Hazel引擎学习(六)
我自己维护引擎的github地址在这里,里面加了不少注释,有需要的可以看看
How to Build a 2D Renderer
不管是3D还是2D的游戏引擎,都需要渲染2D的东西,因为一个游戏里是必须有UI的。
渲染架构
目前引擎里Render的代码是这样的:
// 把Camera里的VP矩阵信息传到Renderer的SceneData里
Hazel::Renderer::BeginScene(m_Camera);
{
glm::mat4 scale = glm::scale(glm::mat4(1.0f), glm::vec3(0.1f));
...
flatColorShader->UploadUniformVec4("u_Color", m_FlatColor);
// Submit里面会bind shader, 上传Vertex Array, 然后调用DrawCall
Hazel::Renderer::Submit(flatColorShader, m_QuadVertexArray, transform);
...
Hazel::Renderer::Submit(textureShader, m_QuadVertexArray, transform);
...
}
Hazel::Renderer::EndScene();
这里面的操作基本就是,设置统一的SceneData后,针对各个VertexArray,也就是Mesh,提交其Mesh数据,然后添加对应的Draw的命令。
但这套操作,对于绘制2D的内容而言,不太符合,有这么几个原因:
- 2D的渲染过程中,基本没有Mesh这个概念,它不需要Vertex Array,因为万物皆可用Quad来表示
- 2D的渲染,也没啥Shader和Material的概念,因为它就是一张图贴上去而已,还要啥渲染(感觉加点类似光照的后处理是不是就行了)?
那么如何设计相关的2D渲染呢,由于3D渲染和2D渲染的相机不同,这里直接可以分为两个Scene,然后设置不同的Renderer即可设计两种Renderer,分别负责2D和3D的内容,大概是这样:
Hazel::Renderer::BeginScene(m_Camera);
{
Hazel::Renderer::DrawCube(...);// 3D
...
}
Hazel::Renderer::EndScene();
Hazel::Renderer2D::BeginScene(m_OrthographicCamera);
{
Hazel::Renderer2D::DrawQuad(...);// 2D
...
}
Hazel::Renderer2D::EndScene();
2D Renderer需要支持的内容
2D的Renderer主要需要实现以下内容:
- 2D Batch Render: 支持批处理的2D Renderer,主要是合并多个Quad的Geometry
- Texture Atlas的支持
- Sprite Animation系统
- 贴图Data压缩技术:大概是只保留第一帧的全数据,后面都只记录产生变化的像素的Delta值,主要是为了支持高精度的贴图,后面会细聊
- UI系统:主要是Layout系统,还挺复杂的,比如怎么布置UI、UI元素怎么随窗口变化而自动匹配、怎么对其Text、怎么支持不同分辨率的屏幕、Font文件的读取和使用(文字的SpriteSheet)
- 后处理系统:为了做好2D游戏,这个系统是必须的,比如做2D的爆炸特效、实现HDR、粒子系统、blur、bloom的后处理效果、Color Grading用于矫正颜色
- Scripting:暂时不需要考虑
不需要考虑的:
- Dynamic Lighting
在性能上,目标是实现每帧绘制10W个quad,而且fps在60以上。
关于BatchRenderer和Texture Atlas
目前是做2D的部分,那么先实现2D的quad的批处理即可,至于每帧的贴图个数,实际上游戏引擎里的需求,一般每帧用到一两百张贴图就已经很多了。假设GPU上有32个贴图槽位,假设其中的8个是用于其他需求的,不是用于直接渲染的,那么还剩24个槽位。那么120张贴图,就要Flush Renderer五次,也就是五次Draw Call。所以2D的渲染来说,Texture Atlas或者说Sprite Sheet,至关重要。就是在一张贴图上,尽可能多的存储贴图内容。当然,这种适合小的低像素的贴图,才能进行组合,如果是一个4K的贴图,那么一般是不会把它合并到Texture Atlas里面的。
关于Scripting
当谈到Game Engine与User的Interaction部分时,人们很容易想到ECS架构或者CGO(Composable GameObjects)。也就是说GameObject可以通过Component来组合,而不是代码里面的通过继承来组合(比如多重继承)。比如一个Player,是个Entity,然后里面添加各种Component,比如:
- Transform组件
- Renderer组件
- Script组件,用于负责Interaction和自定义行为
但这里提到的是Scriting。有的是用lua作为脚本语言,UE4里用蓝图作为可视化的脚本,还提供了U++;Frosbite里也提供了类似蓝图的schematics,Unity是C#,基本的游戏引擎都有这块部分。
Camera Controllers
在创建Renderer2D之前,还有些内容需要整理一下。比如这里的Camera系统,就非常的简陋。游戏里的Camera应该会暴露很多接口给User来使用,比如像这样的很多用户层面的比较直观内容:
而目前用户的代码,又不实用,又不直观,所以需要改引擎,让它暴露出一个Camera类,然后给更多用户级别可以调用的API。
