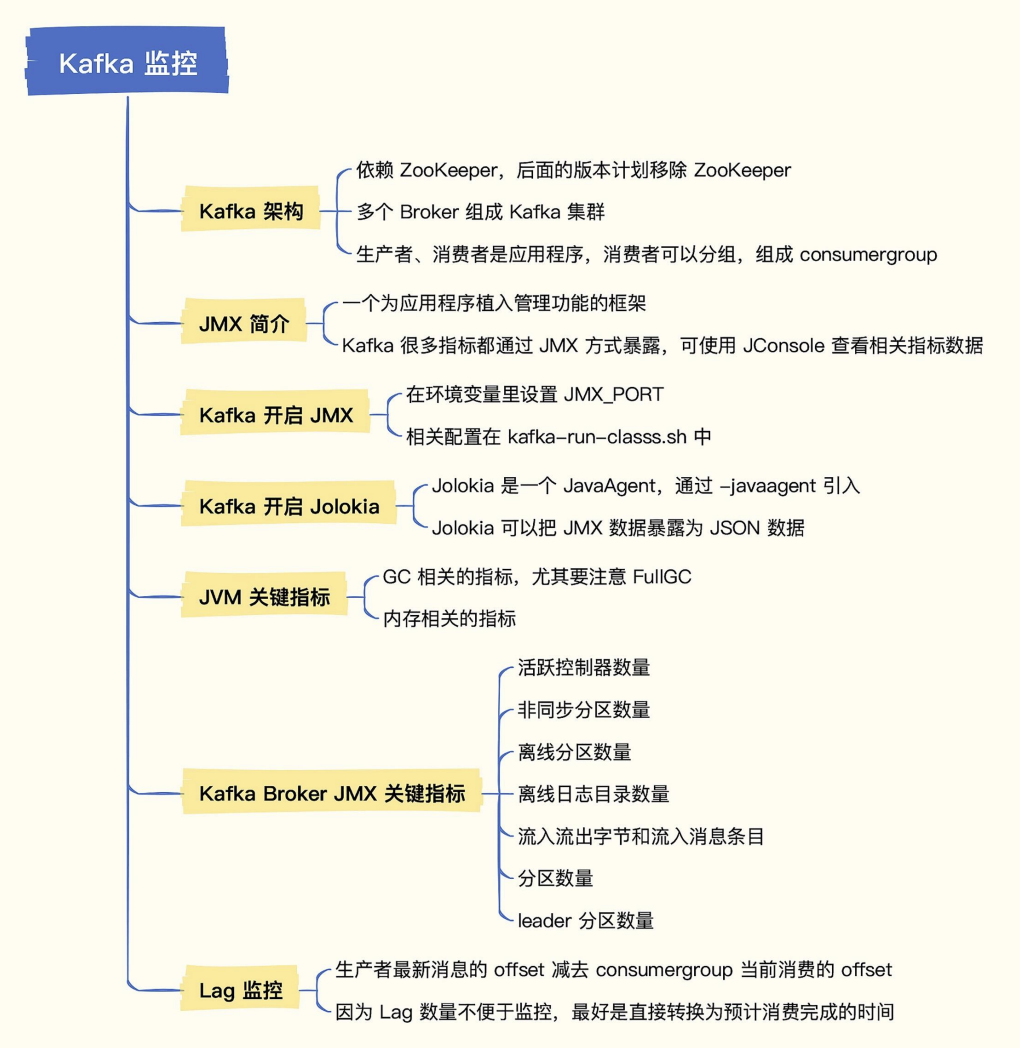
• 活跃控制器数量
- MBean:broker kafka.controller:type=KafkaController,name=ActiveControllerCount
- 一个 Kafka 集群有多个 Broker,正常来讲其中一个 Broker 会是活跃控制器,且只能有一个。从整个集群角度来看,SUM 所有 Broker 的这个指标,结果应该为 1。如果 SUM 的结果为 2,也就是说,有两个Broker 都认为自己是活跃控制器。这可能是网络分区导致的,需要重启 Kafka Broker 进程。如果重启了不好使,可能是依赖的 ZooKeeper 出现了网络分区,需要先去解决 ZooKeeper 的问题,然后重启 Broker 进程。
• 非同步分区数量
- MBean:kafka.server:type=ReplicaManager,name=UnderReplicatedPartitions
- 这个指标是对每个 Topic 的每个分区的统计,如果某个分区主从同步出现问题,对应的数值就会大于 0。常见的原因比如某个 Broker 出问题了,一般是 Kafka 进程问题或者所在机器的硬件问题,那么跟这个Broker 相关的分区就全部都有问题,这个时候出问题的分区数量大致是恒定的。如果出问题的分区数量不恒定,可能是集群性能问题导致的,需要检查硬盘 I/O、CPU 之类的指标。
• 离线分区数量
- MBean:kafka.controller:type=KafkaController,name=OfflinePartitionsCount
- 这个指标只有集群控制器才有,其他 Broker 这个指标的值是 0,表示集群里没有 leader 的分区数量。Kafka 主要靠 leader 副本提供读写能力,如果有些分区没有 leader 副本了,显然就无法读写了,是一个非常严重的问题。
• 离线日志目录数量
- MBean:kafka.log:type=LogManager,name=OfflineLogDirectoryCount
- Kafka 是把收到的消息存入 log 目录,如果 log 目录有问题,比如写满了,就会被置为 Offline,及时监控离线日志目录的数量显然非常有必要。如果这个值大于 0,我们想进一步知道具体是哪个目录出问题了,可以查询 MBean:kafka.log:type=LogManager,name=LogDirectoryOffline,logDirectory=*",LogDirectory 字段会标明具体是哪个目录。
• 流入流出字节和流入消息
- 这是典型的吞吐指标,既有 Broker 粒度的,也有 Topic 粒度的,名字都一样,Topic 粒度的指标数据MBean ObjectName 会多一个 topic=xx 的后缀。
• 流入字节
