
正则表达式 grep sed awk
正则表达式
表示字符匹配

. 匹配任意单个字符,可以是一个汉字 [] 匹配指定范围内的任意单个字符,示例:[zhou] [0-9] [] [a-zA-Z] [[:alpha:]] [0-9a-zA-Z]= [:alnum:] [^] 匹配指定范围外的任意单个字符,示例:[^zhou] [^a.z] [a.z] [:alnum:] 字母和数字 [:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z [:lower:] 小写字母,示例:[[:lower:]],相当于[a-z] [:upper:] 大写字母 [:blank:] 空白字符(空格和制表符) [:space:] 包括空格、制表符 (水平和垂直)、换行符、回车符等各种类型的空白,比[:blank:]包含的范围广 [:cntrl:] 不可打印的控制字符(退格、删除、警铃...) [:digit:] 十进制数字 [:xdigit:]十六进制数字 [:graph:] 可打印的非空白字符 [:print:] 可打印字符 [:punct:] 标点符号 \w #匹配单词构成部分,等价于[_[:alnum:]] \W #匹配非单词构成部分,等价于[^_[:alnum:]] \S #匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 \s #匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意Unicode 正则表达式会匹配全角空格符
##标注
\f:换页符,在文本编辑中,它表示一个新页的开始。
\n:换行符,在文本编辑中,它表示新的一行的开始。
\r:回车符,在文本编辑中,它表示光标移动到当前行的末尾。
\t:制表符,在文本编辑中,它表示一个制表位,通常用于对齐文本。
\v:垂直制表符,在文本编辑中,它表示一个垂直制表位,通常用于对齐文本。
表示次数
* 匹配前面的字符任意次,贪婪模式:尽可能长的匹配 .* 任意长度的任意字符 \? 匹配其前面的字符出现0次或1次 \+ 匹配其前面的字符出现最少1次 \{n\} 匹配前面的字符n次 \{m,n\} 匹配前面的字符至少m次,至多n次 \{,n\} 匹配前面的字符至多n次,<=n \{n,\} 匹配前面的字符至少n次
位置锚定
^ 行首锚定, 用于模式的最左侧 $ 行尾锚定,用于模式的最右侧 ^PATTERN$ 用于模式匹配整行(单独一行 ^root$表示只有root) ^$ 空行,不包括空格行 ^[[:space:]]*$ 空白行
\b,\< 词首锚定,用于单词模式的左侧(连续的数字,字母,下划线都算单词内部)
\b,\> 词尾锚定,用于单词模式的右侧
表示分组或其他
分组:( ) 将多个字符捆绑在一起,当作一个整体处理,如:(root)+
后向引用:分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名方式为: \1, \2, \3, ...
\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
扩展正则表达式
在使用扩展正则表达式时,不加转义\
表示次数
* 匹配前面字符任意次 ? 0或1次 + 1次或多次 {n} 匹配n次 {m,n} 至少m,至多n次 {,n} #匹配前面的字符至多n次,<=n,n可以为0 {n,} #匹配前面的字符至少n次,<=n,n可以为0
表示分组
() 分组 分组:() 将多个字符捆绑在一起,当作一个整体处理,如:\(root\)+ 后向引用:\1, \2, ... | 或者 a|b #a或b C|cat #C或cat (C|c)at #Cat或cat
