
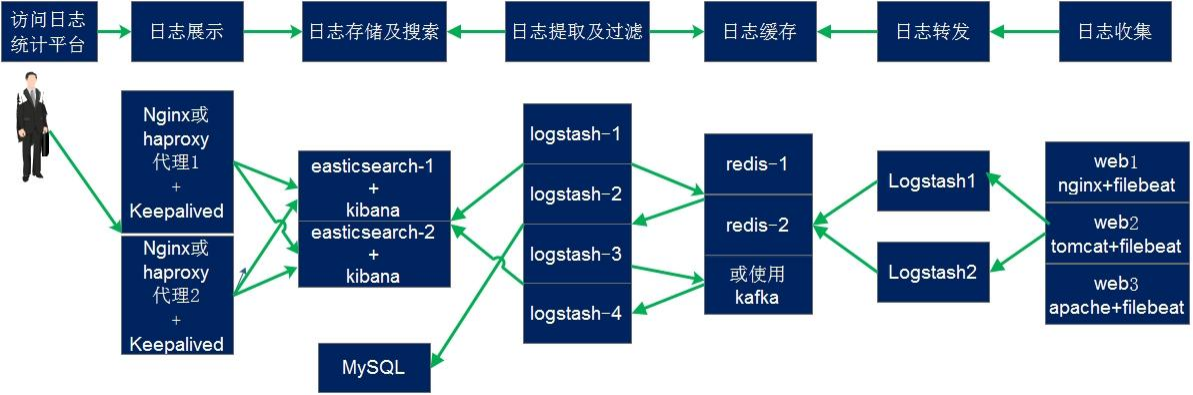
ELK平台部署
是一个高度可扩展的开源全文搜索和分析引擎,它可实现数据的实时全文搜索
搜索、支持分布式可实现高可用、提供 API 接口,可以处理大规模日志数据,比如 Nginx、Tomcat、系统日志等功能。
Elasticsearch 使用 Java 语言开发,是建立在全文搜索引擎 Apache Lucene 基础之上的搜索引擎,https://lucene.apache.org/。
Elasticsearch 的特点:
-
实时搜索、实时分析
-
分布式架构、实时文件存储
-
文档导向,所有对象都是文档
-
高可用,易扩展,支持集群,分片与复制
-
接口友好,支持 json
(1)在所有需要收集日志的服务器上部署Logstash;或者先将日志进行集中化管理在日志服务器上,在日志服务器上部署 Logstash。
(2)Logstash 收集日志,将日志格式化并输出到 Elasticsearch 群集中。
(3)Elasticsearch 对格式化后的数据进行索引和存储。
(4)Kibana 从 ES 群集中查询数据生成图表,并进行前端数据的展示。
总结:logstash作为日志搜集器,从数据源采集数据,并对数据进行过滤,格式化处理,然后交由Elasticsearch存储,kibana对日志进行可视化处理。
三、安装部署ELK
7-3 node1节点(2C/4G):node1/192.168.100.155 Elasticsearch 7-5 node2节点(2C/4G):node2/192.168.100.160 Elasticsearch 7-1 日志节点: log/192.168.100.146 Logstash Kibana
java -version #如果没有安装,yum -y install java

systemctl disable --now firewalld setenforce 0 sed -i.bak 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
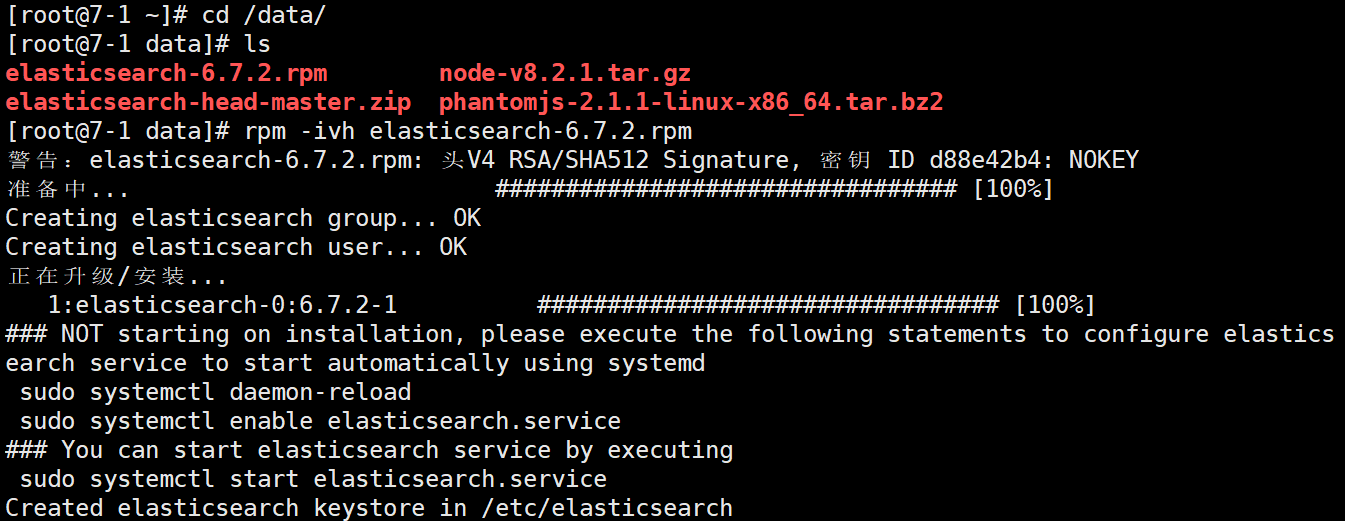