创建OrthographicCameraController类
其实就是OrthographicCamera类的Wrapper类,它也能随着Game Loop不断调用OnUpdate函数,除了前面有的相机的移动和旋转功能,还应该补充这些东西:
- Zoom in/out,根据zoom的数值来调整对应的Projection Matrix
- 根据窗口Resize的事件,动态调整对应的Projection Matrix
- 一个小技巧,Camera水平移动的速度可以与Zoom的值成反比,Zoom越大,相机移动越慢
类声明如下,这里把CameraController设计为了单例类:
namespace Hazel
{
// 其实是个Camera的Wrapper
class OrthographicCameraController
{
public:
// 这里有个比较特别的公式, 就是根据aspectRatio和zoomLevel生成对应的正交投影矩阵的大小
// glm::ortho(-aspectRatio* zoomLevel, aspectRatio* zoomLevel, -zoomLevel, zoomLevel, -1.0f, 1.0f)
OrthographicCameraController(float aspectRatio, float zoom);
void OnUpdate(const Timestep&);
void OnEvent(Event&);
private:
void OnZoomCamera(float scrollOffset);
private:
float m_Zoom = 1.0f;
float m_Radio = 1.66667f;
float m_ZoomSpeed = 120.0f;
float m_RotateSpeed = 20.0f;
bool m_Rotatable = true;
OrthographicCamera m_Camera;
};
}
最后再把ExampleLayer里的Camera改成CameraController即可。
Resizing
目前阶段,其实就是随着窗口的WindowResizedEvent,然后调用glViewport而已,但是未来还需要考虑FrameBuffer来响应WindowResizedEvent,比如说用FrameBuffer渲染一张贴图到屏幕上,那么当窗口Resize时,该FrameBuffer也应该调整渲染得到的贴图大小。顺便提一句,很多大型工程里,都涉及一个FrameBufferPool,避免重复创建内存。
这里还涉及到一个东西,就是相机如何根据窗口大小变化而变化,比如,当窗口变大时,画面是变大,还是会展示更多的内容?
这个问题是针对正交投影的相机的,而透视投影的相机不太需要考虑这个问题(具体原因不太清楚)。反正两种方法是都可以实现的,就看实际的需求了。如果窗口改变的时候,只调整Viewport,那么窗口里绘制的东西,会随着窗口变大而变大;如果不想改变尺寸,那么需要调整正交相机的投影矩阵,动态调整zoom和aspectRadio
然后还需要给Application类添加一个bool,标识窗口是否被缩小化了,缩小的时候,窗口的width和height都会接收WindowResizedEvent变成0,所以当缩小化时,需要停止各个Layer的更新。
Maintenance
这节课主要是优化现有的工程,具体有:
- 升级项目工程,目前是VS2017,感觉可以升级到2022(不过课里是升级到了2019)
- 整理代码结构,把一些代码移到Hazel/Src/Core文件夹下
升级项目工程
之前是用批处理命令,利用premake5.exe生成的工程:
call vendor\bin\premake\premake5.exe vs2017
PAUSE
所以要把vs2017改成2022,而且要更一下项目里的premake5.exe到最新
然后把批处理文件的路径修改一下,大概是这样,能支持多个平台(不过像MacOs这种其他平台的批处理文件,会有各自的后缀了):
此时的批处理文件为:
@echo off // 清除之前的命令行
// 这句话相当于cd..,d代表directory
pushd ..\
call vendor\bin\premake\premake5.exe vs2022
// 这句话代表会到原本的输入路径,d也是directory的意思,相当于cd originalFolder
popd
PAUSE
以后还可以添加Win-BuildSolution.bat,这样就能在生成Project之后,直接进行Build,得到游戏的exe文件,这就不用非得打开Visual Studio再去手动Build了。
谨慎升级Visual Studio版本
虽然这里升级VS版本看上去挺轻松的,但是对于大型项目而言,一定要谨慎升级Visual Studio版本。因为它升级的不只是版本,还有编译器,Complier本身就是存在bug的,当项目里有大量的宏、模板时,很有可能升级VS工程之后,项目就不能编译了。像这种情况一定要充分测试,要测试不同的配置:Debug或Release等,不能随便升级。
更改项目路径
下面这些移到Core文件夹,其他的移到Renderer文件夹,CameraController将就一下,放到Renderer里:
Preparing for 2D Rendering
这节课接受了一些github上的community contribution,具体有:
- 补充了各个平台的宏定义
- 当OpenGL版本太低会报错
比如:
namespace Hazel
{
void OpenGLContext::Init()
{
glfwMakeContextCurrent(m_Window);
...
