
C++ thread学习(一)
参考视频:https://www.youtube.com/watch?v=wXBcwHwIt_I
一.简单的多线程例子
在单一线程的程序里,如果使用cin.get()函数,程序会一直停留在这一行,等待用户输入,当你按下回车时,程序才会继续执行。(关于cin.get()函数,可以参考http://c.biancheng.net/view/1346.html)
那么问题来了,如果要实现如下功能该怎么做:我们屏幕上一直在打印消息,当用户输入回车时,程序终止。使用单线程能做到吗?
具体的单线程的例子我不确定有没有,但是我们可以使用多线程来完成上述功能。
c++ 11之后有了标准的线程库std::thread,代码如下,主线程暂停在了std::cin.get()函数这里,等待用户的输入,同时,另外一个线程一直在打印Working消息。
#include <iostream>
#include <thread>
static bool hasFinished;
void doWork()
{
while (!hasFinished)
{
std::cout << "Working..." << std::endl;
}
}
int main()
{
hasFinished= false;
std::thread work(doWork);
std::cin.get();
hasFinished = true;
std::cout << "Finished" << std::endl;
//相当于C#中的wait函数,主线程会一直等待work线程,直到work线程退出函数,才会继续往下执行
work.join();
}
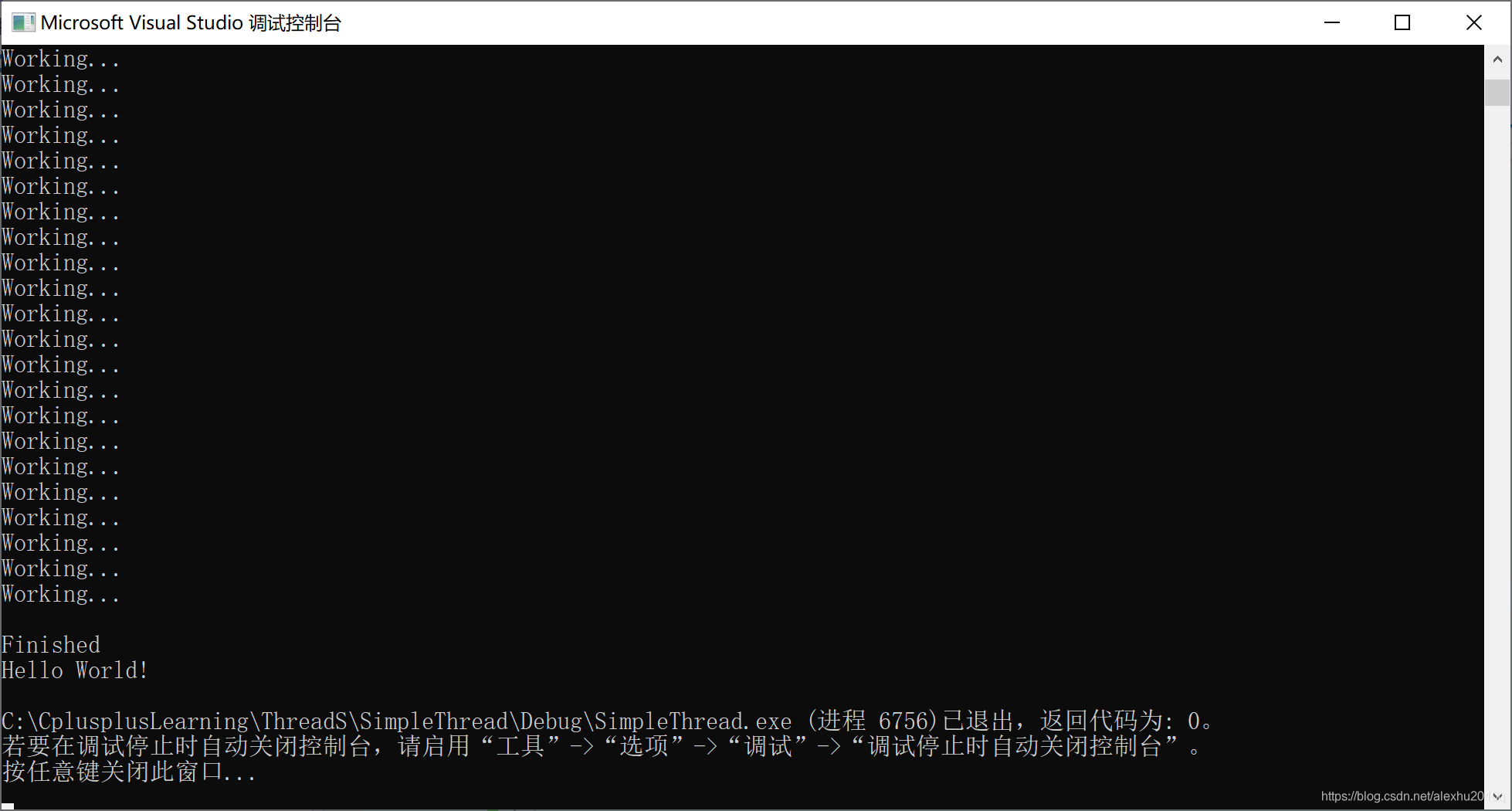
有趣的是,同样的Enter操作,可能出现两种结果:
第一种结果:
第二种结果:
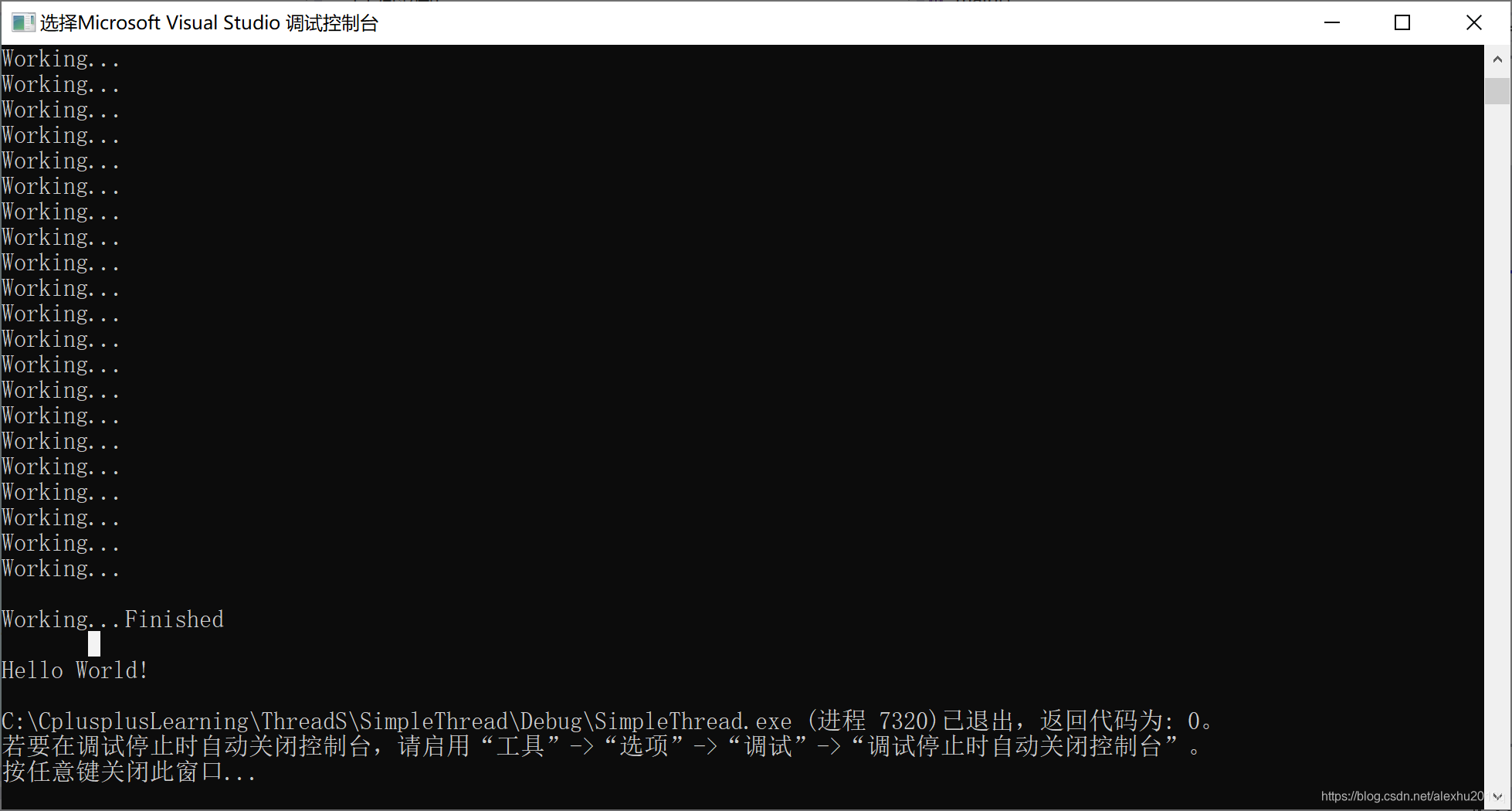
可以看出,语句std::cout << "Working..." << std::endl;并不是原子操作,所以第二种情况是,在输出workind…之后,准备输出std::endl时,由于两个线程是同时进行的,所以Finished消息没等其换完行,就打印出来了,所以在Finished打印完后,还会多一行空白行。
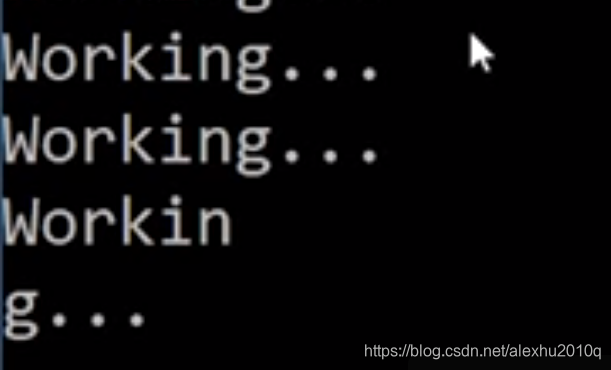
甚至可能会这样(下图所示的代码,没有打印Finished语句):
为了减少CPU的使用率,可以改为1s打印一次消息:
void doWork()
{
using namespace::std::literals::chrono_literals;
std::cout << "Work Thread Id" << std::this_thread::get_id() << std::endl;//输出线程Id
while (!finished)
{
std::cout << "Working..." << std::endl;
std::this_thread::sleep_for(1s);
//std::this_thread::sleep_for(chrono::seconds(1));//这样写也可以
}
}
二. C++创建Thread的五种方法
- Function Pointer
void doWork1(int a)
{
std::cout << "Working..." << a << std::endl;
}
void doWork2(int &a)
{
std::cout << "Working..." << a << std::endl;
}
int main()
{
...