[root@localhost data]#ls elasticsearch-6.7.2.rpm elasticsearch-head-master.zip node-v8.2.1.tar.gz phantomjs-2.1.1-linux-x86_64.tar.bz2 [root@localhost data]#rpm -ivh elasticsearch-6.7.2.rpm [root@localhost data]#cd /etc/elasticsearch/ [root@localhost elasticsearch]#mkdir bak [root@localhost elasticsearch]#cp -a *.yml bak/ #备份


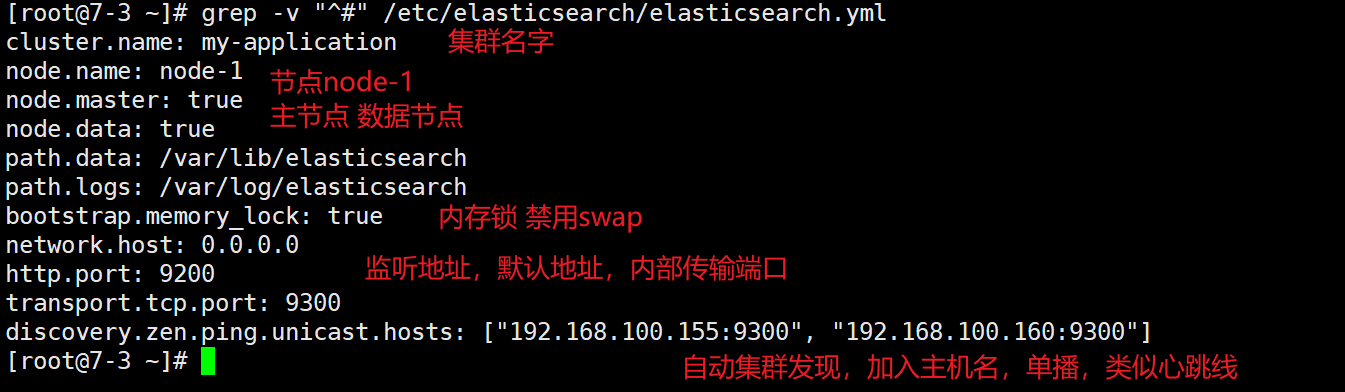
[root@node1 elasticsearch]#vim elasticsearch.yml 17 cluster.name: my-elk-cluster #修改集群名字 23 node.name: node1 24 node.master: true 25 node.data: true #设置 节点名称 主从之间不能一致 24作为主节点 25作为数据节点 45 bootstrap.memory_lock: true #内存锁开启 禁止使用 swap 57 network.host: 0.0.0.0 #监听地址 60 http.port: 9200 # 默认使用端口 61 transport.tcp.port: 9300 #内部传输端口 73 discovery.zen.ping.unicast.hosts: ["192.168.100.155:9300", "192.168.100.160:9300"] #自动集群发现,加入主机名 使用单播 类似心跳线
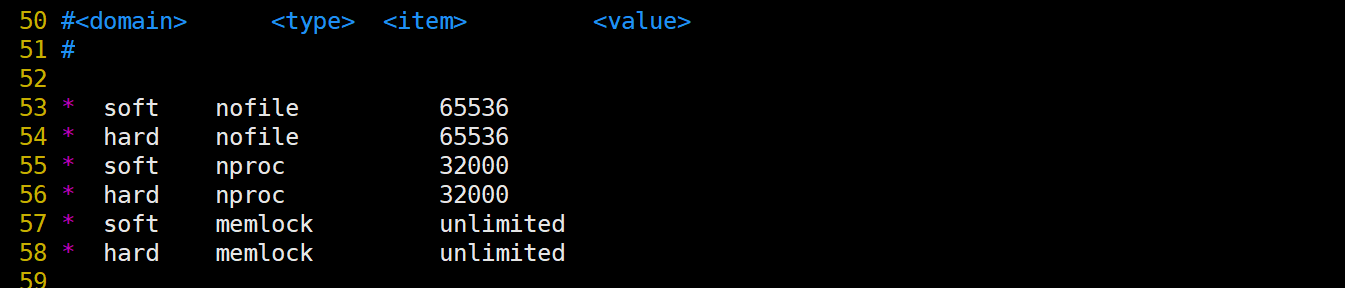
[root@localhost elasticsearch]#vim /etc/security/limits.conf ...... * soft nofile 65536 * hard nofile 65536 * soft nproc 32000 * hard nproc 32000 * soft memlock unlimited * hard memlock unlimited