// 检查OpenGL版本
#ifdef HZ_ENABLE_ASSERTS
int versionMajor;
int versionMinor;
glGetIntegerv(GL_MAJOR_VERSION, &versionMajor);
glGetIntegerv(GL_MINOR_VERSION, &versionMinor);
HAZEL_CORE_ASSERT((versionMajor > 4 || (versionMajor == 4 && versionMinor >= 5)), "Hazel requires at least OpenGL version 4.5!");
#endif
}
Starting our 2D Renderer
为了避免跟原本的3D的Renderer混淆,这里创建了个Renderer2D,内容也比较简单,里面全部都是静态函数,之所以不做成成员函数是因为没有必要,毕竟成员函数本质上也是静态函数,无非静态函数的第一个参数变成了this指针而已。
这里可以开始设计Renderer2D类了,这里设计的Renderer2D,与原本的Renderer类的区别在于:
- 2D渲染里没有什么Vertex Array和Mesh的概念,万物皆可用带贴图的quad绘制,所以这里只会有唯一的Mesh数据,所以这里直接把quad的顶点数据作为静态数组存在了Renderer2D类里,在其Init函数里被创建出来。
- 2D渲染里,基本不需要用户在绘制的时候传入自定义的Shader,所以Shader可以作为Renderer2D的静态数据
大概思路如下:
// Renderer2D的cpp里
struct Renderer2DStorage
{
std::shared_ptr<VertexArray> QuadVertexArray; // 一个Mesh, 代表Quad
std::shared_ptr<Shader> FlatColorShader; // 两个Shader
std::shared_ptr<Shader> TextureShader;
std::shared_ptr<Texture2D> WhiteTexture; // 一个默认贴图, 用于Blend等
};
// 定义静态的Data
static Renderer2DStorage* s_Data;
对应的类声明如下,基本没改什么东西,主要是取消了Submit函数,添加了DrawQuad函数,不需要Vertex Array数据:
class Renderer2D
{
public:
static void Init();
static void Shutdown();
static void BeginScene(const OrthographicCamera& camera);
static void EndScene();
// 绘制FlatColor的quad, vec2和vec3的position是为了加入depth信息
static void DrawQuad(const glm::vec2& position, const glm::vec2& size, const glm::vec4& color);
static void DrawQuad(const glm::vec3& position, const glm::vec2& size, const glm::vec4& color);
// 绘制Texture的quad
static void DrawQuad(const glm::vec2& position, const glm::vec2& size, const Ref<Texture2D>& texture);
static void DrawQuad(const glm::vec3& position, const glm::vec2& size, const Ref<Texture2D>& texture);
};
2D Renderer Transforms and Textures
这两节课没啥干货,就是在Shader里加了很多上传uniform到GPU的API,很简单,不多说,然后这节课还开启了depth test,就在之前开启Blend的位置,Texture的部分我已经加到DrawQuad对应的API里了
namespace Hazel
{
void OpenGLRendererAPI::Init() const
{
glEnable(GL_BLEND);
glBlendFuncSeparate(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA, GL_ONE, GL_ZERO);
glEnable(GL_DEPTH_TEST);
}
...
}
Single Shader 2D Renderer
目前的Renderer2D有两个Shader,FlatColorShader和TextureShader,其实可以把两个Shader合为一个Shader,毕竟Shader的编译还是要消耗不少性能的。
这么做的思路是,使用两个uniform,一个是代表color的float4的uniform,一个是代表texture的sampler2D的uniform,片元着色器如下所示:
#version 330 core
layout(location = 0) out vec4 color;
in vec2 v_TexCoord;
uniform vec4 u_Color;
uniform sampler2D u_Texture;
void main()
{
color = texture(u_Texture, v_TexCoord) * u_Color;
}
核心思路是,当我想要把Shader用作TextureShader时,那么传入我要渲染的Texture,u_Color传入(1,1,1,1)即可;当我想要把Shader用作FlatShader时,u_Color里传入我要显示的FlatColor,同时传入一个特殊的WhiteTexture,这个Texture的Sample的返回值永远是(1,1,1,1)。
代码如下:
struct Renderer2DStorage
{
std::shared_ptr<VertexArray> QuadVertexArray;
// std::shared_ptr<Shader> FlatColorShader; 原来的这行干掉了
std::shared_ptr<Shader> TextureShader;
std::shared_ptr<Texture2D> WhiteTexture;// 这张图是白色的, 用作FlatColor
};