grep
grep 命令的语法:grep [选项] ...查找条件 目标文件
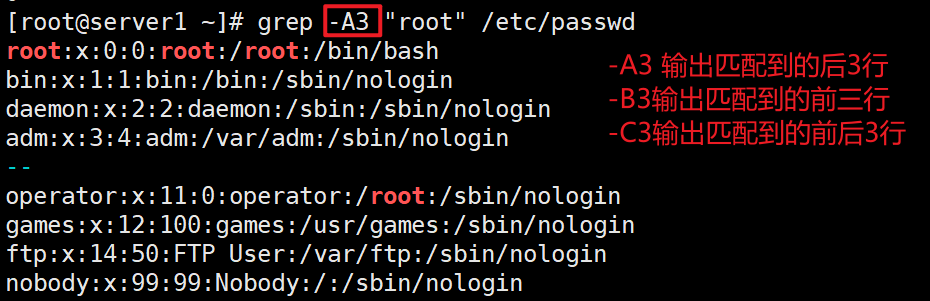
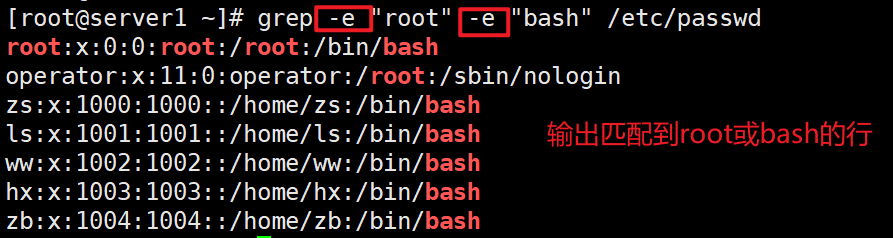
选项: -color=auto 对匹配到的文本着色显示 -m # 匹配#行后停止 grep -m 1 root /etc/passwd #多个匹配只取第一个 -v 显示不被pattern匹配到的行,即取反 grep -Ev '^[[:space:]]*#|^$' /etc/fstab -i 忽略字符大小写 -n 显示匹配的行号 -c 统计匹配的行数 grep -c root /etc/passwd #统计匹配到的行数 -o 仅显示匹配到的字符串 -q 静默模式,不输出任何信息 -A # after, 后#行 grep -A3 root /etc/passwd #匹配到的行后3行业显示出来 -B # before, 前#行 -C # context, 前后各#行 -e 实现多个选项间的逻辑or关系,如:grep –e ‘cat ' -e ‘dog' file grep -e root -e bash /etc/passwd #包含root或者包含bash 的行 grep -E root|bash /etc/passwd -w 匹配整个单词 grep -w root /etc/passwd useradd rooter -E 使用ERE,相当于egrep #使用扩展正则表达式 -F 不支持正则表达式,相当于fgrep -f file 根据模式文件,处理两个文件相同内容 把第一个文件作为匹配条件 -r 递归目录,但不处理软链接 -R 递归目录,但处理软链接


awk
awk的工作原理
###awk的工作原理
第一步:执行BEGIN{action;… }语句块中的语句
第二步:从文件或标准输入(stdin)读取一行,然后执行pattern{ action;… }语句块,它逐行扫描文件,
从第一行到最后一行重复这个过程,直到文件全部被读取完毕。
第三步:当读至输入流末尾时,执行END{action;…}语句块
BEGIN语句块在awk开始从输入流中读取行之前被执行,这是一个可选的语句块,比如变量初始化、打印输出表格的表头等语句通常可以写在BEGIN语句块中;
END语句块在awk从输入流中读取完所有的行之后即被执行,比如打印所有行的分析结果这类信息汇总都是在END语句块中完成,它也是一个可选语句块pattern语句块中的通用命令是最重要的部分,也是可选的。
如果没有提供pattern语句块,则默认执行{print},即打印每一个读取到的行,awk读取的每一行都会执行该语句块
##### BEGIN{}模式表示,在处理指定的文本前,需要先执行BEGIN模式中的指定动作; awk再处理指定的文本,之后再执行END模式中的指定动作,END{}语句中,一般会放入打印结果等语句。
读取输入:AWK首先读取输入文件或从标准输入接收输入;
分割输入:AWK默认将输入行分割成字段,并使用空格或制表符作为字段分隔符;
匹配模式:AWK使用模式匹配来确定需要处理的行,可以使用正则表达式或其他条件来指定匹配的行。如果没有指定模式,AWK将默认匹配所有行;
执行动作:当输入行与模式匹配时,AWK执行相应的动作;
处理下一行:一旦完成当前行的处理,AWK继续处理下一行,重复上述步骤。
awk命令格式
#命令格式# awk [选项] '[模式匹配条件]{处理动作 }' 文件1 文件2..