/etc/systemd/system.conf 文件是用于配置 systemd 的,这是一种用于 Linux 操作系统的系统和服务管理器。通过这个文件,你可以自定义与系统操作、性能和行为相关的各种设置
-
DefaultTimeoutStartSec=:设置启动服务的默认等待时间
-
DefaultTimeoutStopSec=:设置停止服务的默认等待时间
-
DefaultRestartSec=:设置在重新启动服务之前的默认休眠时间
-
DefaultLimitNOFILE=:设置打开文件数量的默认限制
-
DefaultLimitNPROC=:设置进程数量的默认限制
-
DefaultLimitCORE=:设置核心文件大小的默认限制
-
DefaultEnvironment=:指定服务的默认环境变量
实际修改
[root@localhost elasticsearch]#vim /etc/systemd/system.conf DefaultLimitNOFILE=65536 DefaultLimitNPROC=32000 DefaultLimitMEMLOCK=infinity

Lucene 是一个高性能、全功能的文本搜索引擎库,用于实现高效的文本索引和搜索。它是用 Java 编写的,可以嵌入到各种应用程序中,以提供强大的全文搜索功能。Lucene 是许多流行搜索平台的核心,如 Apache Solr 和 Elasticsearch。
以下是 Lucene 的一些关键特性和功能:
-
文本索引:Lucene 提供了强大的文本索引功能,能够处理大规模文本数据并生成高效的索引。
-
全文搜索:支持复杂的查询语法,包括布尔查询、短语查询、通配符查询、模糊查询等。
-
可扩展性:Lucene 设计为模块化和可扩展的,允许用户根据需要扩展和定制其功能。
-
分词和分析:提供了丰富的分词器和分析器,用于将文本分解为可索引和可搜索的词语。
-
排序和评分:支持对搜索结果进行排序和评分,以提高搜索的准确性和相关性。
-
多语言支持:支持多种语言的文本处理和搜索。
优化elasticsearch用户拥有的内存权限 由于ES构建基于lucene, 而lucene设计强大之处在于lucene能够很好的利用操作系统内存来缓存索引数据,以提供快速的查询性能。lucene的索引文件segements是存储在单文件中的,并且不可变,对于OS来说,能够很友好地将索引文件保持在cache中,以便快速访问;因此,我们很有必要将一半的物理内存留给lucene ; 另一半的物理内存留给ES(JVM heap )。所以, 在ES内存设置方面,可以遵循以下原则:
-
当机器内存小于64G时,遵循通用的原则,50%给ES,50%留给操作系统,供lucene使用
-
当机器内存大于64G时,遵循原则:建议分配给ES分配 4~32G 的内存即可,其它内存留给操作系统,供lucene使用
[root@localhost elasticsearch]#vim /etc/sysctl.conf #一个进程可以拥有的最大内存映射区域数,参考数据(分配 2g/262144,4g/4194304,8g/8388608) vm.max_map_count=262144 sysctl -p sysctl -a | grep vm.max_map_count

reboot systemctl start elasticsearch.service systemctl enable elasticsearch.service netstat -antp | grep 9200
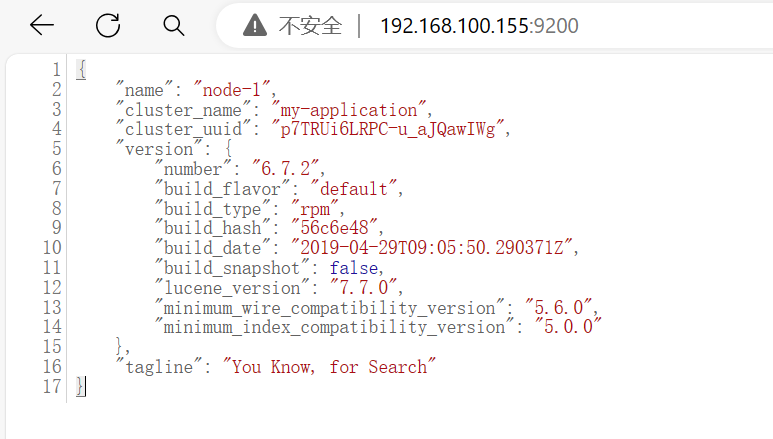
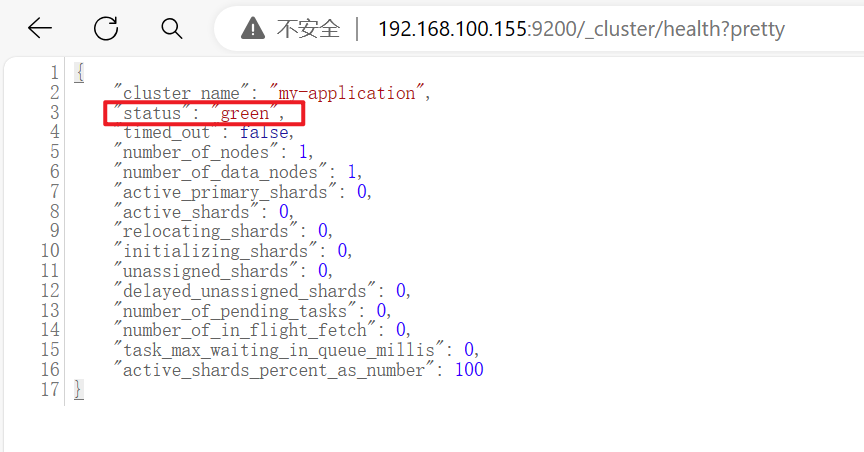
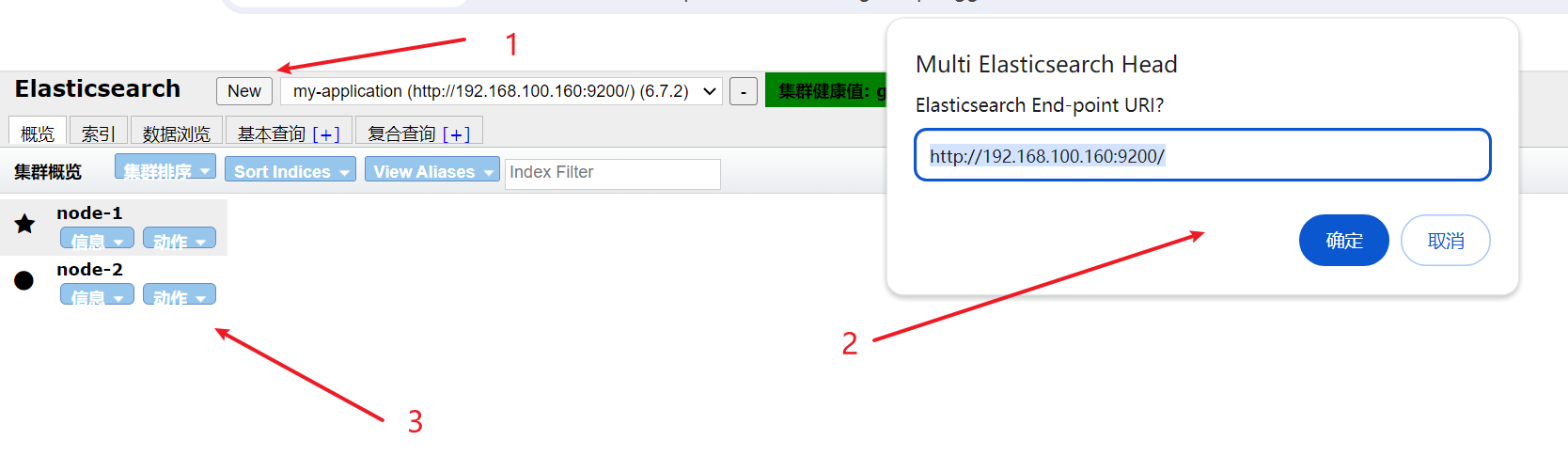
浏览器访问 http://192.168.100.155:9200 http://192.168.100.160:9200 查看节点 Node1、Node2 的信息。 浏览器访问 http://192.168.100.155:9200/_cluster/health?pretty http://192.168.100.160:9200/_cluster/health?pretty 查看群集的健康情况,可以看到 status 值为 green(绿色), 表示节点健康运行。 浏览器访问 http://192.168.100.155:9200/_cluster/state?pretty 检查群集状态信息