int a= 0;
std::thread work(doWork1, a);//Function Pointers: pass value
std::thread work(doWork2, std::ref(a));//Function Pointers: pass refference
...
}
- Lambda Functions
int main()
{
int a1 = 10;
std::thread work([](int a){std::cout << "Working..." << a << std::endl;}, a1);
work.join();
return 0;
}
- Functors
class C
{
public:
void operator ()(int x)
{
std::cout << "Working..." << x << std::endl;
}
};
int main()
{
std::thread work((C()), 4);
work.join();
return 0;
}
- Member Functions
对于类的非静态成员函数,其写法与Function Pointer类似,取函数的地址,不过要额外添加一个对象的地址,因为是调用的该对象的成员函数。
class B
{
public:
void func(int x) { std::cout <<"Working..." << x << std::endl; }
};
int main()
{
B b;
std::thread work(&B::func, &b, 6);//成员函数的地址,和对象的地址
work.join();
return 0;
}
- Static Member Functions
与no-static member functions 类似,只不过不再需要特定对象的地址
class B
{
public:
static void func(int x) { std::cout <<"Working..." << x << std::endl; }
};
int main()
{
std::thread work(&B::func, 6);
work.join();
return 0;
}
三.先在main函数中创建的Thread并不保证会先启动
如下述代码,并不能一定保证先打印5:
void func(int x)
{
cout << x <<endl;
}
int main()
{
thread t1(func, 5);
thread t2(func, 6);
t1.join();
t2.join();
return 0;
}
四.Join Joinable and Detach
Join
相当于waitForExit();
thread1.join(),意味着当主线程走到这,会停下来,一直等到线程thread1完成后,才会继续往下走。
Detach
与Join函数类似,不过Join函数会让父线程停下来等待子线程完成,但是Detach函数不会等待,如果父线程结束,子线程会被Suspended
如图所示的例子,main thread会照常执行,在执行return 0之后,func就不再继续打印了。
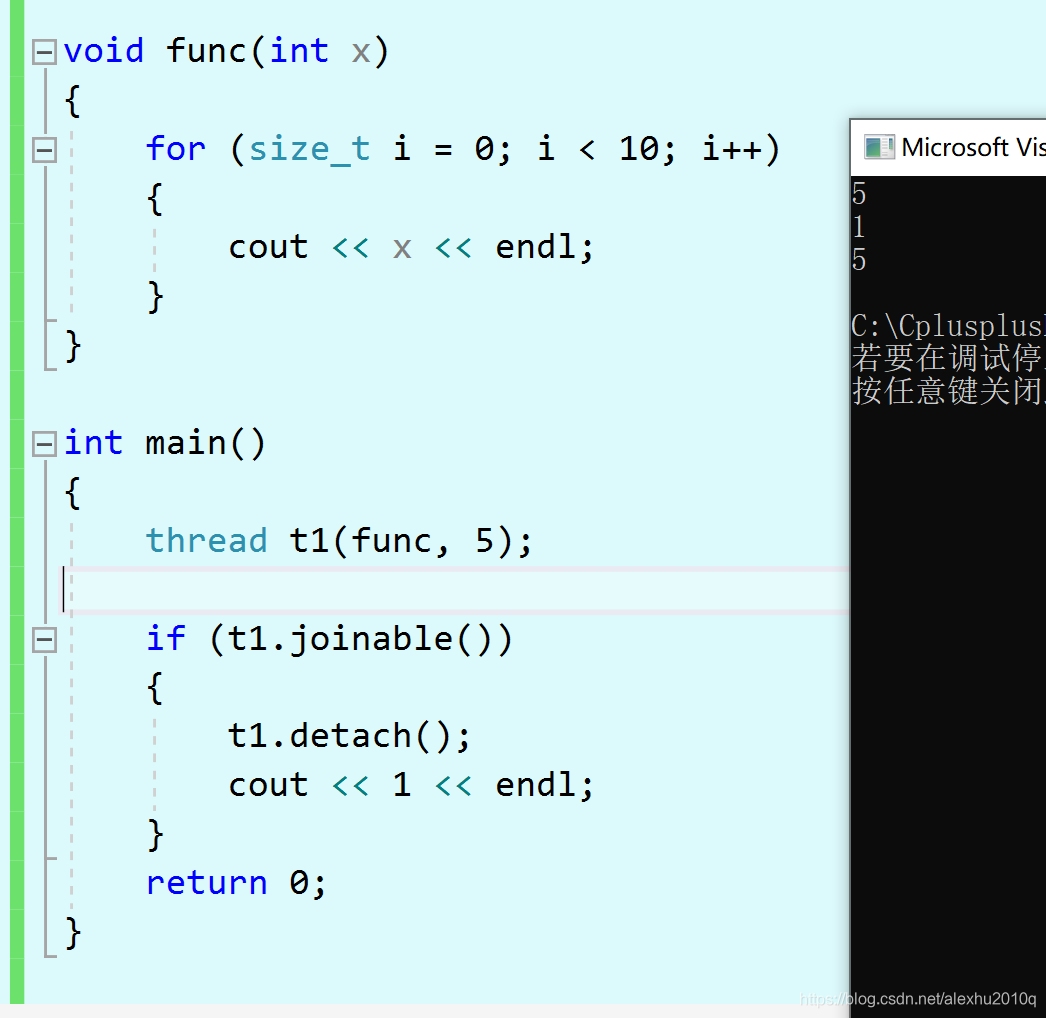
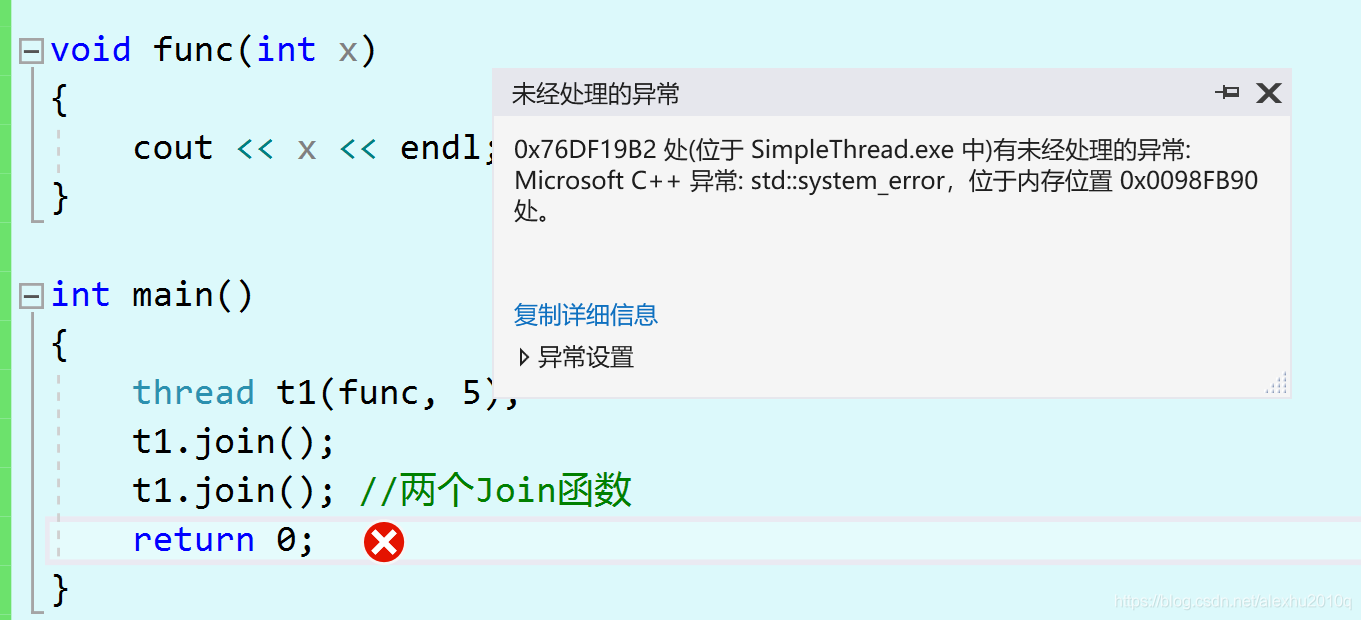
Joinable
对于开启的线程,需要用Join(同Detach)函数等待其退出,但是如果连写两个Join函数,编译器并不会报错,而是会在运行时报错。
void func(int x)
{
cout << x <<endl;
}
int main()
{
thread t1(func, 5);
t1.join();
t1.join(); //两个Join函数
return 0;
}
运行后会报错
但是实际操作写代码时,可能会出现这样的情况,程序员已经写了一个t1.join了,但是程序员又接着写了很多其他代码,然后忘记了之前已经有一个join了,就又写了一个join函数。(同Detach函数)
t1.join();
...
