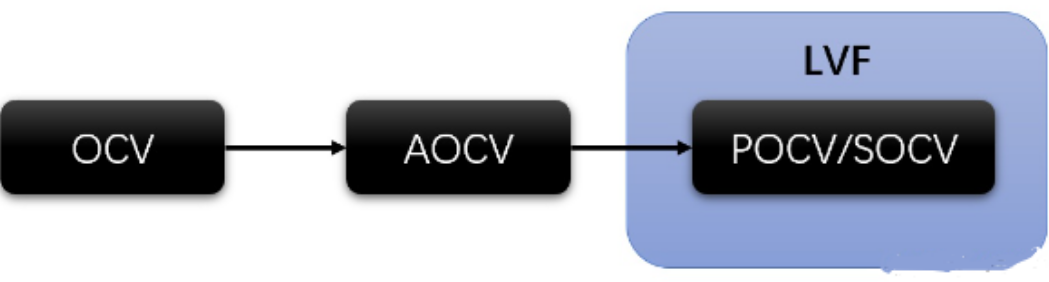
后端基础——OCV
本文参考资料:
数字IC后端知识扫盲——OCV(上)_bendandawugui的博客-CSDN博客
数字后端知识点扫盲——OCV(下)_数字后端pocv_bendandawugui的博客-CSDN博客
科普:OCV、AOCV、POCV、LVF都有什么作用? (qq.com)
芯片在实际生产中,同一片晶圆上的不同区域的芯片,因为各种外部条件和生产条件的变化(variation)比如:工艺*(process),电压(Voltage),温度(Temperature),可能会产生不同的误差从而导致同一块晶圆上某些区域上的芯片里的晶体管整体速度变快或变慢,因此有了corner的概念,与此同时,在同一块芯片上的不同区域,也会因为上述因素而有进一步的差异(variation),因此产生了OCV(On chip Variation)的概念。在设计中引入OCV的目的在于从设计角度考虑芯片在实际生产中可能出现的各种差异(variation)从而适度增加设计裕量(margin),减少不必要的设计悲观量(permission)
从OCV的概念出现至今,随着工艺的发展,OCV也经历了如下的一系列进化:
一,OCV产生的原因
在实际生产中,由于各种variation可能会出现如下情况:
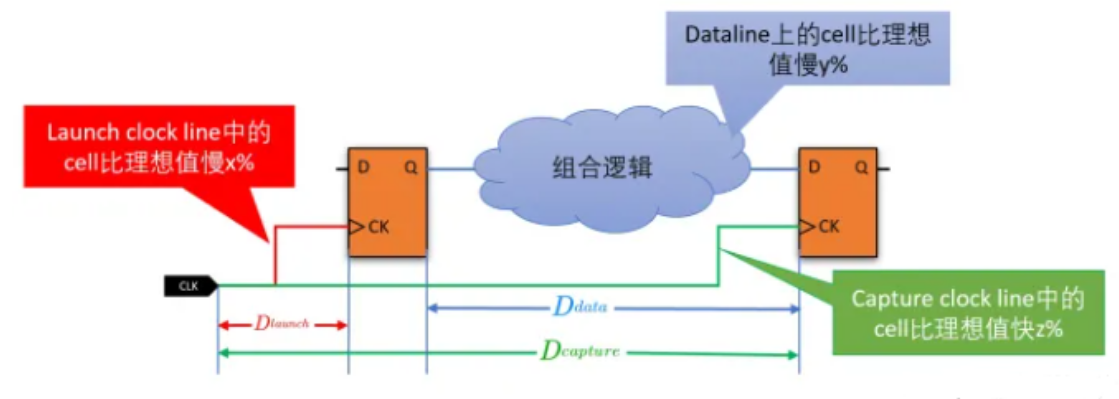
因此,只满足理想状态下setup的电路时不一定能够满足上述条件的,这样就会导致实际生产出来的芯片有一定概率不能满足需要的频率等条件,严重的甚至会导致芯片失效而降低良率。
二,OCV
它的基本思路时对launch,capture和data line上的cell或者net加一个固定的derate数值,使得setup和hold等时序约束比理想状况更加悲观从而能够覆盖部分实际生产中所产生的variation。通过这样的方法让时序约束更加悲观,一次来覆盖生产中和实际应用中的各种variation,提高良率。
三,AOCV
AOCV的概念之所以被提出来,是由于OCV存在以下缺点:在实际中的variation,绝少是一个统一的数值,而大概率是服从正太分布的,以一条timing path的data line为例,可能并不是所有的cell都因为variation而变慢或变快,而时大部分variation较小,少量variation较大,如果我们采用OCV的方式,就会引入不必要的悲观量使得设计更难收敛,同时可能增加不必要的面积和功耗。
针对这个问题,AOCV提出:对于一条path上,级数越多其variation分布越接近正太分布,因而这条path整体的variation也越小,在实际设计中,会根据一条line上cell的级数不同而设置不同的derate值,实现这种设置的方法是通过一种AOCV table来查表决定。
四,POCV
POCV,也称SOCV(Statistical On Chip Variation),就是将cell的delay模拟成一个数学期望为 μ ,标准差为 σ 的高斯分布。简单地讲,每个cell的delay都有最高的概率出现在期望值上,有一定的概率出现在大于或者小于期望值一定范围内的区间上。
五,LVF
从它的名字Liberty Variation Format我们可以看出LVF是一种和liberty库文件(.lib)有关的数据格式。
我们知道一般情况下无论是AOCV或者POCV,都会有一个专门的文本文件通过特定的命令读取到工具中。以PrimeTime为例,读取AOCV和POCV的命令如下:
read_aocvm $file_name而除了这种方式之外,我们还有另外一种选择:将POCV的内容集成到类似于liberty文件中,目前在尖端工艺中,POCV和LVF都在渐渐普及,如果有在做相关项目的童鞋,希望借此机会好好注意项目中是如何使用它们的,这将有助于我们深入理解它们的应用。
总结:OCV就是在同一块芯片上的晶体管也会有变快或者变慢的现象。derate就是在launch、capture、data line的cell或者net上加上一个比理想情况更为悲观的倍数。比如说设置成1.1,就表示delay变成之前的1.1倍;如果涉及到common path,可用cppr将悲观量移除。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号