vim /etc/elasticsearch/elasticsearch.yml ...... --末尾添加以下内容--注意空格 http.cors.enabled: true #开启跨域访问支持,默认为 false http.cors.allow-origin: "*" #指定跨域访问允许的域名地址为所有 systemctl restart elasticsearch #重启elasticsearch 服务
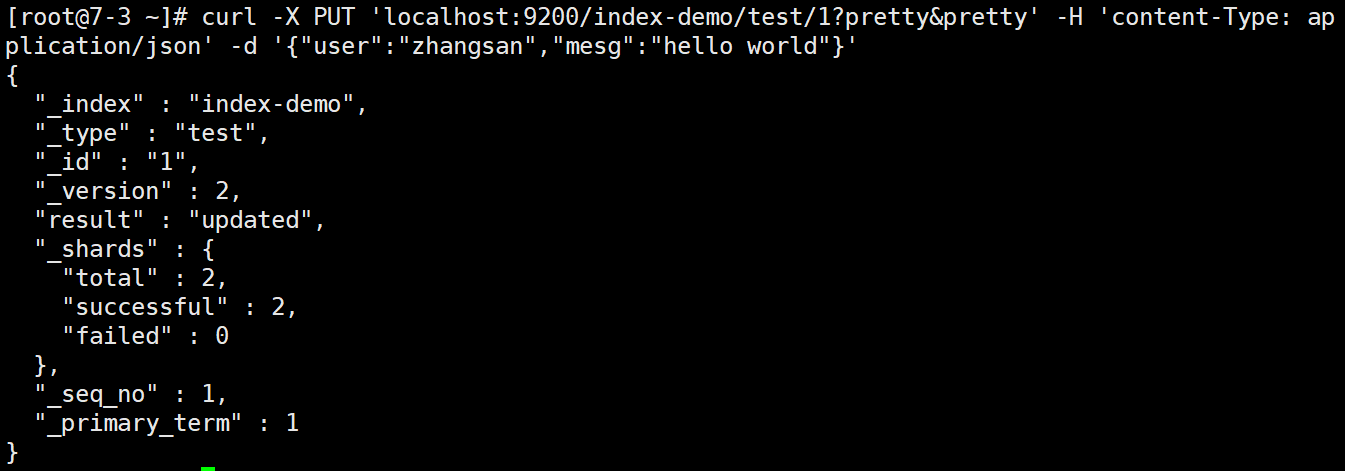
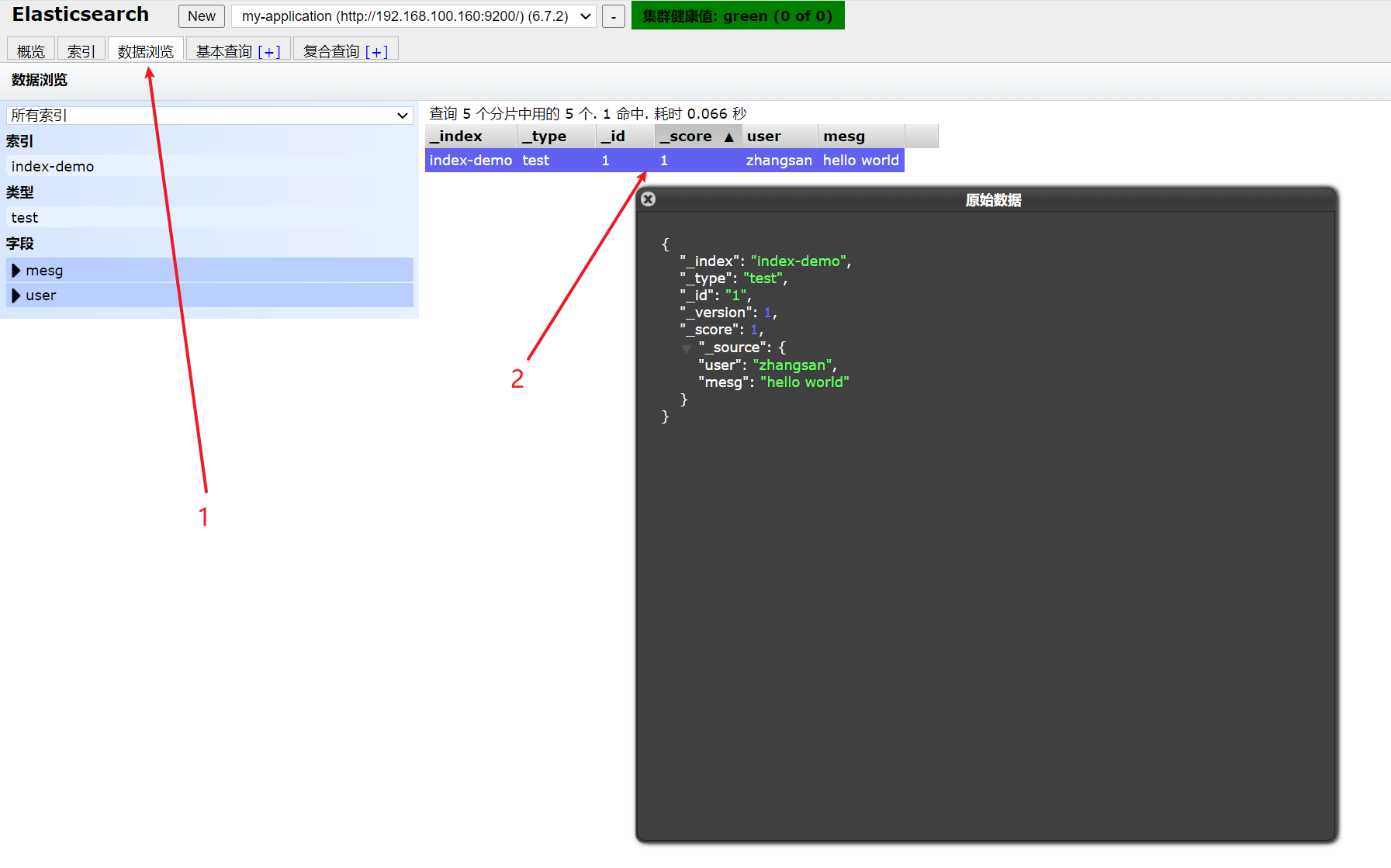
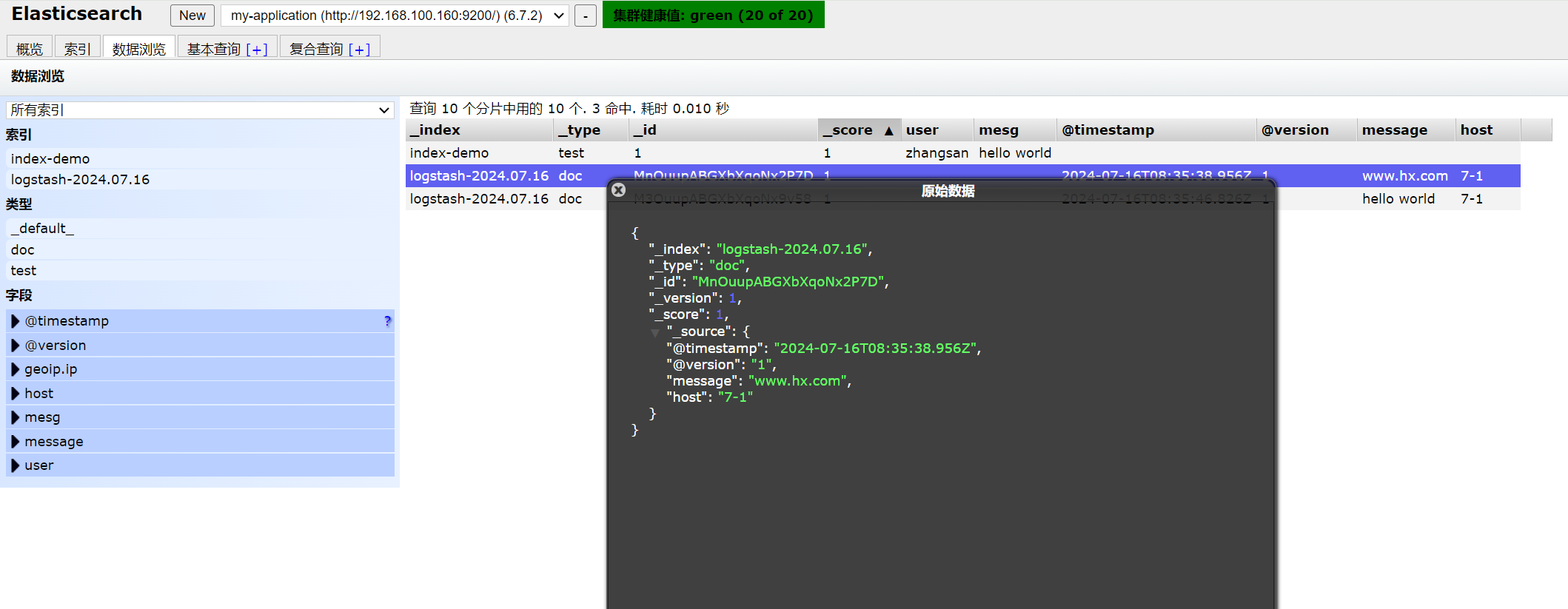
curl -X PUT 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}' -x 指定方法 -H 添加请求头 -d 请求体
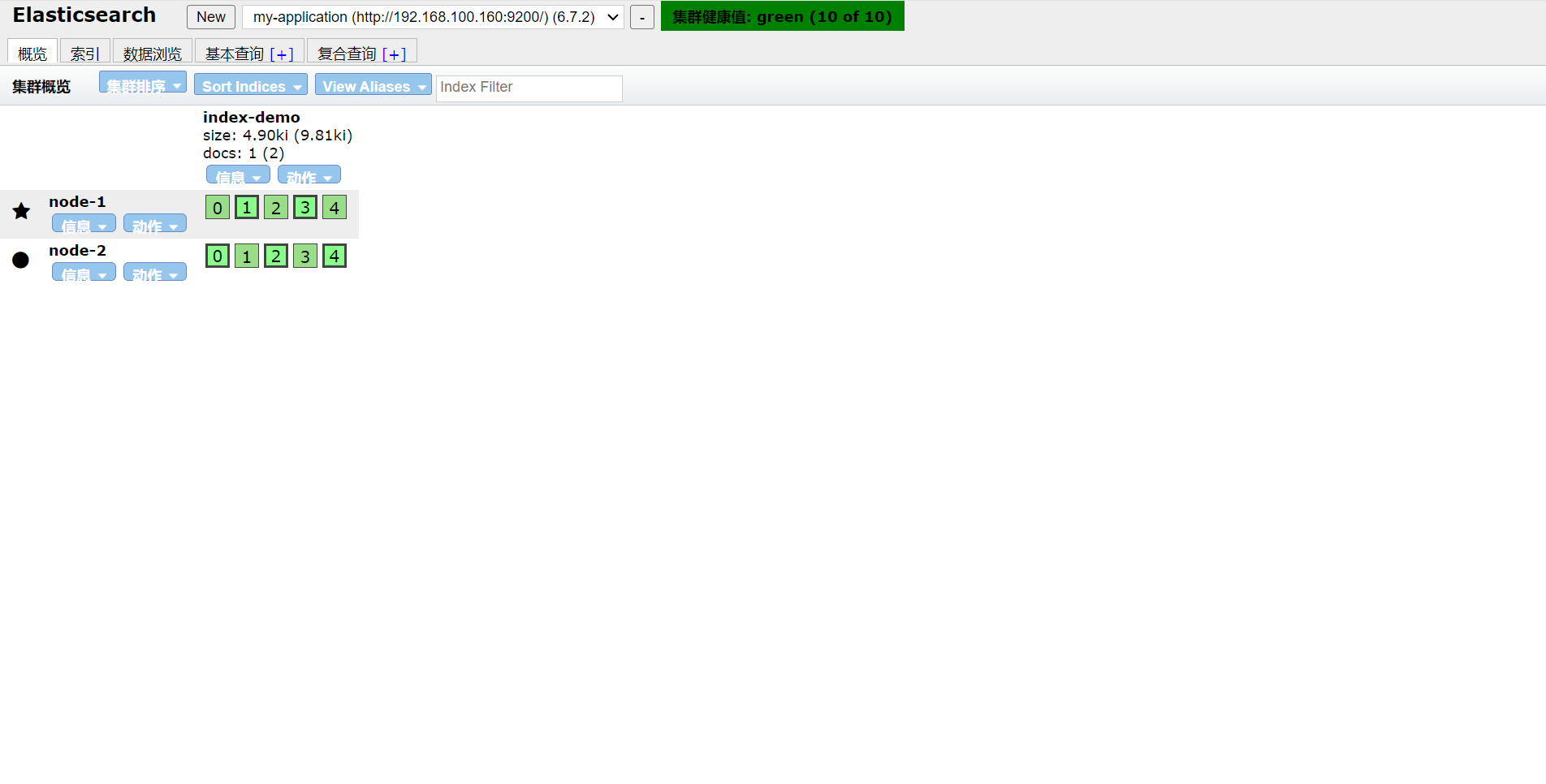
刷新页面可以看到有新的数据
#安装apache
yum -y install java java -version yum -y install httpd systemctl start httpd
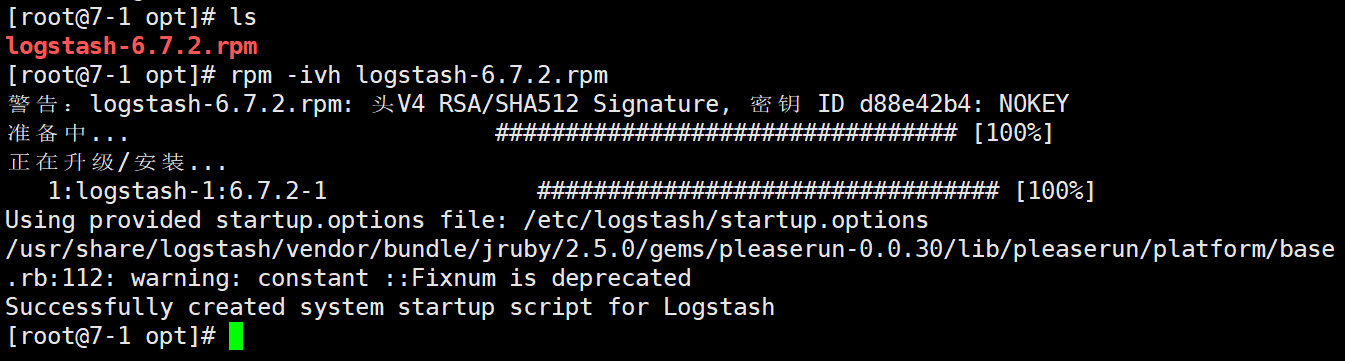
cd /opt [root@localhost opt]# rpm -ivh logstash-6.7.2.rpm #开启服务 systemctl enable --now logstash.service [root@localhost opt]# ln -s /usr/share/logstash/bin/logstash /usr/bin/ # 做软连接
Logstash 命令常用选项: -f:通过这个选项可以指定 Logstash 的配置文件,根据配置文件配置 Logstash 的输入和输出流。 -e:从命令行中获取,输入、输出后面跟着字符串,该字符串可以被当作 Logstash 的配置(如果是空,则默认使用 stdin 作为输入,stdout 作为输出)。 -t:测试配置文件是否正确,然后退出。
例子:在命令行中收集日志数据
#输入采用标准输入,输出采用标准输出(类似管道),新版本默认使用 rubydebug 格式输出
[root@localhost opt]# logstash -e 'input { stdin{} } output { stdout{} }'

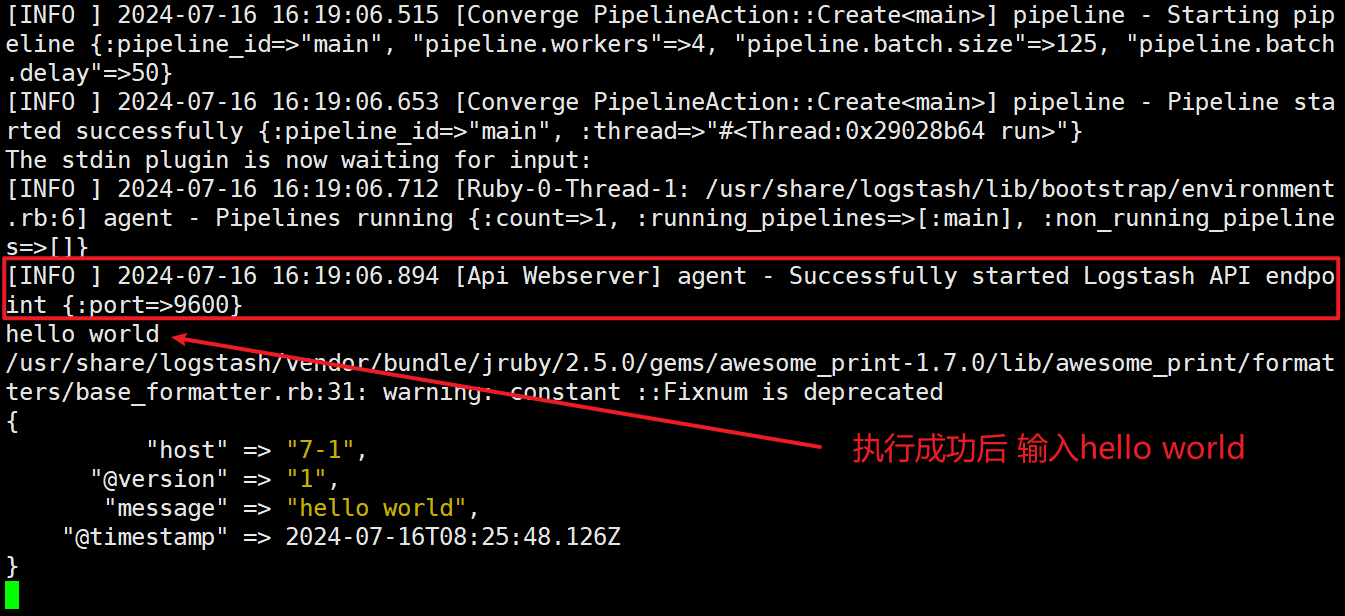