常用选项
#选项# #一般只有-F常用 -F 指定分隔符,默认的分隔符是若干个连续空白符,默认的时候可不写 -v 自定义变量 -f 脚本 awk '/匹配条件/{ print $x }' #匹配条件可以不写 x为任意数字
模式匹配条件
#模式匹配条件格式# / 匹配条件 / # 起始 结束 #/ / 一定要加
处理动作
#操作# #常用的 只有 print awk '{ print $1 }' awk '{ print $1 $2 $3 .... }' #awk会自动压缩空格,不需要再写tr -s ' '
awk常用内置变量
- FS :指定每行文本的字段分隔符,缺省默认为空格或制表符(tab)。与 “-F”作用相同 -v "FS=:" - OFS:输出时的分隔符 - NF:当前处理的行的字段个数 - NR:当前处理的行的行号(序数) - $0:当前处理的行的整行内容 - $n:当前处理行的第n个字段(第n列) - FILENAME:被处理的文件名 - RS:行分隔符。awk从文件上读取资料时,将根据RS的定义就把资料切割成许多条记录,而awk一次仅读入一条记录进行处理。预设值是\n
常见操作
指定分隔符 -F
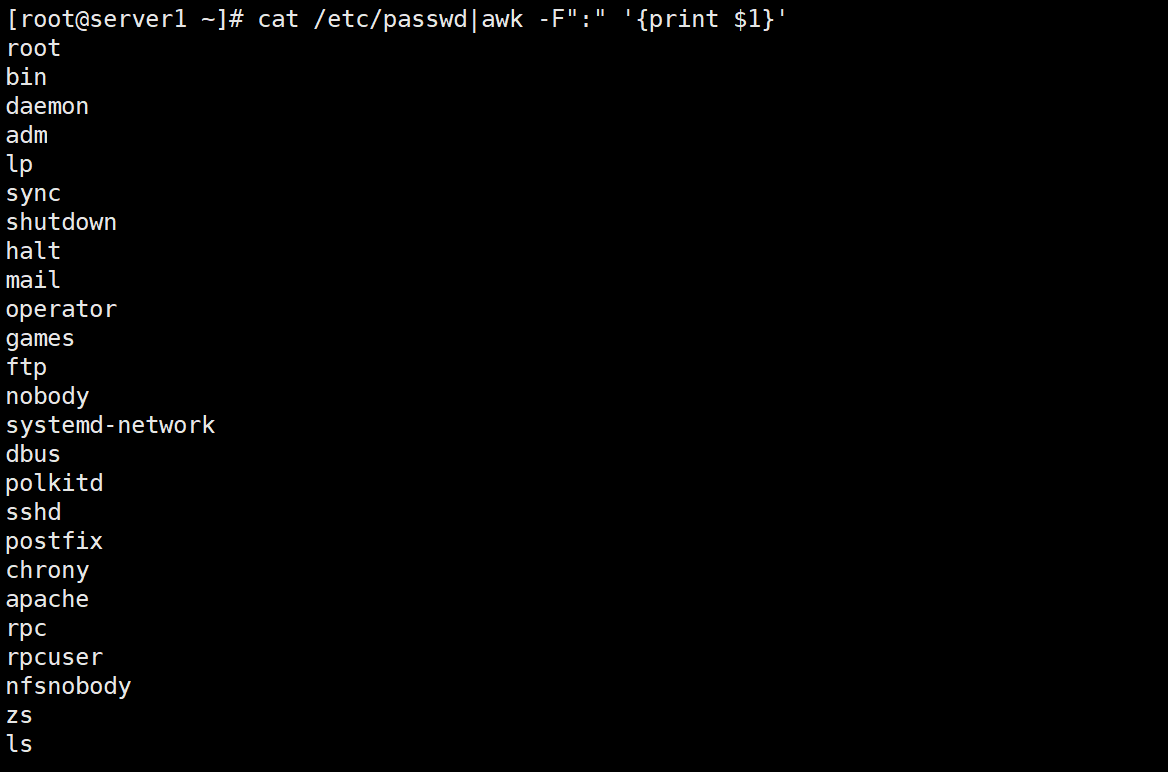
指定':'为分隔符 cat /etc/passwd|awk -F":" '{print $1}' #打印所有用户名
