RabbitMQ学习笔记
目录
- 前言
- 1 消息队列
- 2 Hello World
- 3 Work Queues
- 4 发布确认
- 5 交换机
- 6 死信队列
- 7 延迟队列
- 8 发布确认高级
- 9 RabbitMQ 其他知识点
- 10 RabbitMQ 集群
- 后记
前言
让我们跟随尚硅谷王旭老师的讲解步入RabbitMQ的学习中去吧。
1 消息队列
1.1 MQ概述
1.1.1 MQ介绍

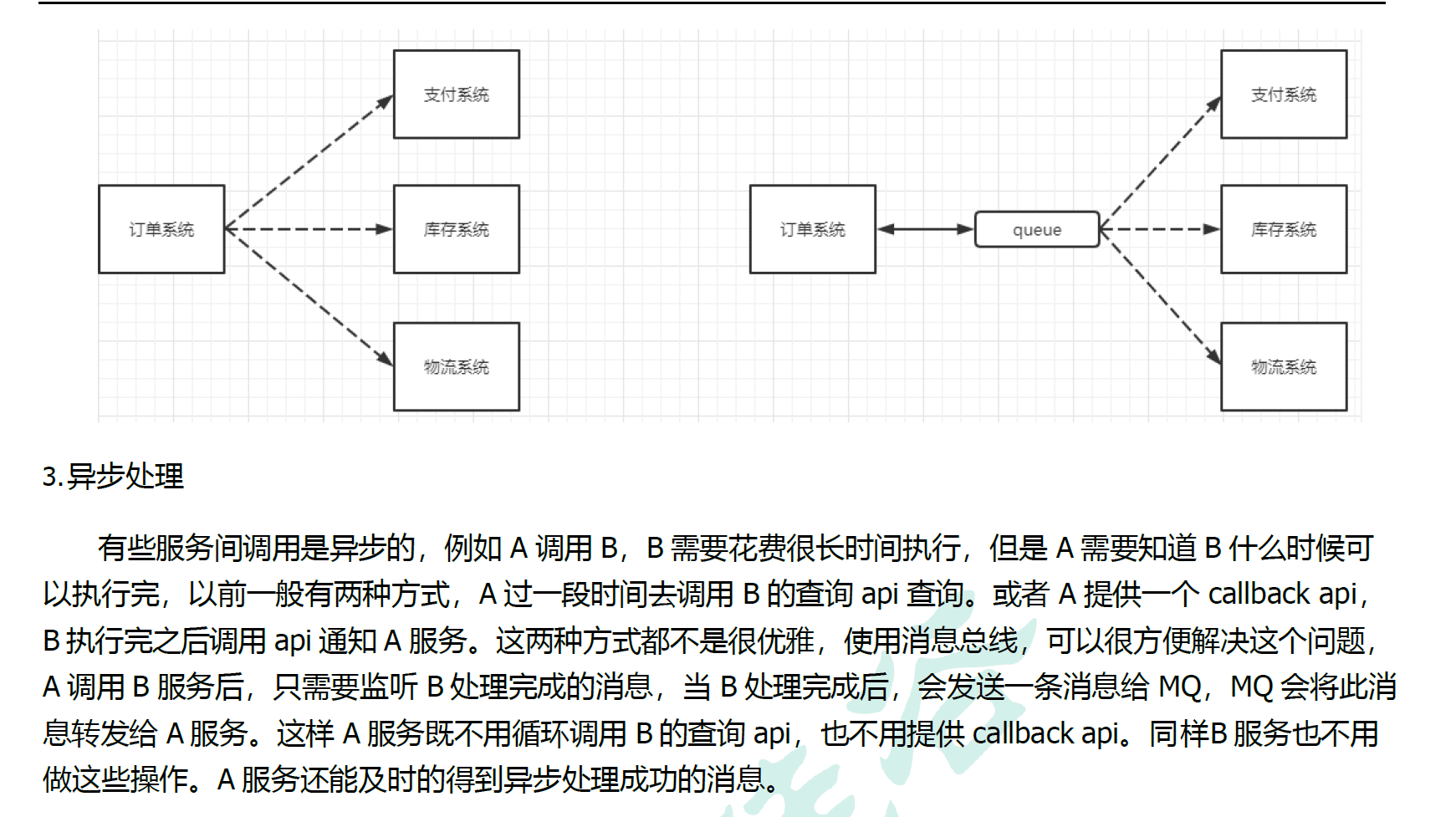
1.1.2 MQ的分类
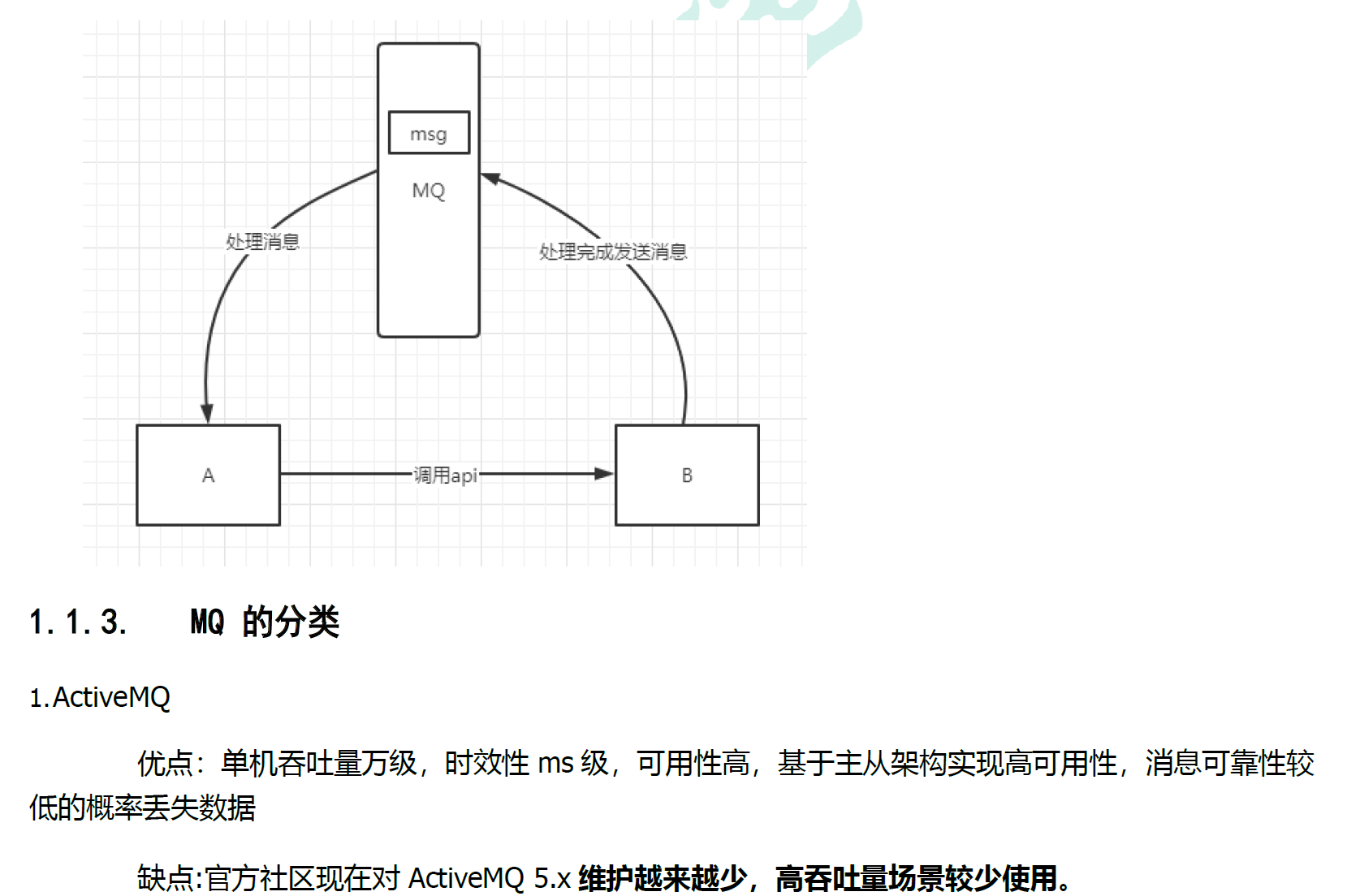

1.1.3 MQ的选择

1.2 RabbitMQ
1.2.1 RabbitMQ的概念

1.2.2 四大核心概念


1.2.3 RabbitMQ的核心概念
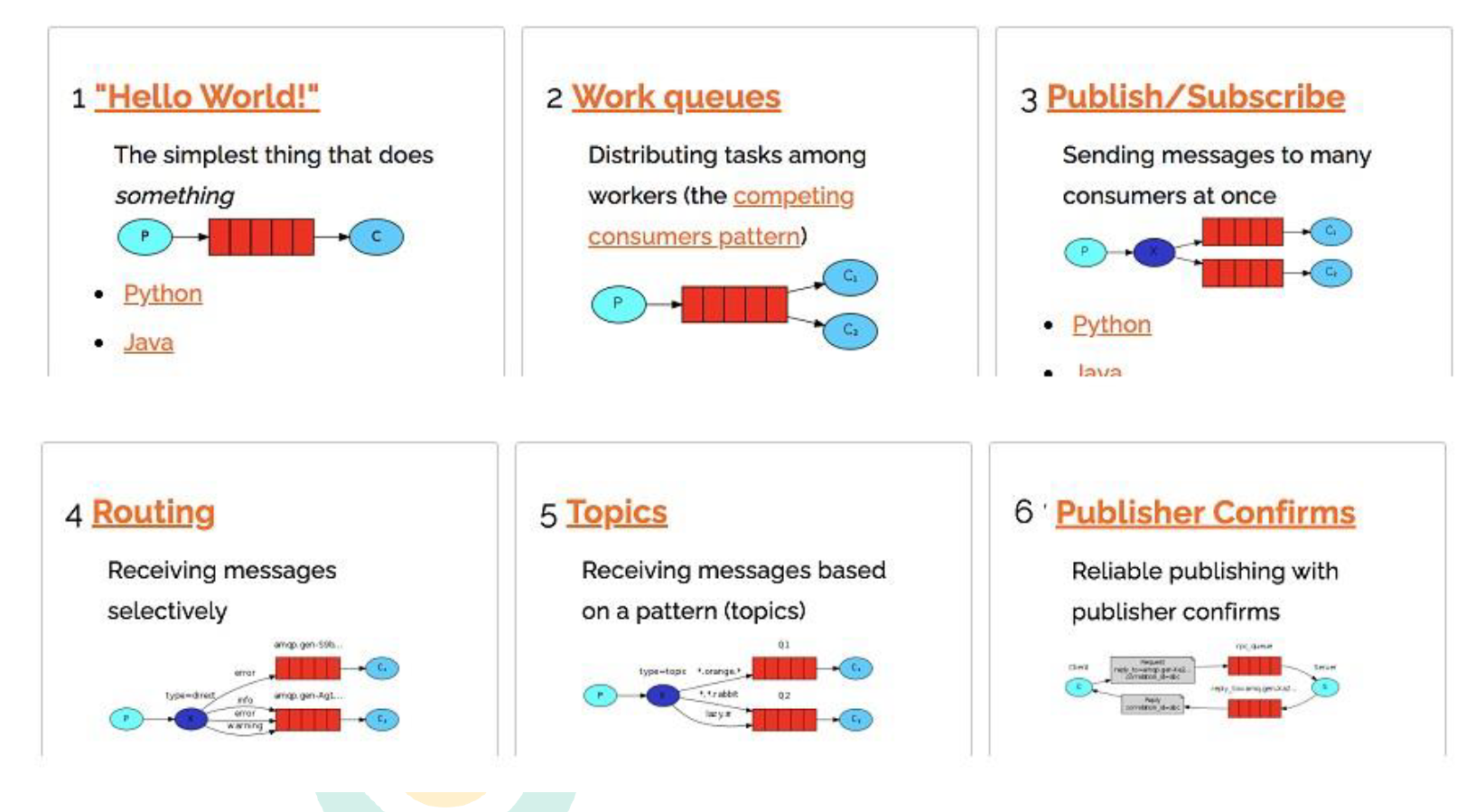
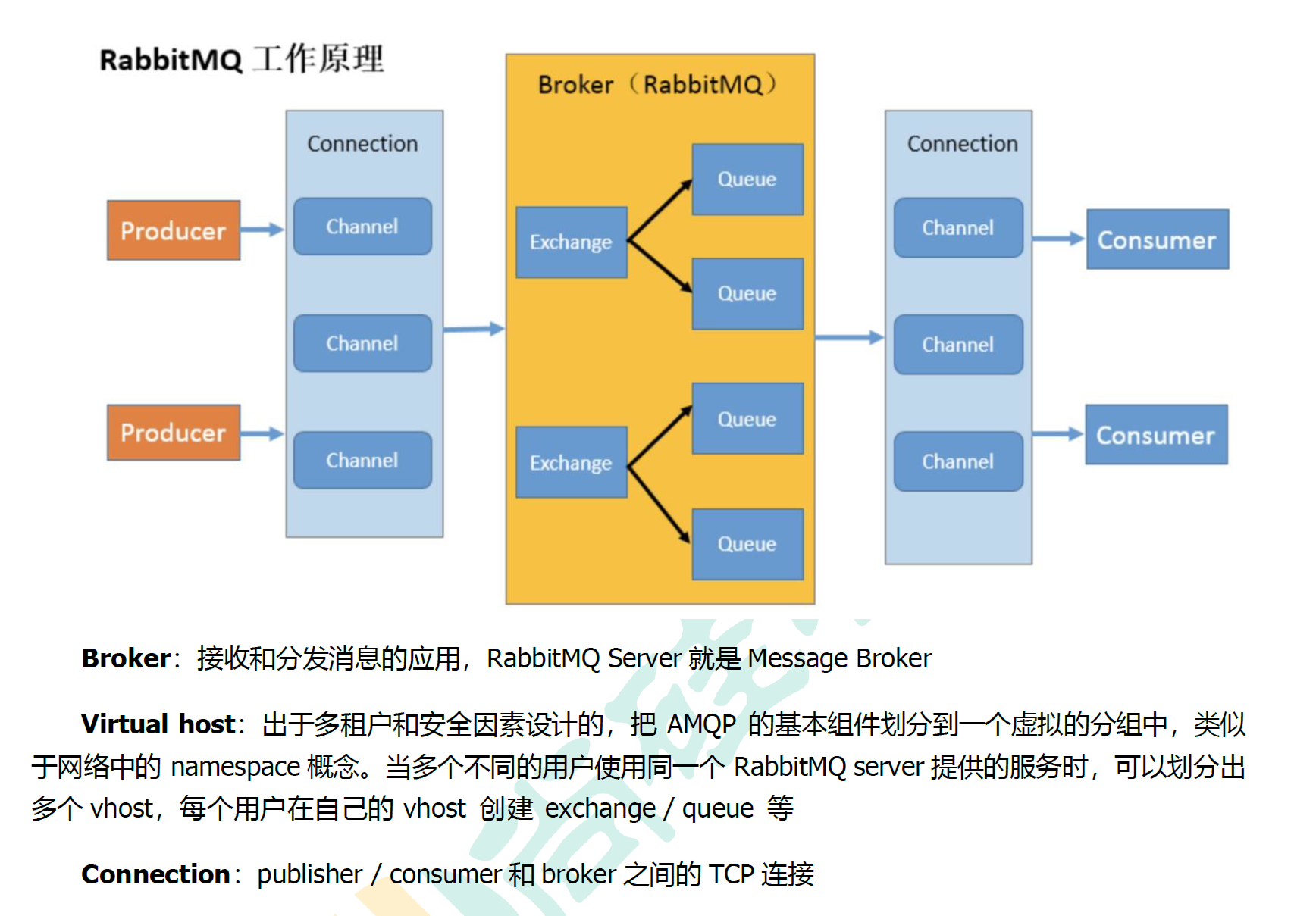
1.2.4 名词介绍

1.2.5 安装

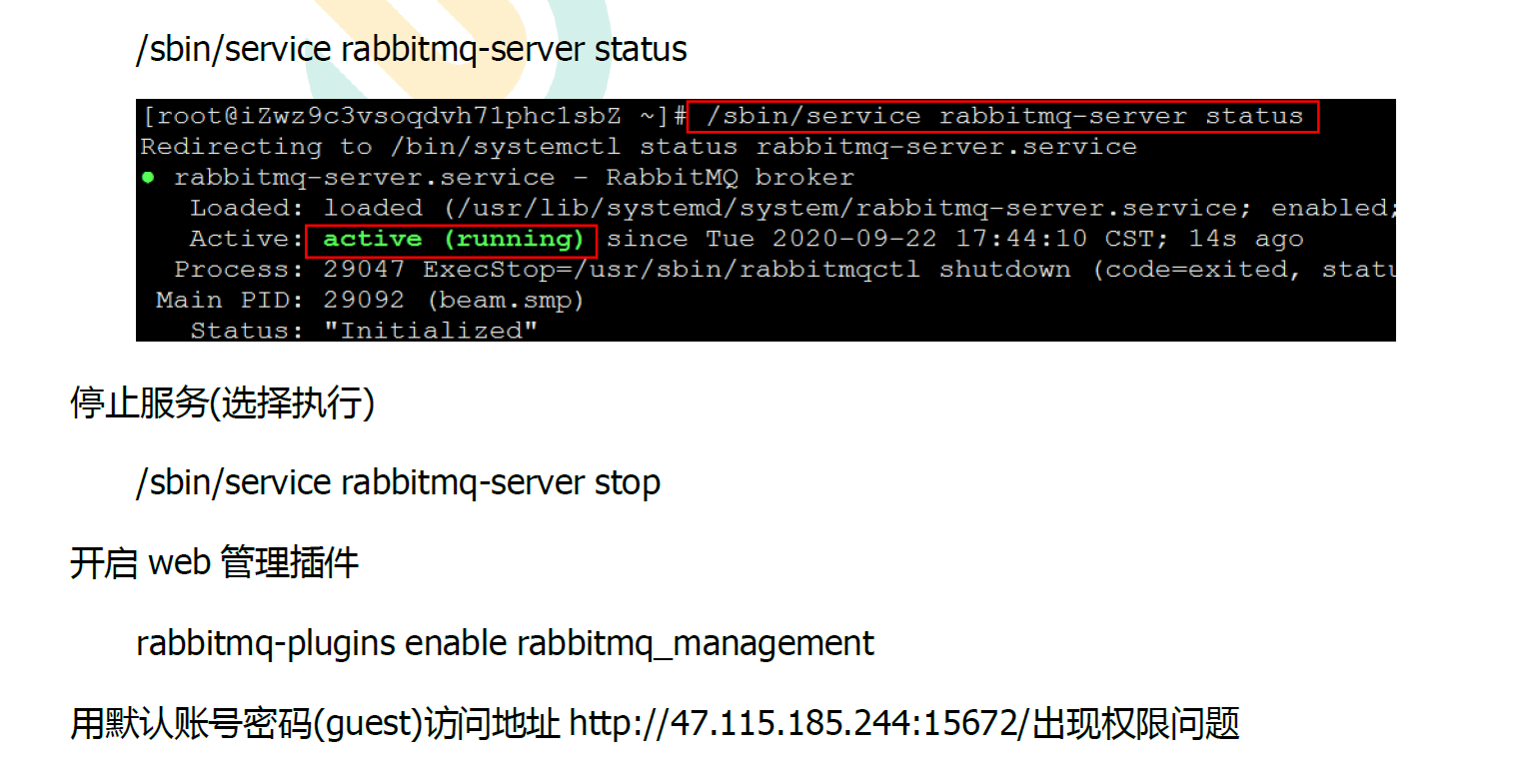
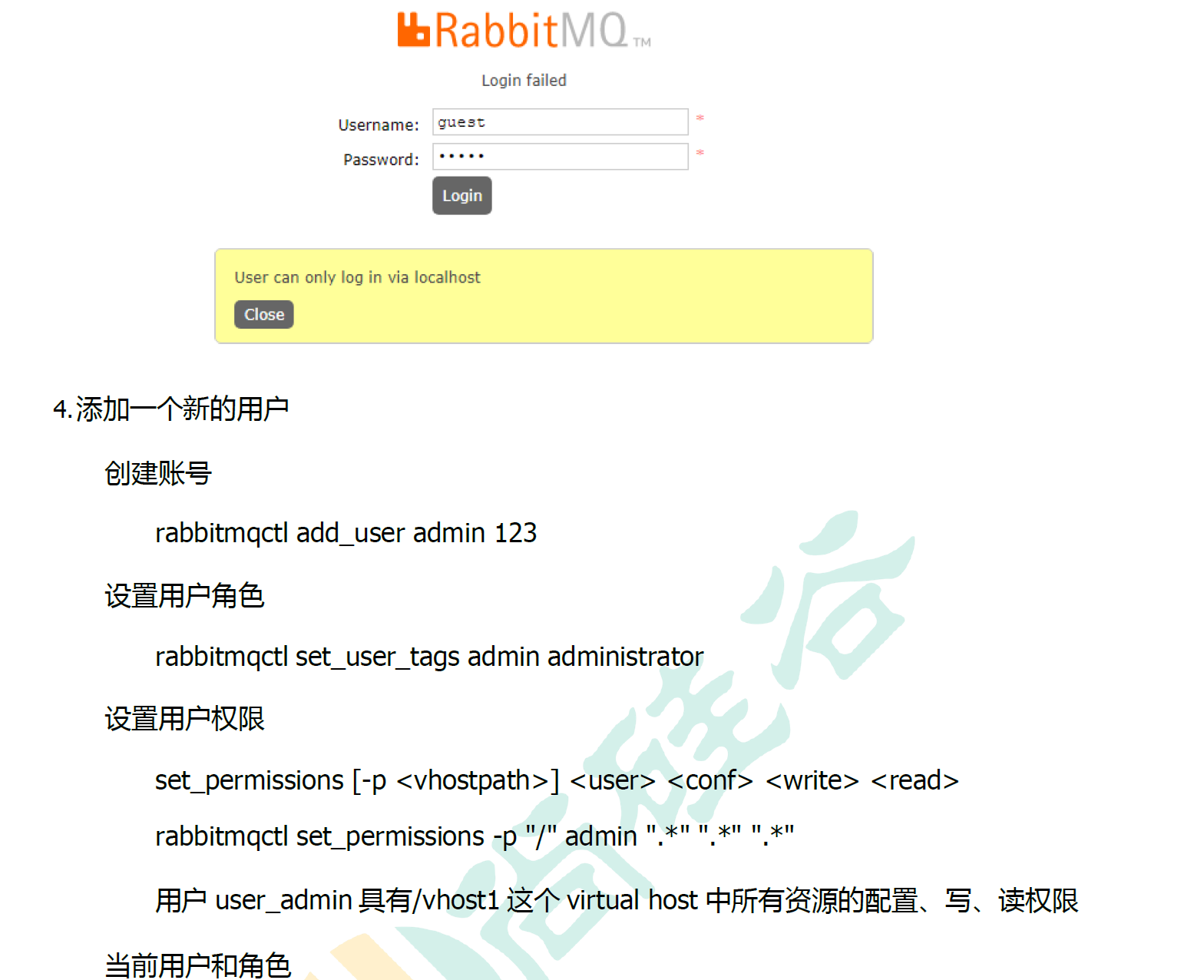
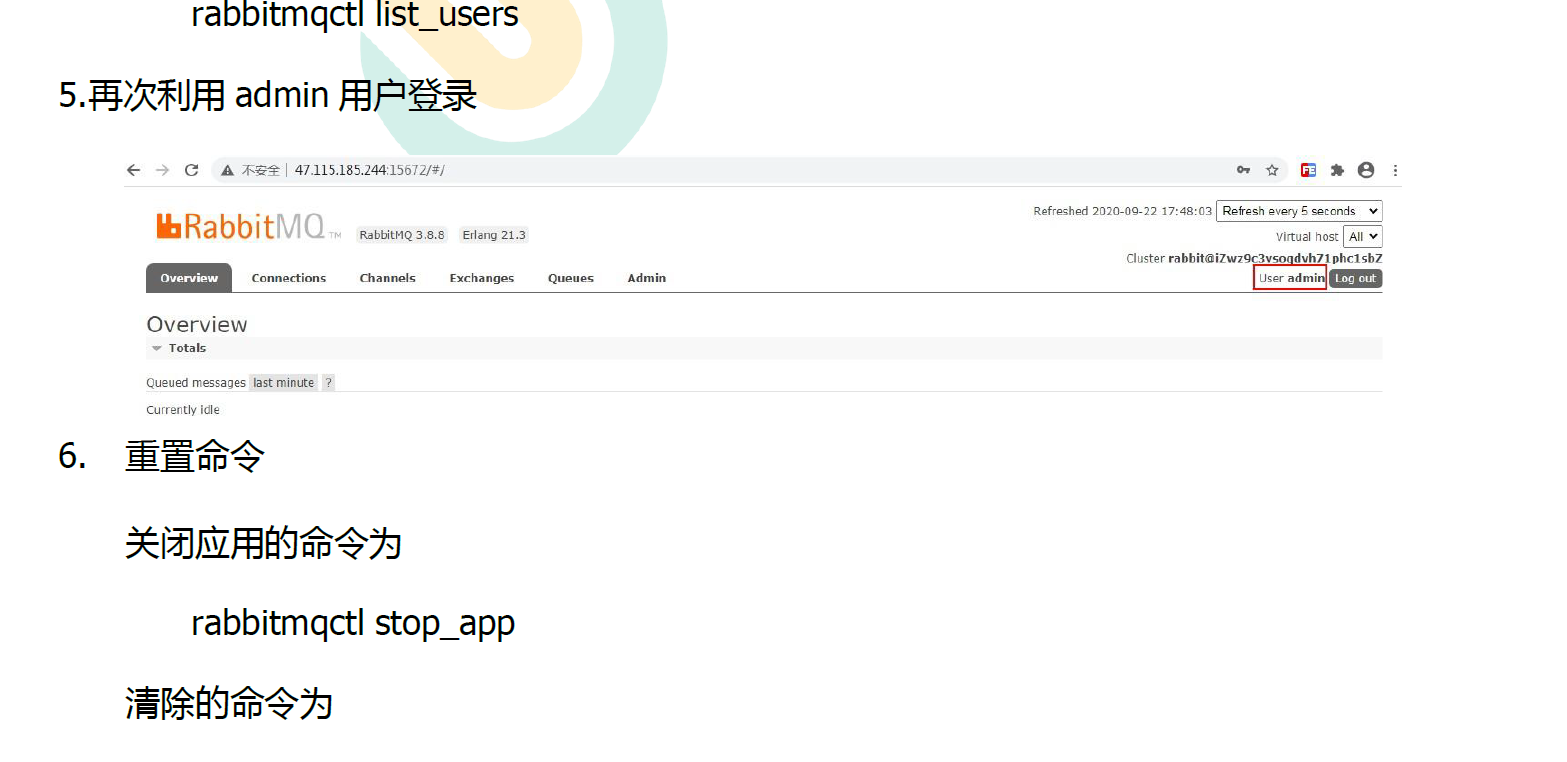

在vm26-vm28装的。
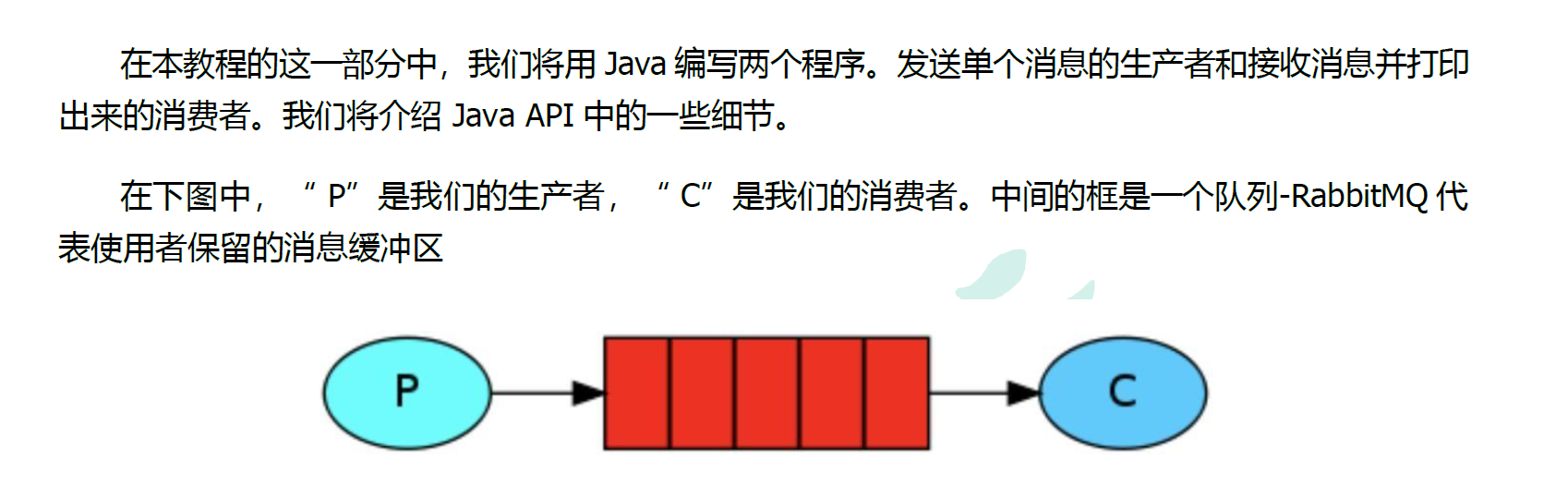
2 Hello World
2.1 依赖
<dependencies>
<!--rabbitmq依赖客户端-->
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>5.8.0</version>
</dependency>
<!--操作文件流的一个依赖-->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
</dependencies>
2.2 消息生产者
public class Producer {
//队列名称
public static final String QUEUE_NAME = "hello";
//URL
public static final String URL_NAME = "192.168.76.100";
//用户名
public static final String USER_NAME = "admin";
//密码
public static final String PASSWORD = "123";
public static void main(String[] args) throws IOException, TimeoutException {
//创建工厂
ConnectionFactory factory = new ConnectionFactory();
// 工厂ip 连接RabbitMQ的队列
factory.setHost(URL_NAME);
//用户名
factory.setUsername(USER_NAME);
//密码
factory.setPassword(PASSWORD);
//创建连接
Connection connection = factory.newConnection();
//获取信道
Channel channel = connection.createChannel();
/**
* 生成一个队列
* 参数有五个
* 1.队列名称
* 2.队列里面的消息是否持久化(磁盘) 默认非持久化即存在内存中
* 3.该队列是否只能供一个消费者消费,即进行消息共享,true:共享,false:不共享
* 4.是否自动删除 当最后一个消费者断开连接后,该队列是否自动删除,true:自动删除
* 5.其他参数
*/
channel.queueDeclare(QUEUE_NAME,false,false,false,null);
//发消息
String message = "hello world";
/**
* 发送一个消息
* 1.发送到哪个交换机
* 2.路由的Key值是哪个,本次是队列的名称
* 3.其他参数信息
* 4.发送消息的消息体
*/
channel.basicPublish("",QUEUE_NAME,null,message.getBytes());
System.out.println("消息发送完毕");
}
}
2.3 消息生产者
public class Consumer {
//队列名称
public static final String QUEUE_NAME = "hello";
//URL
public static final String URL_NAME = "192.168.76.100";
//用户名
public static final String USER_NAME = "admin";
//密码
public static final String PASSWORD = "123";
public static void main(String[] args) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost(URL_NAME);
factory.setUsername(USER_NAME);
factory.setPassword(PASSWORD);
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
/**
* 参数
* 1.消费哪个队列
* 2.消费成功后是否自动应答 true:自动yingda
* 3.消费者成功消费的回调 - -- 接口 使用匿名内部类或者lambda
* 4.消费者取消消费的回调 - -- 接口 使用匿名内部类或者lambda
*/
//成功消费
//匿名内部类实现方式
// DeliverCallback deliverCallback = new DeliverCallback() {
// @Override
// public void handle(consumerTag, message) throws IOException {
// System.out.println(message);
// }
// };
//lambda表达式
DeliverCallback deliverCallback = (consumerTag, message) -> {
System.out.println(new String(message.getBody()));
};
//未成功消费
//匿名内部类
// CancelCallback cancelCallback = new CancelCallback() {
// @Override
// public void handle(String consumerTag ) throws IOException {
// System.out.println(consumerTag );
// }
// };
//lambda表达式 当只有一个参数的时候可以取消小括号
CancelCallback cancelCallback =consumerTag -> {
System.out.println("消息消费被中断");
};
channel.basicConsume(QUEUE_NAME,true,deliverCallback,cancelCallback);
}
}
3 Work Queues
工作队列(又称任务队列)的主要思想是避免立即执行资源密集型任务,而不得不等待它完成。相反我们安排任务在之后执行。我们把任务封装为消息并将其发送到队列。在后台运行的工作进程将弹出任务并最终执行作业。当有多个工作线程时,这些工作线程将一起处理这些任务。
3.1 轮训发送消息
3.1.1 抽取工具类
因为生产者和消费者最初创建信道的代码是一样的,所以我们可以进行抽取为一个工具类,然后返回这个信道即可。
public class RabbitMQUtils {
//URL
public static final String URL_NAME = "192.168.76.100";
//用户名
public static final String USER_NAME = "admin";
//密码
public static final String PASSWORD = "123";
public static Channel getChannel() throws Exception {
//创建工厂
ConnectionFactory factory = new ConnectionFactory();
// 工厂ip 连接RabbitMQ的队列
factory.setHost(URL_NAME);
//用户名
factory.setUsername(USER_NAME);
//密码
factory.setPassword(PASSWORD);
//创建连接
Connection connection = factory.newConnection();
//获取信道
Channel channel = connection.createChannel();
return channel;
}
}
3.1.2 创建消费者
public class Wroker01 {
public static final String QUEUE_NAME = "hello";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
DeliverCallback deliverCallback = (consumerTag, message) -> {
System.out.println("接收到的消息:"+message.getBody());
};
CancelCallback cancelCallback = consumerTag -> {
System.out.println(consumerTag +"消息失败回调");
};
System.out.println("c2等待接收消息");
channel.basicConsume(QUEUE_NAME,true,deliverCallback,cancelCallback);
}
}
public class Wroker01 {
public static final String QUEUE_NAME = "hello";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
DeliverCallback deliverCallback = (consumerTag, message) -> {
System.out.println("接收到的消息:"+message.getBody());
};
CancelCallback cancelCallback = consumerTag -> {
System.out.println(consumerTag +"消息失败回调");
};
System.out.println("c1等待接收消息");
channel.basicConsume(QUEUE_NAME,true,deliverCallback,cancelCallback);
}
}
这两个消费者代码都是一样的,我们只是模拟一种场景,生产者发送消息,多个消费者到底是怎么进行接收消费的。
3.1.3 生产者
public class Task01 {
public static final String QUEUE_NAME = "hello";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
channel.queueDeclare(QUEUE_NAME,false,false,false,null);
//从控制台接收消息
Scanner scanner = new Scanner(System.in);
while(scanner.hasNext()){
String message = scanner.next();
/**
* 发送到哪个交换机
* 路由的key值是哪个,即本次队列的名称
* 其他参数信息
* 发送消息的消息体
*/
channel.basicPublish("",QUEUE_NAME,null,message.getBytes());
System.out.println("消息发送完成"+message);
}
}
}
3.1.4 测试
我们通过采用在控制台输出消息来生产消息进行测试,看看两个消费者收到的消息的数量。
结论:两个消费者消费消息是轮训的,即发送aa bb cc dd ,消费者1 :aa 消费者2: bb 消费者1:cc 消费者2:dd,当然顺序可能不一样。但是总的来说是一个消费者消费一条,下一条会被另一消费者消费。