t1.jion();
为了防止这样的情况出现,C++提供了joinable参数,来判断这个线程是不是可以join或Detach,写法如下:
if(t1.joinable())
t1.join();
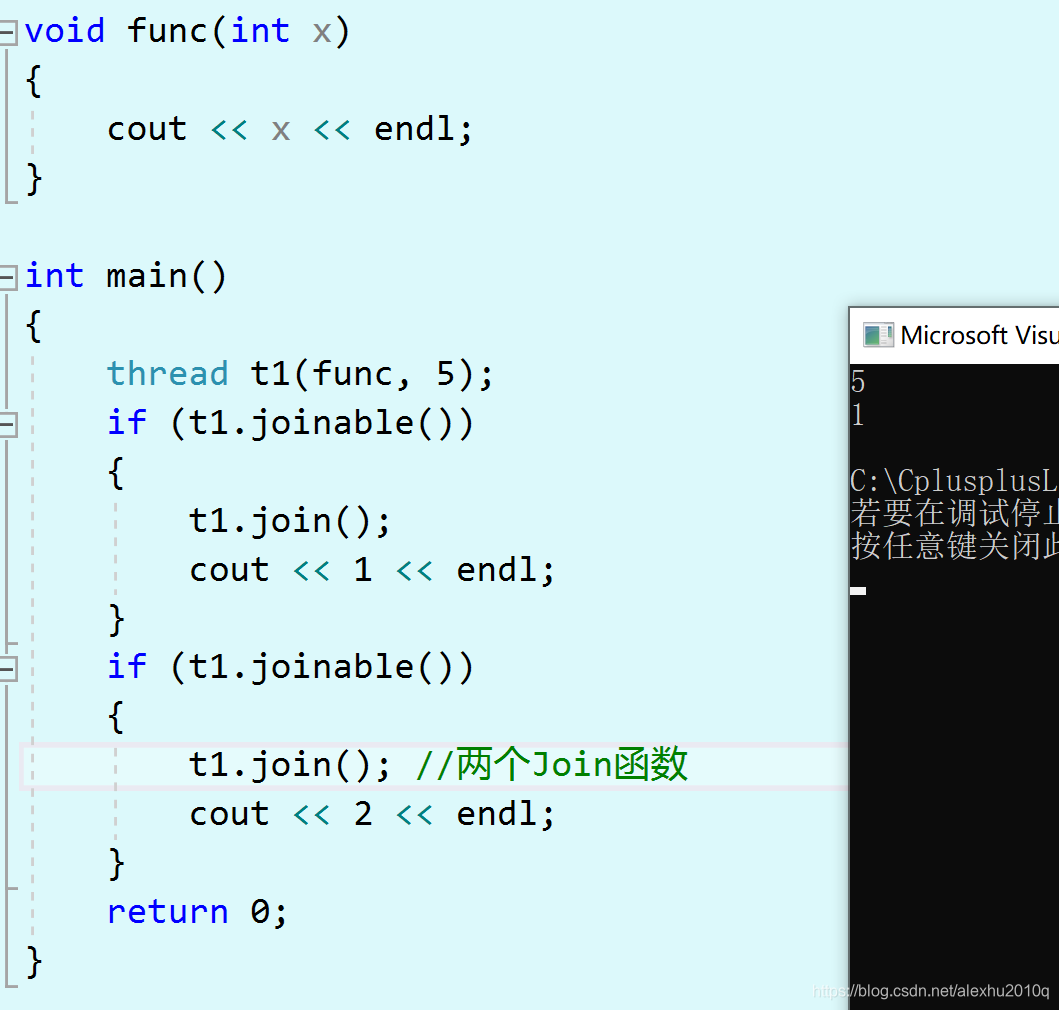
提示
创建thread后,后面必须写thread.join()或者thread.detach(),否则程序会提前终止。
五. 各种Mutex Lock
Mutex Lock
mutex:Mutual Exclusion,互斥锁
需要引用头文件#include <mutex>
举一个简单的例子:
#include<iostream>
#include <thread>
#include <mutex>
using namespace std;
int x = 0;
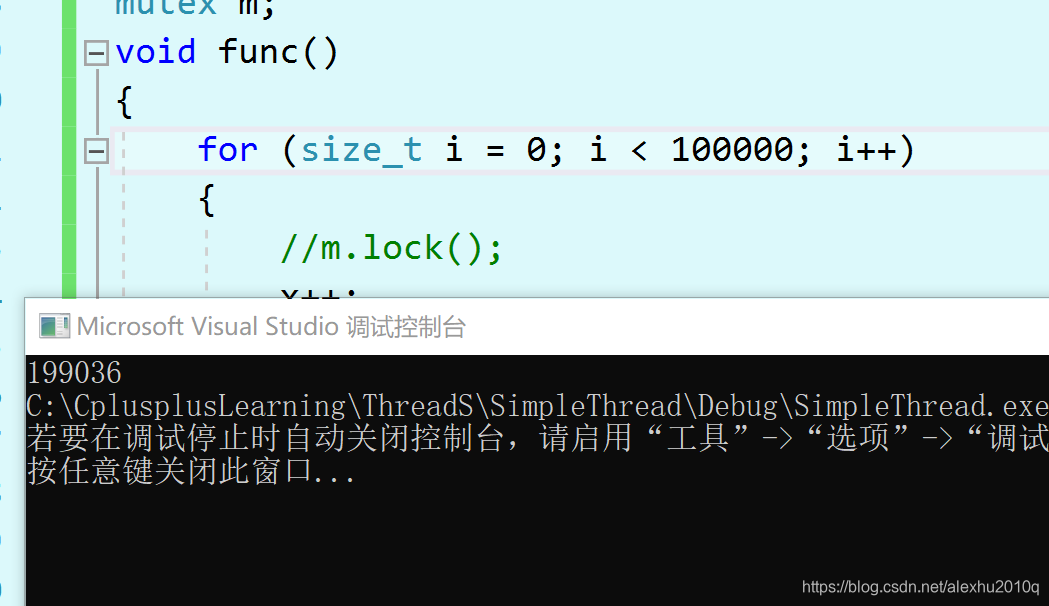
mutex m;//最普通的Lock
void func()
{
for (size_t i = 0; i < 100000; i++)
{
//m.lock();
x++;
//m.unlock();
}
}
int main()
{
thread t1(func);
thread t2(func);
t1.join();
t2.join();
cout << x;
return 0;
}
由于x++不是原子操作,分为三步,取x值,x值++,存x值,如果不添加互斥锁,多次运行后,可能会出现不正确的结果,如下图所示:
而利用m.lock()和m.unlock()函数,加上互斥锁后,每次运行的结果都是200000
lock()与try_lock()
mutex m;
m.lock();
m.try_lock();
当运行m.lock();时,程序会一直停留在这里,直到获取到lock再继续进行,所以可能会产生死锁
当运行m.try_lock();时,程序不会停在这里,而是尝试获取lock,若成功则返回true,否则返回false。
下面举一个具体的例子,下述代码会稳定输出200000:
void func()
{
for (size_t i = 0; i < 100000; i++)
{
m.lock();
x++;
m.unlock();
}
}
int main()
{
thread t1(func);