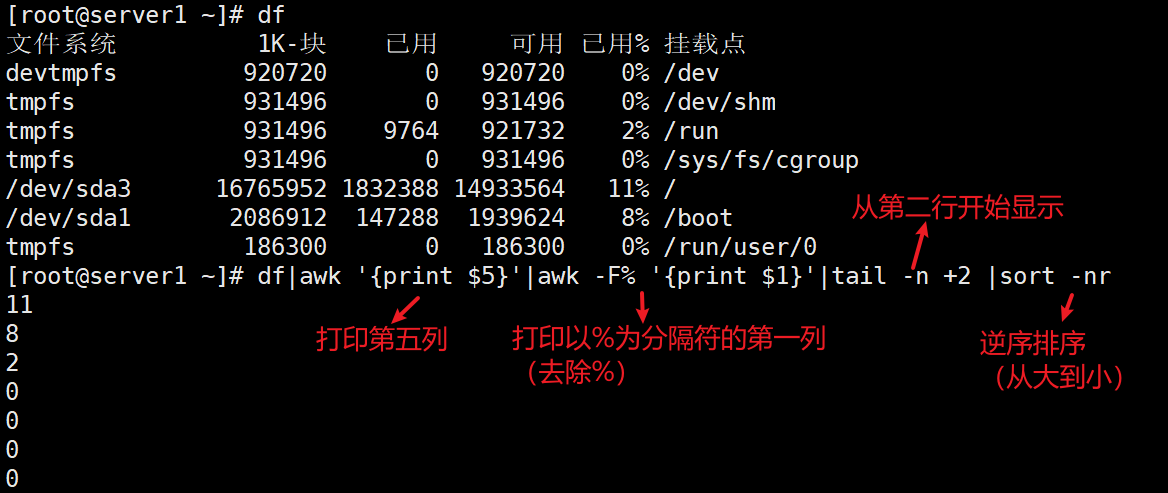
df|awk '{print $5}'|awk -F% '{print $1}'|tail -n +2 |sort -nr #打印磁盘已经使用情况,去除%并且从第二行开始倒序显示
BEGIN 和 END
BEGIN模式表示,在处理指定的文本之前,需要先执行BEGIN模式中指定的动作;
awk再处理指定的文本,之后再执行END模式中指定的动作;
END{ } 语句块中,往往会放入打印结果等语句
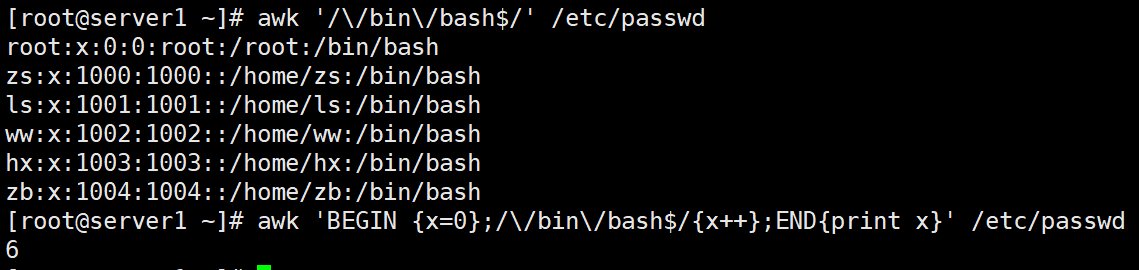
awk 'BEGIN {x=0};/\/bin\/bash$/{x++};END{print x}' /etc/passwd #显示包含/bin/bash的行在/etc/passwd中的数量
{x=0} # 在开始之前,初始化变量x为0
/\/bin\/bash$/ # 使用正则表达式匹配包含"/bin/bash"的行
{x++} # 每匹配到一行,变量x加1
END {print x} # 结束后,输出变量x的值
NR行号
awk 'NR==3' /etc/passwd #打印特定行号的行的内容

awk 'END {print NR}' /etc/passwd #计算输入文件的总行数
![]()
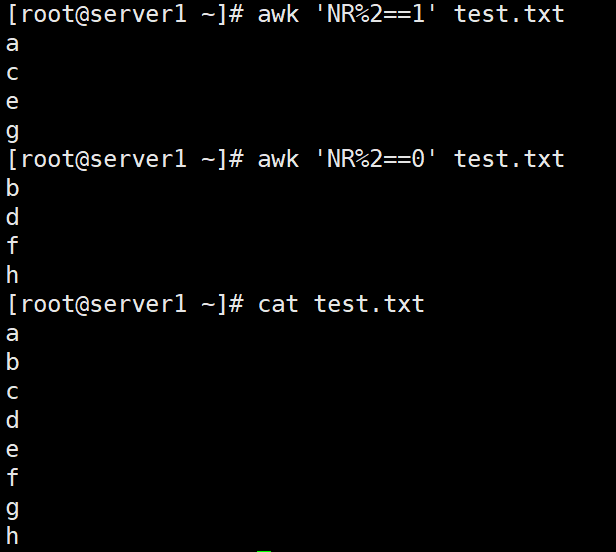