3.2 消息应答
3.2.1 概念

3.2.2 自动应答

工作中几乎不用。我们采用手动应答的方式。
3.2.3 消息应答的方法

3.2.4 Multiple 的解释

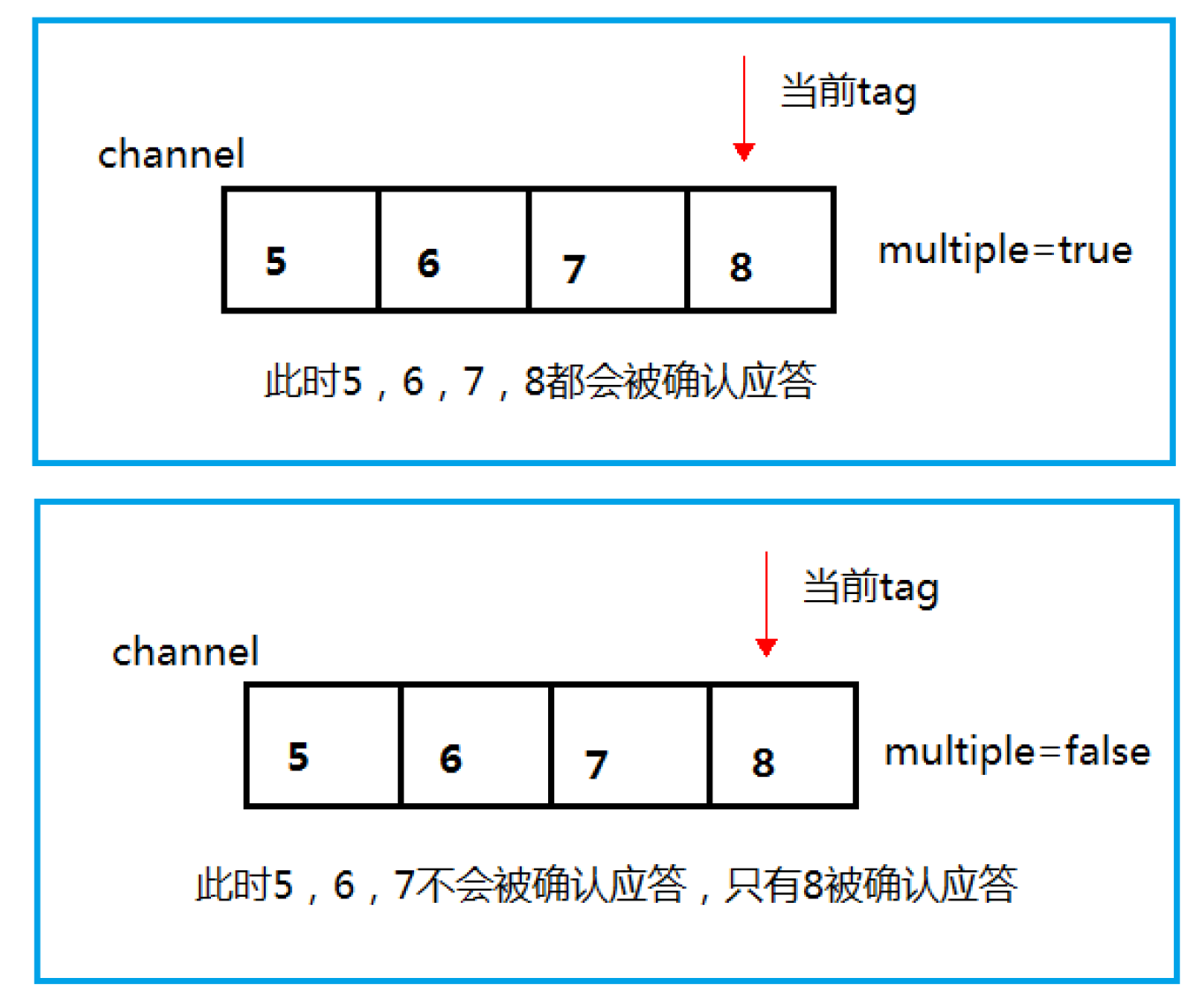
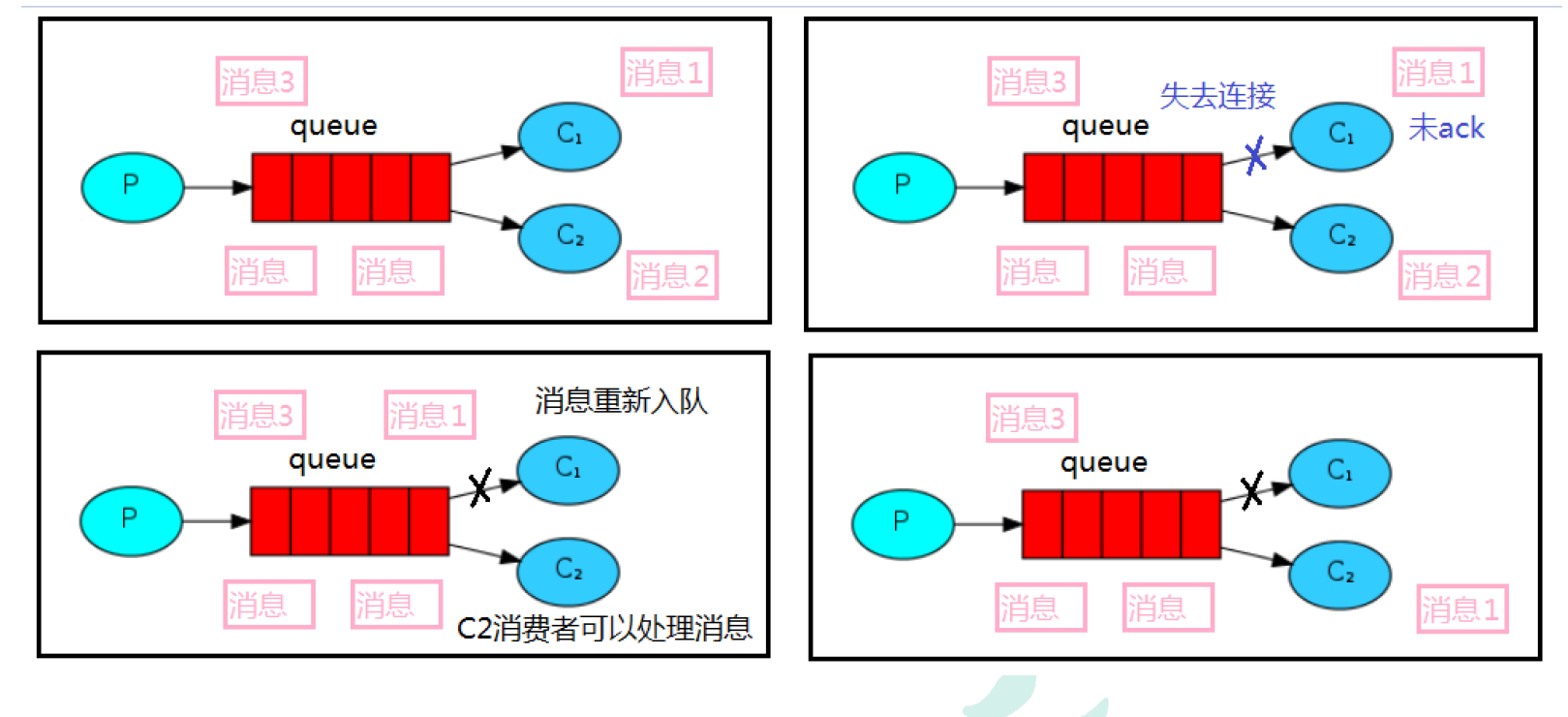
3.2.5 消息自动重新入队
如果消费者由于某些原因失去连接(其通道已关闭,连接已关闭或 TCP 连接丢失),导致消息未发送 ACK 确认,RabbitMQ 将了解到消息未完全处理,并将对其重新排队。如果此时其他消费者可以处理,它将很快将其重新分发给另一个消费者。这样,即使某个消费者偶尔死亡,也可以确保不会丢失任何消息。
3.2.6 消息手动应答代码
默认消息采用的是自动应答,所以我们要想实现消息消费过程中不丢失,需要把自动应答改为手动应答。
生产者代码无变化。
public class Task02 {
public static final String TASK_QUEUE_NAME = "ack_queue";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
channel.queueDeclare(TASK_QUEUE_NAME,false,false,false,null);
//从控制台接收消息
Scanner scanner = new Scanner(System.in);
while (scanner.hasNext()){
String message = scanner.next();
channel.basicPublish("",null,message.getBytes(StandardCharsets.UTF_8));
System.out.println("生产者生产消息:"+message);
}
}
}
消费者1
public class Wroker03 {
public static final String TASK_QUEUE_NAME = "ack_queue";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
System.out.println("c1接收消息较短");
DeliverCallback deliverCallback = (consumerTag, message) -> {
// 模拟场景 业务处理多,睡眠1秒
SleepUtils.sleep(1);
System.out.println("接收到的消息:"+new String(message.getBody(),"utf-8"));
//手动应答
/**
* 参数1 :消息标记,每一个消息头上都带着一个消息标记
* 参数2:是否批量应答 true 表示批量
*/
channel.basicAck(message.getEnvelope().getDeliveryTag(),false);
};
CancelCallback cancelCallback = consumerTag -> {
System.out.println(consumerTag+"消费者取消消息回调");
};
//手动应答
boolean autoAck = false;
channel.basicConsume(TASK_QUEUE_NAME,autoAck,deliverCallback,cancelCallback);
}
}
消费者2
public class Wroker04 {
public static final String TASK_QUEUE_NAME = "ack_queue";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
System.out.println("c2接收消息较长");
DeliverCallback deliverCallback = (consumerTag, message) -> {
// 模拟场景 业务处理多,睡眠1秒
SleepUtils.sleep(30);
System.out.println("接收到的消息:"+new String(message.getBody(),"utf-8"));
//手动应答
/**
* 参数1 :消息标记,每一个消息头上都带着一个消息标记
* 参数2:是否批量应答 true 表示批量
*/
channel.basicAck(message.getEnvelope().getDeliveryTag(),false);
};
CancelCallback cancelCallback = consumerTag -> {
System.out.println(consumerTag+"消费者取消消息回调");
};
//手动应答
boolean autoAck = false;
channel.basicConsume(TASK_QUEUE_NAME,autoAck,deliverCallback,cancelCallback);
}
}
睡眠工具类
public class SleepUtils {
public static void sleep(int second){
try {
Thread.sleep(1000*second);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
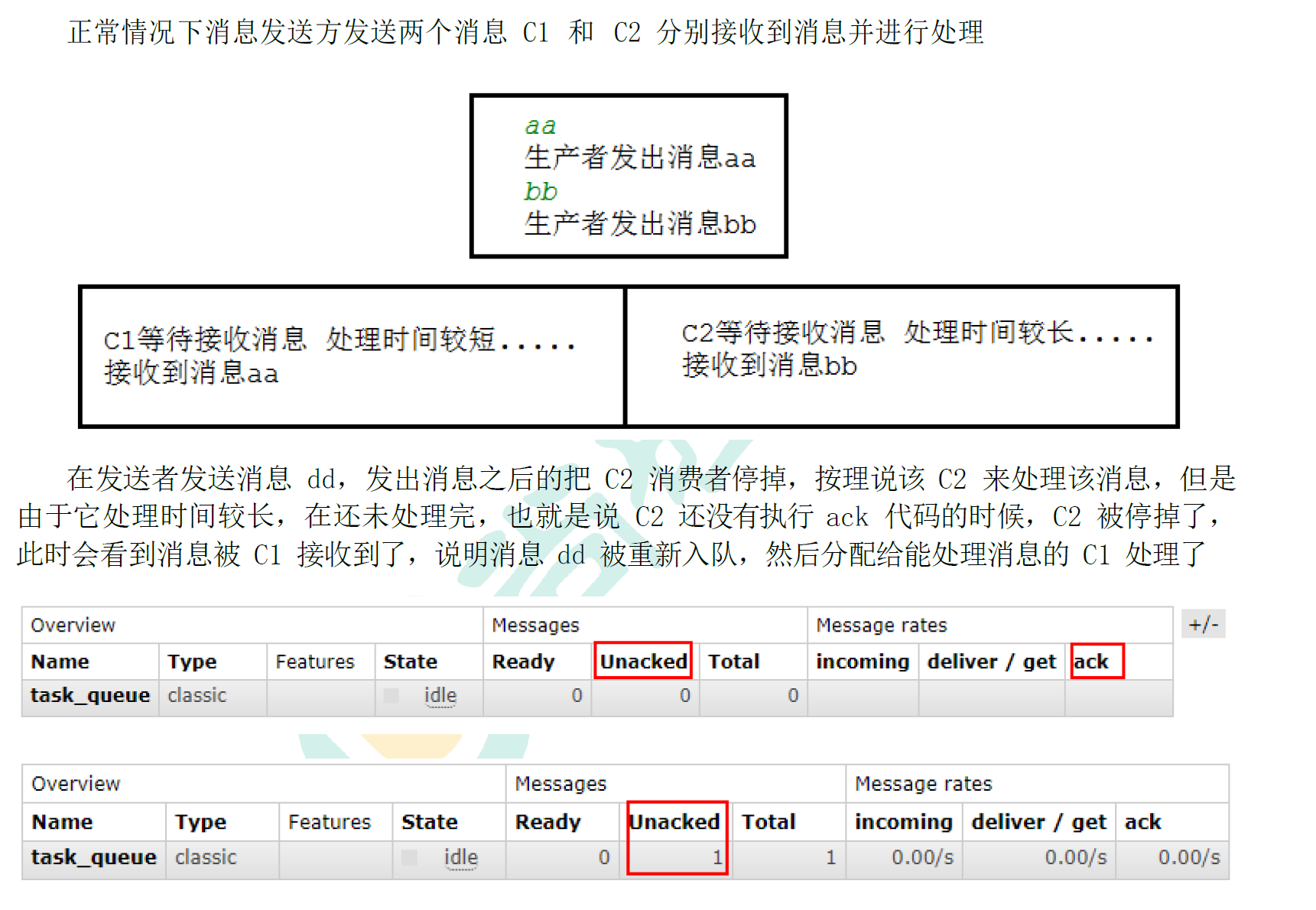
3.2.7 测试

3.3 RabbitMQ 持久化
3.3.1 概念
刚刚我们已经看到了如何处理任务不丢失的情况,但是如何保障当 RabbitMQ 服务停掉以后消息生产者发送过来的消息不丢失。默认情况下 RabbitMQ 退出或由于某种原因崩溃时,它忽视队列和消息,除非告知它不要这样做。确保消息不会丢失需要做两件事:我们需要将队列和消息都标记为持久化。
3.3.2 队列如何实现持久化

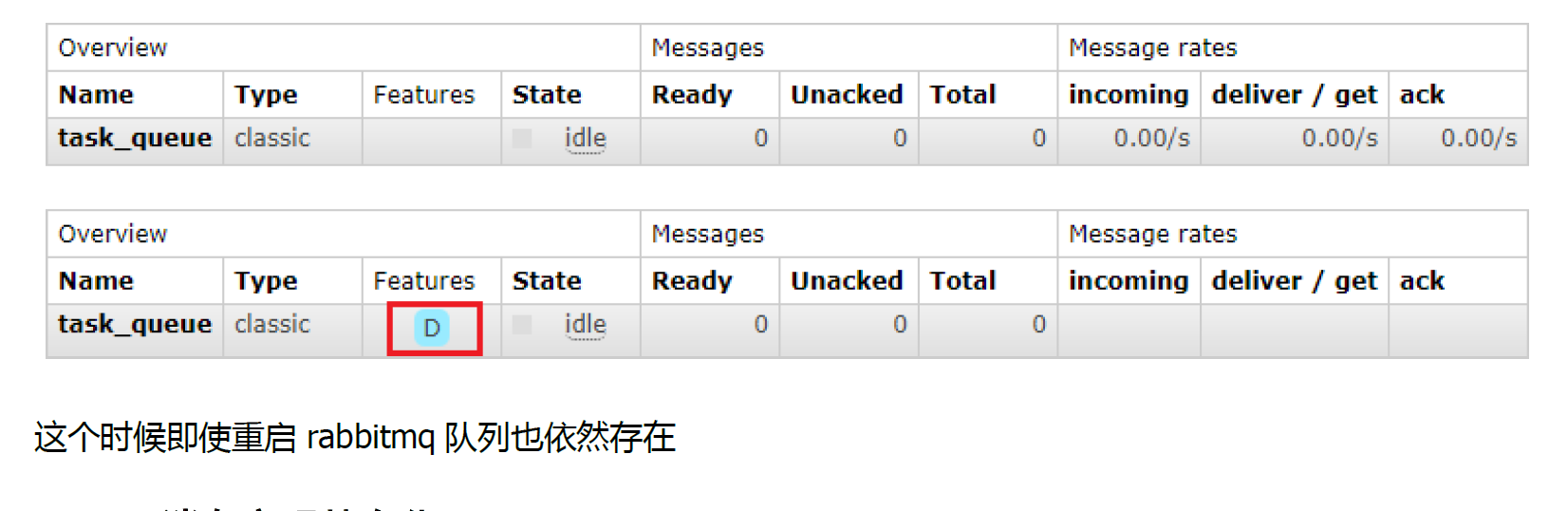
3.3.3 消息持久化
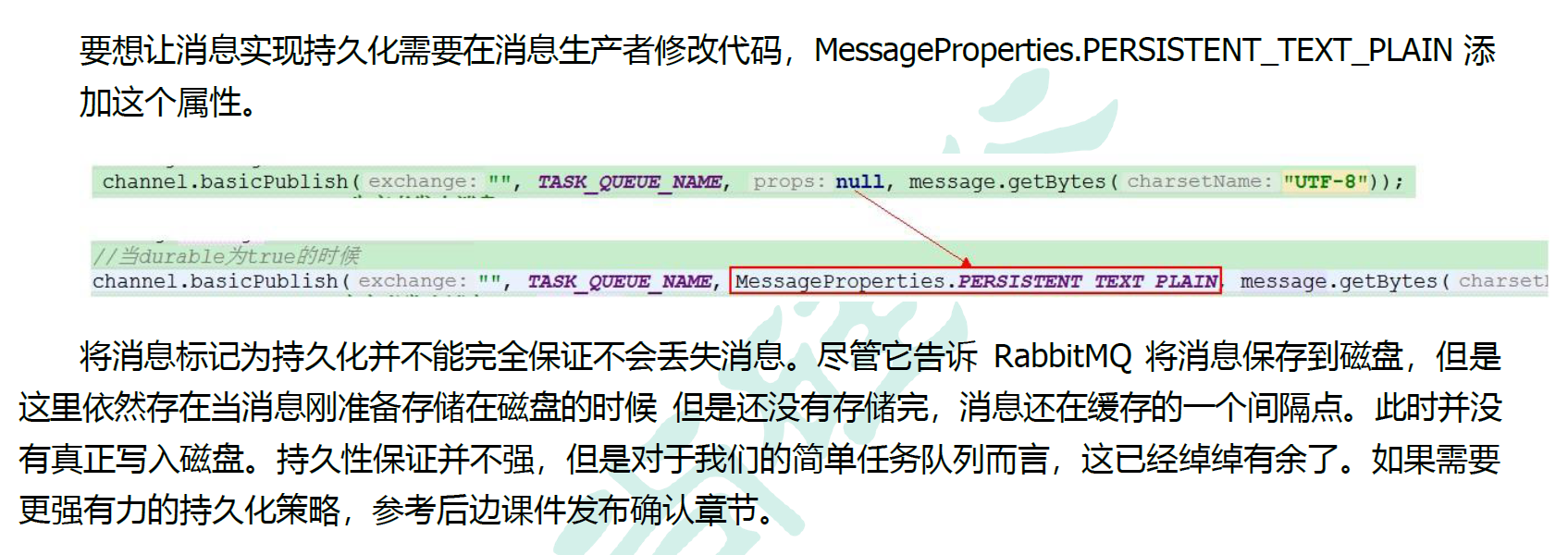
3.3.4 不公平分发

意思就是如果这个任务我还没有处理完或者我还没有应答你,你先别分配给我,我目前只能处理一个任务,然后 rabbitmq 就会把该任务分配给没有那么忙的那个空闲消费者,当然如果所有的消费者都没有完成手上任务,队列还在不停的添加新任务,队列有可能就会遇到队列被撑满的情况,这个时候就只能添加新的 worker 或者改变其他存储任务的策略。
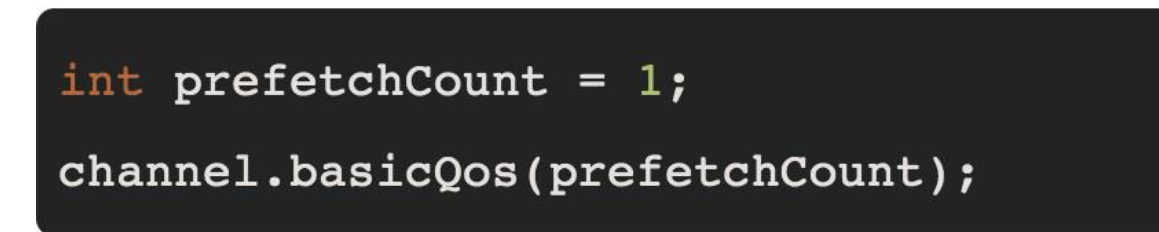
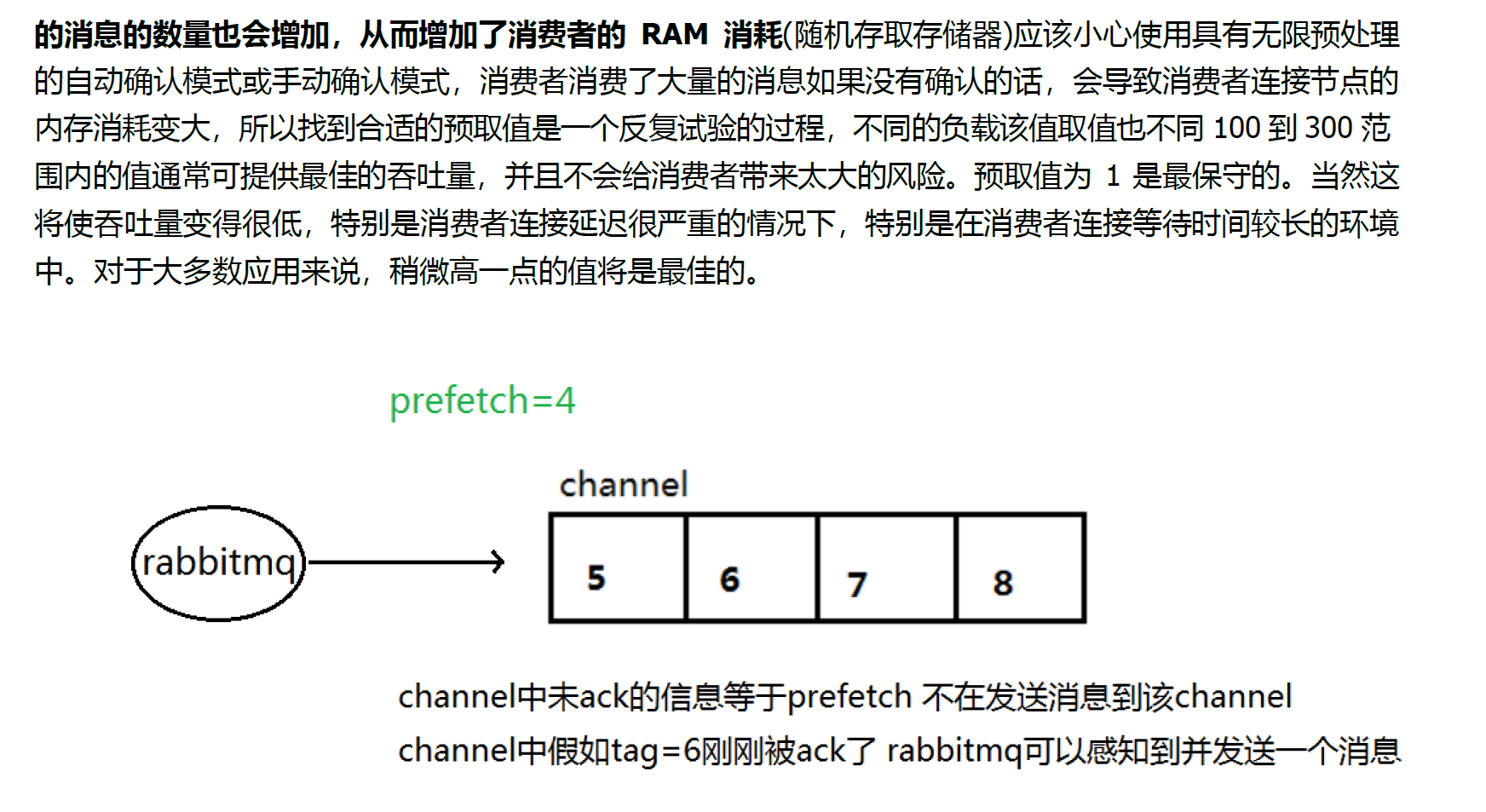
3.3.5 预取值

3.3.6 代码实现
其实改动很小,就一行代码。
public class Wroker03 {
public static final String TASK_QUEUE_NAME = "ack_queue";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
System.out.println("c1接收消息较短");
DeliverCallback deliverCallback = (consumerTag, message) -> {
// 模拟场景 业务处理多,睡眠1秒
SleepUtils.sleep(1);
System.out.println("接收到的消息:"+new String(message.getBody(),"utf-8"));
//手动应答
/**
* 参数1 :消息标记,每一个消息头上都带着一个消息标记
* 参数2:是否批量应答 true 表示批量
*/
channel.basicAck(message.getEnvelope().getDeliveryTag(),false);
};
CancelCallback cancelCallback = consumerTag -> {
System.out.println(consumerTag+"消费者取消消息回调");
};
//设置不公平分发 1 轮训分发 0 (默认)
// int prefetchCount = 1;
//预取值
int prefetchCount = 2;
channel.basicQos(prefetchCount);
//手动应答
boolean autoAck = false;
channel.basicConsume(TASK_QUEUE_NAME,autoAck,deliverCallback,cancelCallback);
}
}
public class Wroker04 {
public static final String TASK_QUEUE_NAME = "ack_queue";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
System.out.println("c2接收消息较长");
DeliverCallback deliverCallback = (consumerTag, message) -> {
// 模拟场景 业务处理多,睡眠1秒
SleepUtils.sleep(30);
System.out.println("接收到的消息:"+new String(message.getBody(),"utf-8"));
//手动应答
/**
* 参数1 :消息标记,每一个消息头上都带着一个消息标记
* 参数2:是否批量应答 true 表示批量
*/
channel.basicAck(message.getEnvelope().getDeliveryTag(),false);
};
CancelCallback cancelCallback = consumerTag -> {
System.out.println(consumerTag+"消费者取消消息回调");
};
//设置不公平分发 1 轮训分发 0 (默认)
// int prefetchCount = 1;
//预取值
int prefetchCount = 5;
channel.basicQos(prefetchCount);
//手动应答
boolean autoAck = false;
channel.basicConsume(TASK_QUEUE_NAME,autoAck,deliverCallback,cancelCallback);
}
}
轮训分发 设置属性为 0(默认),不公平分发设置属性为1,预取值按照自己设置。
4 发布确认
4.1 发布确认原理

4.2发布确认的策略
4.2.1 开启发布确认的方法

4.2.2 单个确认发布

//单个确认
public static void single() throws Exception {
Channel channel = RabbitMQUtils.getChannel();
//开启发布确认
channel.confirmSelect();
String queueName = UUID.randomUUID().toString();
channel.queueDeclare(queueName,true,false,false,null);
//开始时间
long begin = System.currentTimeMillis();
//批量发消息
for (int i = 0; i < MESSAGE_COUNT; i++) {
String message = i + " ";
channel.basicPublish("",queueName,null,message.getBytes(StandardCharsets.UTF_8));
//单个消息确认
boolean flag = channel.waitForConfirms();
if(flag){
System.out.println("消息发送成功");
}
}
//结束时间
long end = System.currentTimeMillis();
System.out.println("发布"+MESSAGE_COUNT+"个单独确认消息,耗时"+(end - begin)+"ms");
}
4.2.3 批量确认发布