现在的想法是,我runtime创建一个贴图,作为这个WhiteTexture,它的width和height均为1,图片通道格式为RGBA或者RGB,每个pixel的值都是(1,1,1,1)或(1,1,1)。但是目前的Texture2D没有这个功能,所以这里加一个API:
// 在原本的Texture的虚基类里加上这个接口
class Texture
{
public:
virtual ~Texture() = default;
virtual unsigned int GetWidth() = 0;
virtual unsigned int GetHeight() = 0;
virtual void SetData(void* data, uint32_t size) = 0;// 新加这行接口
virtual void Bind(uint32_t slot) = 0;
};
// 然后在具体的OpenGLTexture2D里实现这个虚函数
void OpenGLTexture2D::SetData(void * data, uint32_t size)
{
// bpp: bytes per pixel
uint32_t bpp = 4;// 默认是用RGBA的格式
HAZEL_CORE_ASSERT(size == m_Width * m_Height * bpp, "Data must be entire texture!");
// 可以通过`glTextureSubImage2D`这个API,为Texture手动提供数据,创建这个WhiteTexture
// 注意这里的格式是GL_RGBA, 这是贴图的DataFormat
glTextureSubImage2D(m_TextureID, 0, 0, 0, m_Width, m_Height, GL_RGBA, GL_UNSIGNED_BYTE, data);
}
// 由于之前的OpenGLTexture2D是通过读取图片路径创建的, 这里的WhiteTexture需要一种额外的创建方法
// 与之前创建Texture, 调用Create函数相同, 仍然需要在Texture2D里加上这个函数:
class Texture2D : public Texture
{
public:
static std::shared_ptr<Texture2D> Create(const std::string& path);
static std::shared_ptr<Texture2D> Create(uint32_t width, uint32_t height);
};
// OpenGLTexture2D里实现具体的函数
OpenGLTexture2D::OpenGLTexture2D(uint32_t width, uint32_t height)
: m_Width(width), m_Height(height)
{
glCreateTextures(GL_TEXTURE_2D, 1, &m_TextureID);
// 注意格式是GL_RGBA8不是GL_RGBA, RGBA8是InternalFormat
glTextureStorage2D(m_TextureID, 1, GL_RGBA8, m_Width, m_Height);
glTextureParameteri(m_TextureID, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTextureParameteri(m_TextureID, GL_TEXTURE_MAG_FILTER, GL_NEAREST);
glTextureParameteri(m_TextureID, GL_TEXTURE_WRAP_S, GL_REPEAT);
glTextureParameteri(m_TextureID, GL_TEXTURE_WRAP_T, GL_REPEAT);
}
有了这些代码,接下来就简单了,无非是这几步:
- 调用Texture2D::Create函数,创建一个1*1大的贴图
- 调用SetData函数,把贴图里的数据,即RGBA对应的四个字节,改为白色(0xffffffff)
- DrawQuad传入color时,upload对应的u_Color,upload WhteTexture
- DrawQuad传入texture时,upload u_Color为(1,1,1,1),upload 对应的Texture
结果如下图所示:

有意思的是,如果把Shader里的TexCoord乘以10,那么采样的区域会变大,而且我设置的Texture的采样模式为Repeat,此时会变成:

Intro to Profiling
Profiling的内容不多,主要是两点:
- 创建Timer类,相当于计时器,它会记录一段代码执行所用的时间
- 把Timer显示的数据用Dear IMGUI显示出来
另外说一点,其实很多IDE,比如Visual Studio本身,就提供了Profiling工具(不过我还不知道咋用),它可以看一段代码的执行时间,但作为游戏引擎而言,它肯定是需要自己的Profiling工具的,毕竟IDE都不是跨平台的,而且就算有跨平台的IDE,也不方便在Runtime进行Profiling,因为这样的开销肯定是比游戏引擎自带的Profiling工具的开销大的。
这节课开始之前,可以回顾一下怎么用C++写计时功能
C++的计时功能
Cherno其实在C++教程里提到过怎么写Timer类,我做过记录。对于C++程序的性能优劣,程序所用时长是一个很重要的指标,C++11加入了计时功能,需要用头文件#include<chrono>
举个例子,测试计算机执行一段代码用了多长时间,代码如下:
#include <iostream>
#include <chrono>
int main()
{
// 开始计时, 这个auto对应的类型还挺复杂的, 叫
// std::chrono::time_point<std::chrono::steady_clock>
auto start = std::chrono::high_resolution_clock::now();
for (size_t i = 0; i < 100; i++)
std::cout << "1" << std::endl;
// 结束记时
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<float>duration = end - start;
std::cout << duration.count() << "s" << std::endl;
}
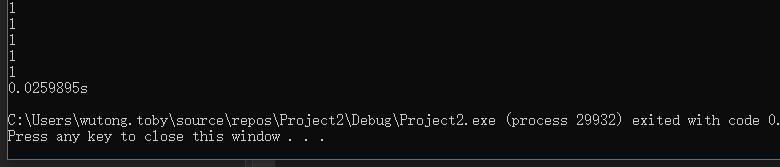