thread t2(func);
t1.join();
t2.join();
cout << x;
return 0;
}
如果把func函数用try_lock的方式进行:
void func()
{
for (size_t i = 0; i < 100000; i++)
{
if(m.try_lock())
{
x++;
m.unlock();
}
}
}
输出的结果比100000还小,这是因为两个线程总有一个在不断进行try_lock,重复在走循环,而并没有对x进行操作,而且try_lock的检查操作比正常进行x++操作更快,所以最后会导致结果反而比100000还小:
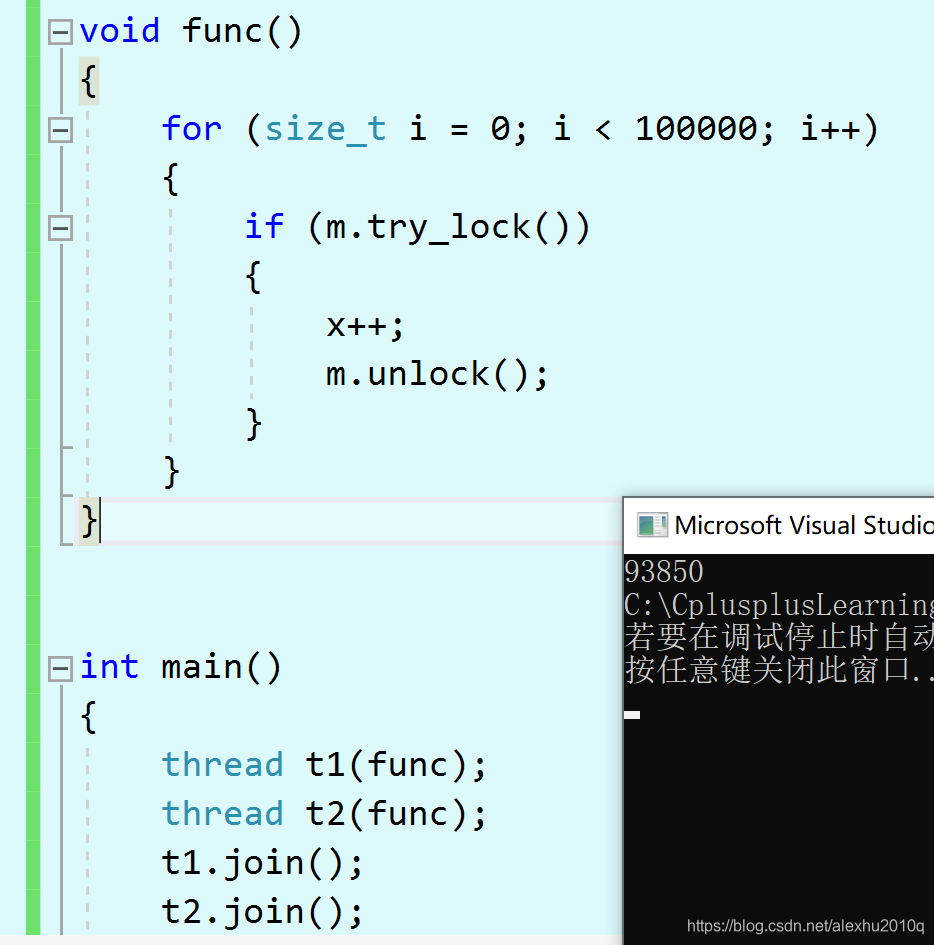
mutex.try_lock与std::try_lock()
与单个mutex对象的成员函数.try_lock()不同,std::try_lock提供了多个mutex一起try_lock的功能,若成功返回-1,否则返回0-based mutex index number,并释放之前所有已获取的锁。

举一个使用std::try_lock函数的例子,该例子有三个子线程,线程t1负责++x,线程t2负责++y,线程t3负责重置x和y,并统计总清零的个数。
#include<iostream>
#include<thread>
#include<mutex>
using namespace std;
mutex m1, m2;
void doSomeOtherWork(int t)
{
this_thread::sleep_for(chrono::seconds(t));
}
void increaseXOrYBucket(int &xOrY, mutex &m, char c)
{
for (size_t i = 0; i < 5; i++)
{
m.lock();
xOrY = 1;
cout << c << "=" << xOrY<< endl;
m.unlock();
doSomeOtherWork(1);//等一秒,让consume函数进行清空
}
}
void consumeTwoBuckets(int &consumeSum, int &x, int &y)
{
for (size_t i = 0; i < 5;)
{