awk 'NR%2==1' test.txt #奇数行提取 awk 'NR%2==0' test.txt #偶数行提取
awk '{if (NR%2 == 0) {print "111: " $0} else {print "222: " $0}}' test.txt

NF当前处理的行的字段个数
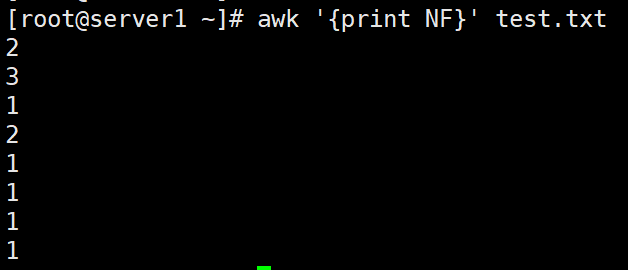
awk '{print NF}' test.txt #打印每一行的字段数量
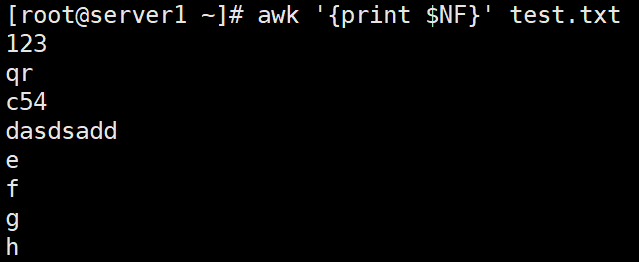
awk '{print $NF}' test.txt #打印每一行的最后一个字段
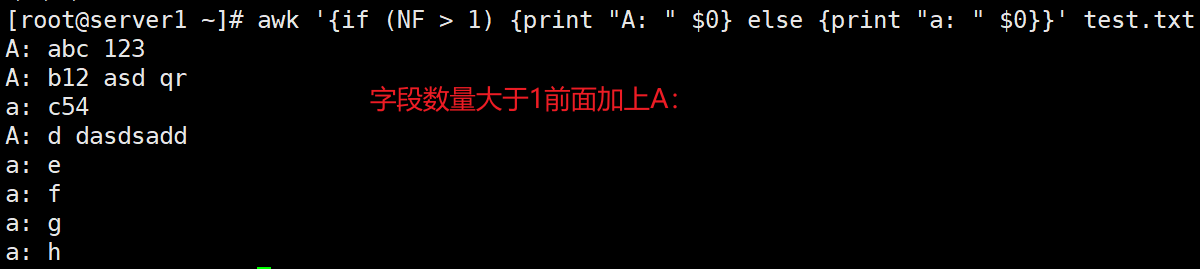
awk '{if (NF > 3) {print "A: " $0} else {print "a: " $0}}' test.txt #根据字段数量执行不同的操作
awk实例
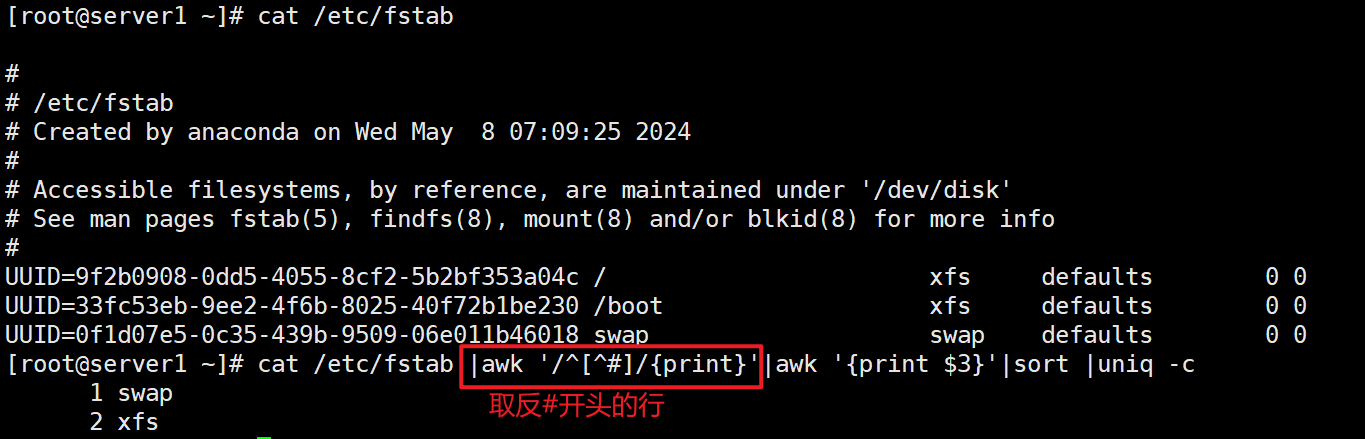
cat /etc/fstab |awk '/^[^#]/{print}'|awk '{print $3}'|sort |uniq -c #统计/etc/fstab文件中每个文件系统类型出现的次数


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· Vue3状态管理终极指南:Pinia保姆级教程