可以看到,计算机执行这一段一共用时约0.02s
有了这个基础,就可以设计一个Timer类了:
设计Timer类
设计定时器的思想跟RAII是一样的,在对象的构造函数里调用开始计时,在对象的析构函数里结束计时。一般来说,结束计时的时候,肯定需要调用某段代码,这段代码需要调用者自定义化。这里我觉得可以设计一个函数指针,比如说类型为void(const char* name, float time),用于在ImGUI里展示Timer的结果,作为callback,在Timer对象的析构函数里调用。
参考了一下Cherno的做法,它把这个callback做成了模板类,我改进了一下他的代码,现在Timer类支持签名为void(const char*, float)的callable object,而不仅仅是只支持对应签名的函数指针。代码如下,唯一复杂的就是这个模板的用法:
namespace Hazel
{
template<typename Fn>
class Timer
{
public:
// Timer的构造函数里接受一个Fn的右值, Fn代表一个callable object
// 在Timer的析构函数里会去调用它
Timer(const char* name, Fn&& func)
: m_Name(name), m_Func(func), m_Stopped(false)
{
// 构造函数里开始计时
m_StartTimepoint = std::chrono::high_resolution_clock::now();
}
~Timer()
{
if (!m_Stopped)
Stop();
}
void Stop()
{
// 结束计时
auto endTimepoint = std::chrono::high_resolution_clock::now();
// 换算成秒
long long start = std::chrono::time_point_cast<std::chrono::microseconds>(m_StartTimepoint).time_since_epoch().count();
long long end = std::chrono::time_point_cast<std::chrono::microseconds>(endTimepoint).time_since_epoch().count();
float duration = (end - start) * 0.001f;
m_Stopped = true;
// 调用m_Func
m_Func(m_Name, duration);
}
private:
const char* m_Name;
Fn m_Func;
std::chrono::time_point<std::chrono::steady_clock> m_StartTimepoint;
bool m_Stopped;
};
}
使用IMGUI把Profiling的结果显示出来
这个操作的核心代码是调用ImGUI的函数:
char label[50];
strcpy(label, "%.3fms "); // 保留三位小数
strcat(label, result.Name);
// 感觉写法很简单
ImGui::Text(label, result.Time);// 打印Profile条目的名字和time
下面这些是配套的改动:
// 在2D TestLayer里添加一个数组, 每个数组元素代表每个Timer的结果
struct ProfileResult
{
const char* Name;
float Time;
};
std::vector<ProfileResult> m_ProfileResults;
// 在2D TestLayer里
void Renderer2DTestLayer::OnImGuiRender()
{
ImGui::Begin("Test");
ImGui::ColorEdit4("Flat Color Picker", glm::value_ptr(m_FlatColor));
for (size_t i = 0; i < m_ProfileResults.size(); i++)
{
auto& result = m_ProfileResults[i];
char label[50];
strcpy_s(label, result.Name);
strcat_s(label, ": %.3fms "); // 保留三位小数
ImGui::Text(label, result.Time);// 打印Profile条目的名字和time
}
m_ProfileResults.clear();
ImGui::End();
}
得到的结果如下图所示,这个数字是实时更新的:
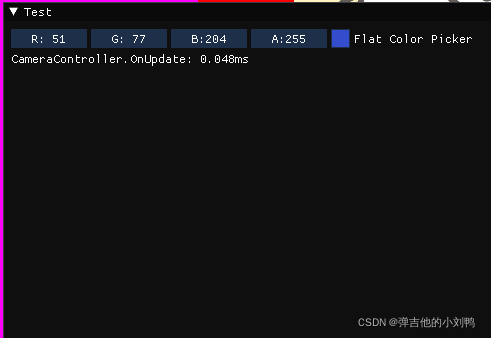
Visual Profiling
目前的Profiling用ImGUI绘制出来了,如上图所示,这种很简陋,缺点有:
- 只能看实时数据,无法看之前帧的数据
- 没有Hierarchy信息,比如像Unity那种Profiler,可以看具体函数的Hierarchy的Profile信息
- 没有搜索功能等
学习这节课之前,需要保证看过C++里VISUAL BENCHMARKING in C++ (how to measure performance visually)
VISUAL BENCHMARKING in C++
为了方便预览和分析程序里想要分析的代码片段每帧所花的时间,这里选了一个很简单的方法,就是在Runtime把Profile信息写到一个JSON文件里,然后利用Chrome提供的Chrome Tracing工具(只要在谷歌浏览器里输入chrome://tracing即可打开它),来帮忙分析这个JSON文件。
实现写入JSON文件的类叫instrumentor,这个单词在英语里其实并不存在,它源自于单词instrumentation,本意是一套仪器、仪表,在CS里的意思是对程序性能、错误等方面的监测:
In the context of computer programming, instrumentation refers to the measure of a product’s performance, to diagnose errors, and to write trace information.[1] Instrumentation can be of two types: source instrumentation and binary instrumentation.