例子:#使用 rubydebug 输出详细格式显示,codec 为一种编解码器 logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug } }' 结果与上面一样
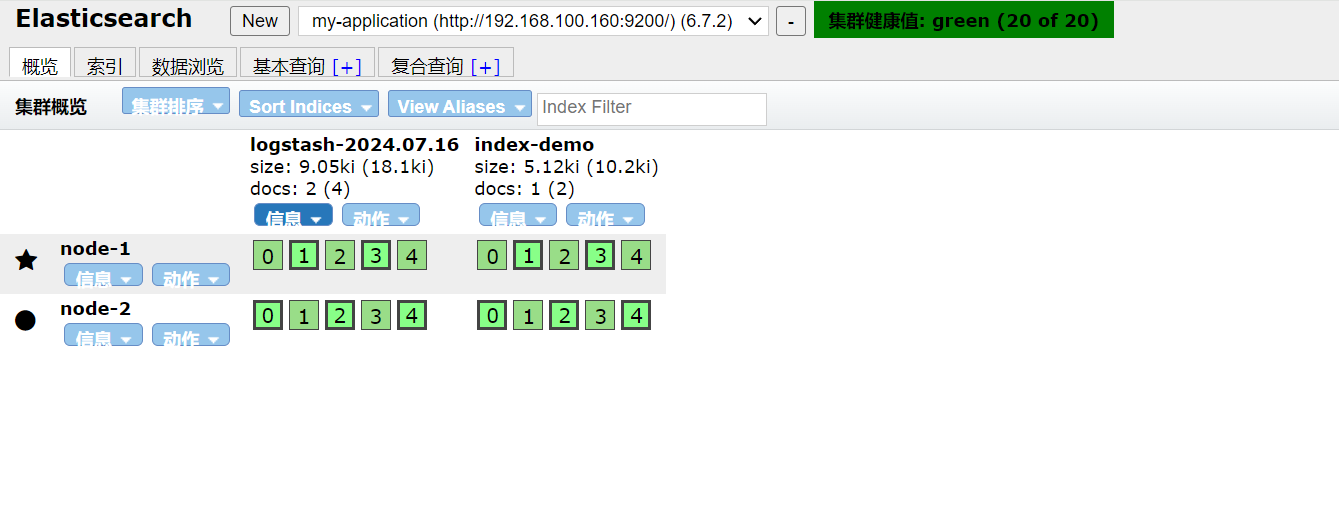
[root@localhost opt]#logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["192.168.100.155:9200","192.168.100.160:9200"]} }'
//结果不在标准输出显示,而是发送至 Elasticsearch 中,可浏览器查看索引信息和数据浏览。
# 输入信息
www.hx.com
hello world

Logstash 配置文件基本由三部分组成:input、output 以及 filter(可选,根据需要选择使用)
-
input:表示从数据源采集数据,常见的数据源如Kafka、日志文件等 file beats kafka redis stdin
-
filter:表示数据处理层,包括对数据进行格式化处理、数据类型转换、数据过滤等,支持正则表达式 grok 对若干个大文本字段进行再分割成一些小字段 (?<字段名>正则表达式) 字段名: 正则表达式匹配到的内容 date 对数据中的时间格式进行统一和格式化 mutate 对一些无用的字段进行剔除,或增加字段 mutiline 对多行数据进行统一编排,多行合并或拆分
-
output:表示将Logstash收集的数据经由过滤器处理之后输出到Elasticsearch。 elasticsearch stdout
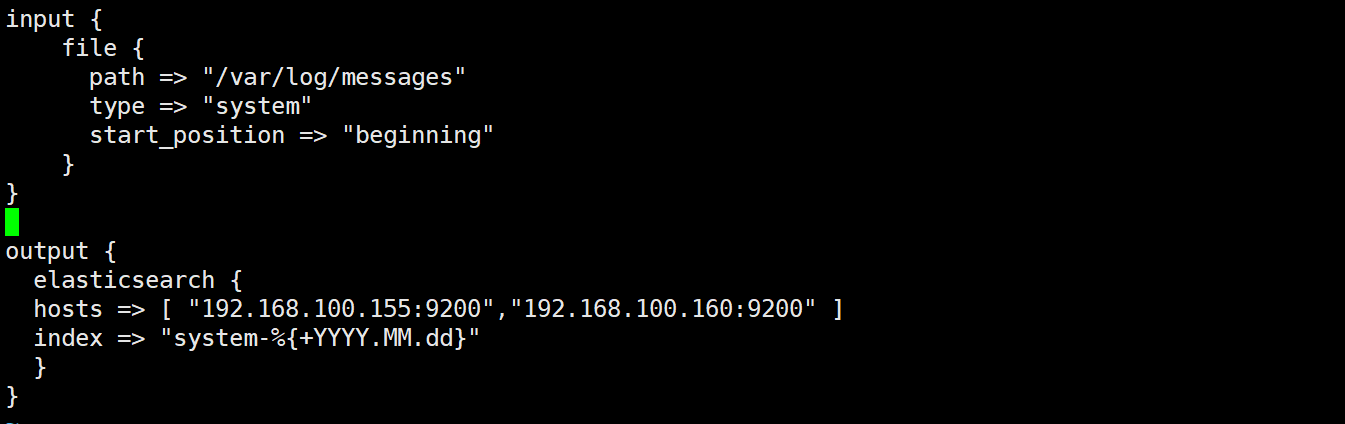
#格式如下: input {...} filter {...} output {...} #在每个部分中,也可以指定多个访问方式。