//批量确认
public static void batch() throws Exception {
Channel channel = RabbitMQUtils.getChannel();
//开启发布确认
channel.confirmSelect();
String queueName = UUID.randomUUID().toString();
channel.queueDeclare(queueName,true,false,false,null);
//开始时间
long begin = System.currentTimeMillis();
//批量确认消息大小
int batchSize = 1000;
//批量发消息 批量发布确认
for (int i = 0; i < MESSAGE_COUNT; i++) {
String message = i + " ";
channel.basicPublish(" ",queueName,null,message.getBytes(StandardCharsets.UTF_8));
//判断达到100条消息的时候,批量确认一次
if( i % batchSize == 0 ){
//发布确认
channel.waitForConfirms();
}
}
//结束时间
long end = System.currentTimeMillis();
System.out.println("发布"+MESSAGE_COUNT+"个批量确认消息,耗时"+(end - begin)+"ms");
}
4.2.4 异步确认发布
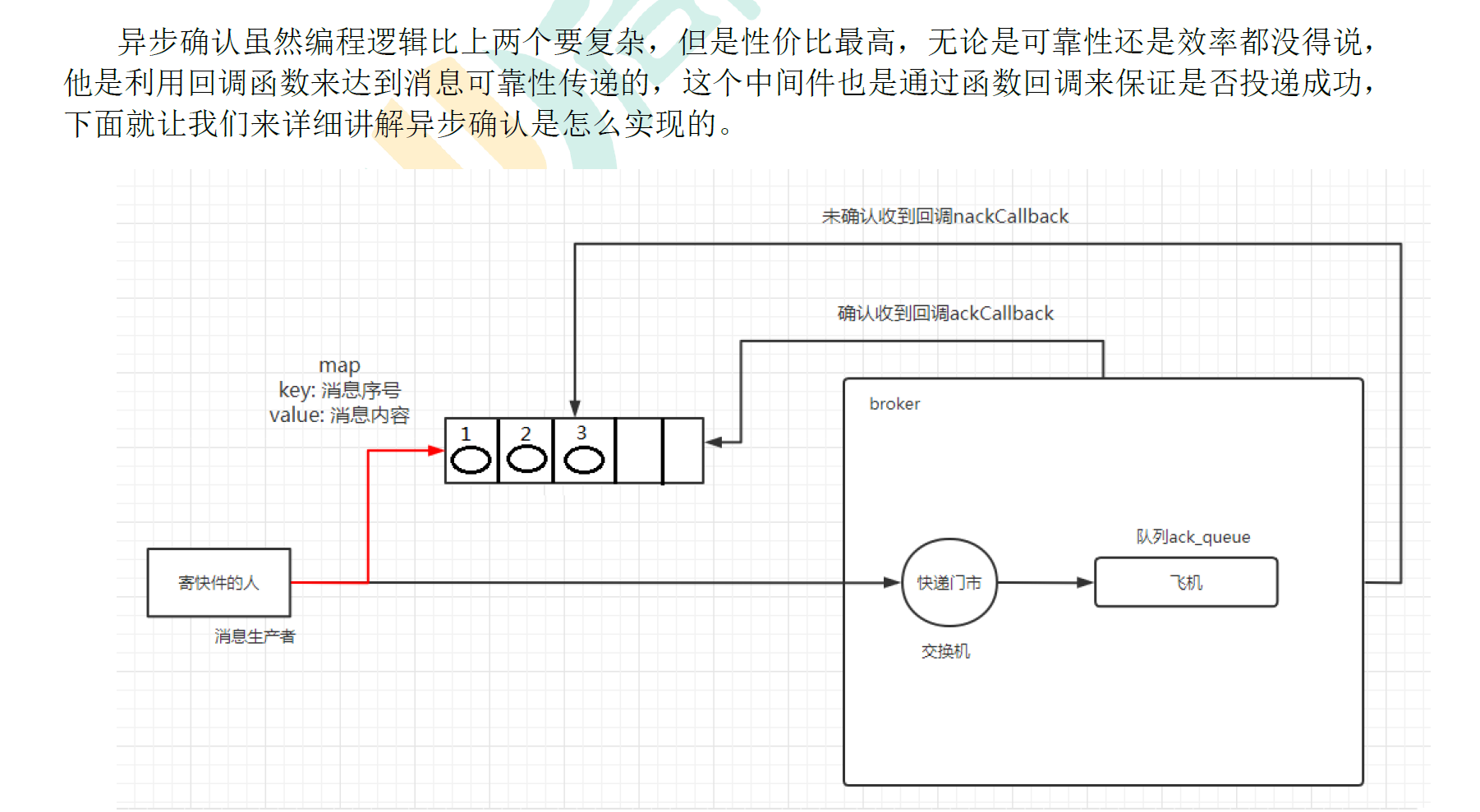
//异步批量确认
public static void async() throws Exception {
Channel channel = RabbitMQUtils.getChannel();
//开启发布确认
channel.confirmSelect();
String queueName = UUID.randomUUID().toString();
channel.queueDeclare(queueName,true,false,false,null);
/**
* 准备一个容器
* ConcurrentSkipListMap ---线程安全有序的一个哈希表,适用于高并发的情况下
* 1.轻松的将序号与消息进行关联
* 2.轻松批量删除条目 只要给到序号
* 3.支持高并发(多线程)
*/
ConcurrentSkipListMap<Long,String> outstandingConfirms = new ConcurrentSkipListMap<>();
//消息确认成功 回调函数
ConfirmCallback ackCallback = (deliveryTag, multiple) -> {
if(multiple){
//2.删除到已经确认的消息 剩下的就是未确认的消息
ConcurrentNavigableMap<Long,String> confimed = outstandingConfirms.headMap(deliveryTag);
confimed.clear();
}else {
outstandingConfirms.remove(deliveryTag);
}
System.out.println("确认的消息"+deliveryTag);
};
//消息失败 回调函数
ConfirmCallback nackCallback = (deliveryTag, multiple) -> {
System.out.println("未确认的消息"+deliveryTag);
};
//监听器 消息哪失败,消息哪成功
channel.addConfirmListener(ackCallback,nackCallback); //异步通知
//开始时间
long begin = System.currentTimeMillis();
for (int i = 0; i < MESSAGE_COUNT; i++) {
String message = "消息"+i;
channel.basicPublish("",queueName,null,message.getBytes(StandardCharsets.UTF_8));
//1.此处记录下所有要发送的消息 消息的总和
outstandingConfirms.put(channel.getNextPublishSeqNo(),message);
}
//结束时间
long end = System.currentTimeMillis();
System.out.println("发布"+MESSAGE_COUNT+"个异步发布确认消息,耗时"+(end - begin)+"ms");
}
4.2.5 如何处理异步未确认消息

4.2.6 三种发布确认速度对比

5 交换机


5.1 交换机
5.1.1 交换机概念
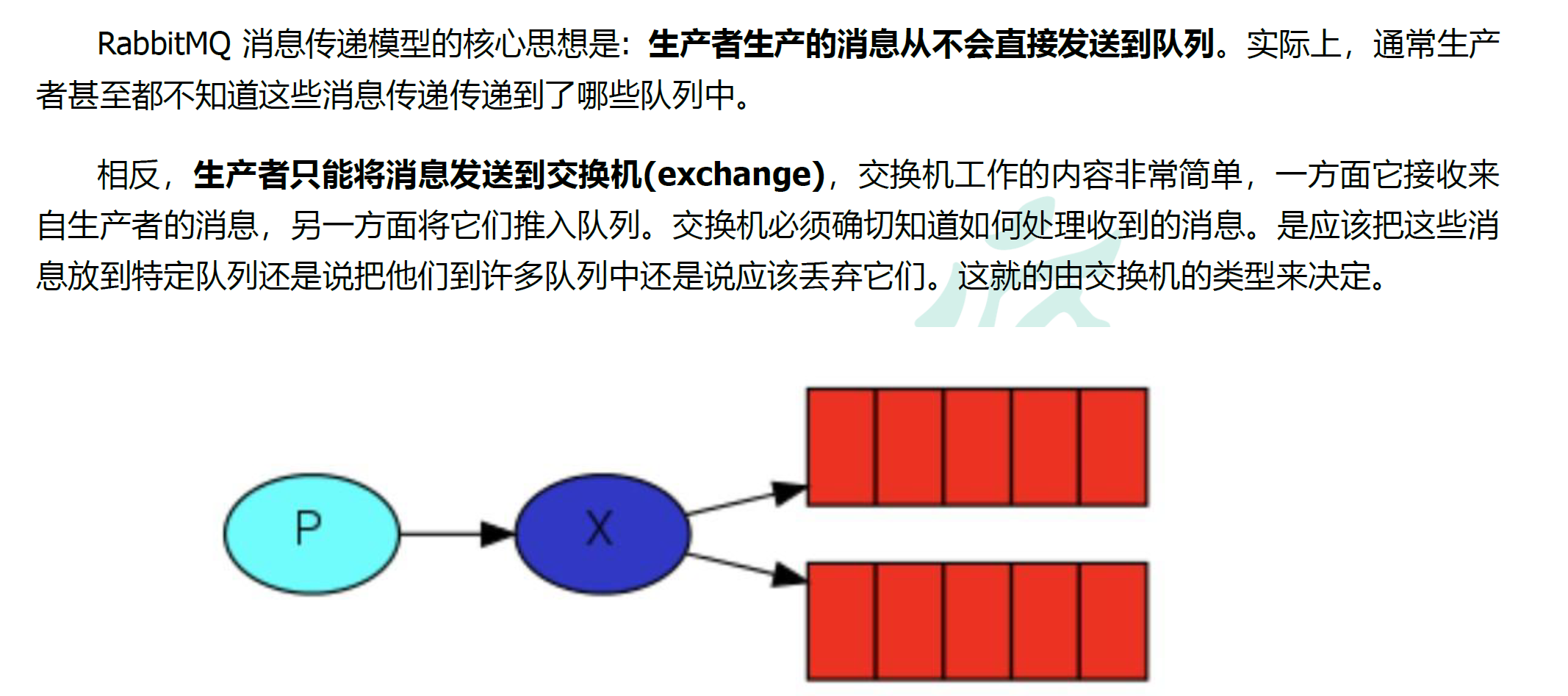
5.1.2 交换机类型

5.1.3 无名交换机

5.2 临时队列
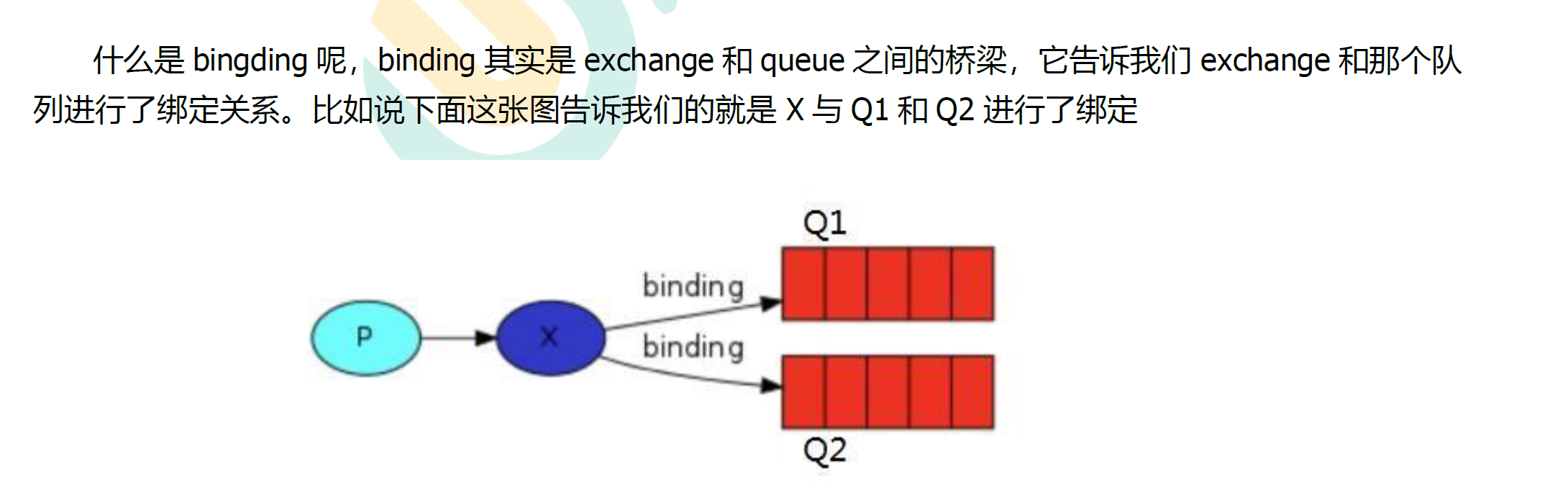
5.3 绑定
5.4 fanout(扇出)
5.4.1 fanout介绍
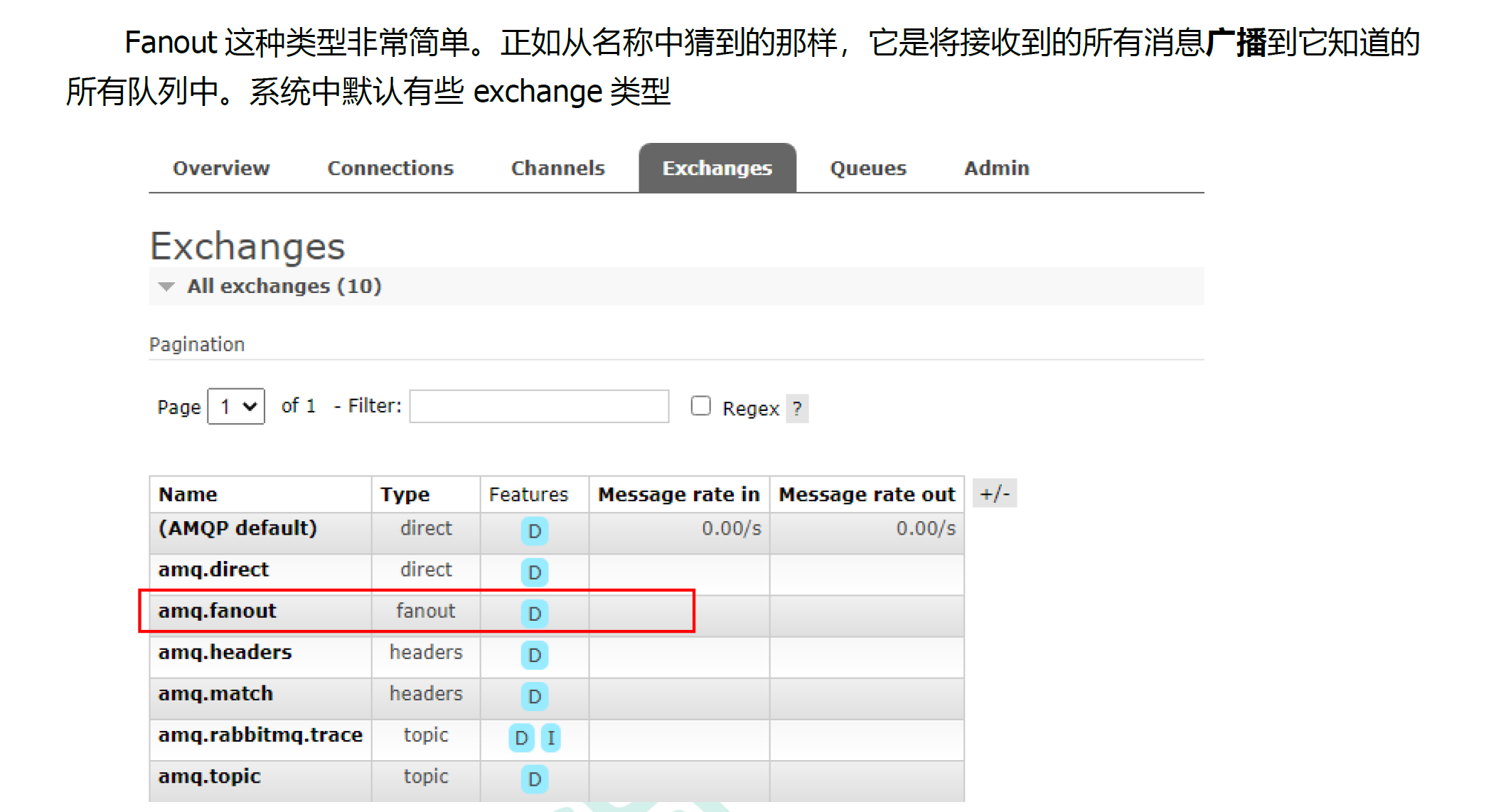
5.4.2 fanout实战
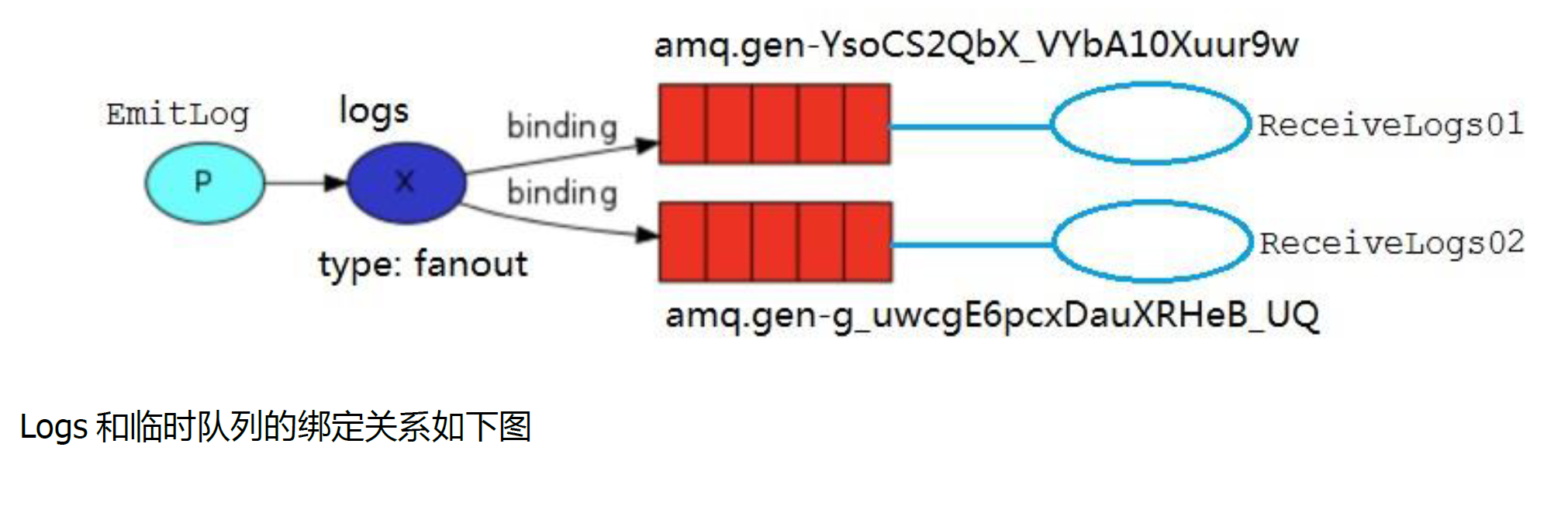
public class ReceiveLogs01 {
//交换机名称
public static final String EXCHANGE_NAME = "logs";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
//声明一个交换机
channel.exchangeDeclare(EXCHANGE_NAME,"fanout");
/**
* 生成一个临时队列,队列的名称是随机的
* 当消费者断开与队列的连接的时候,队列就自动删除
*/
String queueName = channel.queueDeclare().getQueue();
/**
* 绑定交换机与队列
*/
channel.queueBind(queueName,EXCHANGE_NAME,"");
System.out.println("等待接收消息,把接收到消息打印在屏幕上。。。。。");
//接收消息
DeliverCallback deliverCallback = (consumerTag, message) -> {
System.out.println("01控制台打印接收到的消息:"+new String(message.getBody(),"UTF-8"));
};
//取消消息
CancelCallback cancelCallback = consumerTag -> {
};
channel.basicConsume(queueName,true,deliverCallback,cancelCallback);
}
}
public class ReceiveLogs02 {
//交换机名称
public static final String EXCHANGE_NAME = "logs";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
//声明一个交换机
channel.exchangeDeclare(EXCHANGE_NAME,"fanout");
/**
* 生成一个临时队列,队列的名称是随机的
* 当消费者断开与队列的连接的时候,队列就自动删除
*/
String queueName = channel.queueDeclare().getQueue();
/**
* 绑定交换机与队列
*/
channel.queueBind(queueName,EXCHANGE_NAME,"");
System.out.println("等待接收消息,把接收到消息打印在屏幕上。。。。。");
//接收消息
DeliverCallback deliverCallback = (consumerTag, message) -> {
System.out.println("02控制台打印接收到的消息:"+new String(message.getBody(),"UTF-8"));
};
//取消消息
CancelCallback cancelCallback = consumerTag -> {
};
channel.basicConsume(queueName,true,deliverCallback,cancelCallback);
}
}
public class EmitLog {
//交换机名称
public static final String EXCHANGE_NAME = "logs";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
Scanner scanner = new Scanner(System.in);
while(scanner.hasNext()){
String message = scanner.next();
channel.basicPublish(EXCHANGE_NAME,"",null,message.getBytes(StandardCharsets.UTF_8));
System.out.println("生产者发送消息:"+ message);
}
}
}
5.5 Direct exchange
5.5.1 回顾

5.5.2 Direct exchange 介绍

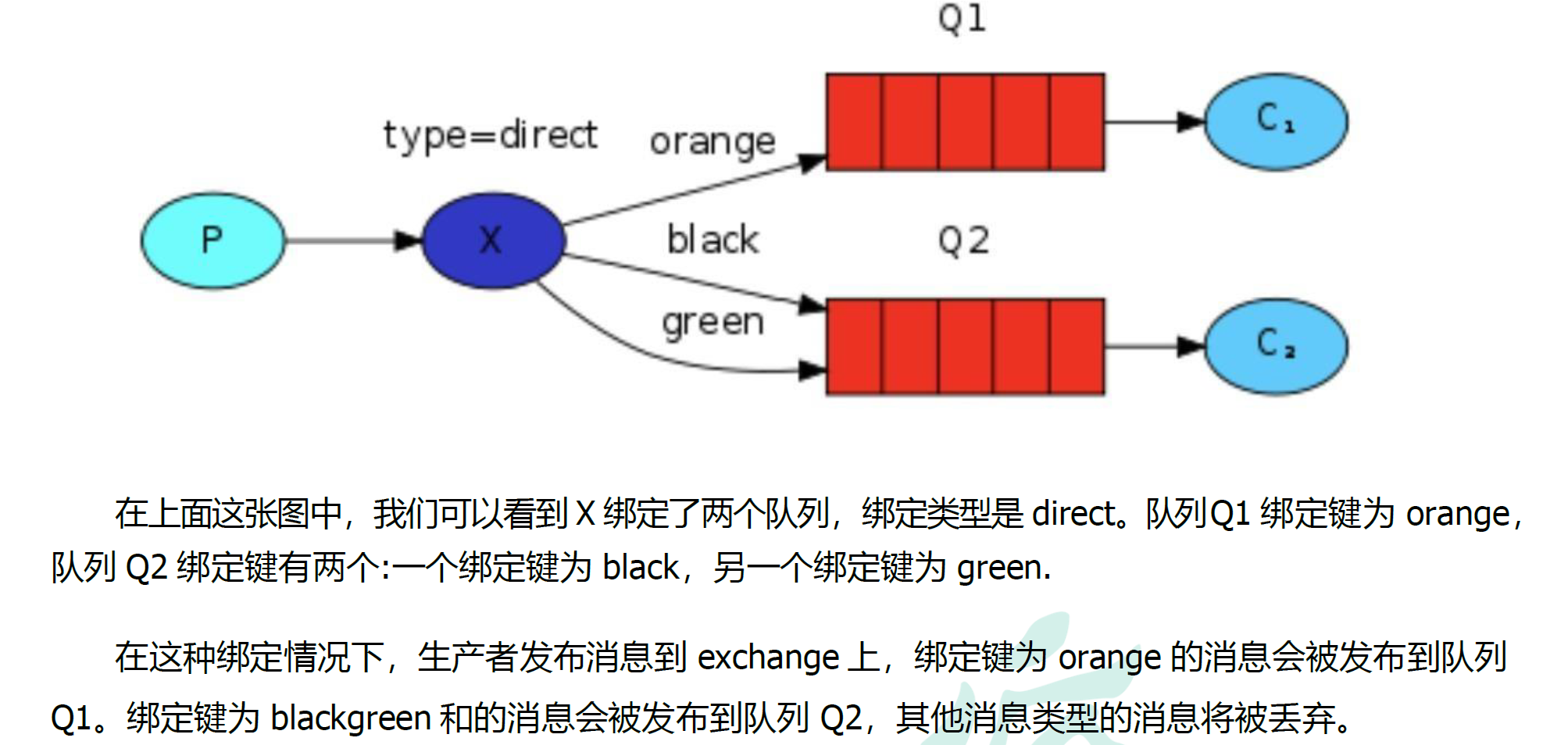
5.5.3 多重绑定
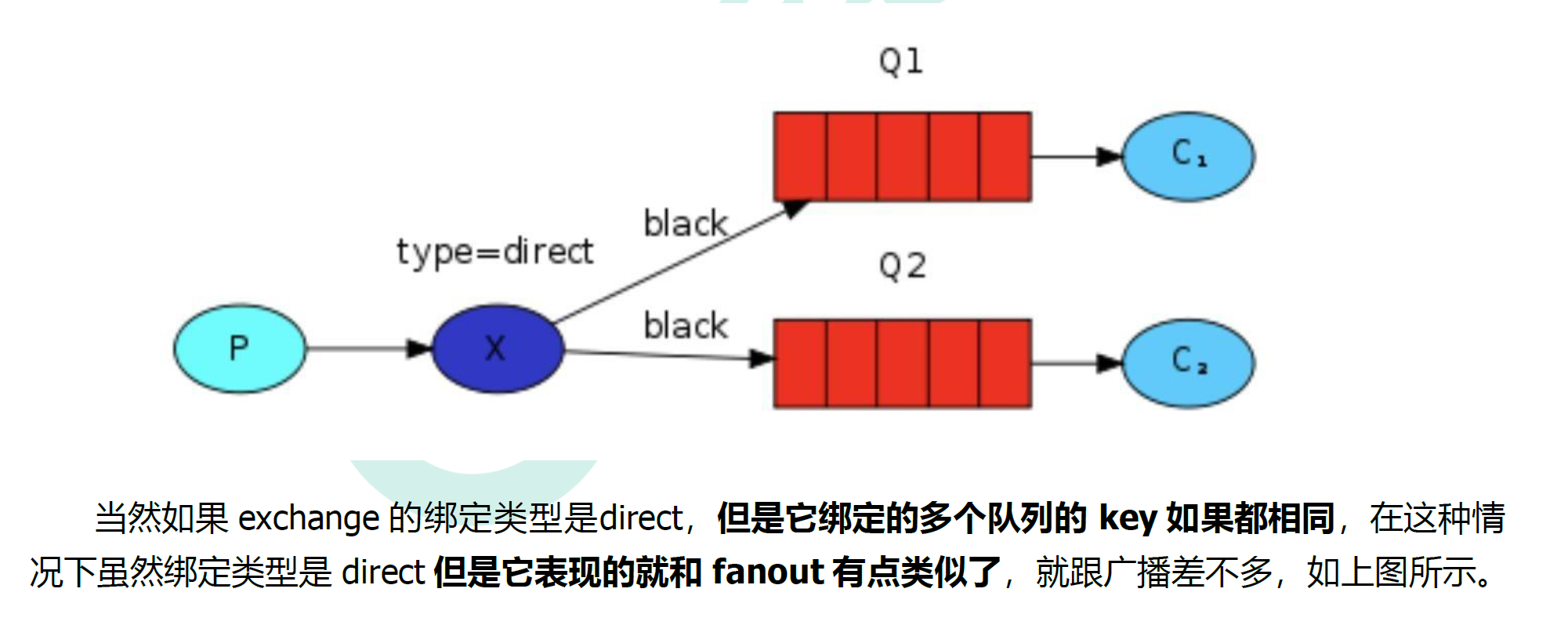
5.5.4 实战
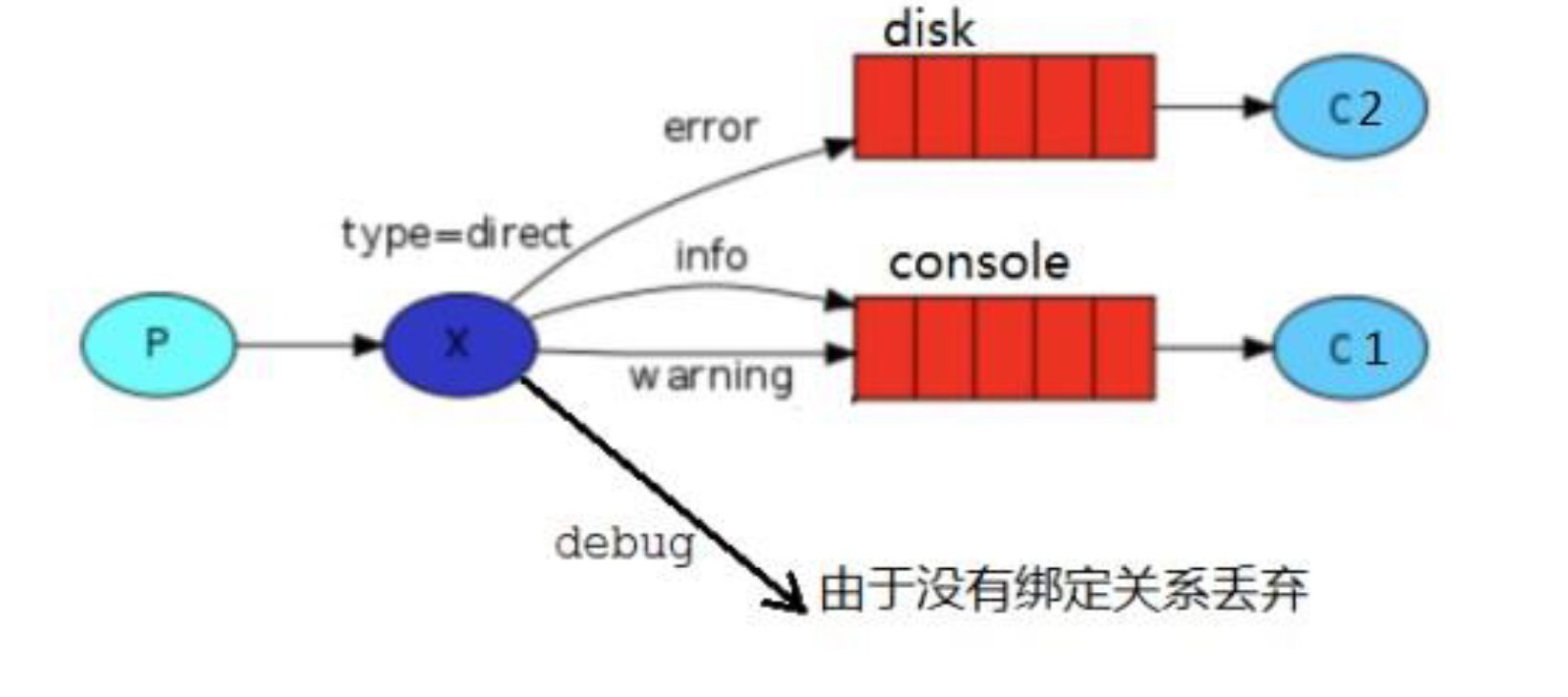

public class ReceiveLogsDirect01 {
//交换机名称
public static final String EXCHANGE_NAME = "direct_logs";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
//声明一个交换机
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.DIRECT);
//声明一个队列
channel.queueDeclare("console",false,false,false,null);
//绑定
channel.queueBind("console",EXCHANGE_NAME,"info");
channel.queueBind("console",EXCHANGE_NAME,"warning");
//接收消息
DeliverCallback deliverCallback = (consumerTag, message) -> {
System.out.println("01控制台打印接收到的消息:"+new String(message.getBody(),"UTF-8"));
};
//取消消息
CancelCallback cancelCallback = consumerTag -> {
};
channel.basicConsume("console",true,deliverCallback,cancelCallback);
}
}
public class ReceiveLogsDirect02 {
//交换机名称
public static final String EXCHANGE_NAME = "direct_logs";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
//声明一个交换机
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.DIRECT);
//声明一个队列
channel.queueDeclare("disk",false,false,false,null);
//绑定
channel.queueBind("disk",EXCHANGE_NAME,"error");
//接收消息
DeliverCallback deliverCallback = (consumerTag, message) -> {
System.out.println("02控制台打印接收到的消息:"+new String(message.getBody(),"UTF-8"));
};
//取消消息
CancelCallback cancelCallback = consumerTag -> {
};
channel.basicConsume("disk",true,deliverCallback,cancelCallback);
}
}
public class DirectLogs {
//交换机名称
public static final String EXCHANGE_NAME = "direct_logs";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
Scanner scanner = new Scanner(System.in);
while(scanner.hasNext()){
String message = scanner.next();
channel.basicPublish(EXCHANGE_NAME,"warning",null,message.getBytes(StandardCharsets.UTF_8));
System.out.println("生产者发送消息:"+ message);
}
}
}
5.6 Topics
5.6.1 之前类型问题