所以instrumentor可以翻译为程序性能检测者,代码如下:
struct ProfileResult
{
const char* Name;
size_t ThreadId;
long long Start;
long long End;
};
// Instrumentor是个单例, 但是应该不是线程安全的单例
class Instrumentor
{
public:
static Instrumentor& Get()
{
static Instrumentor instance;// 这一行只会执行一次
return instance;
}
Instrumentor()
: m_CurrentSessionName(""), m_ProfileCount(0)
{
}
// 创建一个Stream, 写入对应的Header文件
void BeginSession(const std::string& name, const std::string& filepath = "results.json")
{
m_OutputStream.open(filepath);
WriteHeader();
m_CurrentSessionName = name;
}
// Stream里写入Footer文件, 结束Stream
void EndSession()
{
WriteFooter();
m_OutputStream.close();
m_ProfileCount = 0;
}
// 需要在Timer的析构函数里, 也就是结束计时的时候, 调用函数, 把结果写入stream里
void WriteProfile(const ProfileResult& result)
{
if (m_ProfileCount++ > 0)
m_OutputStream << ",";
std::string name = result.Name;
std::replace(name.begin(), name.end(), '"', '\'');
// 这样写也是为了符合Chrome Tracing的文件读取格式
m_OutputStream << "{";
m_OutputStream << "\"cat\":\"function\",";
m_OutputStream << "\"dur\":" << (result.End - result.Start) << ',';
m_OutputStream << "\"name\":\"" << name << "\",";
m_OutputStream << "\"ph\":\"X\",";
m_OutputStream << "\"pid\":0,";
m_OutputStream << "\"tid\":" << result.ThreadId << ",";
m_OutputStream << "\"ts\":" << result.Start;
m_OutputStream << "}";
m_OutputStream.flush();
}
// 整个JSON文件的Header
void WriteHeader()
{
m_OutputStream << "{\"otherData\": {},\"traceEvents\":[";
m_OutputStream.flush();
}
// 整个JSON文件的Footer
void WriteFooter()
{
m_OutputStream << "]}";
m_OutputStream.flush();
}
private:
std::string m_CurrentSessionName;
std::ofstream m_OutputStream;
int m_ProfileCount;
};
// 原本的Timer类
template<typename Fn>
class Timer
{
public:
// Timer的构造函数里接受一个Fn的右值, Fn代表一个callable object, 其参数为void(ProfileResult)
// 在Timer的析构函数里会去调用它
Timer(const char* name, Fn&& func)
: m_Name(name), m_Func(func), m_Stopped(false)
{
// 构造函数里开始计时
m_StartTimepoint = std::chrono::high_resolution_clock::now();
}
~Timer()
{
if (!m_Stopped)
Stop();
}
void Stop()
{
// 结束计时
auto endTimepoint = std::chrono::high_resolution_clock::now();
ProfileResult result;
// 换算成秒
result.Start = std::chrono::time_point_cast<std::chrono::microseconds>(m_StartTimepoint).time_since_epoch().count();
result.End = std::chrono::time_point_cast<std::chrono::microseconds>(endTimepoint).time_since_epoch().count();
// get_id返回的是一个ID对象, 需要取Hash值作为thread id
result.ThreadId = std::hash<std::thread::id>{}(std::this_thread::get_id());
result.Name = m_Name;
m_Stopped = true;
// 调用m_Func
m_Func(result);
}
private:
const char* m_Name;
Fn m_Func;
std::chrono::time_point<std::chrono::steady_clock> m_StartTimepoint;
bool m_Stopped;
};
Cherno在这里面写了很多宏,但我觉得太多宏影响阅读,所以我没有加这些东西,所以我这边具体使用的时候代码是这样:
// Application.cpp的Run函数里的某个片段
{
Hazel::Timer s("Window Update", [&](ProfileResult result)
{
Hazel::Instrumentor::Get().WriteProfile(result);
});
// 4. 每帧结束调用glSwapBuffer函数, 把画面显示到屏幕上
m_Window->OnUpdate();
}
// 再在运行这段Profiling函数的前后调用BeginSession和EndSession函数,确保创建Stream和关闭Stream
int main()
{
...
Hazel::Instrumentor::Get().BeginSession("Run Application", "RunApplication.json");
app->Run();
Hazel::Instrumentor::Get().EndSession();
...
}
这样写,在运行程序结束后,会把相关信息存到JSON文件里,而每个Timer的析构函数里,都会调用Instrumentor的WriteProfile函数,把相关信息写入到JSON对应的Stream里。
一键开关Profiling系统
游戏的Debug模式下,是允许Profiling的,但是Release模式肯定就要关闭Profiling了,目前我虽然写了这么一个宏:(未来会有一个引擎专门的配置文件来决定这些宏):
#define HAZEL_PROFILING
#ifdef HAZEL_PROFILING
#include "Hazel/Debug/Timer.h"
#include "Hazel/Debug/Instrumentor.h"
#endif
但比如我下面这个代码,难道每写一次,都要加一个#ifdef HAZEL_PROFILING么?