例如,若要指定两个日志来源文件,则格式如下: input { file { path =>"/var/log/messages" type =>"syslog"} file { path =>"/var/log/httpd/access.log" type =>"apache"} vim system.conf input { file{ path =>"/var/log/messages" type =>"system" start_position =>"beginning" # ignore_older => 604800 sincedb_path => "/etc/logstash/sincedb_path/log_progress" add_field => {"log_hostname"=>"${HOSTNAME}"} } } #path表示要收集的日志的文件位置 #type是输入ES时给结果增加一个叫type的属性字段 #start_position可以设置为beginning或者end,beginning表示从头开始读取文件,end表示读取最新的,这个要和ignore_older一起使用 #ignore_older表示了针对多久的文件进行监控,默认一天,单位为秒,可以自己定制,比如默认只读取一天内被修改的文件 #sincedb_path表示文件读取进度的记录,每行表示一个文件,每行有两个数字,第一个表示文件的inode,第二个表示文件读取到的位置(byteoffset)。默认为$HOME/.sincedb* #add_field增加属性。这里使用了${HOSTNAME},即本机的环境变量,如果要使用本机的环境变量,那么需要在启动命令上加--alow-env output { elasticsearch { #输出到 elasticsearch hosts => ["192.168.91.100:9200","192.168.91.101:9200"] #指定 elasticsearch 服务器的地址和端口 index =>"system-%{+YYYY.MM.dd}" #指定输出到 elasticsearch 的索引格式 } }
实际例子:
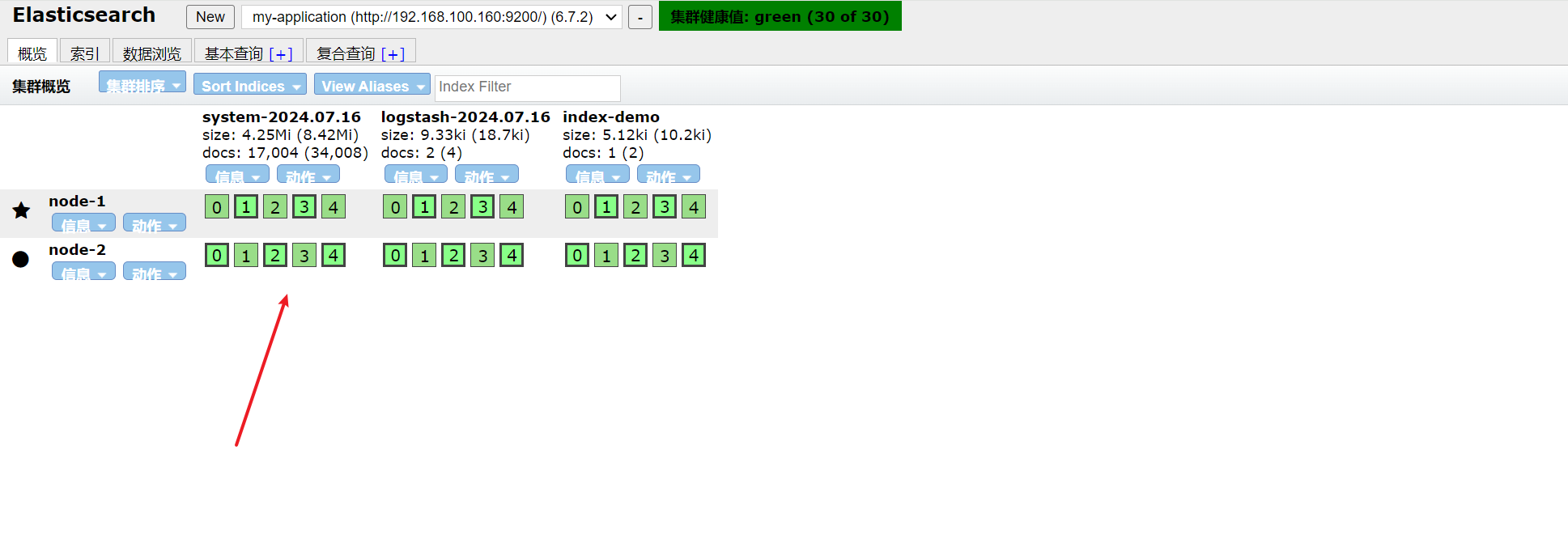
[root@localhost log]# vim /etc/logstash/conf.d/system-log.conf input { file { path => "/var/log/messages" type => "system" start_position => "beginning" } } output { elasticsearch { hosts => [ "192.168.91.100:9200","192.168.91.101:9200" ] index => "system-%{+YYYY.MM.dd}" } } [root@localhost conf.d]# chmod +r /var/log/messages #添加权限 [root@localhost conf.d]# logstash -f system-log.conf

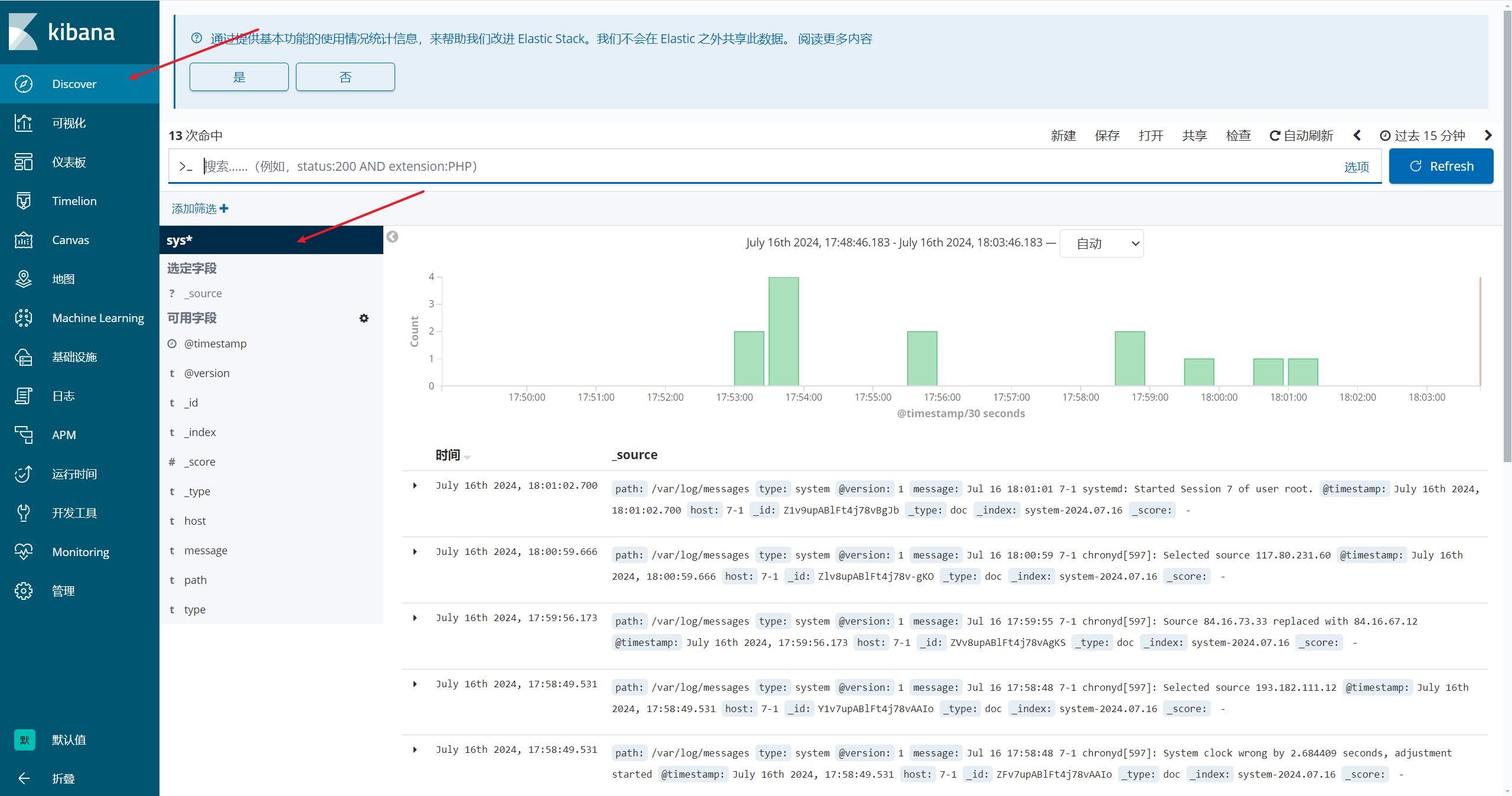
刷新页面
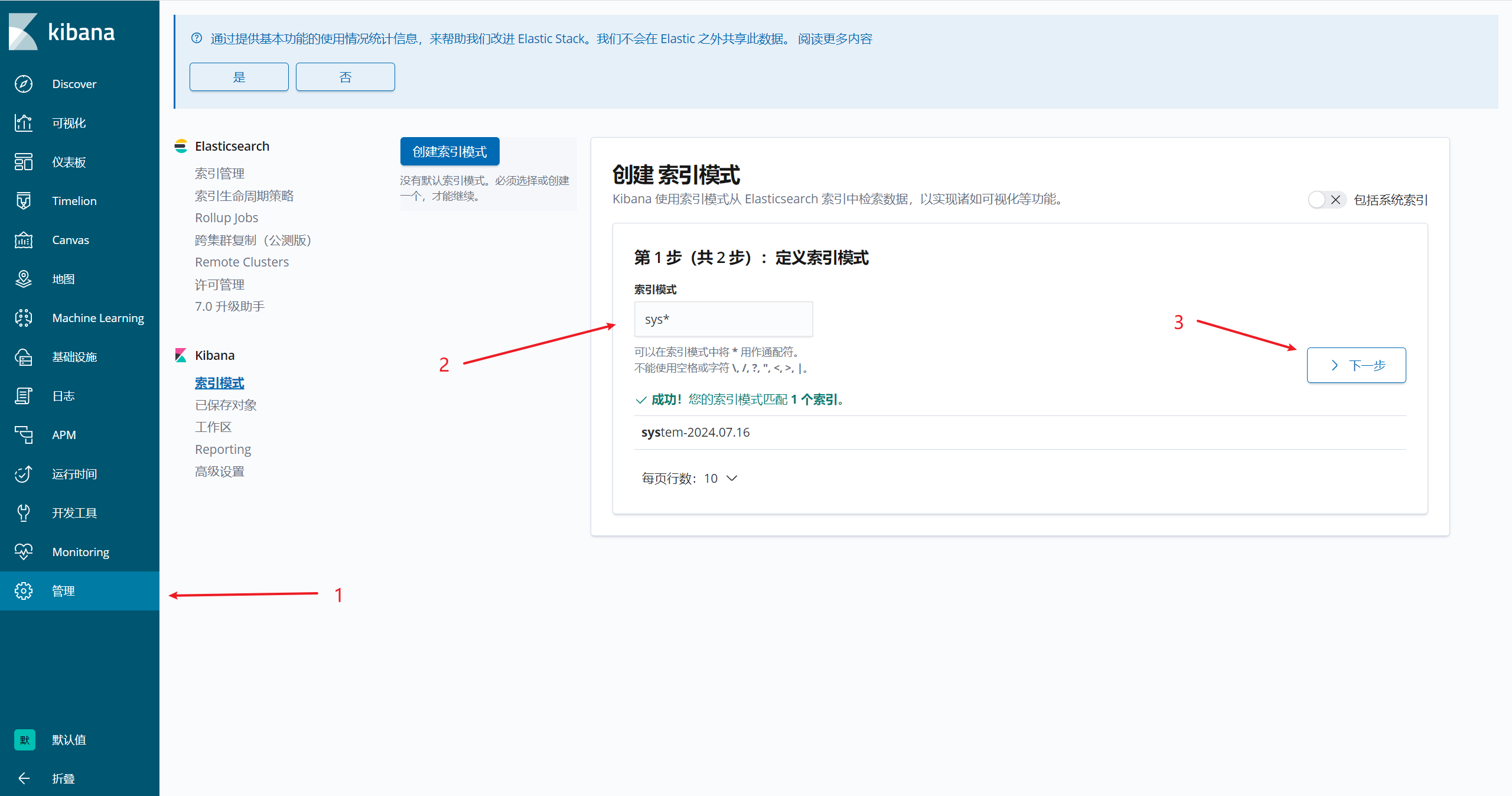
rpm -ivh kibana-6.7.2-x86_64.rpm

[root@localhost opt]# cd /etc/kibana/ [root@localhost kibana]# cp kibana.yml kibana.yml.bak -a [root@localhost kibana]# vim kibana.yml 2 server.port: 5601 #打开端口 7 server.host: "0.0.0.0" #监听端口 28 elasticsearch.hosts: ["http://192.168.100.155:9200", "http://192.168.100.160:9200"] #el服务器地址 37 kibana.index: ".kibana" #打开索引 96 logging.dest: /var/log/k.log #指定日志文件, 需要手动建立文件 114 i18n.locale: "zh-CN" #中文设置 [root@localhost kibana]# chown kibana:kibana /var/log/k.log

[root@localhost kibana]# systemctl enable --now kibana.service [root@localhost kibana]# ss -nap |grep 5601

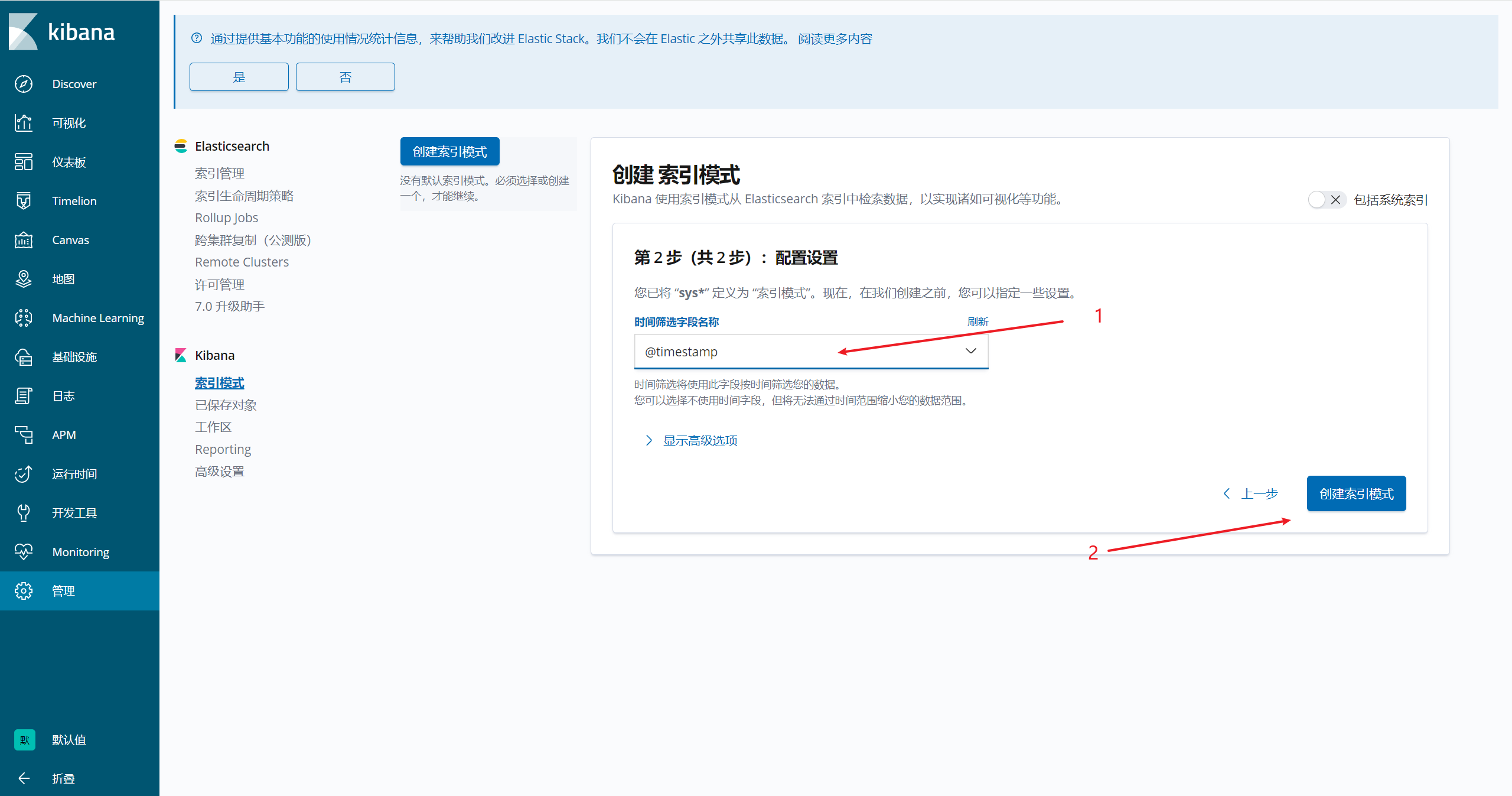
192.168.100.146:5601



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程