5.6.2 Topic的要求

5.6.3 Topic匹配案例
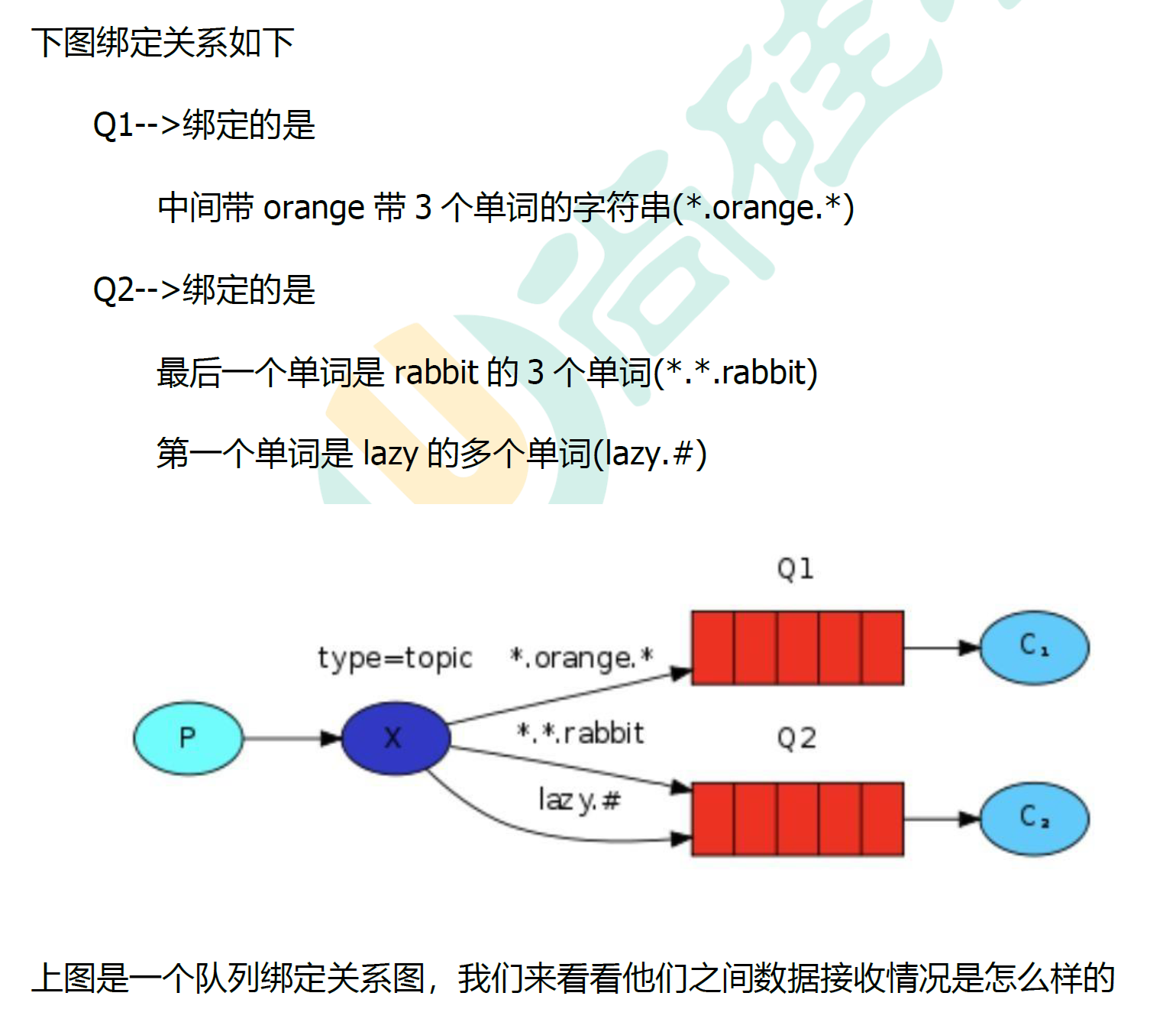


5.6.4 实战
public class EmitLogs {
public static final String EXCHANGE_NAME = "topic_logs";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
Map<String, String> bindingKeyMap = new HashMap<>();
bindingKeyMap.put("quick.orange.rabbit","被队列 Q1Q2 接收到");
bindingKeyMap.put("lazy.orange.elephant","被队列 Q1Q2 接收到");
bindingKeyMap.put("quick.orange.fox","被队列 Q1 接收到");
bindingKeyMap.put("lazy.brown.fox","被队列 Q2 接收到");
bindingKeyMap.put("lazy.pink.rabbit","虽然满足两个绑定但只被队列 Q2 接收一次");
bindingKeyMap.put("quick.brown.fox","不匹配任何绑定不会被任何队列接收到会被丢弃");
bindingKeyMap.put("quick.orange.male.rabbit","是四个单词不匹配任何绑定会被丢弃");
bindingKeyMap.put("lazy.orange.male.rabbit","是四个单词但匹配 Q2");
for (Map.Entry<String, String> bindentry : bindingKeyMap.entrySet()) {
String bindingkey = bindentry.getKey();
String message = bindentry.getValue();
channel.basicPublish(EXCHANGE_NAME,bindingkey,null,message.getBytes("UTF-8"));
System.out.println("生产者发出消息"+message);
}
}
}
public class ReceiveLogsTopic01 {
public static final String EXCHANGE_NAME = "topic_logs";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
//声明交换机
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.TOPIC);
//声明队列
String queueName = "Q1";
channel.queueDeclare(queueName,false,false,false,null);
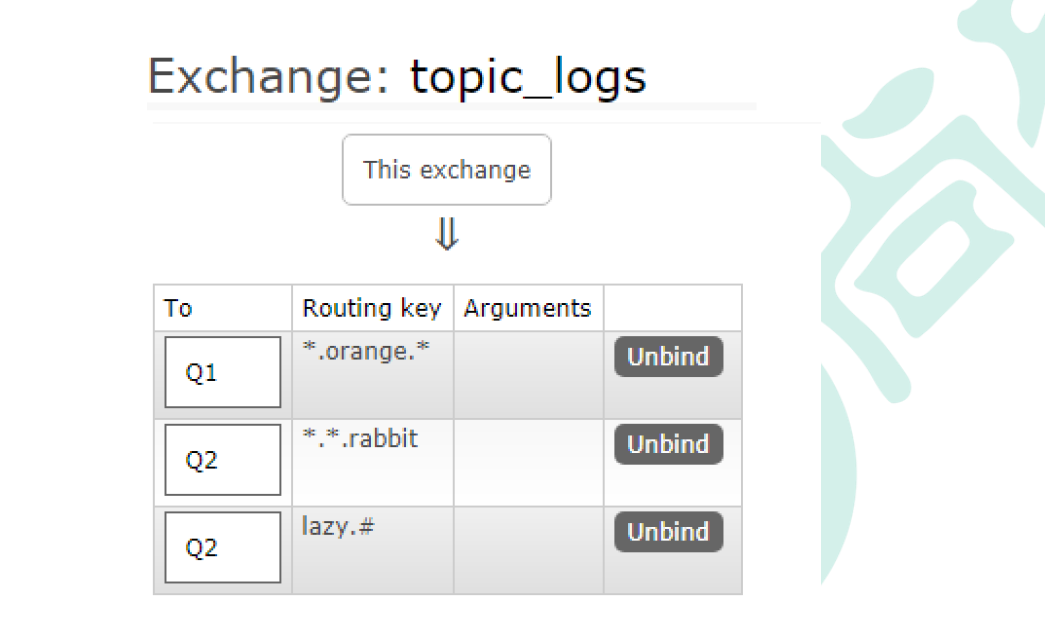
channel.queueBind(queueName,EXCHANGE_NAME,"*.orange.*");
System.out.println("等待接收消息......");
DeliverCallback deliverCallback = (consumerTag, message) ->{
System.out.println(new String(message.getBody(),"UTF-8"));
System.out.println("C1接收队列:"+queueName+"绑定键:"+message.getEnvelope().getRoutingKey());
};
CancelCallback cancelCallback = consumerTag -> {
};
//接收消息
channel.basicConsume(queueName,true,deliverCallback,cancelCallback);
}
}
public class ReceiveLogsTopic02 {
public static final String EXCHANGE_NAME = "topic_logs";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
//声明交换机
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.TOPIC);
//声明队列
String queueName = "Q2";
channel.queueDeclare(queueName,false,false,false,null);
channel.queueBind(queueName,EXCHANGE_NAME,"*.*.rabbit");
channel.queueBind(queueName,EXCHANGE_NAME,"lazy.#");
System.out.println("等待接收消息......");
DeliverCallback deliverCallback = (consumerTag, message) ->{
System.out.println(new String(message.getBody(),"UTF-8"));
System.out.println("C2接收队列:"+queueName+"绑定键:"+message.getEnvelope().getRoutingKey());
};
CancelCallback cancelCallback = consumerTag -> {
};
//接收消息
channel.basicConsume(queueName,true,deliverCallback,cancelCallback);
}
}
6 死信队列

6.2 死信的来源

6.3 死信实战
6.3.1 代码结构图
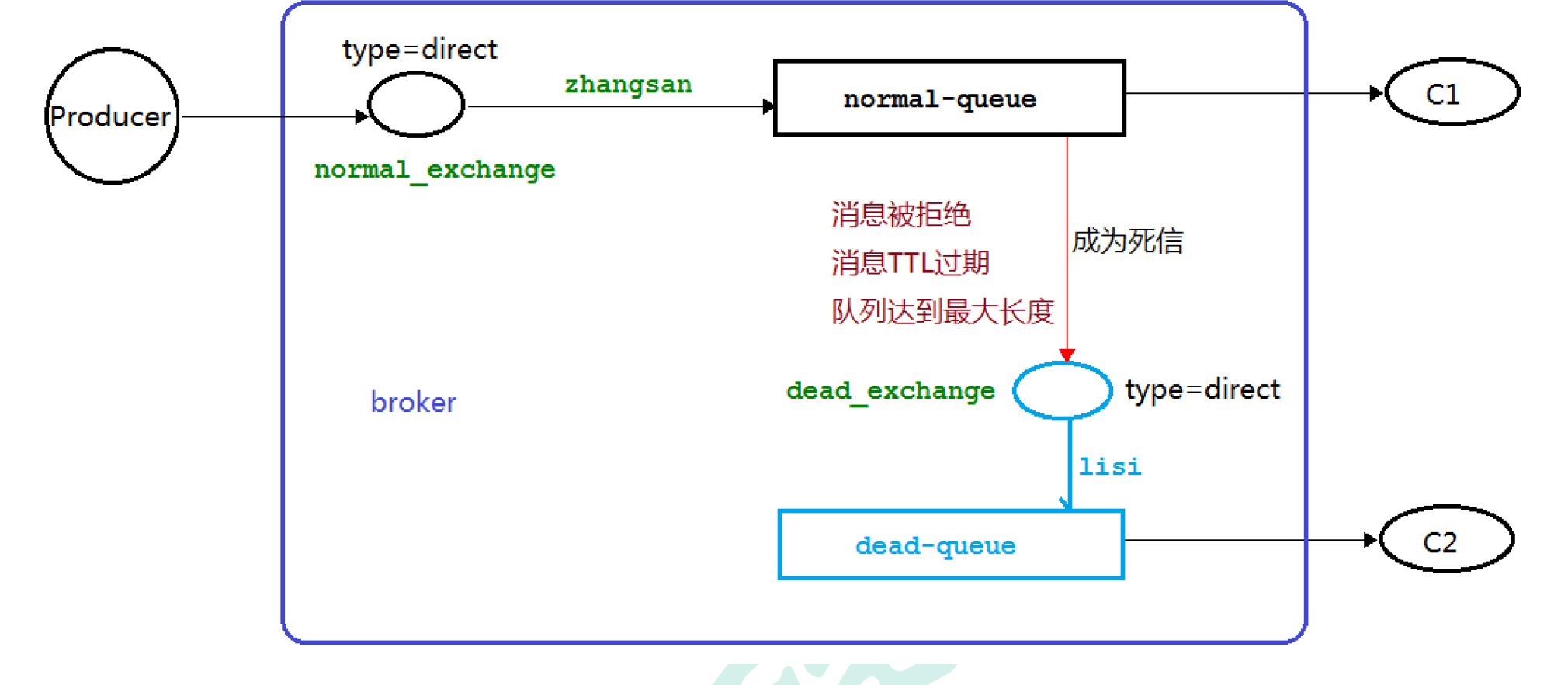
6.3.2 消息TTL 过期
消费者c1启动之后关闭,模拟其收不到消息。
public class Consumer01 {
//普通交换机及普通队列
public static final String NORMAL_EXCHANGE = "normal_exchange";
public static final String NORMAL_QUEUE = "normal_queue";
//死信交换机及死信队列
public static final String DEAD_EXCHANGE = "dead_exchange";
public static final String DEAD_QUEUE = "dead_queue";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
//声明交换机
channel.exchangeDeclare(NORMAL_EXCHANGE, BuiltinExchangeType.DIRECT);
channel.exchangeDeclare(DEAD_EXCHANGE,BuiltinExchangeType.DIRECT);
//声明普通队列
//设置参数,将普通消息超时转为死信消息
Map<String, Object> arguments = new HashMap<>();
/*设置过期时间 单位:ms
---在普通队列到死信交换机时可以设置过期时间;
在生产者发送消息的时候可以设置过期时间(常用)*/
// arguments.put("x-message-ttl",10000);
//普通队列消息到死信交换机
arguments.put("x-dead-letter-exchange",DEAD_EXCHANGE);
//设置死信RountingKEY 死信交换机与死信队列进行关联
arguments.put("x-dead-letter-routing-key","lisi");
channel.queueDeclare(NORMAL_QUEUE,false,false,false,arguments );
//声明死信队列
channel.queueDeclare(DEAD_QUEUE,false,false,false,null);
//绑定普通交换机与普通队列
channel.queueBind(NORMAL_QUEUE,NORMAL_EXCHANGE,"zhangsan");
//绑定死信交换机与死信队列
channel.queueBind(DEAD_QUEUE,DEAD_EXCHANGE,"lisi");
System.out.println("等待接收消息.....");
DeliverCallback deliverCallback = (consumerTag, message) -> {
System.out.println( "c1接收的消息是:"+ new String(message.getBody(),"UTF-8"));
}
};
CancelCallback cancelCallback = consumerTag -> {
};
}
}
public class Producer {
//普通交换机
public static final String NORMAL_EXCHANGE = "normal_exchange";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
// 死信消息,设置TTL时间
AMQP.BasicProperties properties = new AMQP.BasicProperties()
.builder().expiration("10000").build();
for (int i = 1; i < 11 ; i++) {
String message = "info" + i ;
channel.basicPublish(NORMAL_EXCHANGE,"zhangsan",null,message.getBytes());
}
}
}
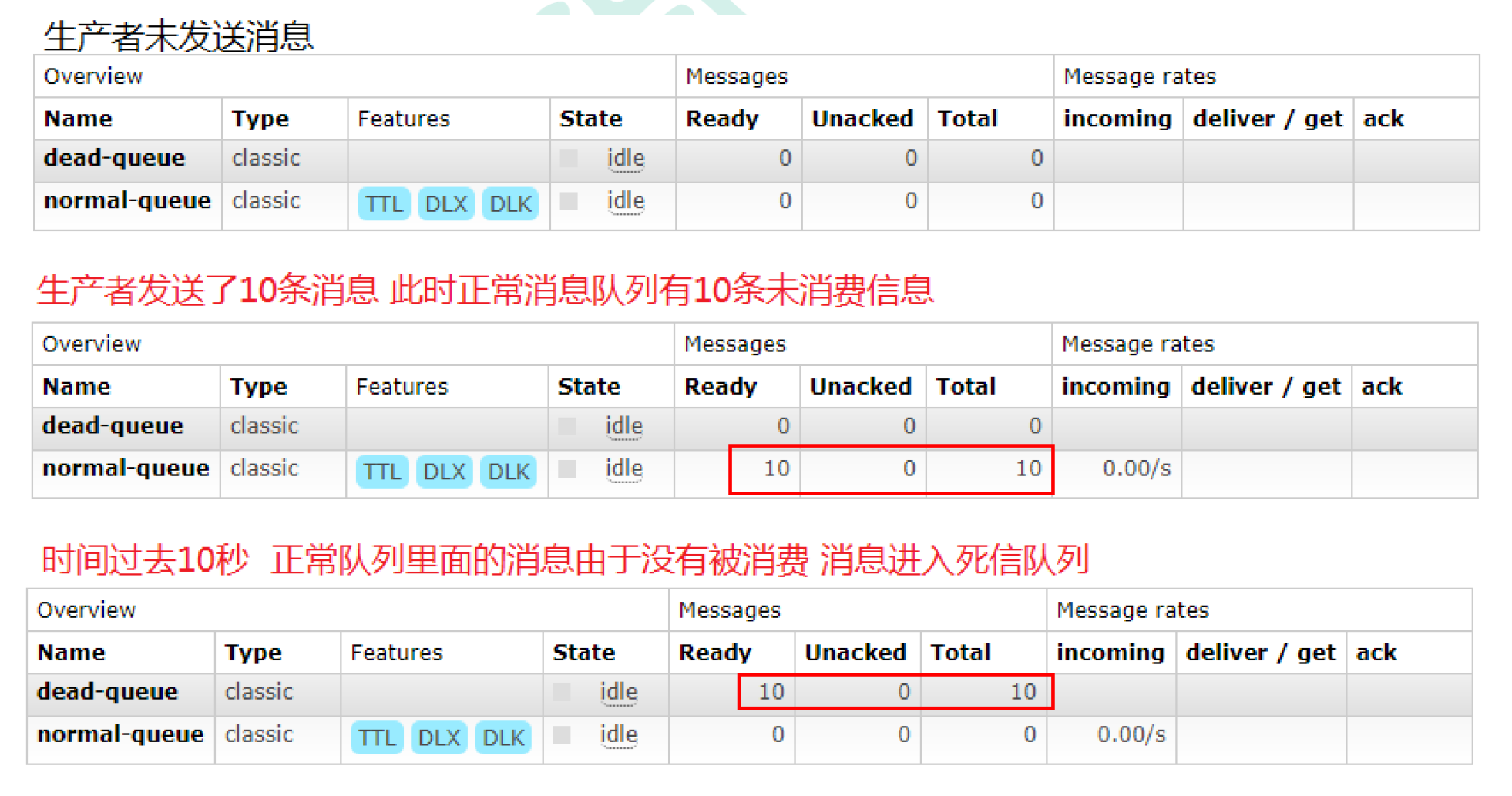
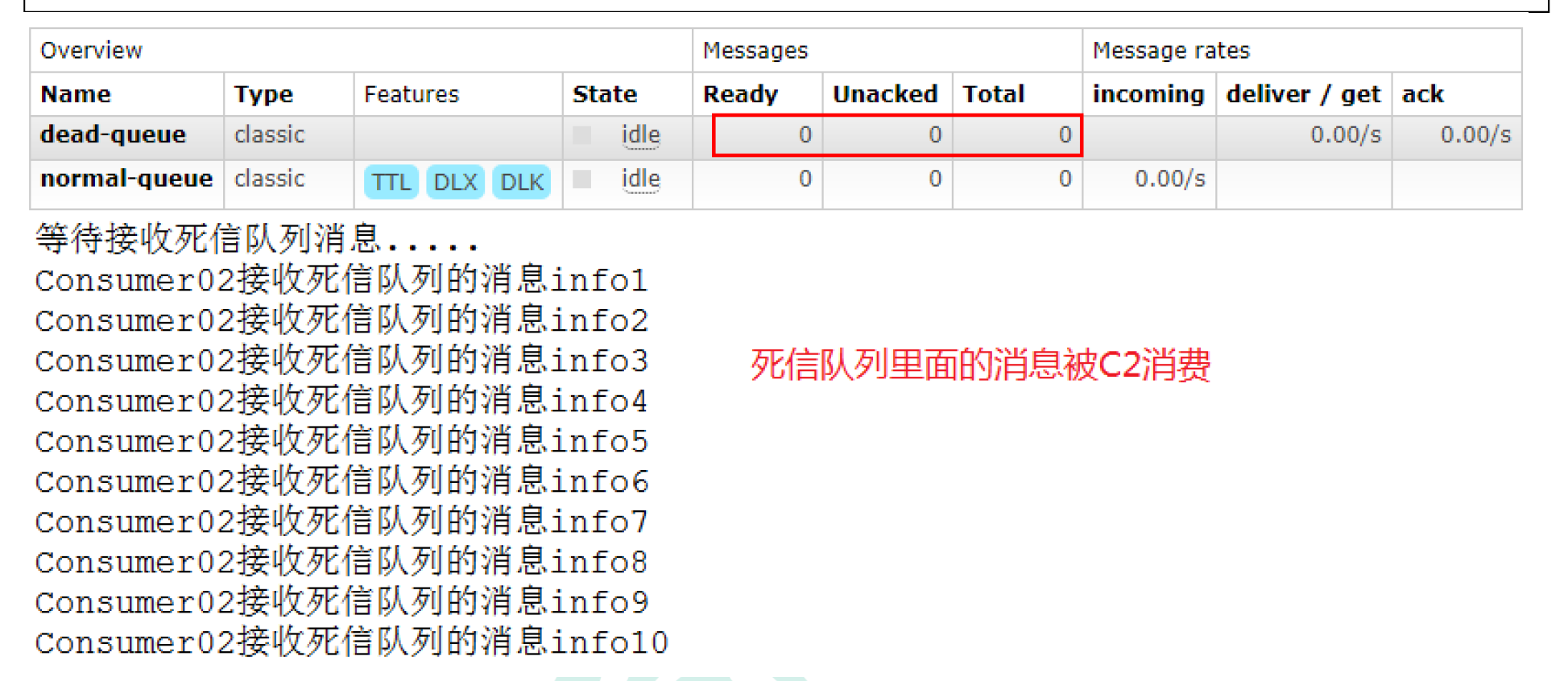
最后启动c2去消费掉死信队列中的消息。
public class Consumer02 {
//死信交换机及死信队列
public static final String DEAD_EXCHANGE = "dead_exchange";
public static final String DEAD_QUEUE = "dead_queue";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
System.out.println("等待接收消息.....");
DeliverCallback deliverCallback = (consumerTag, message) -> {
System.out.println( "c2接收的消息是:"+ new String(message.getBody(),"UTF-8"));
};
CancelCallback cancelCallback = consumerTag -> {
};
channel.basicConsume(DEAD_QUEUE,false,deliverCallback,cancelCallback);
}
}
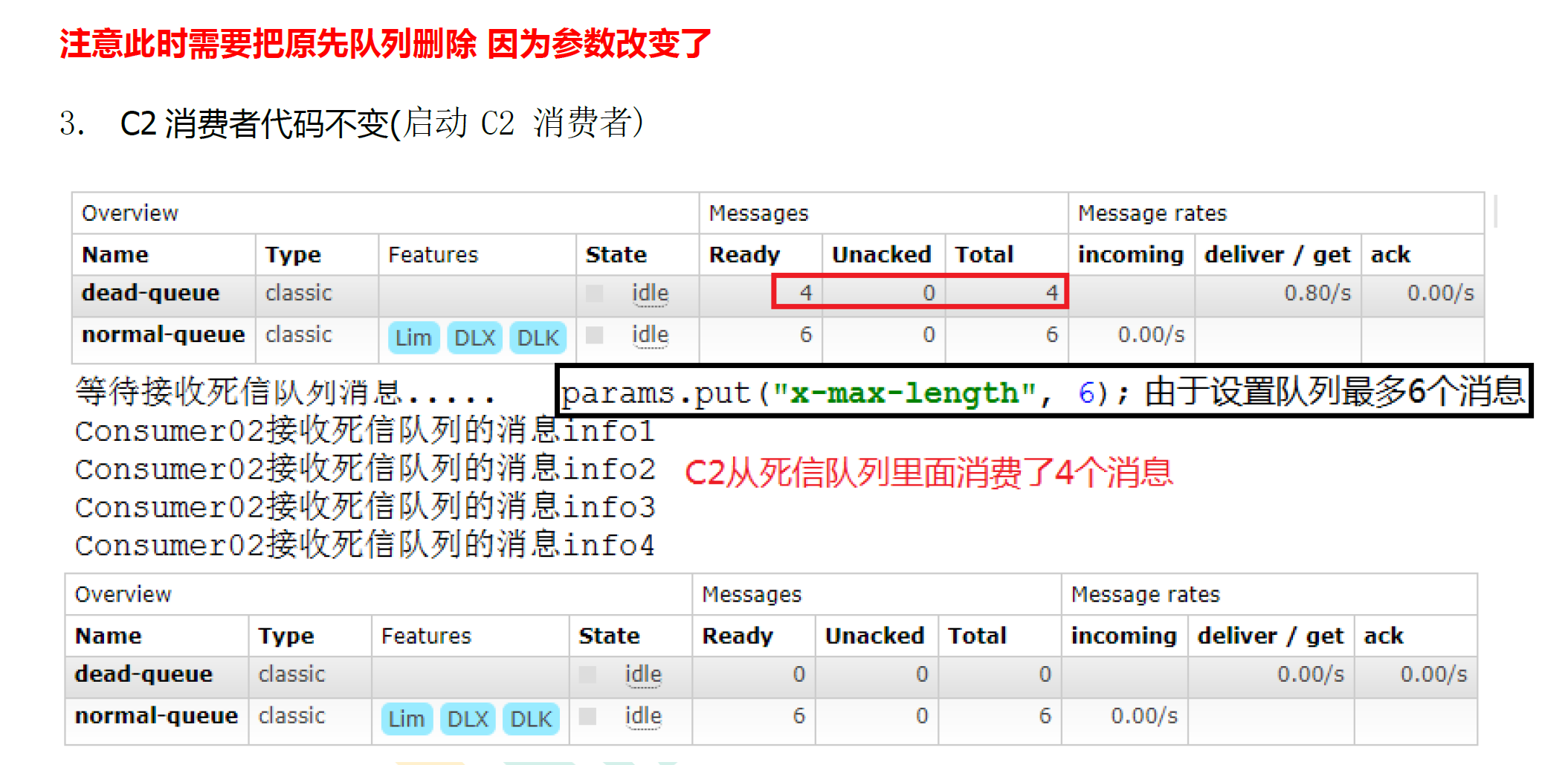
6.3.3 队列达到最大长度
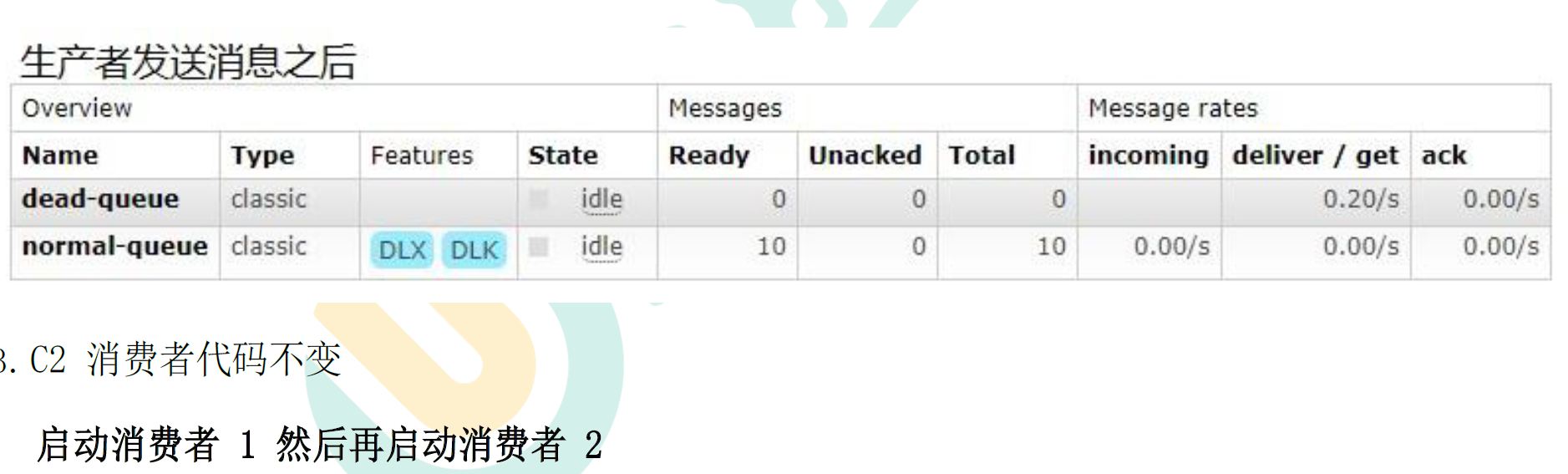
- c2代码不变
- 生产者去掉设置的过期时间
- c1添加代码

6.3.4 消息被拒
- 生产者代码不变
- C2代码不变
- C1添加拒绝方法
public class Consumer01 {
//普通交换机及普通队列
public static final String NORMAL_EXCHANGE = "normal_exchange";
public static final String NORMAL_QUEUE = "normal_queue";
//死信交换机及死信队列
public static final String DEAD_EXCHANGE = "dead_exchange";
public static final String DEAD_QUEUE = "dead_queue";
public static void main(String[] args) throws Exception {
Channel channel = RabbitMQUtils.getChannel();
//声明交换机
channel.exchangeDeclare(NORMAL_EXCHANGE, BuiltinExchangeType.DIRECT);
channel.exchangeDeclare(DEAD_EXCHANGE,BuiltinExchangeType.DIRECT);
//声明普通队列
//设置参数,将普通消息超时转为死信消息
Map<String, Object> arguments = new HashMap<>();
/*设置过期时间 单位:ms
---在普通队列到死信交换机时可以设置过期时间;
在生产者发送消息的时候可以设置过期时间(常用)*/
// arguments.put("x-message-ttl",10000);
//普通队列消息到死信交换机
arguments.put("x-dead-letter-exchange",DEAD_EXCHANGE);
//设置死信RountingKEY 死信交换机与死信队列进行关联
arguments.put("x-dead-letter-routing-key","lisi");
//设置正常队列的长度的限制
arguments.put("x-max-length",6);
channel.queueDeclare(NORMAL_QUEUE,false,false,false,arguments );
//声明死信队列
channel.queueDeclare(DEAD_QUEUE,false,false,false,null);
//绑定普通交换机与普通队列
channel.queueBind(NORMAL_QUEUE,NORMAL_EXCHANGE,"zhangsan");
//绑定死信交换机与死信队列
channel.queueBind(DEAD_QUEUE,DEAD_EXCHANGE,"lisi");
System.out.println("等待接收消息.....");
DeliverCallback deliverCallback = (consumerTag, message) -> {
// System.out.println( "c1接收的消息是:"+ new String(message.getBody(),"UTF-8"));
//设置拒绝
String msg = new String(message.getBody(), "UTF-8");
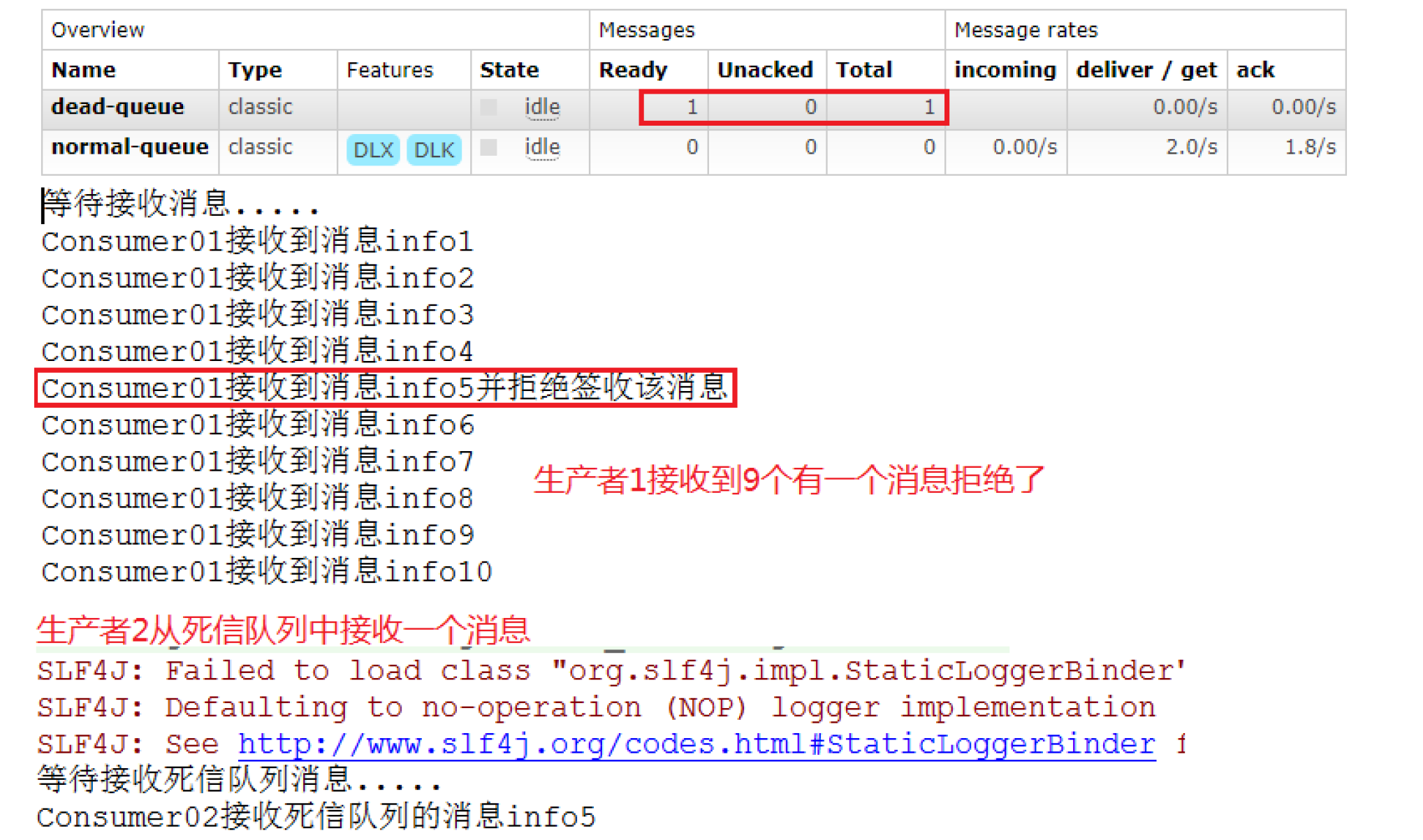
if(msg.equals("info5")){
System.out.println("c1接收的消息是:" +msg+":此消息是被c1拒接的");
channel.basicReject(message.getEnvelope().getDeliveryTag(),false);
}else {
System.out.println("c1接收的消息是:"+msg);
channel.basicAck(message.getEnvelope().getDeliveryTag(),false);
}
};
CancelCallback cancelCallback = consumerTag -> {
};
//开启手动应答,否则自动应答不会存在拒绝
channel.basicConsume(NORMAL_QUEUE,true,deliverCallback,cancelCallback);
}
}
7 延迟队列
7.1 延迟队列概念
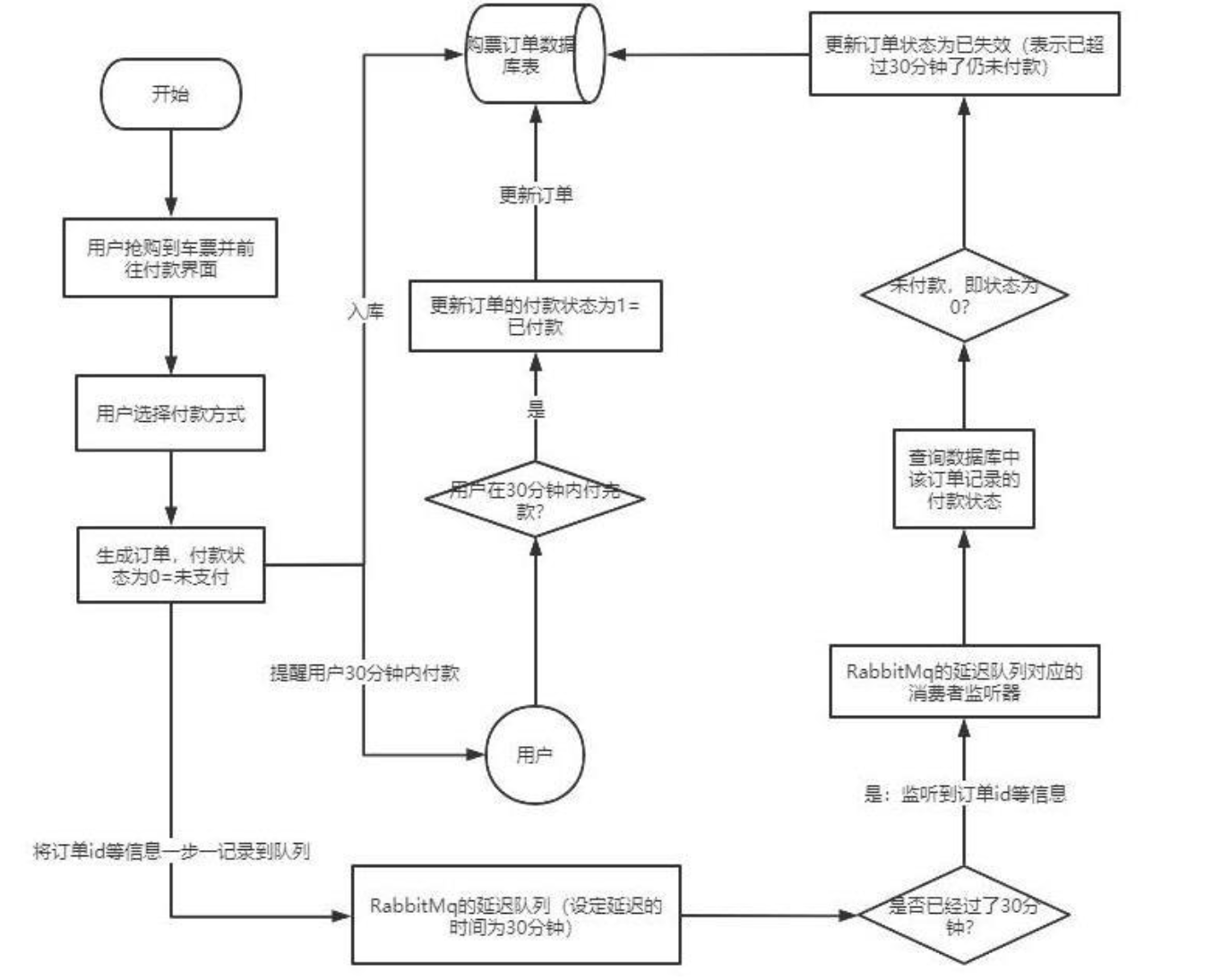
延时队列,队列内部是有序的,最重要的特性就体现在它的延时属性上,延时队列中的元素是希望在指定时间到了以后或之前取出和处理,简单来说,延时队列就是用来存放需要在指定时间被处理的元素的队列。
7.2 延迟队列使用场景
- 订单在十分钟之内未支付则自动取消
- 新创建的店铺,如果在十天内都没有上传过商品,则自动发送消息提醒。
- 用户注册成功后,如果三天内没有登陆则进行短信提醒。
- 用户发起退款,如果三天内没有得到处理则通知相关运营人员。
- 预定会议后,需要在预定的时间点前十分钟通知各个与会人员参加会议

