DQN 文章第一篇
我希望用DQN来做东西, 首先整理一下我从网上看到教程。我个人的要求不是对这个算法有透彻的了解,而是学会怎么用。那么我首先想了解大概的原理,以便能对人家写的程序的一些变量和过程能够了解一点,下面是我自己对看的资料的了解。
http://m.blog.csdn.net/article/details?id=27649323
这篇教程通俗易懂,是一份很不错的学习理解 Q-learning 算法工作原理的材料。作者首先以一个多个房间的例子,将从房间内走出去大楼外的问题建模成一个图的问题,图中的点分别赋予不同的权值。只有达到大楼外的边才会被赋值为100.

介绍了相关的术语:状态(state)和行为(action)。联系上面的图,再把这个图根据state和action建立成一个reward值的矩阵。
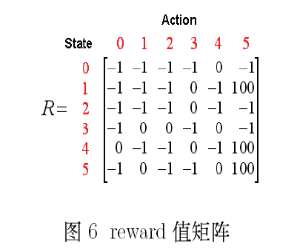
同样,也可以构建一个矩阵Q,代表agent已经从经验学习到的东西。Q中的状态,可以是已经全知道的,也可以是未知的。Q-learning算法的转移规则:


episode:是agent的每一次探索的说法。再每一个agent从任意状态到达目标状态,当agent到达目标状态后,一个episode就结束,然后接着进入另外一个episode。
然后作者给出整个Q-learning的计算步骤:

agent利用上面的方法学习经验,每个episode相当于一个training,并接受外界的reward。训练的目的就是要强化agent的“大脑”(Q)。
参数γ的值是0和1之间,用于表示,0是趋向于imediate reward,1趋向于future rewards。
利用训练好的Q,可以找出从状态S0到目标状态的一种路径。具体步骤如下

这上面,是作者利用一般的语言来进行对Q learning的一般原理阐述,下面是1.2小节的开始,使用一个例子来进行实践。
还是上面的例子,在这里开始进行一步一步的迭代,进一步了解Q-learning所能够做的事情。
取γ=0.8,初始房间为1,Q的意义是经验矩阵,刚开始,没有经验,设置为0.同样引用上面的Reward矩阵
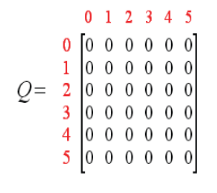

从R图可以看到,1可以到3,也可以到5.这里就会发生一个随机,有可能到5,也有可能到3.
情况1:从1到5,到了5之后,从R图得知(此后不再说从R图得知),它能够发生到到达1,4,5
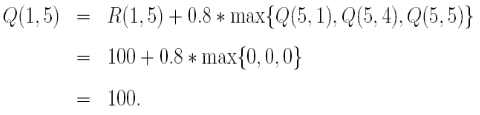
那么Q就会刷新为
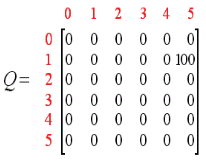
到这儿,因为到达了状态5,就已经结束了这次episode。
下一个episode开始,假设从3开始,能够转到状态1,2,4。这儿,随机选取了1,然后又计算Q,可以得到Q(3,1)
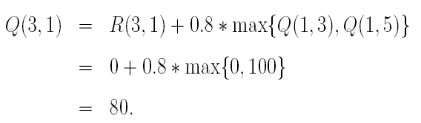
然后,又可以刷新Q了,得到已经的值。
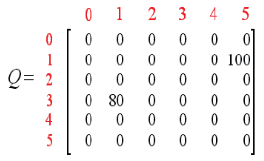
现在状态转换为1,但是还不是目标状态,接下来,可能转换为3或5,再一次,我们选5(实际上是随机的). 这时又一次计算了Q(1,5)。这时,Q并没有变化。
再多次episode之后,能够得收敛为下图
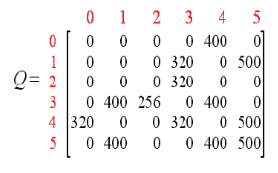
进行规范化,每个都除以5(这个就像是一个平均化).可以得到
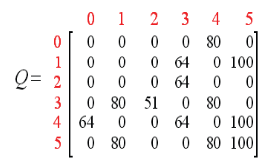
状态收敛好,agent就会得到以下面最优的路径。

这个图能够得出,初始状态是的话,2到3是最大的,所以会走3,然后可以从1和4都是相同,最后能够到达
