
对于已经成功的1000页,也要修改。为了以后代码执行的工作量小点!进行切割:
代码:【并不完善,需要手工修改一下!】
1 ''' 2 核心思想,就是通过不同的id号进行查找。不想要的,移除掉! 3 ''' 4 5 import json 6 def makes(): 7 i = 24999#截取后面的 8 # i = 49999# 截取前面的 9 cve_num0_file = open('D:/1hos/cvebase_ifo.json', "r") 10 cvesum = json.load(cve_num0_file) 11 # print(cvesum[i]['id']) 12 # while i > 25000:#截取前面的 13 while i > 0:#截取后面的 14 print(cvesum[i]['id']) 15 if int(cvesum[i]['id']) < 25000: 16 # cvesum[i].remove 17 del cvesum[i] 18 i -= 1#截取前面的 19 # i += 1#截取后面的 20 21 # with open('D:/1swqcve/cve_num1.json', "w+") as json_file: 22 # json_str = json.dumps(cve_num1_context, indent=4) 23 # json_file.write(json_str) 24 # json_file.close() 25 # print('\n************已经成功复制在cve_num1的内容************\n') 26 # print(cvesum) 27 with open('D:/1hos/cvebase_ifo4.json', "w") as json_file: 28 json_str = json.dumps(cvesum, indent=4) 29 json_file.write(json_str) 30 json_file.close() 31 # with open('D:/1swqcve/cve_num2.json', "w") as json_file: 32 # json_str = json.dumps(cvesum, indent=4) 33 # json_file.write(json_str) 34 # json_file.close() 35 # with open('D:/1swqcve/cve_num3.json', "w") as json_file: 36 # json_str = json.dumps(cvesum, indent=4) 37 # json_file.write(json_str) 38 # json_file.close() 39 # with open('D:/1swqcve/cve_num4.json', "w") as json_file: 40 # json_str = json.dumps(cvesum, indent=4) 41 # json_file.write(json_str) 42 # json_file.close() 43 # print("成功将cve编号写入4个json文件!\n") 44 if __name__=="__main__": 45 makes()
清理CVE编号:
找出分界线下标:
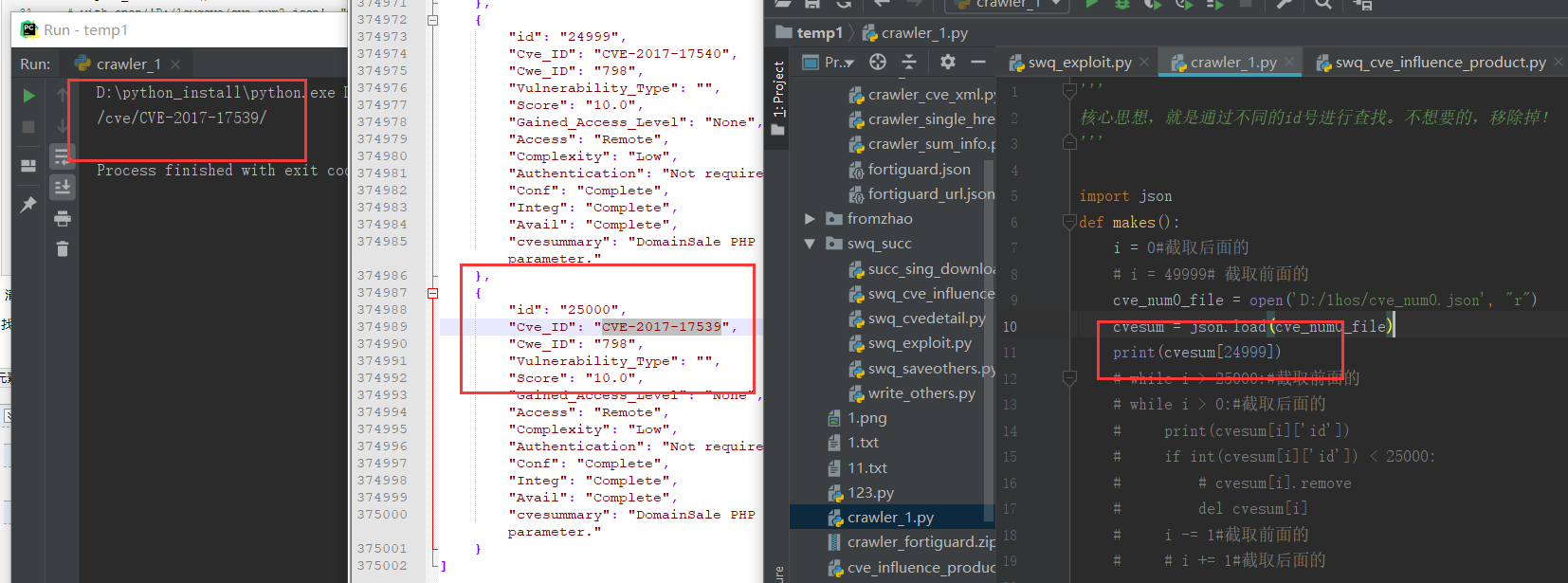
取出前500页【25000个】
成功代码:
1 ''' 2 核心思想,就是通过不同的id号进行查找。不想要的,移除掉! 3 ''' 4 5 import json 6 def makes(): 7 # i = 0#截取后面的 8 i = 49999# 截取前面的 9 cve_num0_file = open('D:/1hos/cve_num0.json', "r") 10 cvesum = json.load(cve_num0_file) 11 print(cvesum[24999]) 12 # while i > 25000:#截取前面的 13 while i > 24999:#截取后面的 14 print(i) 15 del cvesum[i] 16 i -= 1 17 # print(cvesum[i]['id']) 18 # if int(cvesum[i]['id']) < 25000: 19 # # cvesum[i].remove 20 21 # i -= 1#截取前面的 22 # # i += 1#截取后面的 23 24 # with open('D:/1swqcve/cve_num1.json', "w+") as json_file: 25 # json_str = json.dumps(cve_num1_context, indent=4) 26 # json_file.write(json_str) 27 # json_file.close() 28 # print('\n************已经成功复制在cve_num1的内容************\n') 29 # print(cvesum) 30 with open('D:/1hos/cve_num1.json', "w") as json_file: 31 json_str = json.dumps(cvesum, indent=4) 32 json_file.write(json_str) 33 json_file.close() 34 # with open('D:/1swqcve/cve_num2.json', "w") as json_file: 35 # json_str = json.dumps(cvesum, indent=4) 36 # json_file.write(json_str) 37 # json_file.close() 38 # with open('D:/1swqcve/cve_num3.json', "w") as json_file: 39 # json_str = json.dumps(cvesum, indent=4) 40 # json_file.write(json_str) 41 # json_file.close() 42 # with open('D:/1swqcve/cve_num4.json', "w") as json_file: 43 # json_str = json.dumps(cvesum, indent=4) 44 # json_file.write(json_str) 45 # json_file.close() 46 # print("成功将cve编号写入4个json文件!\n") 47 if __name__=="__main__": 48 makes()
截取后面的:【需要手动删除一个信息!】
代码:
1 ''' 2 核心思想,就是通过不同的id号进行查找。不想要的,移除掉! 3 ''' 4 5 import json 6 def makes(): 7 # i = 0#截取后面的 8 i = 24999# 截取前面的 9 cve_num0_file = open('D:/1hos/cve_num0.json', "r") 10 cvesum = json.load(cve_num0_file) 11 print(cvesum[24999]) 12 # while i > 25000:#截取前面的 13 while i > 0:#截取后面的 14 print(i) 15 del cvesum[i] 16 i -= 1 17 # print(cvesum[i]['id']) 18 # if int(cvesum[i]['id']) < 25000: 19 # # cvesum[i].remove 20 21 # i -= 1#截取前面的 22 # # i += 1#截取后面的 23 24 # with open('D:/1swqcve/cve_num1.json', "w+") as json_file: 25 # json_str = json.dumps(cve_num1_context, indent=4) 26 # json_file.write(json_str) 27 # json_file.close() 28 # print('\n************已经成功复制在cve_num1的内容************\n') 29 # print(cvesum) 30 with open('D:/1hos/cve_num8.json', "w") as json_file: 31 json_str = json.dumps(cvesum, indent=4) 32 json_file.write(json_str) 33 json_file.close() 34 # with open('D:/1swqcve/cve_num2.json', "w") as json_file: 35 # json_str = json.dumps(cvesum, indent=4) 36 # json_file.write(json_str) 37 # json_file.close() 38 # with open('D:/1swqcve/cve_num3.json', "w") as json_file: 39 # json_str = json.dumps(cvesum, indent=4) 40 # json_file.write(json_str) 41 # json_file.close() 42 # with open('D:/1swqcve/cve_num4.json', "w") as json_file: 43 # json_str = json.dumps(cvesum, indent=4) 44 # json_file.write(json_str) 45 # json_file.close() 46 # print("成功将cve编号写入4个json文件!\n") 47 if __name__=="__main__": 48 makes()
结果:
需要手动删除一个,其他一切都好!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号