7.3 RabbitMQ中的TTL
TTL 是什么呢?TTL 是 RabbitMQ 中一个消息或者队列的属性,表明一条消息或者该队列中的所有消息的最大存活时间,单位是毫秒。换句话说,如果一条消息设置了 TTL 属性或者进入了设置TTL 属性的队列,那么这条消息如果在TTL 设置的时间内没有被消费,则会成为"死信"。如果同时配置了队列的TTL 和消息的TTL,那么较小的那个值将会被使用,有两种方式设置 TTL。
7.3.1 消息设置TTL

7.3.2 队列设置TTL

7.3.3 两者的区别

7.4 整合Springboot
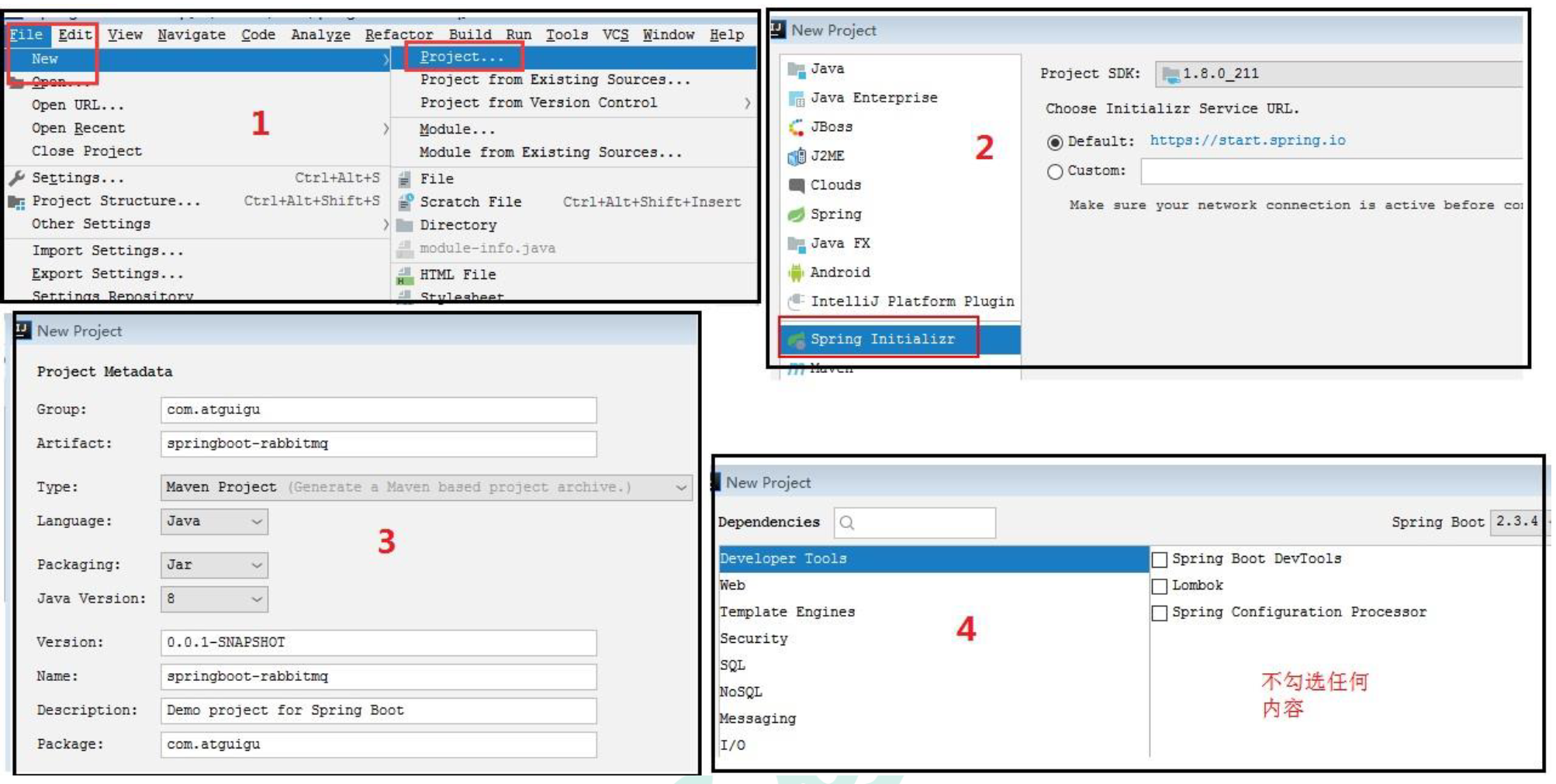
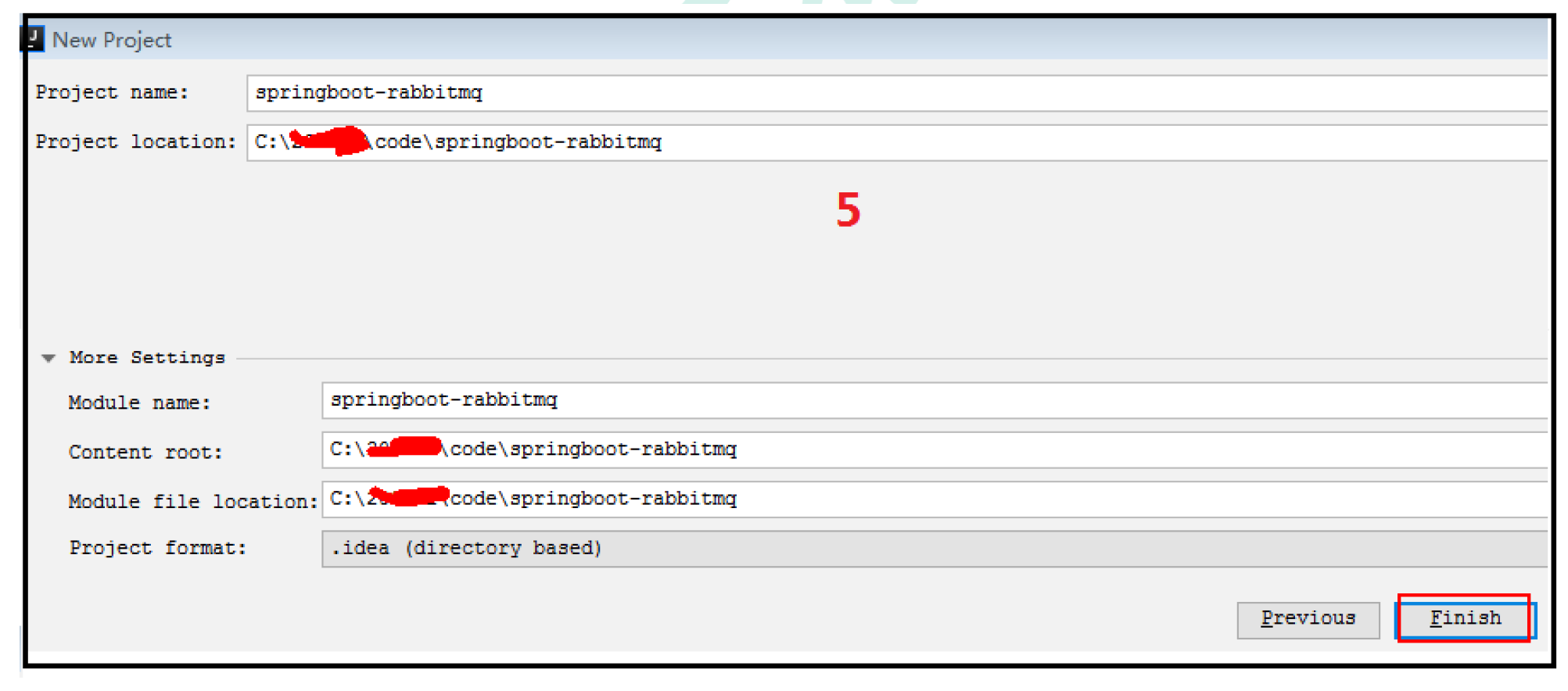
7.4.1 创建项目
7.4.2 添加依赖
<dependencies>
<!--RabbitMQ 依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<!--swagger-->
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.9.2</version>
</dependency>
<!--RabbitMQ 测试依赖-->
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
7.4.3 修改配置文件
Spring.mvc.pathmatch.matching-strategy=ant_path_matcher
spring.rabbitmq.host=192.168.119.100
spring.rabbitmq.port=5672
spring.rabbitmq.username=admin
spring.rabbitmq.password=123
7.4.4 添加swagger配置类
@Configuration
@EnableSwagger2
public class SwaggerConfig {
@Bean
public Docket webApiConfig(){
return new Docket(DocumentationType.SWAGGER_2)
.groupName("webApi")
.apiInfo(webApiInfo())
.select()
.build();
}
private ApiInfo webApiInfo(){
return new ApiInfoBuilder()
.title("rabbitmq 接口文档")
.description("本文档描述了 rabbitmq 微服务接口定义")
.version("1.0")
.contact(new Contact("enjoy6288", "http://atguigu.com","1551388580@qq.com"))
.build();
}
}
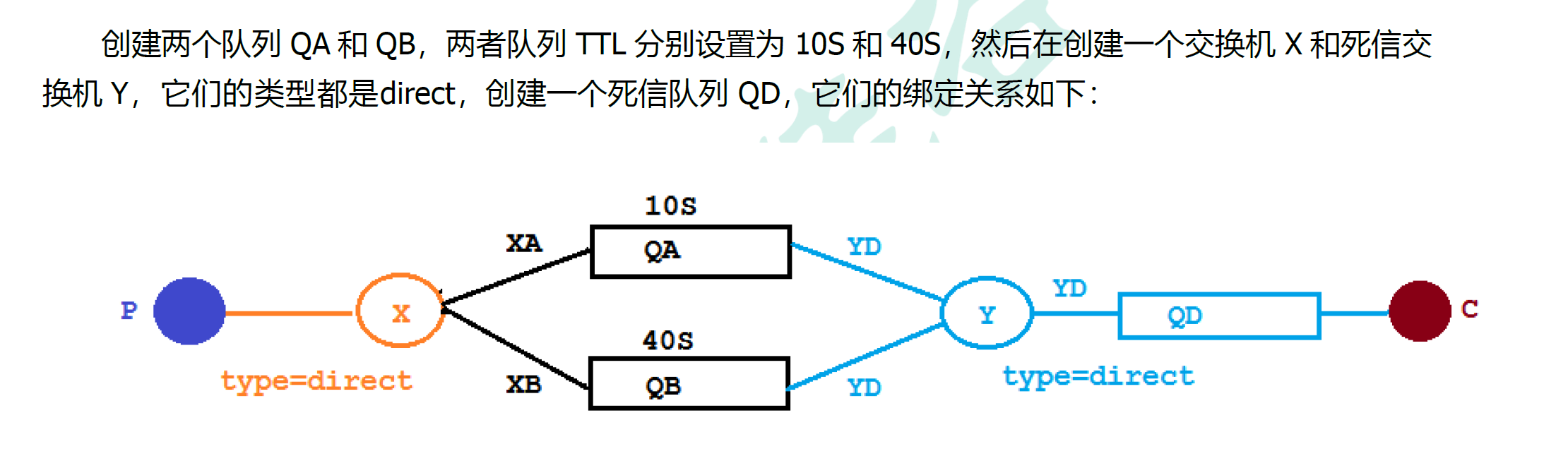
7.5 队列TTL
7.5.1 代码架构图
7.5.2 配置文件类
@Configuration
public class TtlQueueConfig {
//普通交换机
public static final String X_EXCHANGE = "X";
//死信交换机
public static final String Y_DEAD_EXCHANGE = "Y";
//普通队列
public static final String QUEUE_A = "QA";
public static final String QUEUE_B = "QB";
//死信队列
public static final String QUEUE_DEAD_D = "QD";
//使用注解方式声明交换机
@Bean("xExchange")
public DirectExchange xExchange(){
return new DirectExchange(X_EXCHANGE);
}
@Bean("yExchange")
public DirectExchange yExchange(){
return new DirectExchange(Y_DEAD_EXCHANGE);
}
@Bean("queueA")
public Queue queueA(){
Map<String, Object> args = new HashMap<>(3);
//声明当前队列绑定的死信交换机
args.put("x-dead-letter-exchange",Y_DEAD_EXCHANGE);
//声明当前队列的死信路由key
args.put("x-dead-letter-routing-key","YD");
//声明队列的 TTL
args.put("x-message-ttl",10000);
return QueueBuilder.durable(QUEUE_A).withArguments(args).build();
}
//声明队列A绑定X交换机
@Bean
public Binding queueBindingX(@Qualifier("queueA") Queue queueA,
@Qualifier("xExchange") DirectExchange xExchange){
return BindingBuilder.bind(queueA).to(xExchange).with("XA");
};
@Bean("queueB")
public Queue queueB(){
Map<String, Object> args = new HashMap<>(3);
//声明当前队列绑定的死信交换机
args.put("x-dead-letter-exchange",Y_DEAD_EXCHANGE);
//声明当前队列的死信路由key
args.put("x-dead-letter-routing-key","YD");
//声明队列的 TTL
args.put("x-message-ttl",40000);
return QueueBuilder.durable(QUEUE_B).withArguments(args).build();
}
//声明队列B绑定X交换机
@Bean
public Binding queueBBindingX(@Qualifier("queueB") Queue queue1B,
@Qualifier("xExchange") DirectExchange xExchange){
return BindingBuilder.bind(queue1B).to(xExchange).with("XB");
};
//声明死信队列QD
@Bean("queueD")
public Queue queueD(){
return new Queue(QUEUE_DEAD_D);
}
//声明死信队列QD绑定关系
@Bean
public Binding queuedeadBindingX(@Qualifier("queueD") Queue queueD,
@Qualifier("yExchange") DirectExchange yExchange){
return BindingBuilder.bind(queueD).to(yExchange).with("YD");
};
}
7.5.3 消息生产者代码
@Slf4j
@RequestMapping("ttl") //实现浏览器的请求路径与方法的映射
@RestController //表示Controller类,同时要求返回值为JSON
public class SendMsgController {
@Autowired
private RabbitTemplate rabbitTemplate;
@GetMapping("sendMsg/{message}") // 只能接收GET请求类型
//@PathVariable restFul结构,接收参数的注解.
public void sendMsg(@PathVariable String message){
log.info("当前时间:{},发送一条信息给两个TTL队列:{}",new Date(),message);
rabbitTemplate.convertAndSend("X","XA","消息来自ttl为10s的队列:"+message);
rabbitTemplate.convertAndSend("X","XB","消息来自ttl为40s的队列:"+message);
}
}
7.5.4 消费者代码
@Slf4j
@Component
public class Consumer {
@RabbitListener(queues = ConfirmConfig.CONFIRM_QUEUE_NAME)
public void receiveConfigMessage(Message message){
String s = new String(message.getBody());
log.info("接受到的消息是:{}" + s);
}
}

为什么这样说,因为我们队列声明的时候设置的TTL.
7.6 延迟队列优化
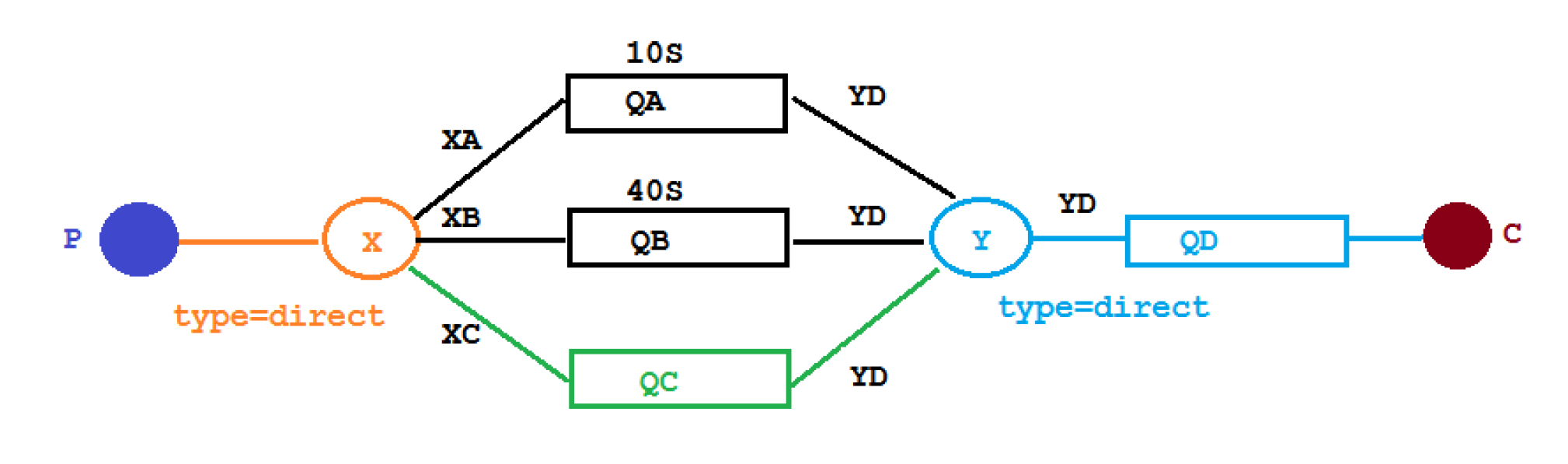
7.6.1 代码架构图
在这里新增了一个队列 QC,绑定关系如下,该队列不设置TTL 时间。
7.6.2 配置类代码
@Configuration
public class TtlQueueConfig {
//死信交换机
public static final String Y_DEAD_EXCHANGE = "Y";
//普通队列
public static final String QUEUE_C = "QC";
@Bean("yExchange")
public DirectExchange yExchange(){
return new DirectExchange(Y_DEAD_EXCHANGE);
}
//优化延迟信息队列
@Bean("queueC")
public Queue queueC(){
Map<String, Object> args = new HashMap<>();
//设置与死信交换机绑定
args.put("x-dead-letter-exchange",Y_DEAD_EXCHANGE);
//声明当前队列的死信路由KEY
args.put("x-dead-letter-routing-key","YD");
return QueueBuilder.durable(QUEUE_C).withArguments(args).build();
}
//绑定
@Bean
public Binding queudeadeBindingC(@Qualifier("queueC") Queue queueC,
@Qualifier("xExchange") DirectExchange xExchange
){
return BindingBuilder.bind(queueC).to(xExchange).with("XC");
}
}
7.6.3 消息生产者代码
@Slf4j
@RequestMapping("ttl") //实现浏览器的请求路径与方法的映射
@RestController //表示Controller类,同时要求返回值为JSON
public class SendMsgController {
@Autowired
private RabbitTemplate rabbitTemplate;
//开始发消息 消息TTL
@GetMapping("/sendExpirationMsg/{message}/{ttlTime}")
public void sendMsg(@PathVariable String message,@PathVariable String ttlTime){
log.info("当前时间:{},发送一条时长{}毫秒TTL信息给队列QC:{}",
new Date().toString(),ttlTime,message);
rabbitTemplate.convertAndSend("X","XC",message,msg ->{
//发送消息的时候 延迟时长
msg.getMessageProperties().setExpiration(ttlTime);
return msg;
});
}
}


7.7 Rabbitmq 插件实现延迟队列
上文中提到的问题,确实是一个问题,如果不能实现在消息粒度上的 TTL,并使其在设置的TTL 时间及时死亡,就无法设计成一个通用的延时队列。那如何解决呢,接下来我们就去解决该问题。
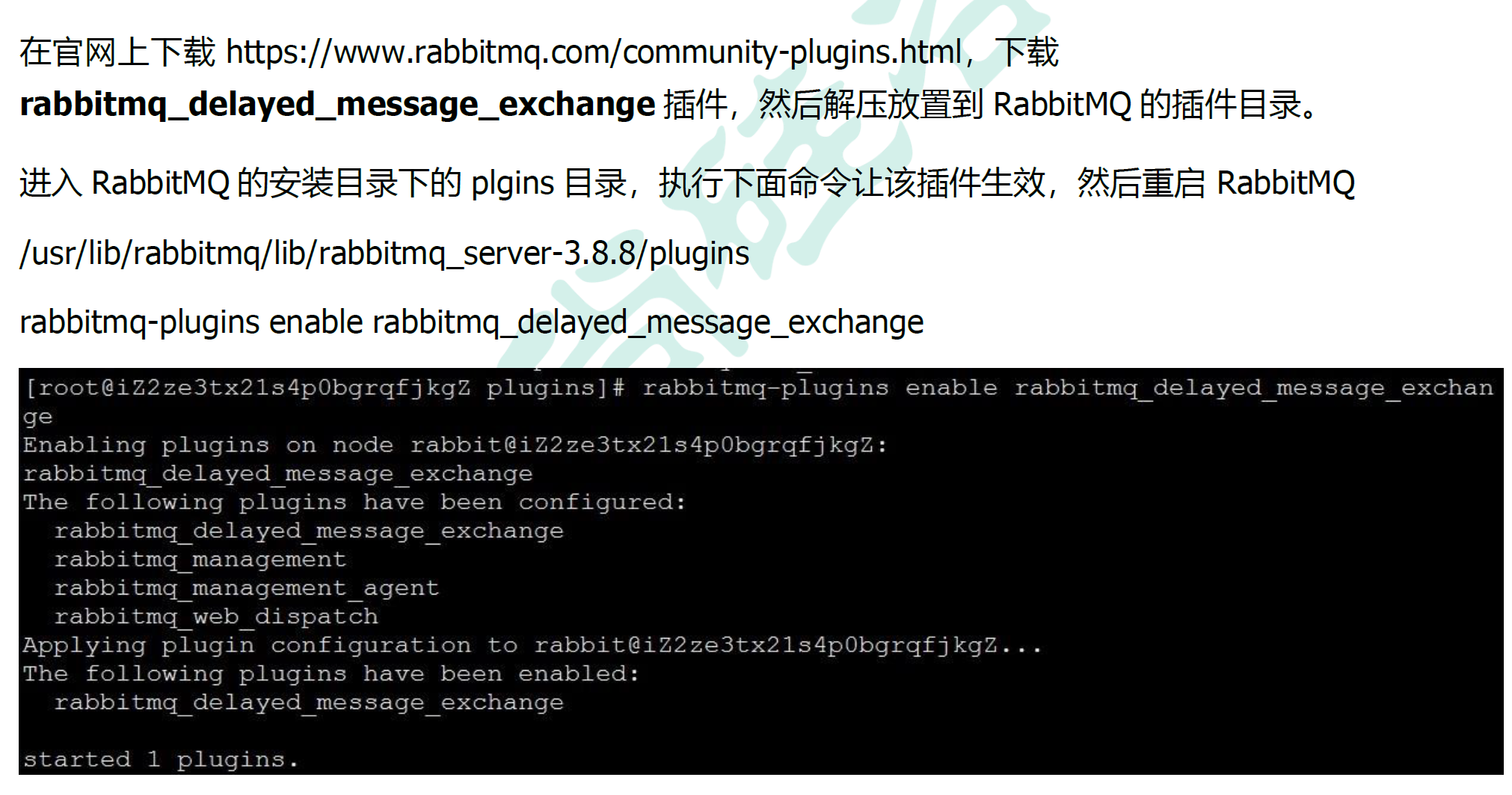
7.7.1 安装延时队列插件
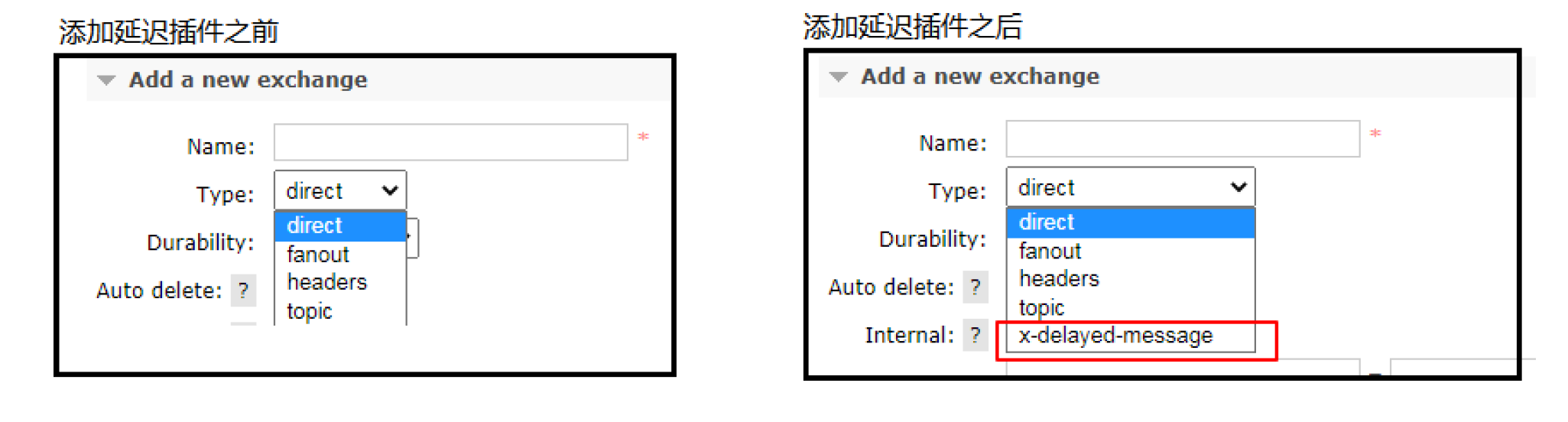
7.7.2 代码架构图

7.7.3 配置文件类代码
在我们自定义的交换机中,这是一种新的交换类型,该类型消息支持延迟投递机制 消息传递后并不会立即投递到目标队列中,而是存储在 mnesia(一个分布式数据系统)表中,当达到投递时间时,才投递到目标队列中。
@Configuration
public class DelayedQueueConfig {
public static final String DELAYED_QUEUE_NAME = "delayed.queue";
public static final String DELAYED_EXCHANGE_NAME = "delayed.exchange";
public static final String DELAYED_ROUTING_NAME = "delayed.routingkey";
//声明队列
@Bean
public Queue delayedQueue(){
return new Queue(DELAYED_QUEUE_NAME);
}
//声明交换机
//自定义交换机,我们在这里定义的是一个延迟交换机
@Bean
public CustomExchange delayedExchange(){
Map<String, Object> args = new HashMap<>();
//自定义交换机的类型
args.put("x-delayed-type","direct");
return new CustomExchange(DELAYED_EXCHANGE_NAME,"x-delayed-message",true,false,args);
}
//声明绑定关系
@Bean
public Binding bindingDelaydeQueue(@Qualifier("delayedQueue")Queue queue,
@Qualifier("delayedExchange") CustomExchange delaydeExchange){
return BindingBuilder.bind(queue).to(delaydeExchange).with(DELAYED_ROUTING_NAME).noargs();
}
}
7.7.4 消息生产者代码
@Slf4j
@RequestMapping("ttl") //实现浏览器的请求路径与方法的映射
@RestController //表示Controller类,同时要求返回值为JSON
public class SendMsgController {
@Autowired
private RabbitTemplate rabbitTemplate;
//开始发消息 基于插件的消息及延迟的时间
@GetMapping("/sendDelayMsg/{message}/{delayTime}")
public void sendMsg(@PathVariable String message,@PathVariable Integer delayTime){
log.info("当前时间:{},发送一条时长{}毫秒TTL信息给队列delayed.queue:{}",
new Date().toString(),delayTime,message);
rabbitTemplate.convertAndSend(DelayedQueueConfig.DELAYED_EXCHANGE_NAME,
DelayedQueueConfig.DELAYED_ROUTING_NAME,message, msg ->{
//发送消息的时候 延迟时长
msg.getMessageProperties().setDelay(delayTime);
return msg;
});
}
}
7.7.5 消息消费者代码
@Slf4j
@Component
public class DelayedQueueConsumer {
//接收消息
@RabbitListener(queues = DelayedQueueConfig.DELAYED_QUEUE_NAME)
public void receiveDelayed(Message message){
String msg = new String(message.getBody());
log.info("当前时间:{},收到延迟队列的消息:{}",new Date().toString(),msg);
}
}