Hazel::Instrumentor::Get().BeginSession("Run Application", "RunApplication.json");
app->Run();
Hazel::Instrumentor::Get().EndSession();
虽然我很不希望用宏把代码变得非常难读,但想了想,感觉确实没什么更好的办法。
大概是改成这样:
#ifdef HAZEL_PROFILING
#define HAZEL_PROFILE_BEGIN_SESSION(name, filename) Hazel::Instrumentor::Get().BeginSession(name, filename);
#define HAZEL_PROFILE_END_SESSION() Hazel::Instrumentor::Get().EndSession();
#define HAZEL_PROFILE_TIMER(name) Hazel::Timer timer##__LINE__(name, [&](ProfileResult result){Hazel::Instrumentor::Get().WriteProfile(result);});
#else
#define HAZEL_PROFILE_BEGIN_SESSION(name, filename)
#define HAZEL_PROFILE_END_SESSION()
#define HAZEL_PROFILE_TIMER(name)
#endif
}
PS: 这里的HAZEL_PROFILE_TIMER跟Cherno实现的不一样,他写了两个版本的创建Timer的宏:
#define HZ_PROFILE_SCOPE(name) ::Hazel::InstrumentationTimer timer##__LINE__(name);
// 其中用的是`__FUNCSIG__`直接把函数的签名作为ProfileResult的名字
#define HZ_PROFILE_FUNCTION() HZ_PROFILE_SCOPE(__FUNCSIG__)
我目前只给了一个HAZEL_PROFILE_TIMER(name)
Instrumentation
现在的Profiling系统,有个比较大的问题:
- 它会不断的Profiling,然后写入到JSON文件里,每一帧都跑这个数据,这是不科学的,得到的文件可能会到几百兆,像Unity的Profiling系统,就提供了录制功能,而且它只会录制特定帧数的Profiling数据,就是那个不停滚动的Profiling窗口…
但其实,这个录制功能对应的API,我已经写好了,就是前面的HAZEL_PROFILINE_BEGIN_SESSION和HAZEL_PROFILINE_END_SESSION,需要的内容,其实是UI,需要有开始Profiling和结束Profiling的Button,这个功能,以后再加上好了。
这节课的主要内容,感觉Cherno在搬砖:
- 在很多函数的开头(好像基本上是每个函数的开头),都加了
HAZEL_PROFILE_TIMER(name)的Timer,当函数跑完的时候,会出Profile结果到JSON文件里 - 然后打开JSON文件,分析整个游戏引擎的性能
感觉这个Chrome Tracing还不如Unity的Profiler看的清晰一点,可能是我还不熟悉吧,这一块比较简单,我就先不做了,等以后性能有问题了,引擎复杂了再来看吧,链接留着:https://www.youtube.com/watch?v=FtsehM4xoDw&t=272s&ab_channel=TheCherno
附录
GL_RGBA和GL_RGBA8
参考:https://stackoverflow.com/questions/34497195/difference-between-format-and-internalformat#comment56736641_34497470
参考:https://stackoverflow.com/questions/26810489/what-data-type-for-internalformat-specified-as-gl-rgba
参考:https://docs.microsoft.com/en-us/windows/win32/opengl/glcolortableext
写OpenGL的时候遇到这么个错误,我一开始是这么写的:
glTextureStorage2D(m_TextureID, 1, GL_RGBA, m_Width, m_Height);
...