if (try_lock(m1, m2) == -1)
{
if (x && y)
{
consumeSum += x + y;
x = 0;
y = 0;
cout << "consume" << consumeSum << endl;
i++;
}
m1.unlock();
m2.unlock();
}
}
}
int main()
{
int x, y;
int sum = 0;
thread t1(increaseXOrYBucket, ref(x), ref(m1), 'X');
thread t2(increaseXOrYBucket, ref(y), ref(m2), 'Y');
thread t3(consumeTwoBuckets, ref(sum), ref(x), ref(y));
t1.join();
t2.join();
t3.join();
return 0;
}
以下是输出结果,由于m1和m2的打印是多线程的,所以看起来有点杂乱,但是总体结果是没错的。
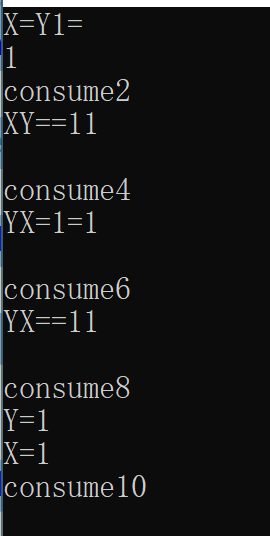
timed_mutex
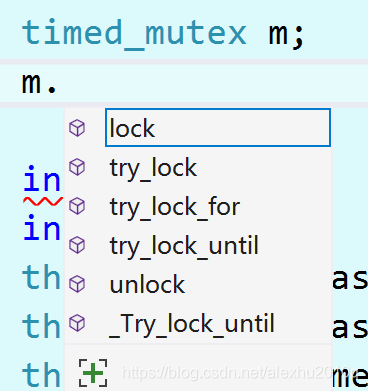
通过timed_miutex mtx可以创建带有时间功能的锁,如下图所示,可以看到多了两个函数:try_lock_for和try_lock_until
try_lock_for
try_lock_for会持续一段时间停在这里(被block),这段时间内如果获取到了锁,就返回true,如果超过这段时间还没获取到,就返回false.
写法如下:
timed_mutex mtx;
if(mtx.try_lock_for(chrono::seconds(1)))//等待一秒,若提前得到锁则为true,超时则为false,继续往下走
{
...
}
try_lock_until
与try_lock_for类似,不过函数里输入的不再是持续时间,而是当前时间,用法如下:
timed_mutex mtx;
auto now = std::chrono::steady_clock::now();
if(mtx.try_lock_for(now + chrono::seconds(1)))//等待一秒,若提前得到锁则为true,超时则为false,继续往下走
{
...