7.8 总结

7.9 启动问题
RabbitMQ整合springboot时出现以下错误:
Error starting ApplicationContext. To display the conditions report re-run your application with ‘debug’ enabled.
2022-08-27 09:05:19.476 ERROR 30248 — [ main] o.s.boot.SpringApplication : Application run failedorg.springframework.context.ApplicationContextException: Failed to
start bean ‘documentationPluginsBootstrapper’; nested exception is
java.lang.NullPointerException at
org.springframework.context.support.DefaultLifecycleProcessor.doStart(DefaultLifecycleProcessor.java:181)
~[spring-context-5.3.22.jar:5.3.22] at
org.springframework.context.support.DefaultLifecycleProcessor.access 200 ( D e f a u l t L i f e c y c l e P r o c e s s o r . j a v a : 54 ) [ s p r i n g − c o n t e x t − 5.3.22. j a r : 5.3.22 ] a t o r g . s p r i n g f r a m e w o r k . c o n t e x t . s u p p o r t . D e f a u l t L i f e c y c l e P r o c e s s o r 200(DefaultLifecycleProcessor.java:54) ~[spring-context-5.3.22.jar:5.3.22] at org.springframework.context.support.DefaultLifecycleProcessor 200(DefaultLifecycleProcessor.java:54) [spring−context−5.3.22.jar:5.3.22]atorg.springframework.context.support.DefaultLifecycleProcessorLifecycleGroup.start(DefaultLifecycleProcessor.java:356)
~[spring-context-5.3.22.jar:5.3.22] at
java.lang.Iterable.forEach(Iterable.java:75) ~[na:1.8.0_131] at
org.springframework.context.support.DefaultLifecycleProcessor.startBeans(DefaultLifecycleProcessor.java:155)
~[spring-context-5.3.22.jar:5.3.22] at
org.springframework.context.support.DefaultLifecycleProcessor.onRefresh(DefaultLifecycleProcessor.java:123)
~[spring-context-5.3.22.jar:5.3.22] at
org.springframework.context.support.AbstractApplicationContext.finishRefresh(AbstractApplicationContext.java:935)
~[spring-context-5.3.22.jar:5.3.22] at
org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.java:586)
~[spring-context-5.3.22.jar:5.3.22] at
org.springframework.boot.web.servlet.context.ServletWebServerApplicationContext.refresh(ServletWebServerApplicationContext.java:145)
~[spring-boot-2.6.11.jar:2.6.11] at
org.springframework.boot.SpringApplication.refresh(SpringApplication.java:745)
[spring-boot-2.6.11.jar:2.6.11] at
org.springframework.boot.SpringApplication.refreshContext(SpringApplication.java:420)
[spring-boot-2.6.11.jar:2.6.11] at
org.springframework.boot.SpringApplication.run(SpringApplication.java:307)
[spring-boot-2.6.11.jar:2.6.11] at
org.springframework.boot.SpringApplication.run(SpringApplication.java:1317)
[spring-boot-2.6.11.jar:2.6.11] at
org.springframework.boot.SpringApplication.run(SpringApplication.java:1306)
[spring-boot-2.6.11.jar:2.6.11] at
com.atguigu.rabbitmq.springbootrabbitmq.SpringbootRabbitmqApplication.main(SpringbootRabbitmqApplication.java:13)
[classes/:na] Caused by: java.lang.NullPointerException: null at
springfox.documentation.spi.service.contexts.Orderings$8.compare(Orderings.java:112)
~[springfox-spi-2.9.2.jar:null] at
springfox.documentation.spi.service.contexts.Orderings$8.compare(Orderings.java:109)
~[springfox-spi-2.9.2.jar:null] at
com.google.common.collect.ComparatorOrdering.compare(ComparatorOrdering.java:37)
~[guava-20.0.jar:na] at
java.util.TimSort.countRunAndMakeAscending(TimSort.java:355)
~[na:1.8.0_131] at java.util.TimSort.sort(TimSort.java:220)
~[na:1.8.0_131] at java.util.Arrays.sort(Arrays.java:1438)
~[na:1.8.0_131] at
com.google.common.collect.Ordering.sortedCopy(Ordering.java:855)
~[guava-20.0.jar:na] at
springfox.documentation.spring.web.plugins.WebMvcRequestHandlerProvider.requestHandlers(WebMvcRequestHandlerProvider.java:57)
~[springfox-spring-web-2.9.2.jar:null] at
springfox.documentation.spring.web.plugins.DocumentationPluginsBootstrapper$2.apply(DocumentationPluginsBootstrapper.java:138)
~[springfox-spring-web-2.9.2.jar:null] at
springfox.documentation.spring.web.plugins.DocumentationPluginsBootstrapper$2.apply(DocumentationPluginsBootstrapper.java:135)
~[springfox-spring-web-2.9.2.jar:null] at
com.google.common.collect.Iterators$7.transform(Iterators.java:750)
~[guava-20.0.jar:na] at
com.google.common.collect.TransformedIterator.next(TransformedIterator.java:47)
~[guava-20.0.jar:na] at
com.google.common.collect.TransformedIterator.next(TransformedIterator.java:47)
~[guava-20.0.jar:na] at
com.google.common.collect.MultitransformedIterator.hasNext(MultitransformedIterator.java:52)
~[guava-20.0.jar:na] at
com.google.common.collect.MultitransformedIterator.hasNext(MultitransformedIterator.java:50)
~[guava-20.0.jar:na] at
com.google.common.collect.ImmutableList.copyOf(ImmutableList.java:249)
~[guava-20.0.jar:na] at
com.google.common.collect.ImmutableList.copyOf(ImmutableList.java:209)
~[guava-20.0.jar:na] at
com.google.common.collect.FluentIterable.toList(FluentIterable.java:614)
~[guava-20.0.jar:na] at
springfox.documentation.spring.web.plugins.DocumentationPluginsBootstrapper.defaultContextBuilder(DocumentationPluginsBootstrapper.java:111)
~[springfox-spring-web-2.9.2.jar:null] at
springfox.documentation.spring.web.plugins.DocumentationPluginsBootstrapper.buildContext(DocumentationPluginsBootstrapper.java:96)
~[springfox-spring-web-2.9.2.jar:null] at
springfox.documentation.spring.web.plugins.DocumentationPluginsBootstrapper.start(DocumentationPluginsBootstrapper.java:167)
~[springfox-spring-web-2.9.2.jar:null] at
org.springframework.context.support.DefaultLifecycleProcessor.doStart(DefaultLifecycleProcessor.java:178)
~[spring-context-5.3.22.jar:5.3.22] … 14 common frames omittedDisconnected from the target VM, address: ‘127.0.0.1:50114’,
transport: ‘socket’Process finished with exit code 1
这个错误的原因是springboot版本和swager版本不对,版本太高。可以在配置文件中加入以下代码:
Spring.mvc.pathmatch.matching-strategy=ant_path_matcher
spring.rabbitmq.host=192.168.119.100
spring.rabbitmq.port=5672
spring.rabbitmq.username=admin
spring.rabbitmq.password=123
但是我在最开始运行的时候发现修改了以上配置文件也不行,仍然会出现一个问题:
org.springframework.amqp.AmqpAuthenticationException: com.rabbitmq.client.Au
解决办法:
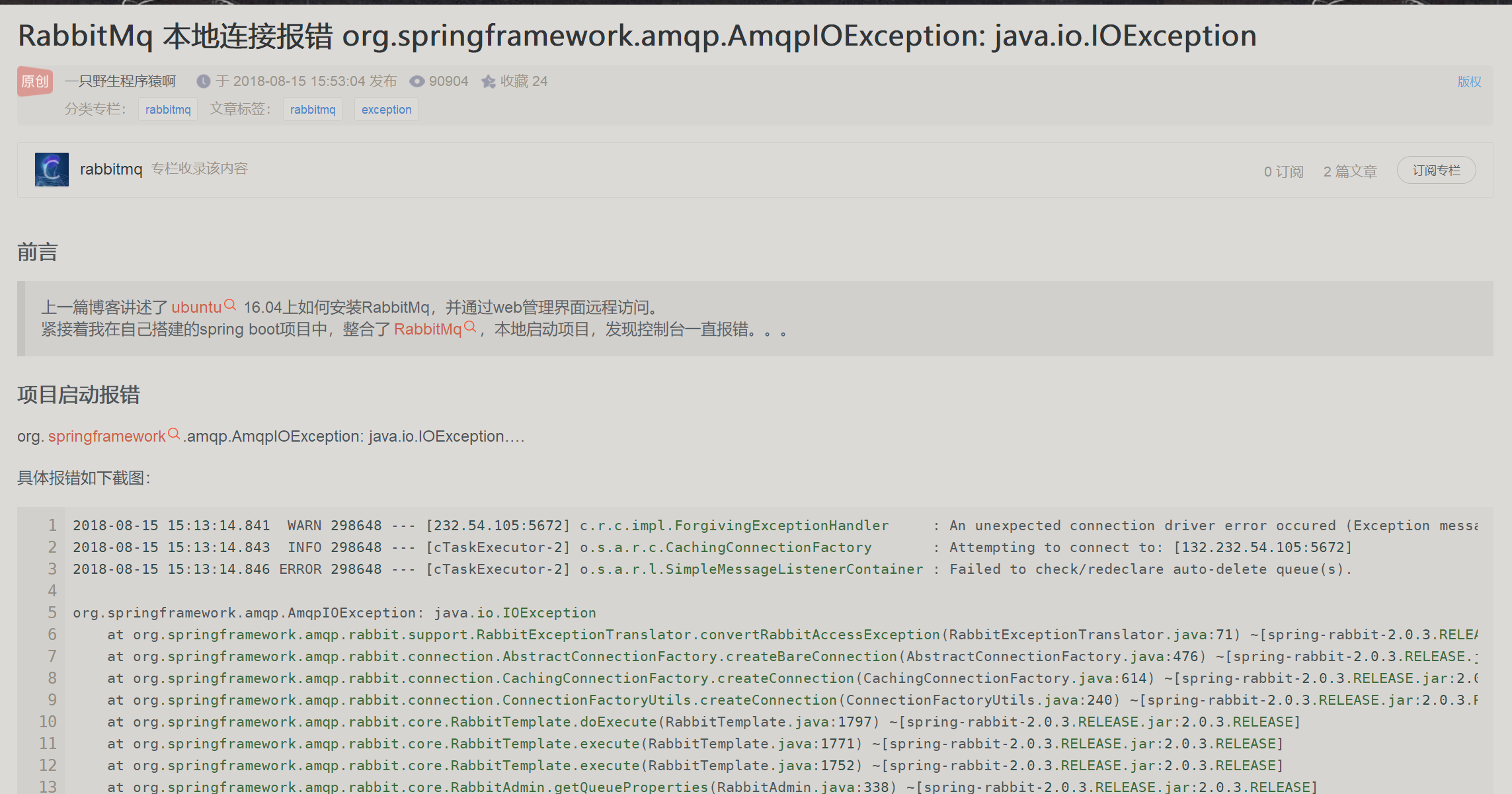
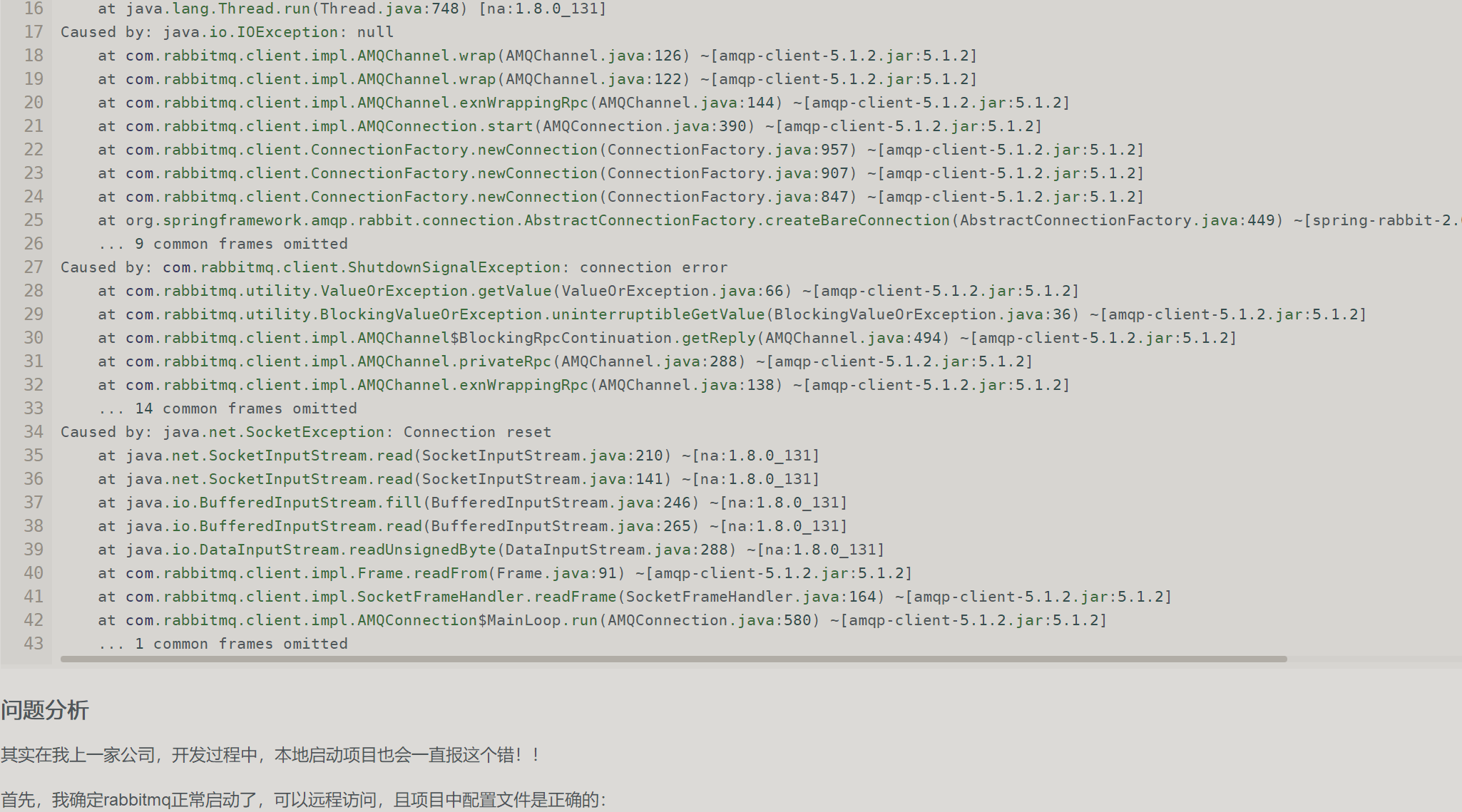
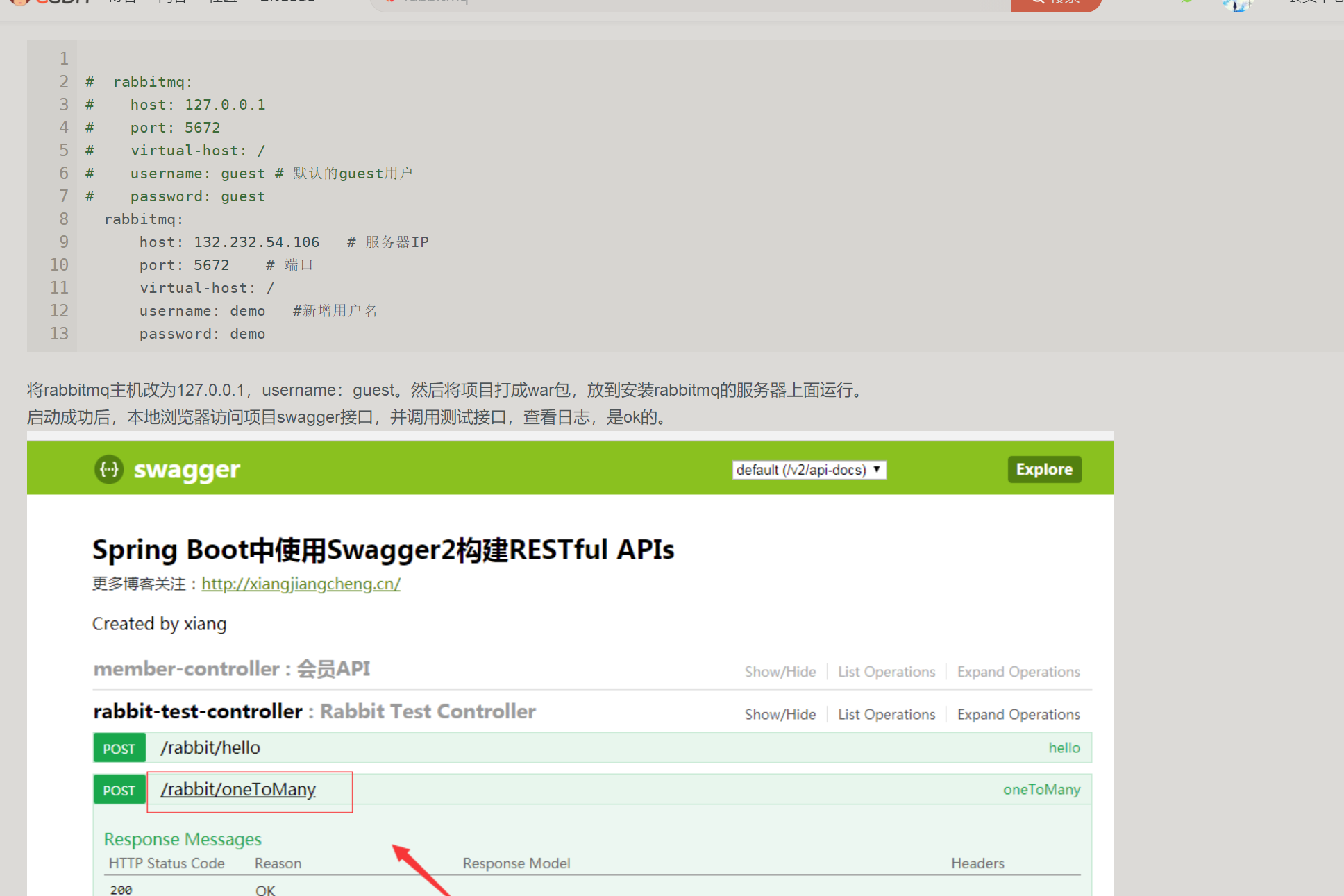
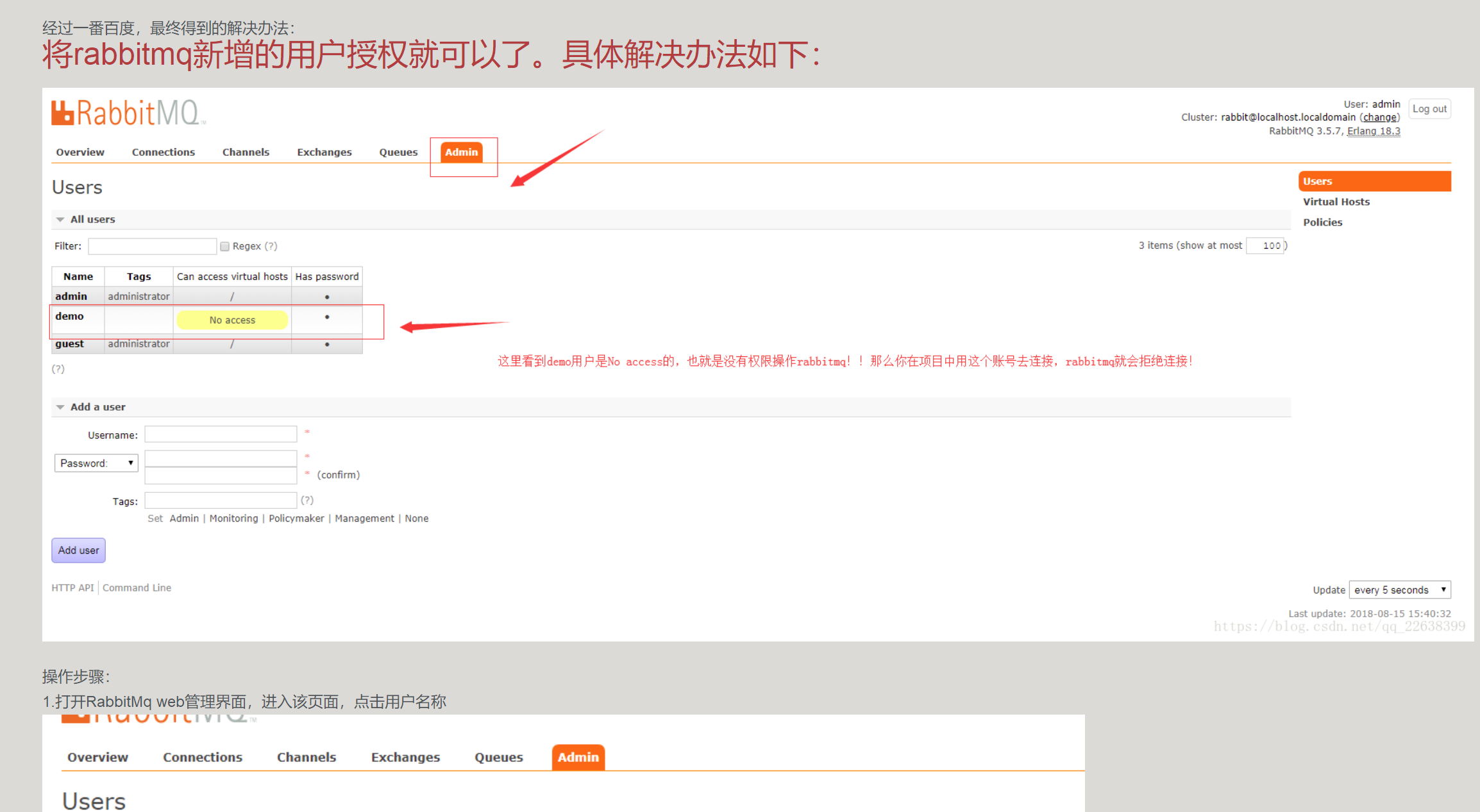
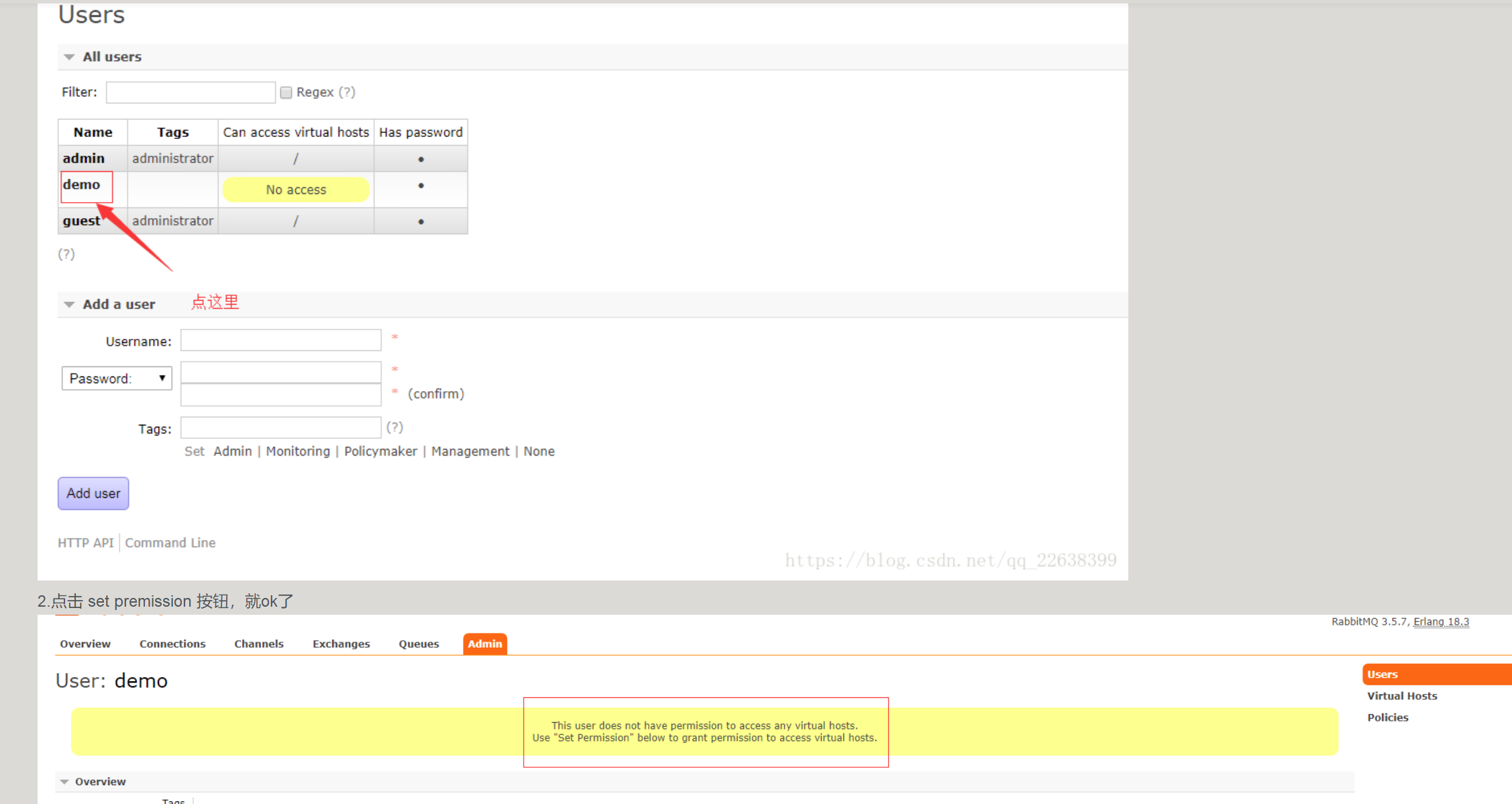
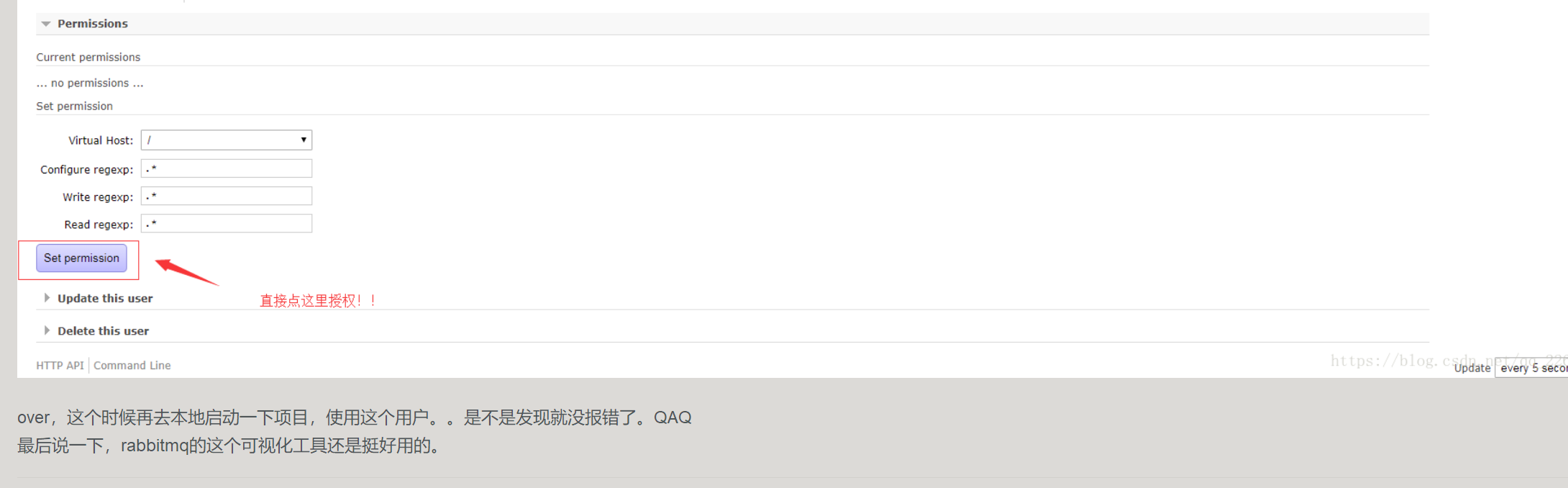
自己操作了一番,运行果然成功。
8 发布确认高级


8.1 发布确认springboot版本
8.1.1 确认机制方案
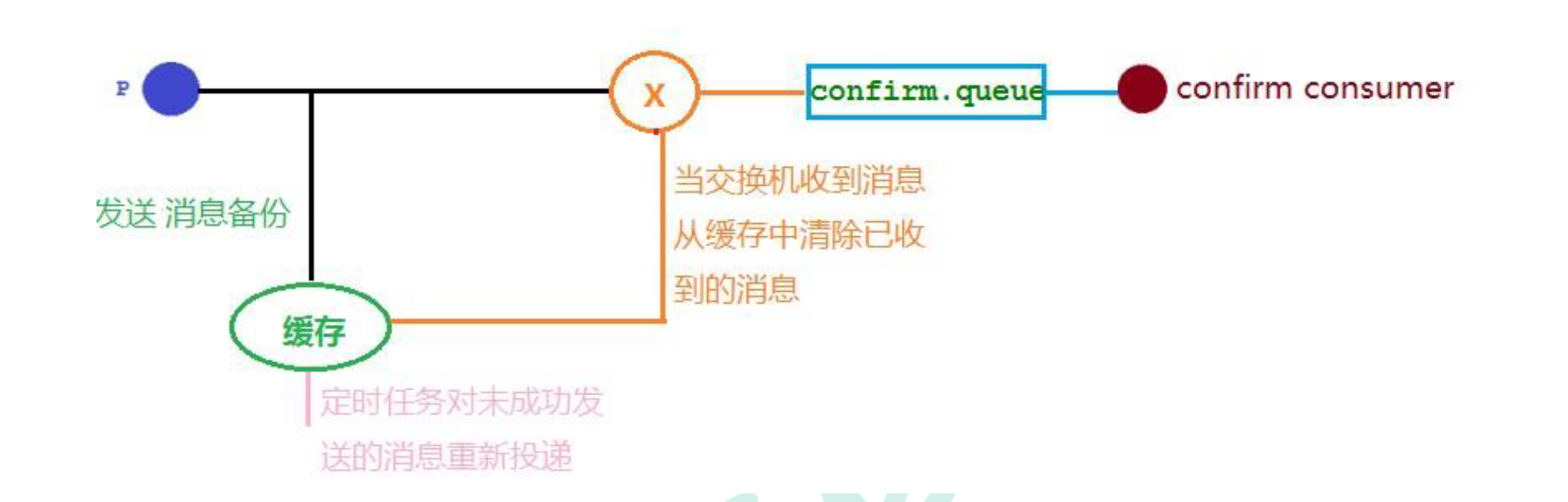
8.1.2 代码架构图

8.1.3 配置文件

Spring.mvc.pathmatch.matching-strategy=ant_path_matcher
spring.rabbitmq.host=192.168.119.100
spring.rabbitmq.port=5672
spring.rabbitmq.username=admin
spring.rabbitmq.password=123
//回调
spring.rabbitmq.publisher-confirm-type=correlated
8.1.4 添加配置类
@Configuration
public class ConfirmConfig {
public static final String CONFIRM_EXCHANGE_NAME = "confirm.exchange";
public static final String CONFIRM_QUEUE_NAME = "confirm.queue";
//声明交换机
@Bean("confirmExchange")
public DirectExchange confirmExchange(){
return new DirectExchange(CONFIRM_EXCHANGE_NAME);
}
//声明队列
@Bean("confirmQueue")
public Queue confirmQueue(){
return QueueBuilder.durable(CONFIRM_QUEUE_NAME).build();
}
//声明绑定关系
@Bean
public Binding queueBindingConfirm(@Qualifier("confirmExchange") DirectExchange exchange,
@Qualifier("confirmQueue")Queue queue){
return BindingBuilder.bind(queue).to(exchange).with("key1");
}
}
8.1.5 消息生产者
@Slf4j
@RestController
@RequestMapping("/confirm")
public class ProducerController {
@Autowired
private RabbitTemplate rabbitTemplate;
@GetMapping("/sendMessage/{message}")
public void sendMessage(@PathVariable String message){
CorrelationData correlationData = new CorrelationData();
rabbitTemplate.convertAndSend(ConfirmConfig.CONFIRM_EXCHANGE_NAME,"key1",message,correlationData);
log.info("发送消息内容:{}",message);
}
}
8.1.6 回调接口
@Component
@Slf4j
public class MyCallBack implements RabbitTemplate.ConfirmCallback,RabbitTemplate.ReturnsCallback {
/**
* 交换机确认回调方法
* 1.发消息 交换机接收到了 回调
* 1.1 correlationData 保存回调消息的ID及相关信息
* 1.2 交换机收到消息 ack = true
* 1.3 cause nullify
*
* 2.发消息 交换机接收失败了 回调
* 2.1 correlationData 保存回调消息的ID及相关信息
* 2.2 交换机未收到消息 ack = false
* 2.3 cause 失败的原因
*/
@Autowired
private RabbitTemplate rabbitTemplate;
@PostConstruct
public void init(){
//注入
rabbitTemplate.setConfirmCallback(this);
}
//回调接口
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
String id = correlationData != null ? correlationData.getId() : ""; //三元表达式
if(ack){
log.info("交换机已经收到id为:{}的消息",id);
}else {
log.info("交换机还未收到id为:{}消息,由于原因:{}",id,cause);
}
}
}
8.1.7 消息消费者
@Slf4j
@Component
public class Consumer {
@RabbitListener(queues = ConfirmConfig.CONFIRM_QUEUE_NAME)
public void receiveConfigMessage(Message message){
String s = new String(message.getBody());
log.info("接受到的消息是:{}" + s);
}
}
8.1.8 结果分析