// 后面会去set texture's data
unsigned int data = 0xffffffff;
// 我想要创建一个白色的贴图
glTextureSubImage2D(m_TextureID, 0, 0, 0, m_Width, m_Height, GL_RGBA, GL_UNSIGNED_BYTE, &data);
结果这个创建出来的贴图有问题,是一个黑色的贴图,改成下面这样就对了:
glTextureStorage2D(m_TextureID, 1, GL_RGBA8, m_Width, m_Height);
查了下资料,大概意思是,GL_RGBA格式,是用GPU上的数据,表示RGBA四个分量,但是每个分量具体占几个字节,这个是不清楚的,如下图所示,都有可能:
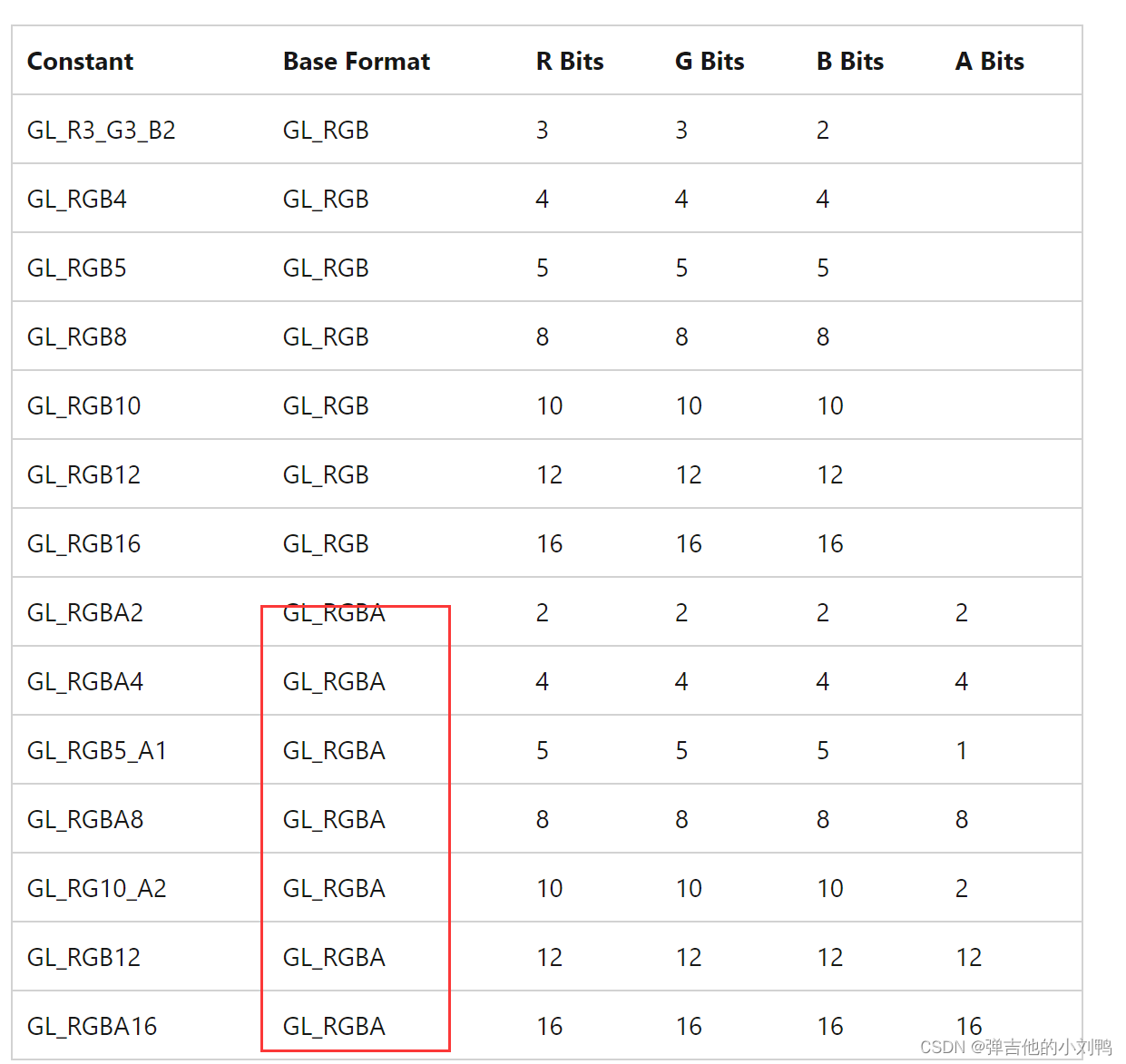
所以如果用GL_RGBA,那么在不知道其内部具体怎么分配的情况下,使用0xffffffff就很有可能出错
C++ lambda的写法
好久没写C++的lambda了,这里回忆一下:
#include <algorithm>
#include <cmath>
void abssort(float* x, unsigned n) {
std::sort(x, x + n,
// Lambda expression begins
[](float a, float b) {
return (std::abs(a) < std::abs(b));
} // end of lambda expression
);
}
lambda里的[&]
参考:https://stackoverflow.com/questions/39789125/what-does-mean-before-function#:~:text=It’s%20a%20lambda%20capture%20list,scope%20within%20the%20lambda%20function.
It means that the lambda function will capture all variables in the scope by reference.
比如Profiling里用到的代码:
{
Hazel::Timer t("CameraController.OnUpdate", [&](ProfileResult profileResult)
{ m_ProfileResults.push_back(profileResult); });
m_OrthoCameraController.OnUpdate(ts);
}
这里的[]叫capture list,里面的&意味着函数体内的东西,也就是花括号里的内容,除了传入函数的参数,其他都是取的引用,意思是这里会把m_ProfileResults作为引用传给函数,这里的capture,指的是除了函数参数以外的变量,省的我要写一个很麻烦的函数签名。上面这个lambda表达式,其代表的函数签名是void(ProfileResult result)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号