全文索引:Apache Lucene(一)
做网站门户,全文检索功能必不可少。如何快速、准确的罗列出用户想要的查询结果,是查询的主要目标。模糊查询是最常见的查询,在做单一模块时,我们通常用Like来检索。【like '%张%'】即检索含有 '张' 字符的项,是从头开始-->的全文匹配。Like的查询原理就是使用索引和匹配算法,如果该字段的值符合匹配模式,那么这条记录就会被选中。在使用了通配符%后,查询效率会大大降低,因为需要扫描整张表【注:当需要频繁使用 Like 查询,建议在数据库中为相应的字段建立索引】。对于数据量小时,Like的查询效率还算可以,但数据量大时每一次的查询扫描全表,查询效率大大降低。索引是对数据库表中一列或多列的值进行排序的一种结构,建立索引之后字段会排序变成有规则的结构性项,如a,b,c,d。查询字段时。 对没有建立索引的字段进行Like查询,是对非结构性字段从第一条到表的最后一条选中匹配结果;当字段建立索引时,查询可以快速的定位到含查询词的项进行匹配,不必查询整个表。
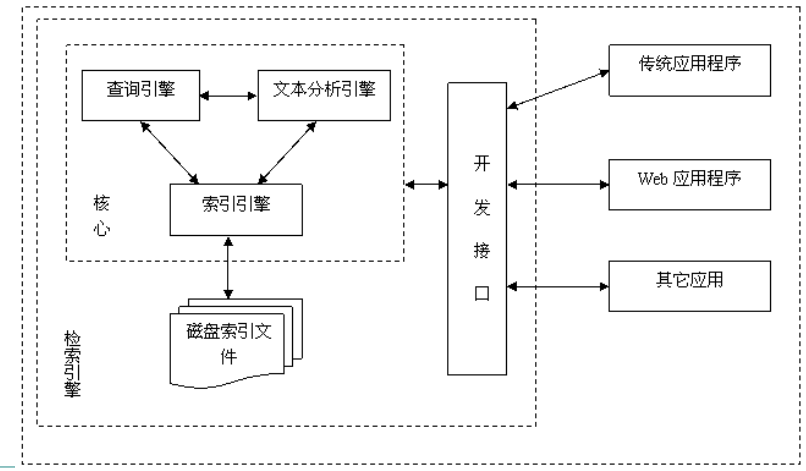
而网站门户的全文检索,不仅仅是对单表的查询,应当是对整个网站的公示信息进行查询。比如你是个政府网站,全文检索应该包含:办事服务,政务动态,政策文件,互动交流,信息公开等。再用Like单表来拼接结果的想法显然靠不住,这时候Apache Lucene就登场了。Apache Lucene是一个开源的高性能、可扩展的信息检索引擎,提供了强大的数据检索能力。后面再归纳Lucene的原理,这篇先写实现。
1 首先引入lucene相关jar包,pom.xml添加
<lucene.version>5.5.2</lucene.version>
<!-- lucene依赖 --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> --分词器 <version>${lucene.version}</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-backward-codecs</artifactId> --用于读取旧版本的索引,实现索引格式化 <version>${lucene.version}</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> --核心处理:解析,解码,存储格式,索引,搜索,存储和工具类 <version>${lucene.version}</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-highlighter</artifactId> --文本高亮 <version>${lucene.version}</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-memory</artifactId> --内存 <version>${lucene.version}</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> --解析构建Query对象 <version>${lucene.version}</version> </dependency>
2 抽出一个对象类来负责全文检索。该对象按照需求添加属性:如id,标题,分类,时间,请求路径(pc,移动端)
//搜索结果entity
public class SearchResult { private String id; private String title; // 用于查询和显示的摘要信息 private String category; // 分类 private String time; // 文章或消息创建时间 private UrlParam urlParam; // 详情请求路径,包含参数设置 private UrlParam mobileParam; // 移动端请求路径,包含参数设置 }
//URL参数
public class UrlParam { private String path; // 请求路径 private String id; // id参数 private String category; // 分类参数 }
3 在启动服务时以及定时任务,建立及更新索引:


/** * 创建索引 */ public void creatIndex(){ System.out.println("----------------删除索引----------------"); try { searchDao.delete(); } catch (IOException e) { e.printStackTrace(); System.out.println("删除索引失败"); } int count =0; starmili = System.currentTimeMillis(); System.out.println("----------------开始创建索引----------------"); try{ //办事服务 count += addWorkToIndex(); //政策文件 count += addArticleToIndex(); //信息公开 count += addInformationToIndex(); }catch(Exception e){ e.printStackTrace(); System.out.println("创建索引失败"); } endmili = System.currentTimeMillis(); System.out.println("成功创建索引:" + count + " 个,共耗时:" + (endmili - starmili) + "毫秒"); System.out.println("----------------创建索引结束----------------\n\n"); } //获取办事服务数据加入索引 private int addWorkToIndex(){ List<SearchResult> resultList = new LinkedList<SearchResult>(); List<Workinfo> workinfolist = workService.findList(new Workinfo()); if(workinfolist != null && !workinfolist.isEmpty()){ for(Workinfo work : workinfolist){ SearchResult result = new SearchResult(); result.setId(work.getId()); result.setTitle(work.getTitle()); result.setCategory(SearchEnum.WORKINFO.getCategory()); result.setTime(work.getCreateDate()); // 详情请求路径 UrlParam urlParam = new UrlParam(); urlParam.setPath(SearchEnum.WORKINFO.getPath()); urlParam.setId(work.getId()); urlParam.setCategory(SearchEnum.WORKINFO.getCategory()); result.setUrlParam(urlParam); // 移动端 UrlParam mobileParam = new UrlParam(); mobileParam.setPath(SearchEnum.WORKINFO.getMobilePath()); mobileParam.setId(work.getId()); mobileParam.setCategory(SearchEnum.WORKINFO.getCategory()); result.setMobileParam(mobileParam); resultList.add(result); } return searchDao.createIndex(resultList); } return 0; } //获取政策文件数据加入索引 private int addArticleToIndex(){ List<SearchResult> resultList = new LinkedList<SearchResult>(); List<Article> articlelist = articleService.findList(new Article()); if(articlelist != null && !articlelist.isEmpty()){ for(Article art : articlelist){ if(art != null && art.getCategory() != null){ SearchResult result = new SearchResult(); result.setId(art.getId()); result.setTitle(art.getTitle()); result.setCategory(art.getCategory().getName()); result.setTime(art.getCreateDate()); // 详情请求路径 UrlParam urlParam = new UrlParam(); urlParam.setPath(SearchEnum.ARTICLE.getPath()); urlParam.setId(art.getId()); urlParam.setCategory(art.getCategory().getName()); result.setUrlParam(urlParam); // 移动端 UrlParam mobileParam = new UrlParam(); mobileParam.setPath(SearchEnum.ARTICLE.getMobilePath()); mobileParam.setId(art.getId()); mobileParam.setCategory(art.getCategory().getName()); result.setMobileParam(mobileParam); resultList.add(result); } } return searchDao.createIndex(resultList); } return 0; }
/** * 生成索引 * @param list * @return 生成索引数目 */ public int createIndex(List<SearchResult> list){ IndexWriter writer = null; FSDirectory dir = null; Analyzer analyzer = null; int count = 0;//计数器 try { String indexPath = '索引存放位置'; dir = FSDirectory.open(Paths.get(indexPath)); analyzer = new StandardAnalyzer(); IndexWriterConfig config = new IndexWriterConfig(analyzer); writer = new IndexWriter(dir, config); for(SearchResult result : list){ Document doc = new Document(); doc.add(new StringField(SearchResult.SERACH_ID, result.getId(), Store.YES)); doc.add(new