8.2 回退消息
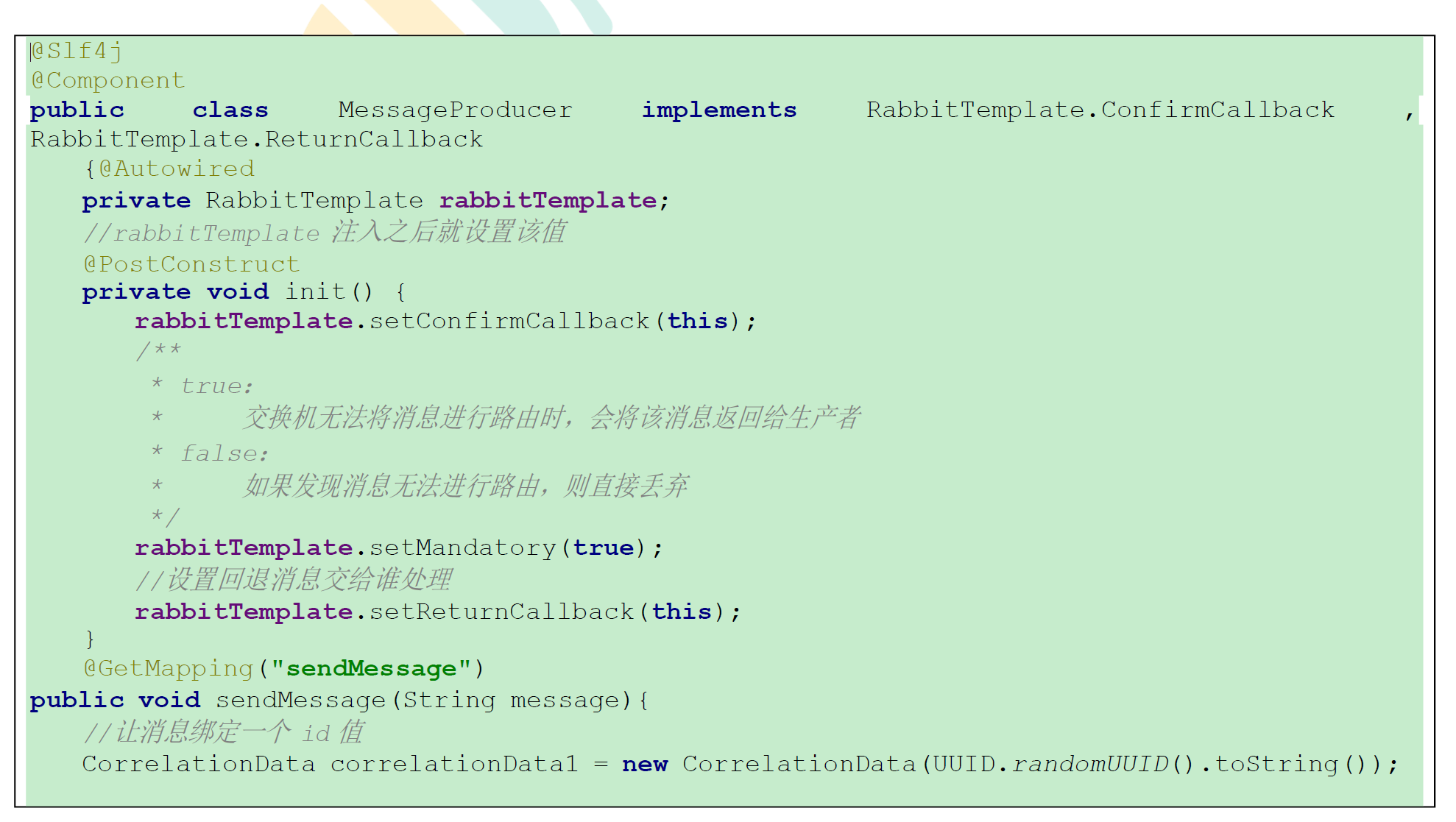
8.2.1 Mandatory 参数

8.2.2 消息生产者代码

8.2.3 回调接口
@Component
@Slf4j
public class MyCallBack implements RabbitTemplate.ConfirmCallback,RabbitTemplate.ReturnsCallback {
@Autowired
private RabbitTemplate rabbitTemplate;
@PostConstruct
public void init(){
//注入
rabbitTemplate.setConfirmCallback(this);
rabbitTemplate.setReturnsCallback(this);
}
//回调接口
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
String id = correlationData != null ? correlationData.getId() : ""; //三元表达式
if(ack){
log.info("交换机已经收到id为:{}的消息",id);
}else {
log.info("交换机还未收到id为:{}消息,由于原因:{}",id,cause);
}
}
//回退接口
@Override
public void returnedMessage(ReturnedMessage returned) {
// log.info("消息{},被交换机{}退回,退回原因:{},路由key:{}:",returned.getMessage()
// ,returned.getExchange(),returned.getReplyText(),returned.getRoutingKey());
log.info(returned.toString());
}
}
8.2.4 结果分析

8.3 备份交换机

8.3.1 代码架构图
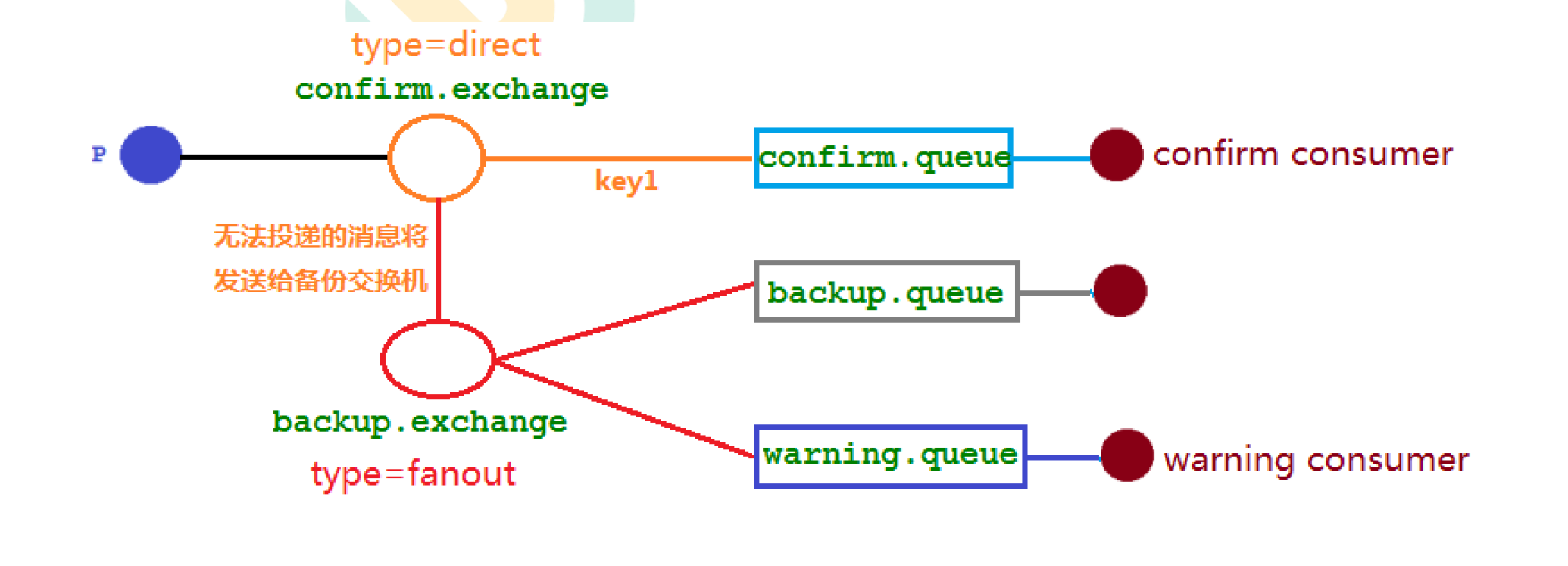
8.3.2 修改配置类
public class ConfirmConfig {
public static final String CONFIRM_EXCHANGE_NAME = "confirm.exchange";
public static final String CONFIRM_QUEUE_NAME = "confirm.queue";
public static final String BACKUP_QUEUE_NAME = "backup.queue";
public static final String WARNING_QUEUE_NAME = "warning.queue";
public static final String BACKUP_EXCHANGE_NAME = "backup.exchange";
//声明交换机
@Bean("confirmExchange")
public DirectExchange confirmExchange(){
// return new DirectExchange(CONFIRM_EXCHANGE_NAME);
//将直接交换机消息转发到备份交换机
return ExchangeBuilder.directExchange(CONFIRM_EXCHANGE_NAME).durable(true)
.withArgument("alternate-exchange",BACKUP_EXCHANGE_NAME).build();
}
@Bean("backupExchange")
public FanoutExchange backupExchange(){
return new FanoutExchange(BACKUP_EXCHANGE_NAME);
}
//声明队列
@Bean("confirmQueue")
public Queue confirmQueue(){
return QueueBuilder.durable(CONFIRM_QUEUE_NAME).build();
}
@Bean("backQueue")
public Queue backQueue(){
return QueueBuilder.durable(BACKUP_QUEUE_NAME).build();
}
@Bean("warningQueue")
public Queue warningQueue(){
return QueueBuilder.durable(WARNING_QUEUE_NAME).build();
}
//声明绑定关系
@Bean
public Binding queueBindingConfirm(@Qualifier("confirmExchange") DirectExchange exchange,
@Qualifier("confirmQueue")Queue queue){
return BindingBuilder.bind(queue).to(exchange).with("key1");
}
@Bean
public Binding queueBindingBackup(@Qualifier("backupExchange")FanoutExchange exchange,
@Qualifier("backQueue")Queue queue){
return BindingBuilder.bind(queue).to(exchange);
}
@Bean
public Binding queueBindingBackupWarning(@Qualifier("backupExchange")FanoutExchange exchange,
@Qualifier("warningQueue")Queue queue){
return BindingBuilder.bind(queue).to(exchange);
}
}
8.3.3 报警消费者


8.3.4 测试注意事项

8.3.5 结果分析

9 RabbitMQ 其他知识点
9.1 幂等性
9.1.1 概念
用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用。举个最简单的例子,那就是支付,用户购买商品后支付,支付扣款成功,但是返回结果的时候网络异常, 此时钱已经扣了,用户再次点击按钮,此时会进行第二次扣款,返回结果成功,用户查询余额发现多扣钱了,流水记录也变成了两条。在以前的单应用系统中,我们只需要把数据操作放入事务中即可,发生错误立即回滚,但是再响应客户端的时候也有可能出现网络中断或者异常等等。
9.1.2 消息重复消费
消费者在消费 MQ 中的消息时,MQ 已把消息发送给消费者,消费者在给MQ 返回 ack 时网络中断, 故 MQ 未收到确认信息,该条消息会重新发给其他的消费者,或者在网络重连后再次发送给该消费者,但实际上该消费者已成功消费了该条消息,造成消费者消费了重复的消息。
9.1.3 解决思路
MQ 消费者的幂等性的解决一般使用全局 ID 或者写个唯一标识比如时间戳 或者 UUID 或者订单消费者消费 MQ 中的消息也可利用 MQ 的该 id 来判断,或者可按自己的规则生成一个全局唯一 id,每次消费消息时用该 id 先判断该消息是否已消费过。
9.1.4 消费端的幂等性保障
在海量订单生成的业务高峰期,生产端有可能就会重复发生了消息,这时候消费端就要实现幂等性, 这就意味着我们的消息永远不会被消费多次,即使我们收到了一样的消息。业界主流的幂等性有两种操作:a. 唯一 ID+指纹码机制,利用数据库主键去重, b.利用 redis 的原子性去实现。
9.1.5 唯一ID+指纹码机制
指纹码:我们的一些规则或者时间戳加别的服务给到的唯一信息码,它并不一定是我们系统生成的,基本都是由我们的业务规则拼接而来,但是一定要保证唯一性,然后就利用查询语句进行判断这个 id 是否存在数据库中,优势就是实现简单就一个拼接,然后查询判断是否重复;劣势就是在高并发时,如果是单个数据库就会有写入性能瓶颈当然也可以采用分库分表提升性能,但也不是我们最推荐的方式。
9.1.6 Redis 原子性
利用 redis 执行 setnx 命令,天然具有幂等性。从而实现不重复消费。
9.2 优先级队列
9.2.1 使用场景
在我们系统中有一个订单催付的场景,我们的客户在天猫下的订单,淘宝会及时将订单推送给我们,如果在用户设定的时间内未付款那么就会给用户推送一条短信提醒,很简单的一个功能对吧,但是,tmall 商家对我们来说,肯定是要分大客户和小客户的对吧,比如像苹果,小米这样大商家一年起码能给我们创造很大的利润,所以理应当然,他们的订单必须得到优先处理,而曾经我们的后端系统是使用 redis 来存
放的定时轮询,大家都知道 redis 只能用 List 做一个简简单单的消息队列,并不能实现一个优先级的场景,所以订单量大了后采用 RabbitMQ 进行改造和优化,如果发现是大客户的订单给一个相对比较高的优先级, 否则就是默认优先级。
9.2.2 如何添加
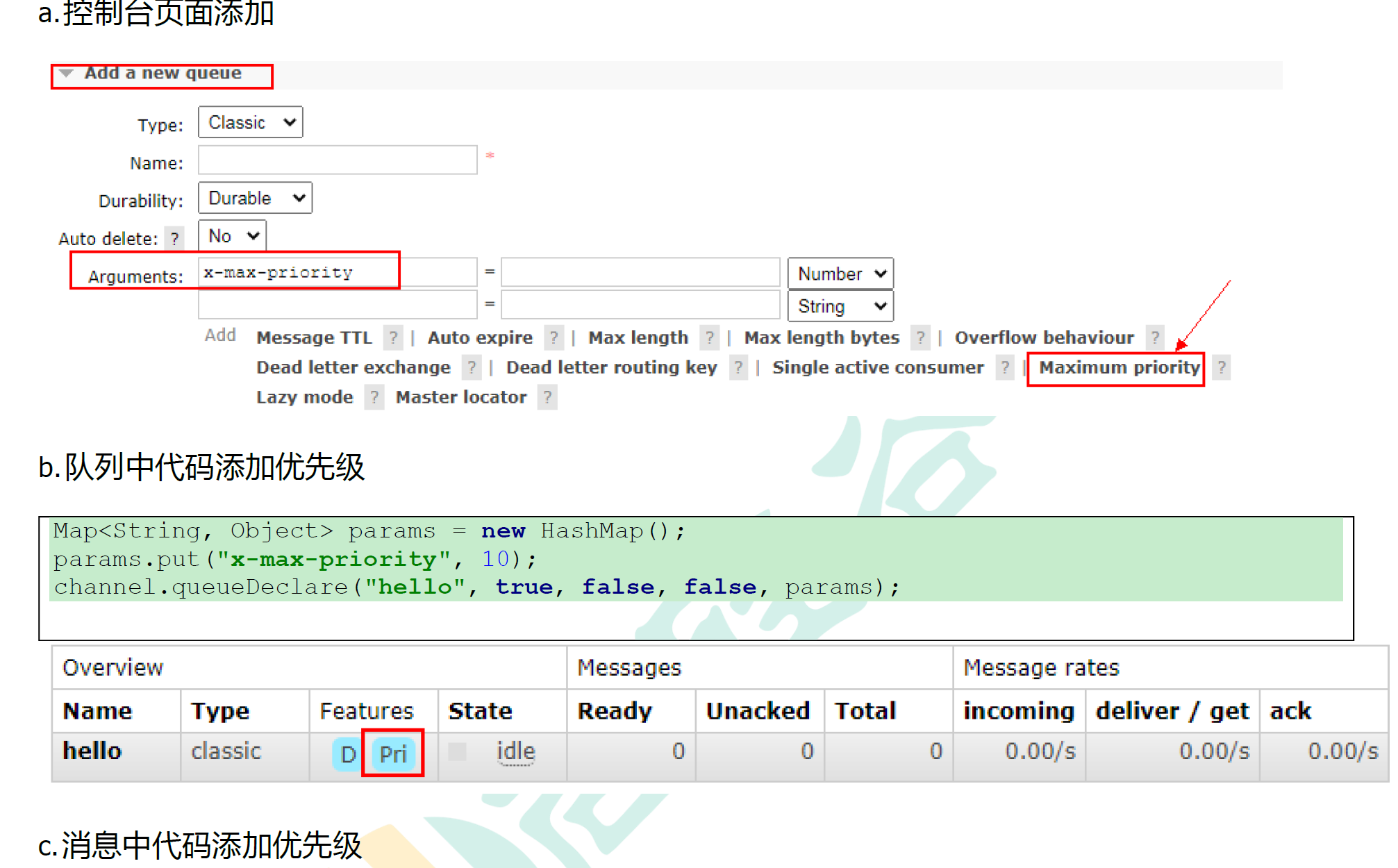

9.2.3 实战
消息生产者


消息消费者

9.3 惰性队列
9.3.1 使用场景

9.3.2 两种模式

9.3.3 内存开销对比

10 RabbitMQ 集群
10.1. clustering
10.1.1. 使用集群的原因
最开始我们介绍了如何安装及运行 RabbitMQ 服务,不过这些是单机版的,无法满足目前真实应用的要求。如果 RabbitMQ 服务器遇到内存崩溃、机器掉电或者主板故障等情况,该怎么办?单台 RabbitMQ 服务器可以满足每秒 1000 条消息的吞吐量,那么如果应用需要 RabbitMQ 服务满足每秒 10 万条消息的吞吐量呢?购买昂贵的服务器来增强单机 RabbitMQ 务的性能显得捉襟见肘,搭建一个 RabbitMQ 集群才是解决实际问题的关键.
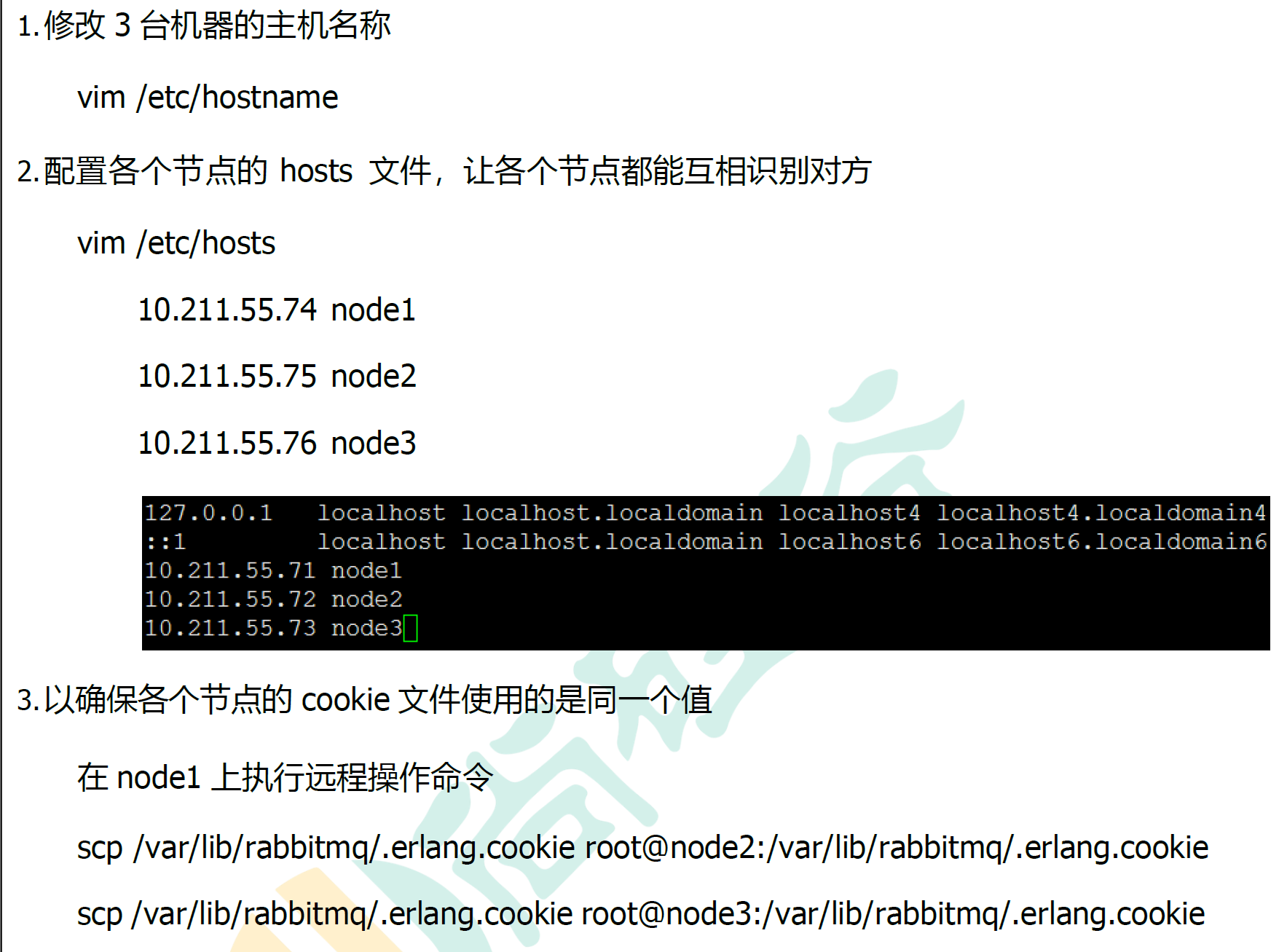
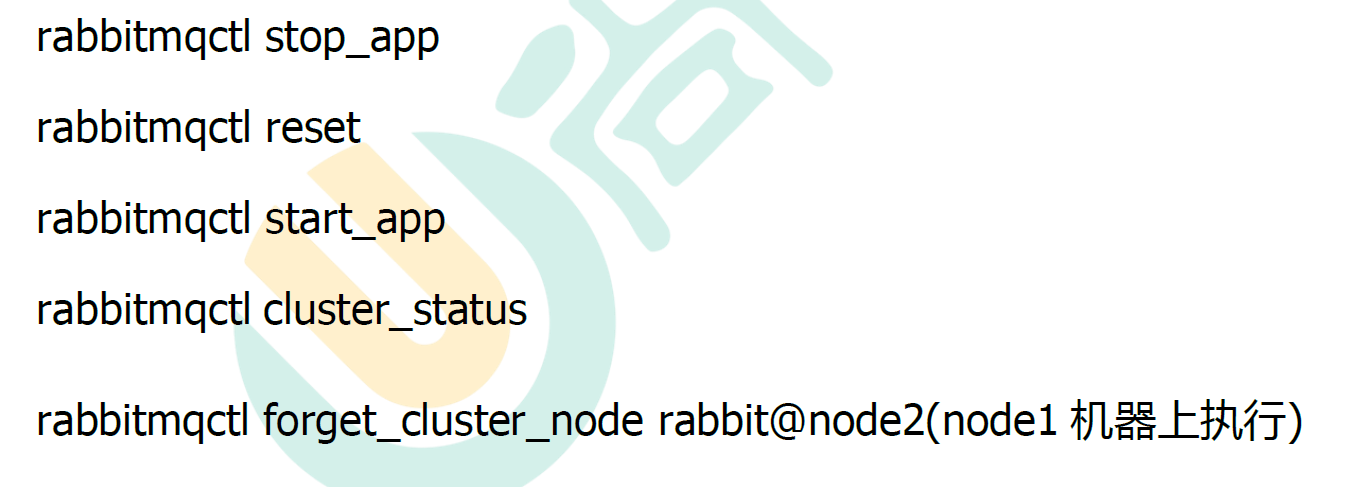
10.1.2 搭建步骤


10.2 镜像队列
10.2.1. 使用镜像的原因
如果 RabbitMQ 集群中只有一个 Broker 节点,那么该节点的失效将导致整体服务的临时性不可用,并且也可能会导致消息的丢失。可以将所有消息都设置为持久化,并且对应队列的durable 属性也设置为true, 但是这样仍然无法避免由于缓存导致的问题:因为消息在发送之后和被写入磁盘井执行刷盘动作之间存在一个短暂却会产生问题的时间窗。通过 publisherconfirm 机制能够确保客户端知道哪些消息己经存入磁盘, 尽管如此,一般不希望遇到因单点故障导致的服务不可用。
引入镜像队列(Mirror Queue)的机制,可以将队列镜像到集群中的其他 Broker 节点之上,如果集群中的一个节点失效了,队列能自动地切换到镜像中的另一个节点上以保证服务的可用性。
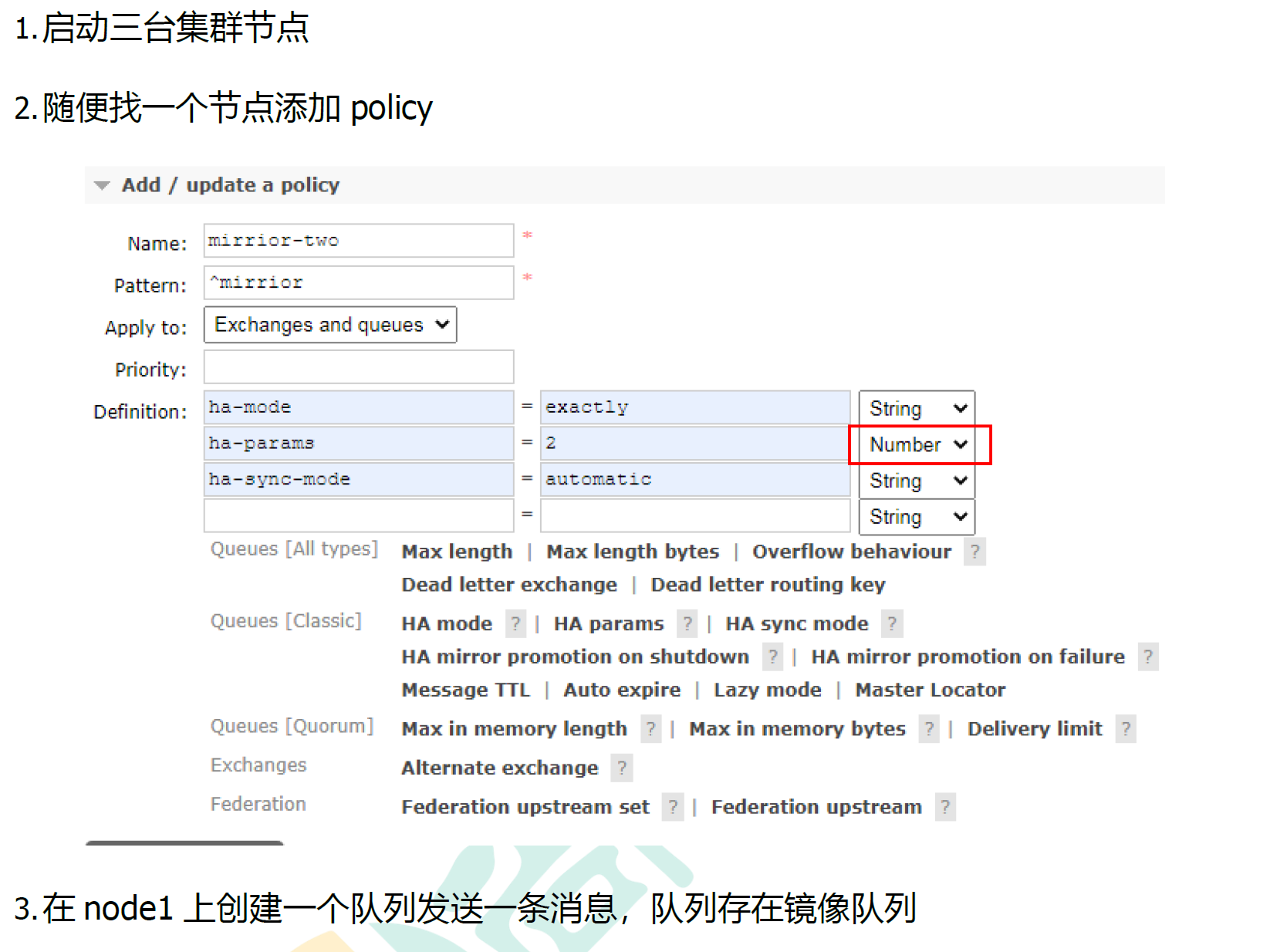
10.2.2 搭建步骤


10.3. Haproxy+Keepalive 实现高可用负载均衡
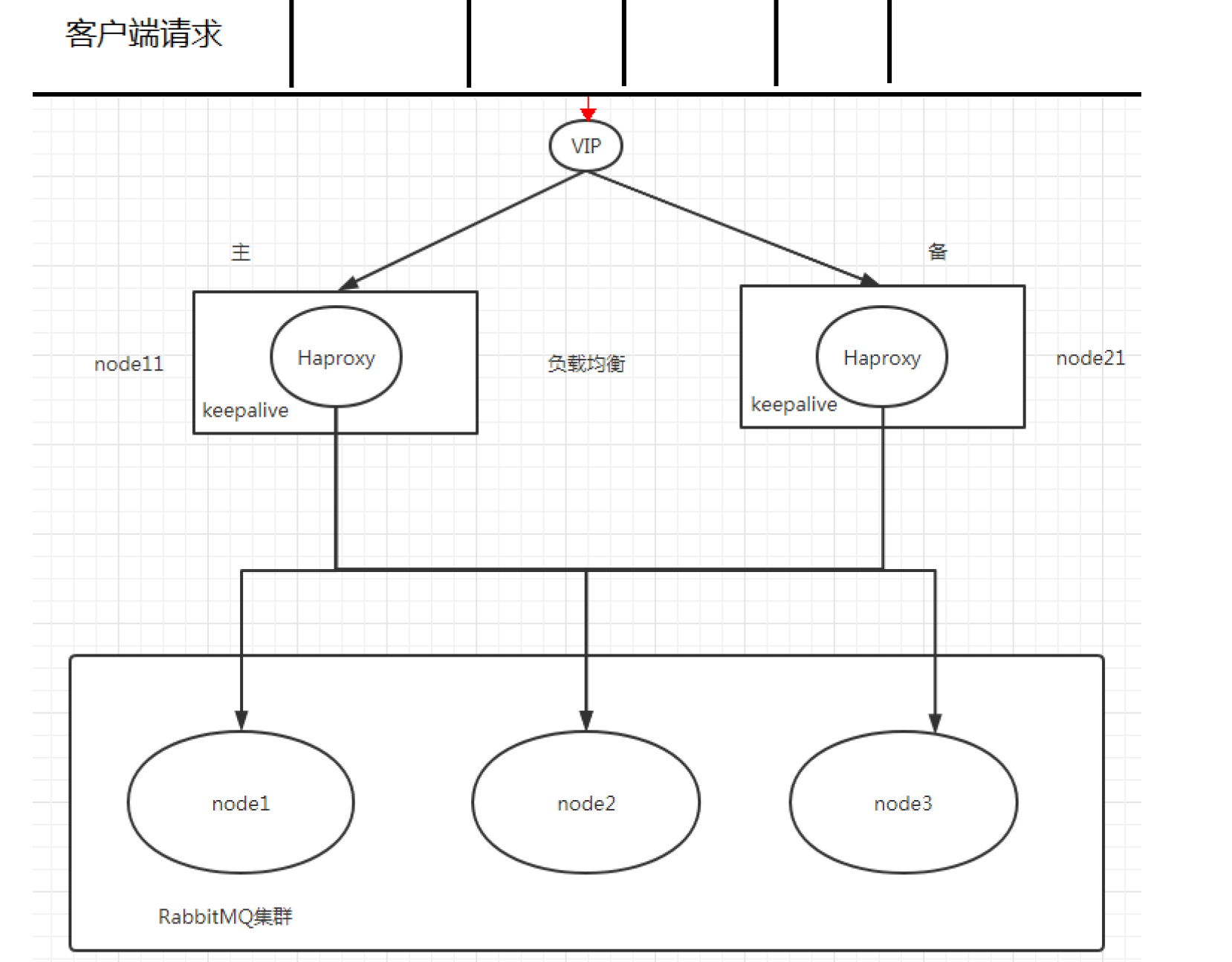
10.3.1. 整体架构图
10.3.2. Haproxy 实现负载均衡
HAProxy 提供高可用性、负载均衡及基于TCPHTTP 应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案,包括 Twitter,Reddit,StackOverflow,GitHub 在内的多家知名互联网公司在使用。HAProxy 实现了一种事件驱动、单一进程模型,此模型支持非常大的井发连接数。
扩展 nginx,lvs,haproxy 之间的区别: http://www.ha97.com/5646.html
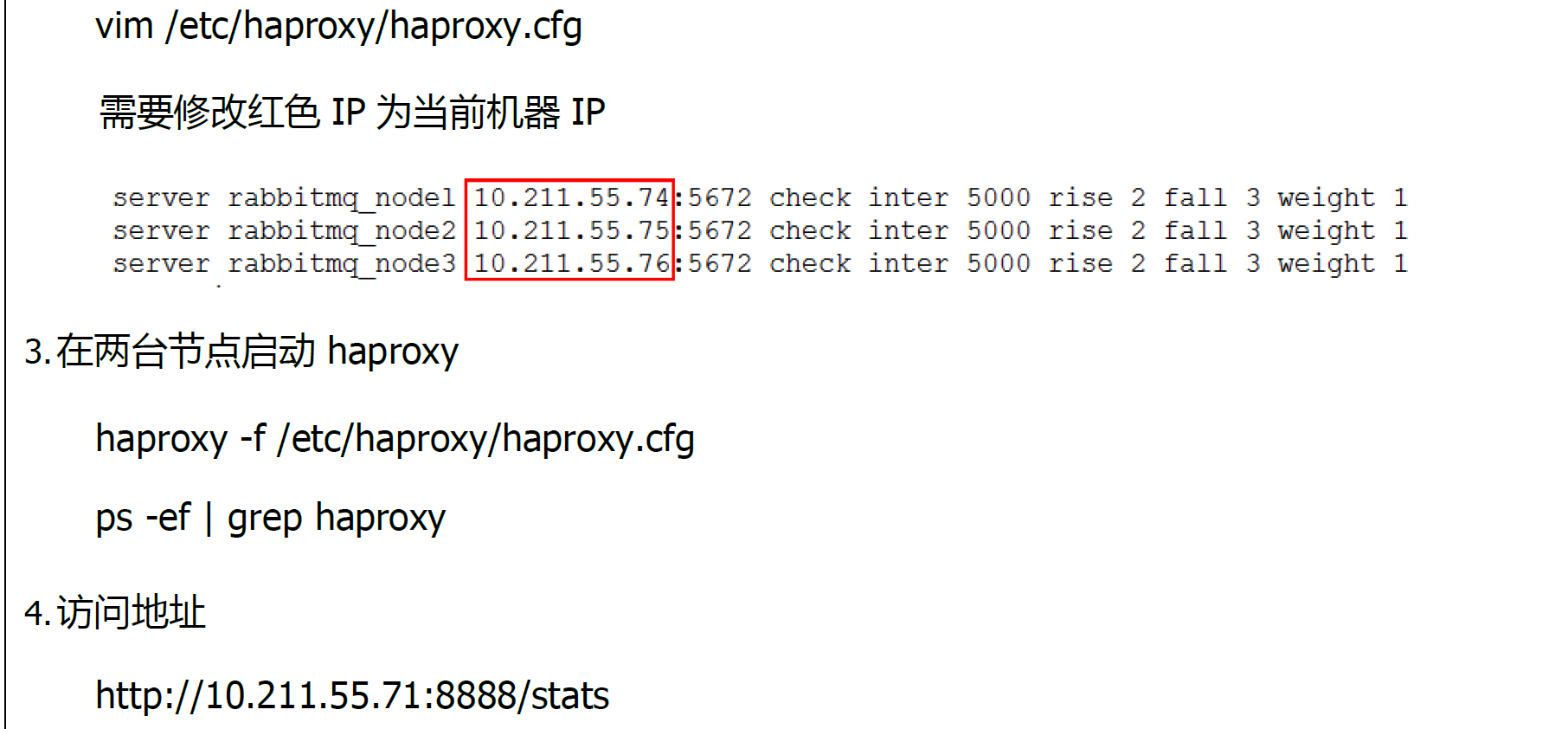
10.3.3 搭建步骤