}
recursive_mutex
timed_mutex是带有计时功能的mutex,recursive_mutex就是带有计数功能的mutex.对于递归函数,在第一次进入函数的时候需要取得锁,如果是普通的锁,则后续递归过程不可以再取得该锁,这个时候就可以用到recursive_mutex
- 写法:
recursive_mutex mtx; - 可用于递归函数
- recursive_mutex加锁了多少次,就必须解锁多少次,否则不可以再被其他线程使用
- 最大递归次数具体不知道是多少,超出的时候用lock函数会报SystemError,用try_lock会返回false
lock_guard
通过lock_guard来创建mutex,可以避免手动释放锁,当离开创建lock_guard的局部范围时,会自动释放锁。
写法如下,m1为一个mutex:
std::lock_guard<mutex> lock(m1),
mutex m;
void func1()
{
for (size_t i = 0; i < 100000; i++)
{
m.lock();
x++;
m.unlock();
}
}
void func2()
{
for (size_t i = 0; i < 100000; i++)
{
std::lock_guard<mutex>lock(m);
x++;
}//走到这里会自动释放锁
}
unique_lock
unique_lock是一个wrapper,可以获取,可以为普通的mutex lock添加特殊功能,当wrapper作为局部变量被Destruct时,会释放锁
mutex s;
unique_lock<mutex>lock(s);
lock.try_lock_for(chrono::seconds(1));//可以使用timed_lock的功能
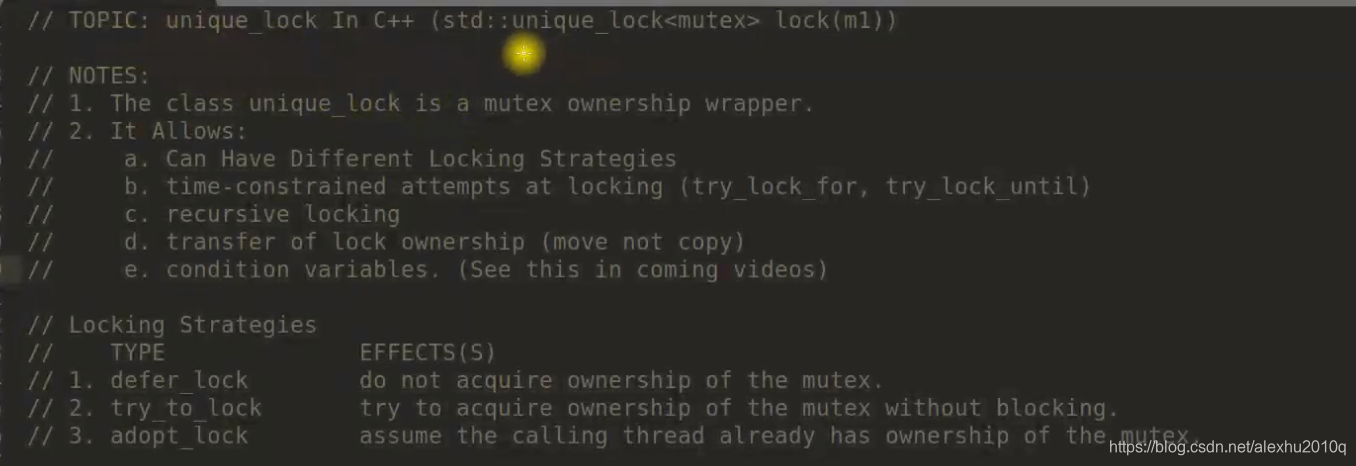
函数有多种Strategy,作为第二个参数进行输入:
mutex mtx;
unique_lock<mutex>lock(mtx);//automatically calls lock on mtx
//不会立马lock,而是会推迟(defer)
unique_lock<mutex>lock(mtx,defer_lock);//do not acquire ownership of the mutex
unique_lock<mutex>lock(mtx,try_lock); //try to acquire ownership of the mutex without blocking
//假定mtx已经上锁了
unique_lock<mutex>lock(mtx,adopt_lock);//assume the calling thread already has ownership of the mutex
举两个具体的例子:
mutex m;
void Func1(){
unique_lock<mutex>lock(m);//会马上上锁
...
}
void Func2(){
unique_lock<mutex>lock(m, defer_lock);//不会上锁,其他地方还可以获取锁
... //还可以继续加代码
m.lock();
...
}
六. Critical Section
Critical Section是英文的名词,指的是多个线程共享的包含了写操作的代码区间。
比如
int a = 5;
void Func()
{
cout<< a <<endl; //not critical section
a++; //critical section
}
void main()
{
thread t1(Func);
thread t2(Func);
return;
}
七. 如何防止死锁
目前学到了两种方法
- 不同的线程用到同样的锁时,要按同样的顺序来获取锁
- 运用std::lock()
std::lock可以获取多个Mutex变量,对于AB两个线程,有资源1和资源2,A先获取1,再获取2,B先获取2,再获取1,如果都用lock和unlock函数,可能会出现A占用1,B占用2的死锁情况,
但是用std::lock(),同时获取1和2,就能避免死锁情况的发生,因为std::lock如果获取了1,发现2获取不到,就会释放资源1,再重新进行std::lock(可能这次从资源2开始获取),写法如下:
std::lock(m1, m2, m3, m4); //注意获取锁的顺序并不一定是m1、m2、m3、m4
...
m1.unlock(); //别忘了用完要解锁
m2.unlock();
m3.unlock();
m4.unlock();
下图所示,两个线程不会产生死锁
// thread1 thread2
// std::lock(m1,m2); std::lock(m2, m1); //no dead lock
// thread1 thread2
// std::lock(m1 ,m2, m3, m4); std::lock(m3, m4); //no dead lock
// std::lock(m1, m2);
下图所示,两个线程会产生死锁, 把两个锁看作一个整体,与最初的情况是一样的
// thread1 thread2
// std::lock(m1,m2); std::lock(m3, m4); //dead lock
// std::lock(m3,m4); std::lock(m2, m1);
注意std::lock 是一个blocking call,如果没获取到所有的锁,会一直block在这里

 浙公网安备 33010602011771号
浙公网安备 33010602011771号