Hadoop完全分布式搭建
1.环境准备
1.1准备三台客户机
1)关闭防火墙
查看防火墙状态
systemctl status firewalld.service
关闭防火墙并关闭防火墙开机自启
sudo systemctl stop firewalld
sudo systemctl disable firewalld.service
2)设置静态ip
vim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static" #设置为静态ip
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="bbc612ba-5365-42a5-9794-38baddacc898"
DEVICE="ens33"
ONBOOT="yes"
#IP 地址
IPADDR=192.168.44.101
#网关
GATEWAY=192.168.44.2
#域名解析器
DNS1=192.168.44.2
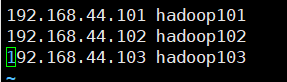
3)配置主机与主机间的映射关系
vim /etc/hosts
1.2安装JDK
1)卸载现有JDK
- 查询是否安装java软件
rpm -qa | grep jdk
- 卸载JDK
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.322.b06-1.el7_9.x86_64
2)安装JDK
- 将已下载的JDK包拖入/opt/software目录下
- 将导入的JDK解压到/opt/module目录下
tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
- 配置环境变量,在profile文件末尾添加JDK路径
vim /etc/profile
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
- 让文件生效
source /etc/profile
- 查看JDK是否安装成功(控制台输出java version "1.8.0_144"则安装成功)
java -version
1.3设置ssh免密登录
1.4安装Hadoop
1)Hadoop下载地址
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/
2)将安装包放入/opt/software目录下
3)解压安装包到/opt/module目录下
tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
4)将Hadoop添加到环境变量
vim /etc/profile
将以下内容添加到文件末尾
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
让文件生效
source /etc/profile
5)查看是否安装成功
hadoop version
2.集群配置
2.1 集群部署规划

2.2 配置集群(进入到Hadoop安装目录下的/etc/hadoop/)
1)核心配置文件
配置core-site.xml
vim core-site.xml
在文件中编写如下配置
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
2)HDFS配置文件
配置hdfs-site.xml
vim hdfs-site.xml
在文件中编写如下配置
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:50090</value>
</property>
3)YARN配置文件
配置yarn-site.xml
vim yarn-site.xml
在文件中编写如下配置
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
4)MapReduce配置文件
配置mapred-site.xml
vim mapred-site.xml
在文件中编写如下配置
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
5)配置slaves
vim slaves
在文件中增加如下内容:
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
hadoop102
hadoop103
hadoop104
2.3 分发配置文件
xsync /opt/module/hadoop-2.7.2/
3.集群启动
- 集群第一次启动需要格式化NameNode
hadoop namenode -format
- 集群启动
在namenode节点主机上启动hdfs
start-dfs.sh
在ResourceManager节点主机上启动yarn
start-yarn.sh
- 查看是否成功启动
[root@hadoop102 hadoop-2.7.2]$ jps
4166 NameNode
4482 Jps
4263 DataNode
4520 NodeManager
[root@hadoop103 hadoop-2.7.2]$ jps
3218 DataNode
3288 Jps
3674 ResourceManager
3567 NodeManager
[root@hadoop104 hadoop-2.7.2]$ jps 3221 DataNode 3283 SecondaryNameNode 3364 Jps
3258 NodeManager
- web端查看
浏览器中输入:http://hadoop102:50070

 浙公网安备 33010602011771号
浙公网安备 33010602011771号