10.3.4. Keepalived 实现双机(主备)热备
试想如果前面配置的 HAProxy 主机突然宕机或者网卡失效,那么虽然 RbbitMQ 集群没有任何故障但是对于外界的客户端来说所有的连接都会被断开结果将是灾难性的为了确保负载均衡服务的可靠性同样显得十分重要,这里就要引入 Keepalived 它能够通过自身健康检查、资源接管功能做高可用(双机热备),实现故障转移.
10.3.5 搭建步骤


10.4. Federation Exchange
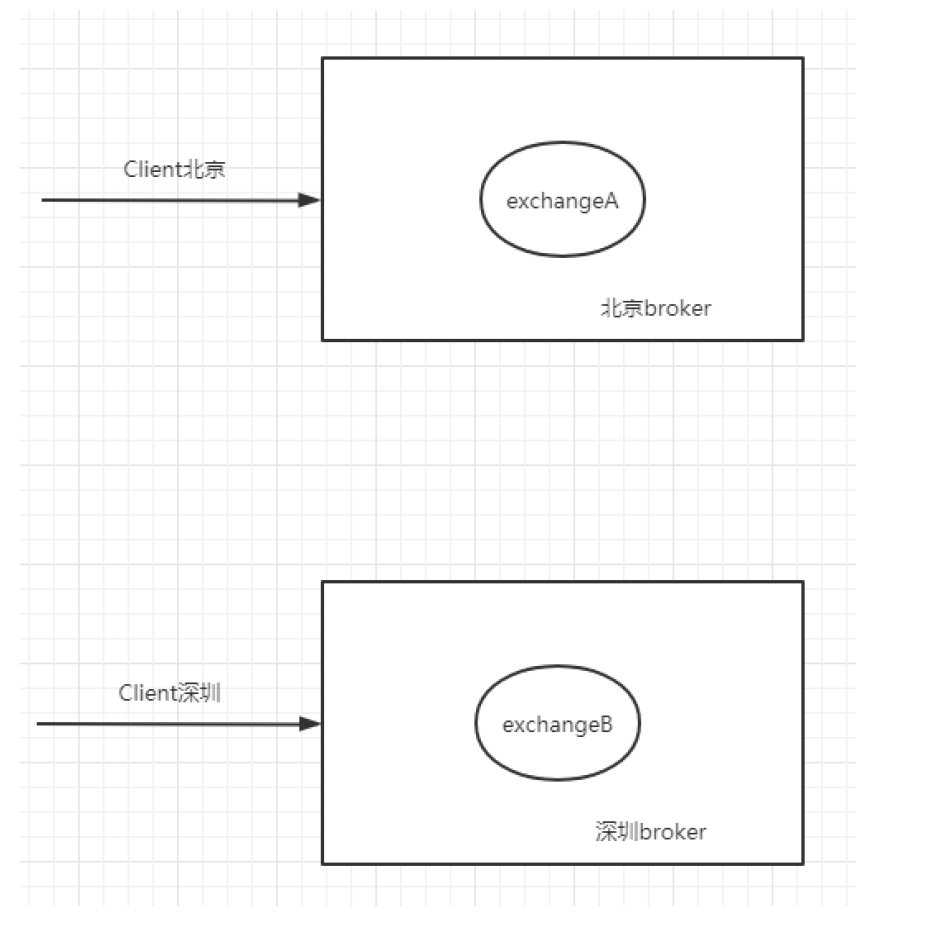
10.4.1. 使用它的原因

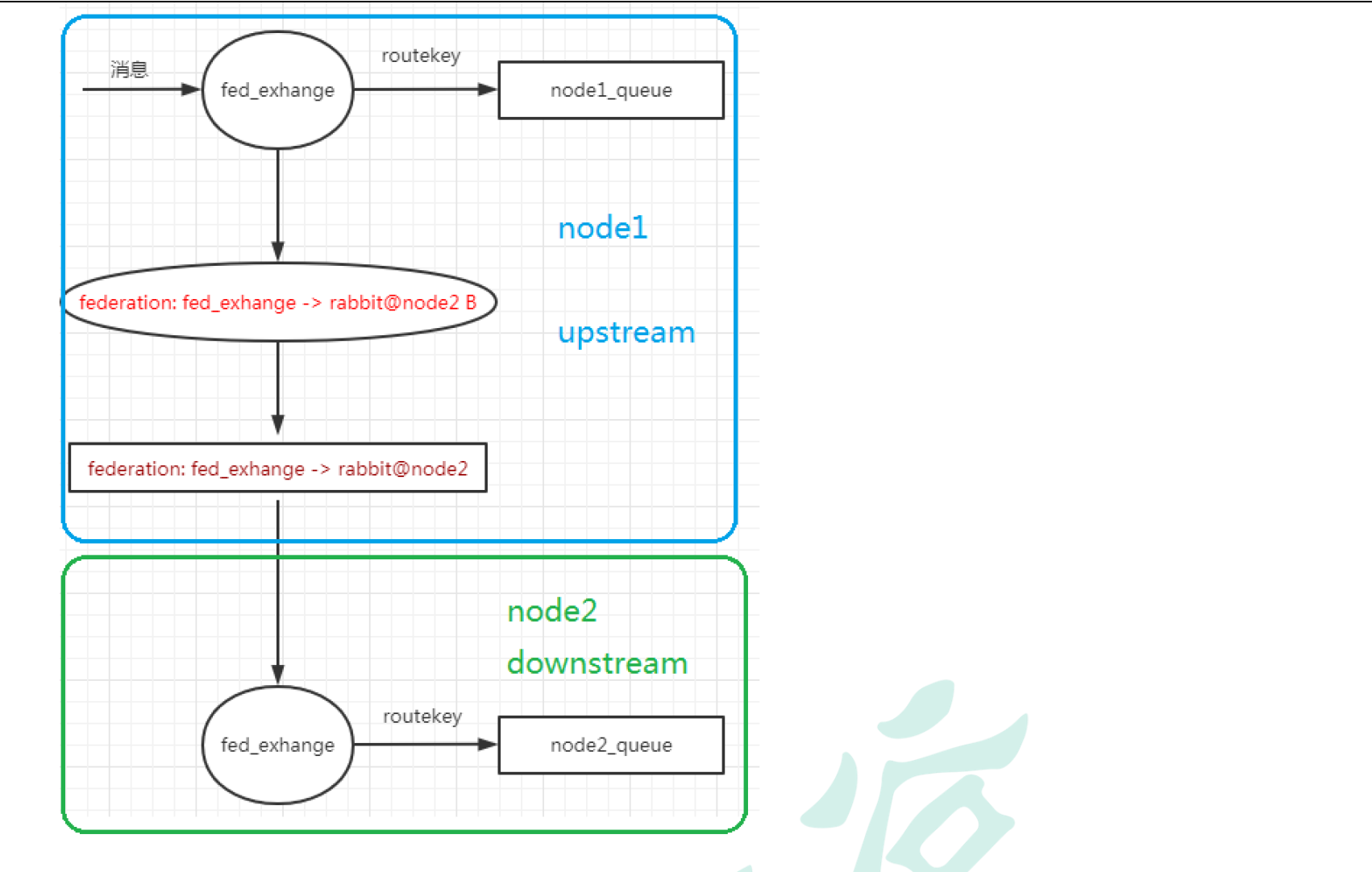
10.4.2 搭建步骤

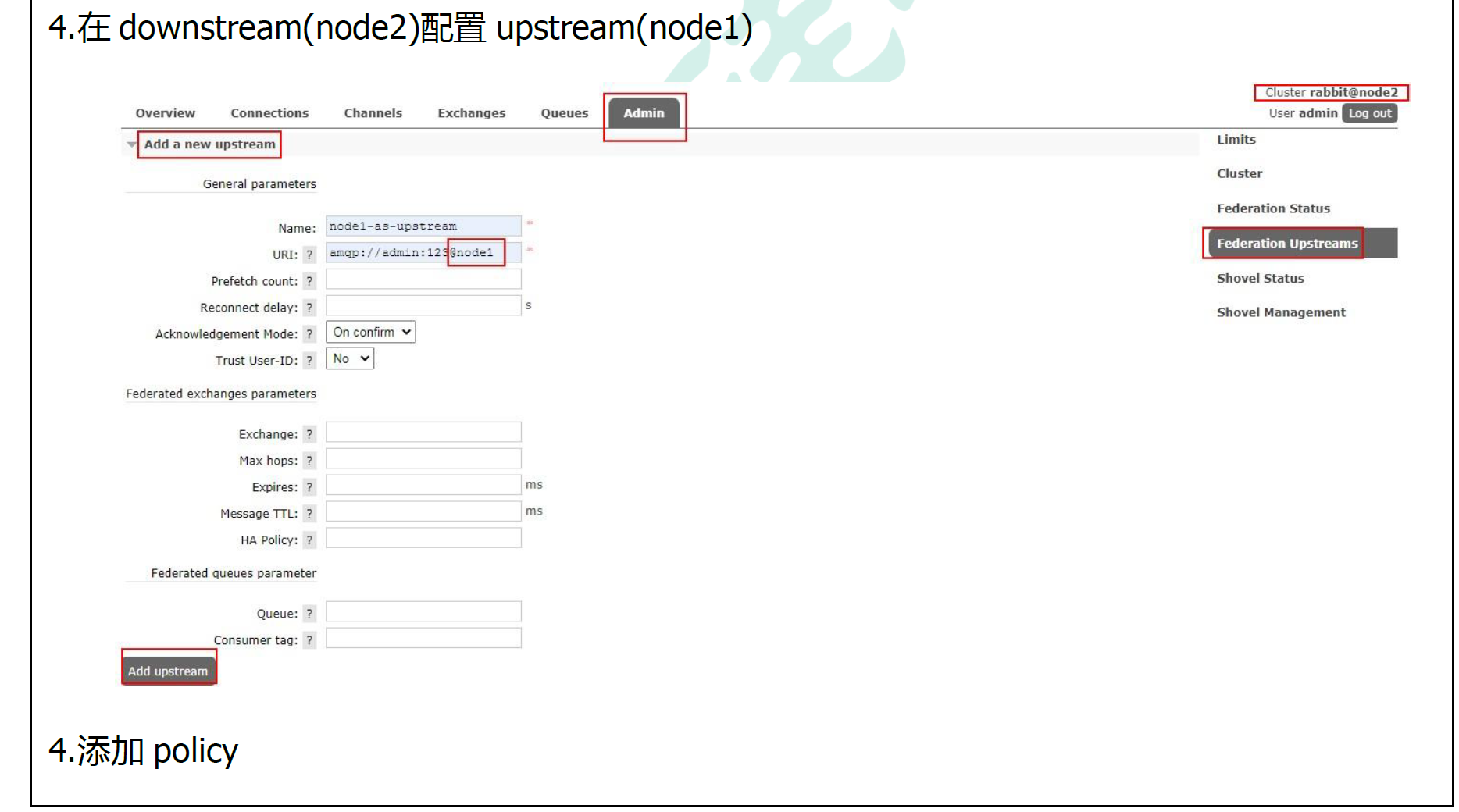
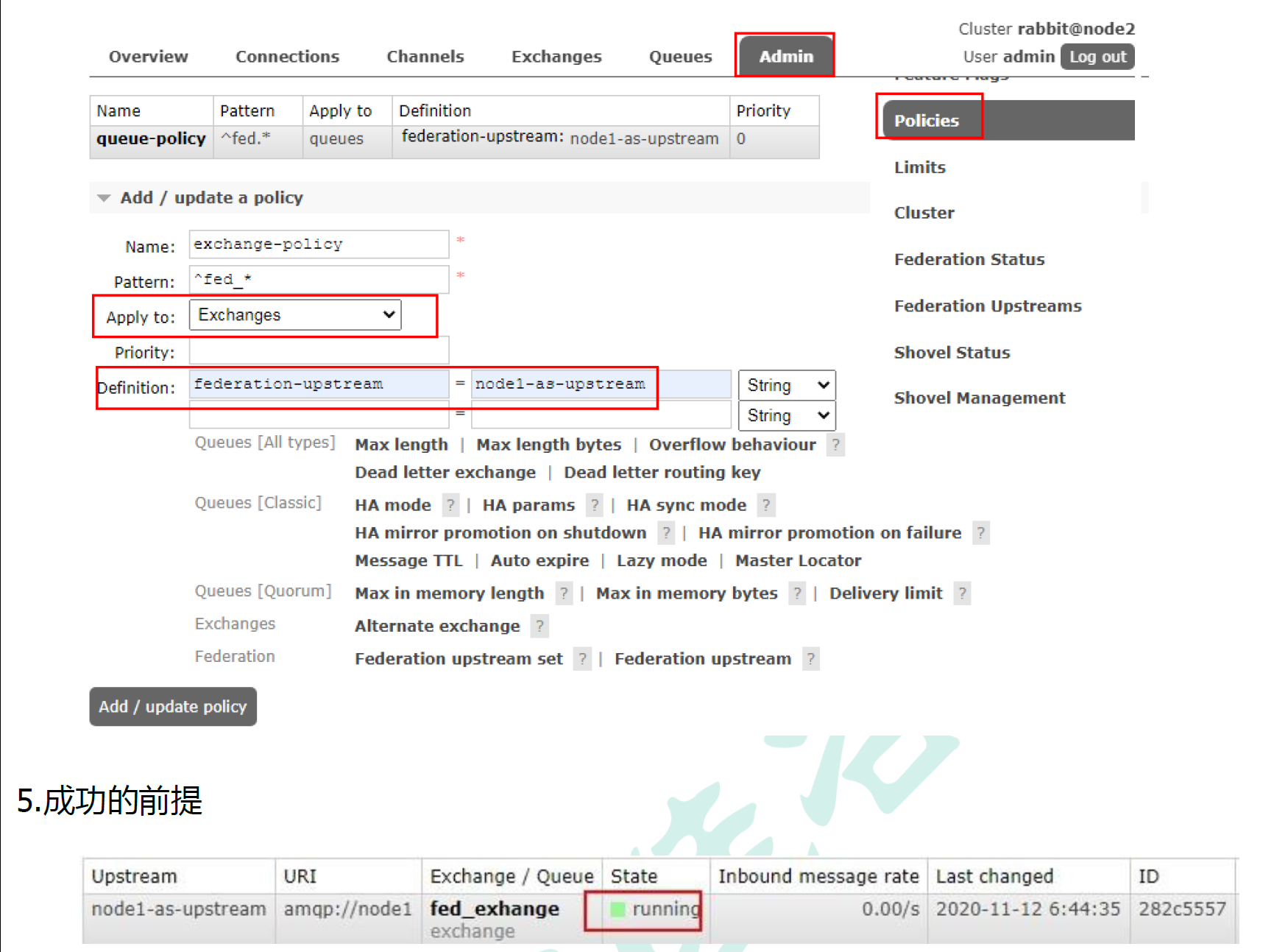
10.5. Federation Queue
10.5.1. 使用它的原因
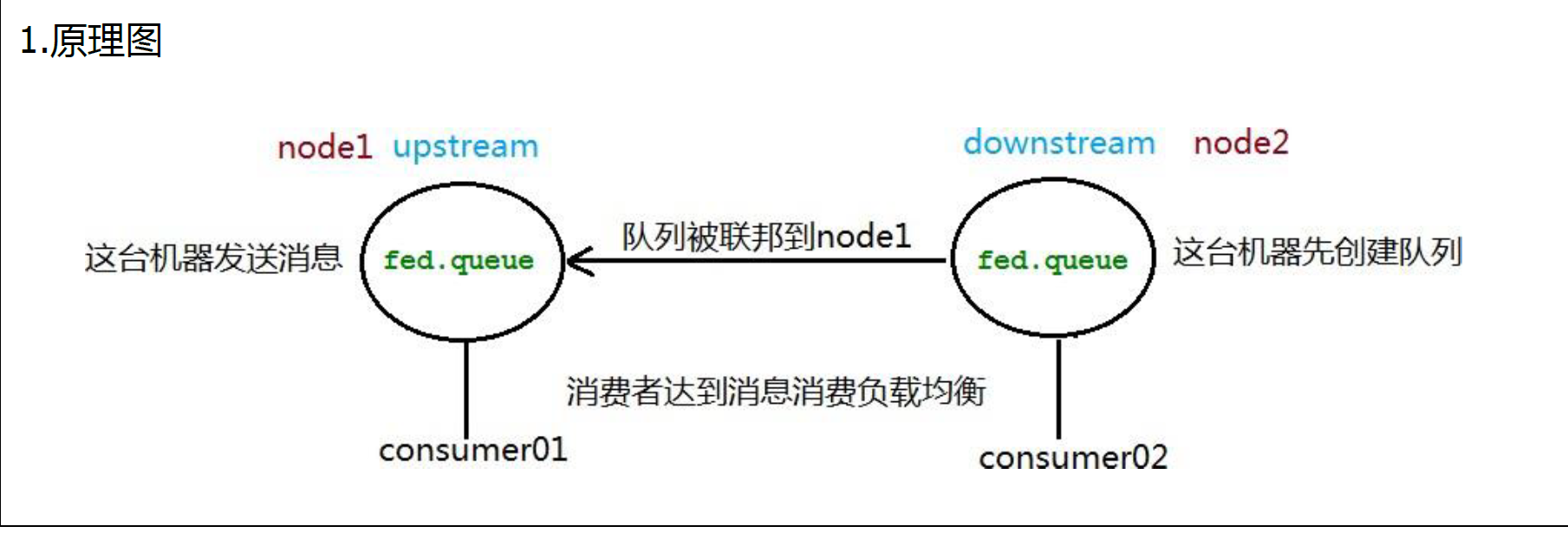
联邦队列可以在多个 Broker 节点(或者集群)之间为单个队列提供均衡负载的功能。一个联邦队列可以连接一个或者多个上游队列(upstream queue),并从这些上游队列中获取消息以满足本地消费者消费消息的需求。
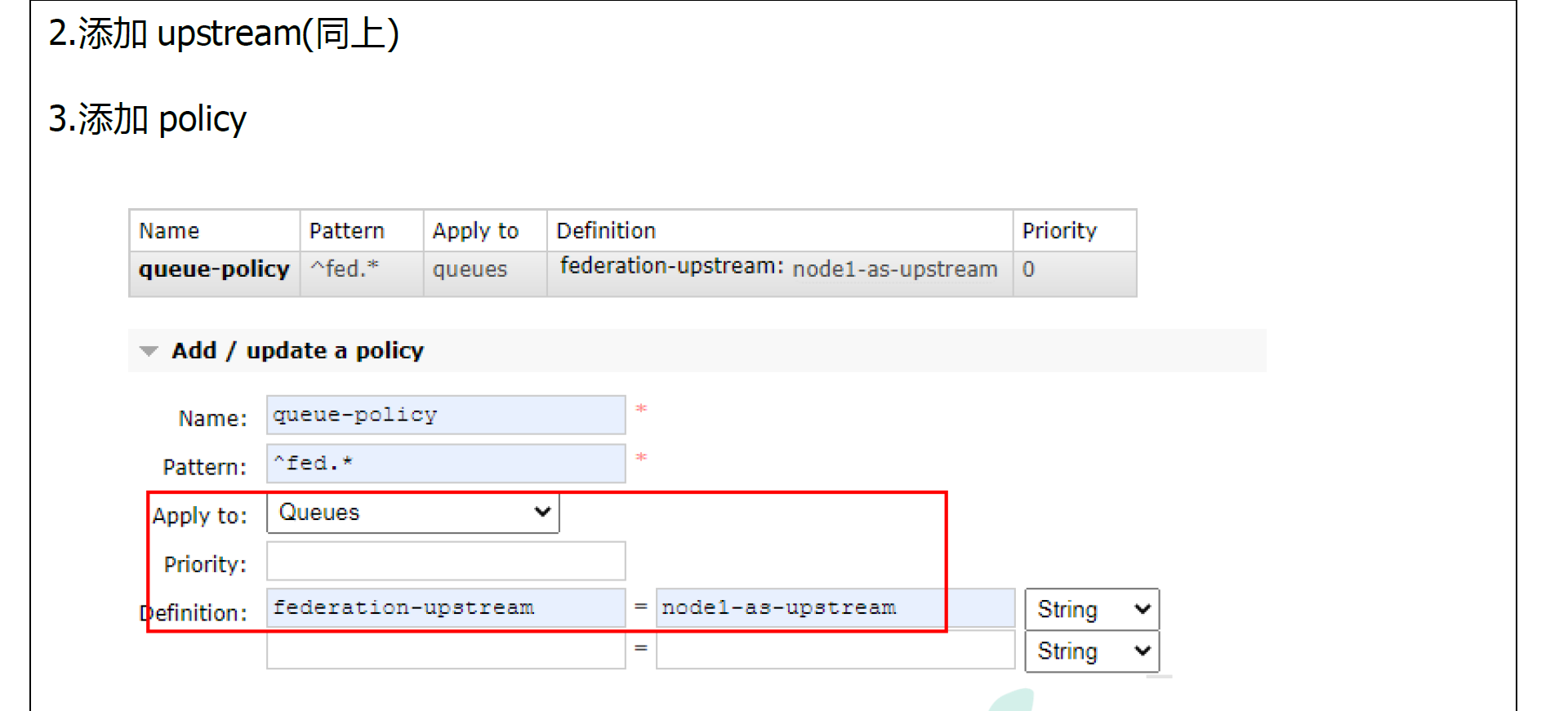
10.5.2 搭建步骤
10.6. Shovel
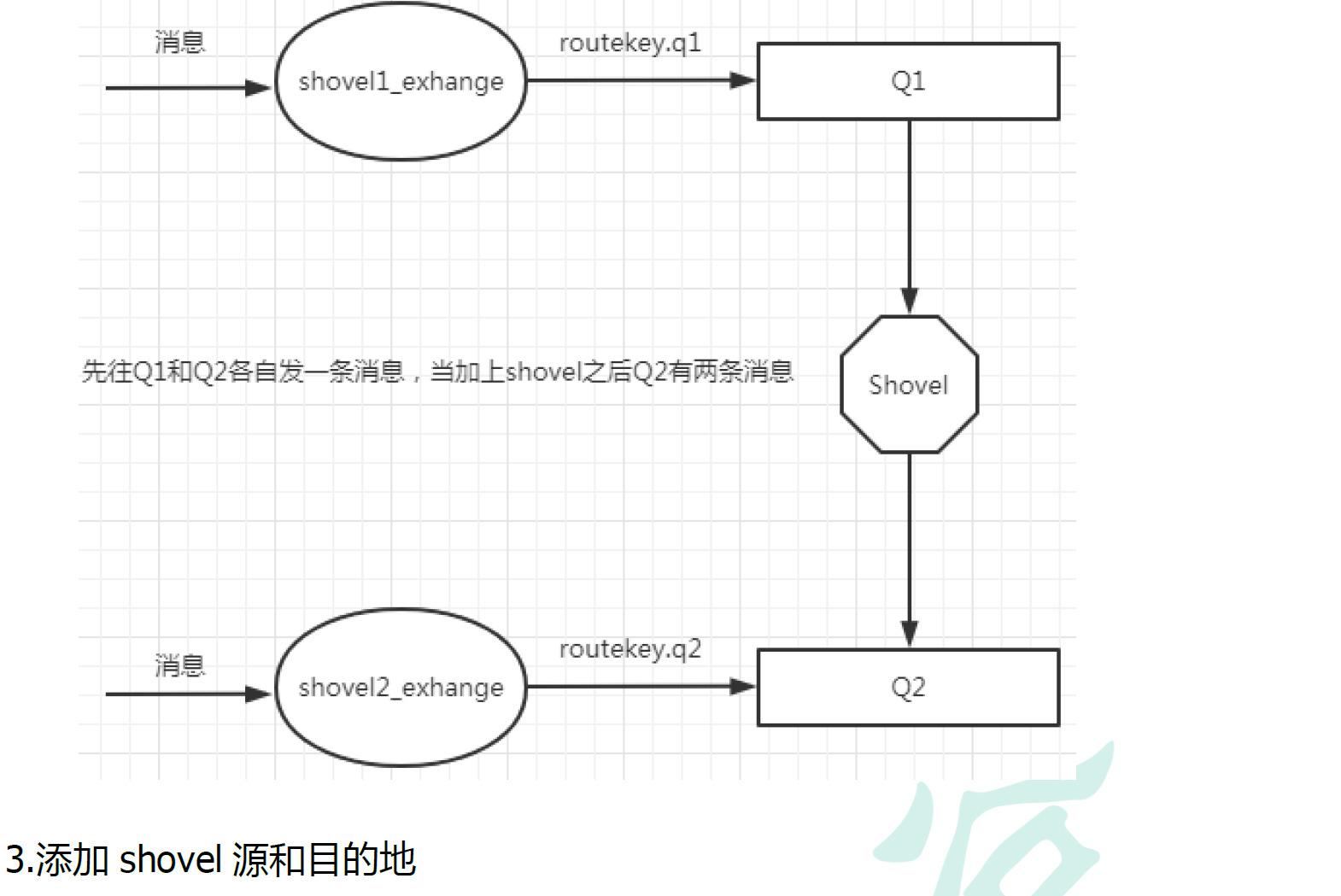
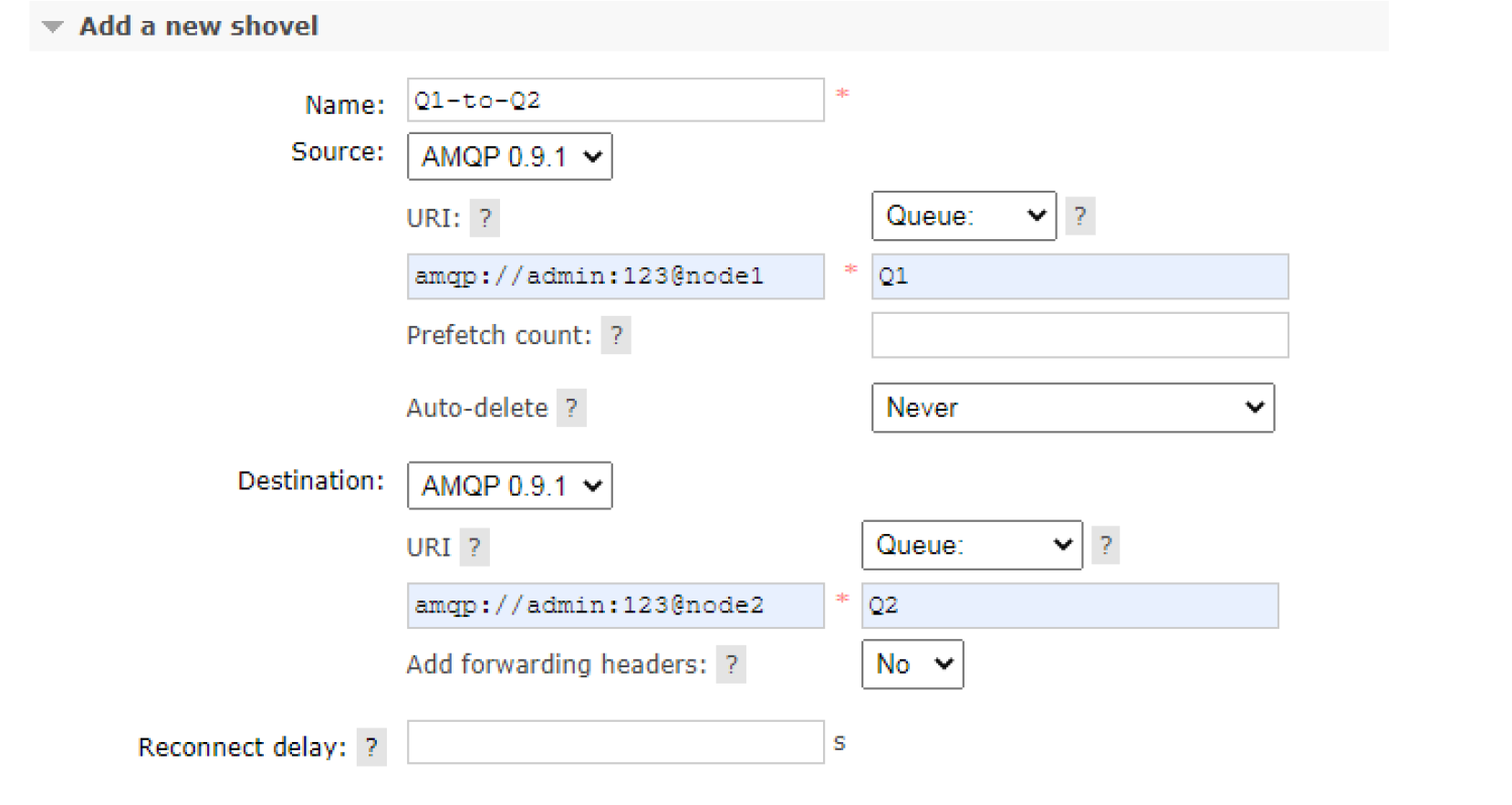
10.6.1. 使用它的原因
Federation 具备的数据转发功能类似,Shovel 够可靠、持续地从一个 Broker 中的队列(作为源端,即source)拉取数据并转发至另一个 Broker 中的交换器(作为目的端,即 destination)。作为源端的队列和作为目的端的交换器可以同时位于同一个 Broker,也可以位于不同的 Broker 上。Shovel 可以翻译为"铲子", 是一种比较形象的比喻,这个"铲子"可以将消息从一方"铲子"另一方。Shovel 行为就像优秀的客户端应用程序能够负责连接源和目的地、负责消息的读写及负责连接失败问题的处理。
10.6.2. 搭建步骤

后记
感谢尚硅谷王旭老师的课程讲解和课件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号