- MBean:kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec
- 这个指标 Kafka 在使用 Yammer Metrics 埋点的时候,设置为了 Meter 类型,所以 Yammer 会自动计算出Count、OneMinuteRate、FiveMinuteRate、FifteenMinuteRate、MeanRate 等指标,也就是 1 分钟、5 分钟、15 分钟内的平均流入速率,以及整体平均流入速率。而 Count 表示总量,如果时序库支持 PromQL,我们就只采集 Count,其他的不用采集,后面使用 PromQL 对 Count 值做 irate 计算即可。
• 流出字节
-
MBean:kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec
-
和 BytesInPerSec 类似,表示出向流量。不过需要注意的是,流出字节除了普通消费者的消费流量,也包含了副本同步流量。
• 流入消息
- MBean:kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec
- BytesInPerSec 和 BytesOutPerSec 都是以 byte 为单位统计的,而 MessagesInPerSec 是以消息个数为单位统计的,也是 Meter 类型,相关属性都一样。
- 需要解释一下的是,Kafka 不提供 MessagesOutPerSec,你可能觉得有点儿奇怪,有入就得有出才正常嘛。这是因为消息被拉取的时候,Broker 会把整个“消息批次”发送给消费者,并不会展开“批次”,也就没法计算具体有多少条消息了。
• 分区数量
- MBean:kafka.server:type=ReplicaManager,name=PartitionCount
- 这个指标表示某个 Broker 上面总共有多少个分区,包括 leader 分区和 follower 分区。如果多个 Broker 分区不均衡,可能会造成有些 Broker 消耗硬盘空间过快,这是需要注意的。
• leader 分区数量
- MBean:kafka.server:type=ReplicaManager,name=LeaderCount
- 这个指标表示某个 Broker 上面总共有多少个 leader 分区,leader 分区负责数据读写,承接流量,所以 leader 分区如果不均衡,会导致某些 Broker 过分繁忙而另一些 Broker 过分空闲,这种情况也是需要我们注意的。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· .NET周刊【3月第1期 2025-03-02】
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器