TextField(SearchResult.SERACH_TILTE, result.getTitle(), Store.YES)); doc.add(new TextField(SearchResult.SERACH_CATEGORY, result.getCategory(),Store.YES)); doc.add(new StoredField(SearchResult.SERACH_TIME, result.getTime())); doc.add(new StoredField(SearchResult.SERACH_URL, result.getUrlParam().getUrl())); doc.add(new StoredField(SearchResult.SERACH_MOBILE_PATH, result.getMobileParam().getUrl())); writer.addDocument(doc); count++; } writer.commit(); } catch (IOException e) { e.printStackTrace(); } finally { analyzer.close(); try { writer.close(); } catch (IOException e) { e.printStackTrace(); } dir.close(); } return count; }
4 查询功能的实现
/** * 查询 * @param question 模糊字符 * @throws IOException */ public List<SearchResult> getResult(String question) throws Exception{ if(StringUtils.isNotEmpty(question)){ question = question.replaceAll(";", "").replaceAll(";", "").replaceAll("\\[", "") .replaceAll("\\]", "").replaceAll("&", "").replaceAll("\\(", "").replaceAll("\\)", ""); } List<SearchResult> list = new LinkedList<SearchResult>(); IndexReader reader = getIndexReader(); reader.incRef(); IndexSearcher indexSearcher = new IndexSearcher(reader); Analyzer analyzer = new StandardAnalyzer(); QueryParser parse = new MultiFieldQueryParser(new String[]{"title","category"}, analyzer); //标题和分类进行检索 Query query = parse.parse(question); TopDocs topDocs = indexSearcher.search(query, 200); ScoreDoc[] scoreDocs = topDocs.scoreDocs; for(ScoreDoc scoredoc : scoreDocs){ Document doc = indexSearcher.doc(scoredoc.doc); SearchResult result = new SearchResult(); result.setId(doc.get(SearchResult.SERACH_ID)); result.setCategory(doc.get(SearchResult.SERACH_CATEGORY)); result.setTitle(toHighlighter(query, doc, SearchResult.SERACH_TILTE, analyzer, true)); //高亮 result.setTime(doc.get(SearchResult.SERACH_TIME)); result.setUrl(doc.get(SearchResult.SERACH_URL)); result.setMobilePath(doc.get(SearchResult.SERACH_MOBILE_PATH)); list.add(result); } indexreader.decRef(); return list; } //获取Indexreader private IndexReader getIndexReader(){ try { Directory directory = FSDirectory.open(Paths.get(indexPath)); if(indexreader == null){ indexreader = DirectoryReader.open(directory); }else{ IndexReader tempReader = DirectoryReader.openIfChanged((DirectoryReader)indexreader);//如果索引有变更,则生成新的IndexReader if(tempReader != null){ indexreader.close(); indexreader = tempReader; } } } catch (IOException e) { e.printStackTrace(); } return indexreader; }
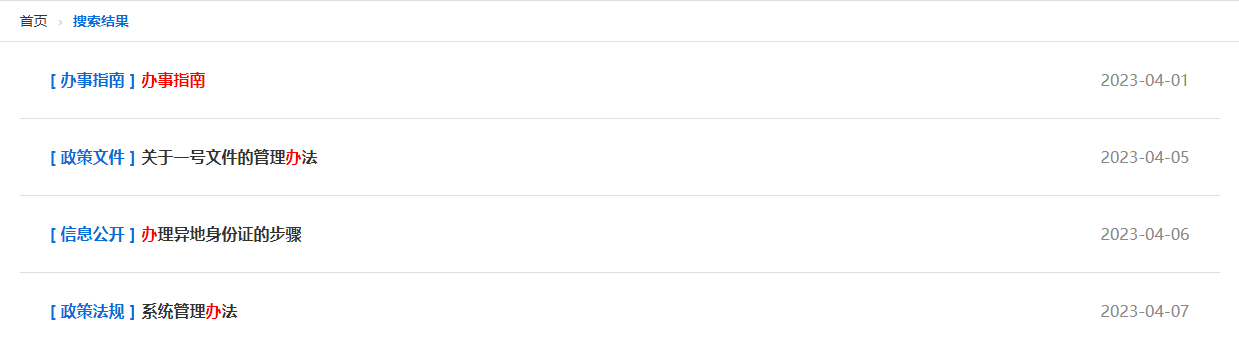
5 效果展示,全文检索:办事指南

 浙公网安备 33010602011771号
浙公网安备 33010602011771号