Redis高可用及分片集群
一、主从复制
- 使用异步复制
- 一个服务器可以有多个从服务器
- 从服务器也可以有自己的从服务器
- 复制功能不会阻塞主服务器
- 可以通过服务功能来上主服务器免于持久化操作,由从服务器去执行持久化操作即可。

以下是关于Redis复制功能的几个重要方面:
- Redis使用异步复制。从Redis 2.8开始,从服务器会以每秒一次的频率向主服务器报告复制流(replication stream)的处理进度。
- 一个主服务器可以有多个从服务器。
- 不仅主服务器可以有从服务器,从服务器也可以有自己的从服务器,多个从服务器之间可以构成一个图状结构。
- 复制功能不会阻塞主服务器: 即使有一个或多个从服务器正在进行初次同步, 主服务器也可以继续处理命令请求。
- 复制功能也不会阻塞从服务器: 只要在 redis.conf 文件中进行了相应的设置, 即使从服务器正在进行初次同步, 服务器也可以使用旧版本的数据集来处理命令查询。
- 不过, 在从服务器删除旧版本数据集并载入新版本数据集的那段时间内, 连接请求会被阻塞。
- 你还可以配置从服务器, 让它在与主服务器之间的连接断开时, 向客户端发送一个错误。
- 复制功能可以单纯地用于数据冗余(data redundancy), 也可以通过让多个从服务器处理只读命令请求来提升扩展性(scalability): 比如说, 繁重的 SORT 命令可以交给附属节点去运行。
- 可以通过复制功能来让主服务器免于执行持久化操作: 只要关闭主服务器的持久化功能, 然后由从服务器去执行持久化操作即可。
Redis主从复制实践
环境:
/data/6380/redis-server /data/6380/redis.conf /data/6381/redis-server /data/6381/redis.conf /data/6382/redis-server /data/6382/redis.conf
配置文件示例:
配置文件示例: redis.conf bind 127.0.0.1 192.168.29.128 port 6380 daemonize yes pidfile /data/6380/redis.pid loglevel notice logfile "/data/6380/redis.log" dbfilename dump.rdb dir /data/6380 appendonly no appendfilename "appendonly.aof" appendfsync everysec slowlog-log-slower-than 10000 slowlog-max-len 128 protected-mode no
启动
/data/6380/redis-server /data/6380/redis.conf /data/6381/redis-server /data/6381/redis.conf /data/6382/redis-server /data/6382/redis.conf
主节点:6380 从节点:6381、6382 开启主从: 6381/6382命令行: redis-cli -p 6381 SLAVEOF 127.0.0.1 6380
运行原理
从服务器以每秒一次的频率PING主服务器一次,并报告复制流的处理情况。主服务器记录各个从服务器最后一次向它发送PING的时间。用户可以通过配置,指定网络延迟的最大值min-slaves-max-lag,以及执行操作所需的至少从服务器数量min-slaves-to-write。 如果至少有min-slaves-to-write个从服务器,并且这些服务器的延迟值都少于min-slaves-max-lag秒,那么主服务器就会执行客户端请求的写操作。你可以将这个特性看作CAP理论的C的条件放宽版本:尽管不能保证写操作的持久性,但起码丢失数量的窗口会被严格限制在指定的描述中。 另一方面,如果条件达不到min-slaves-to-write和min-slaves-max-lag所指定的条件,那么写操作就不会执行,主服务器会向请求执行写操作的客户端返回一个错误。
Redis主从复制管理
主从复制状态监控:
info replication
主从切换:
slaveof no one
二、Redis Sentinel
Redis-Sentinel是Redis官方推荐的高可用性(HA)接近方案,当用Redis做Master-slave的高可用方案时,假如master宕机了,Redis本身(包括它的很多客户端)都没有实现自动进行主备切换,而Redis-sentinel本身也是一个独立运行的进程,他能监控多个master-slave集群,发现master宕机后能进行自动切换。
Sentinel的构造
Sentinel是一个监视器,它可以根据被监视实例的身份和状态来判断应该执行何种动作。

功能
- 监控(Monitoring)
Sentinel会不断地检查你的主服务器和从服务器是否运作正常。
- 提醒(Notification)
当被监控的某个Redis服务器出现问题时,Sentinel可以通过API向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic failover)
当一个主服务器不能正常工作时,Sentinel会开始一次自动故障迁移操作,它会将失效主服务器的其中一个从服务器升级为新的主服务器,并让失效服务器的其他从服务器改为负值新的主服务器;当客户端试图连接失效的主服务器时,集群也会向客户端返回新主服务器的地址,使得集群可以使用新主服务器代替失效服务器。
sentinel配置
mkdir /data/26380 cp /usr/local/redis/src/redis-sentinel /data/26380 cd /data/26380 Vim sentinel.conf port 26380 dir "/tmp" sentinel monitor mymaster 127.0.0.1 6380 2 sentinel down-after-milliseconds mymaster 60000 sentinel config-epoch mymaster 0 启动 ./redis-sentinel ./sentinel.conf
运行一个Sentinel所需的最少配置如下所示:


运行一个 Sentinel 所需的最少配置如下所示: sentinel monitor mymaster 127.0.0.1 6379 2 sentinel down-after-milliseconds mymaster 60000 sentinel failover-timeout mymaster 180000 sentinel parallel-syncs mymaster 1 sentinel monitor resque 192.168.1.3 6380 4 sentinel down-after-milliseconds resque 10000 sentinel failover-timeout resque 180000 sentinel parallel-syncs resque 5 第一行配置指示 Sentinel 去监视一个名为 mymaster 的主服务器, 这个主服务器的 IP 地址为 127.0.0.1 , 端口号为 6379 , 而将这个主服务器判断为失效至少需要 2 个 Sentinel 同意 (只要同意 Sentinel 的数量不达标,自动故障迁移就不会执行)。 不过要注意, 无论你设置要多少个 Sentinel 同意才能判断一个服务器失效, 一个 Sentinel 都需要获得系统中多数(majority) Sentinel 的支持, 才能发起一次自动故障迁移, 并预留一个给定的配置节点 (configuration Epoch ,一个配置节点就是一个新主服务器配置的版本号)。 换句话说, 在只有少数(minority) Sentinel 进程正常运作的情况下, Sentinel 是不能执行自动故障迁移的。 其他选项的基本格式如下: sentinel <选项的名字> <主服务器的名字> <选项的值> 各个选项的功能如下: down-after-milliseconds 选项指定了 Sentinel 认为服务器已经断线所需的毫秒数。 如果服务器在给定的毫秒数之内, 没有返回 Sentinel 发送的 Ping 命令的回复, 或者返回一个错误, 那么 Sentinel 将这个服务器标记为主观下线(subjectively down,简称 SDOWN )。 不过只有一个 Sentinel 将服务器标记为主观下线并不一定会引起服务器的自动故障迁移: 只有在足够数量的 Sentinel 都将一个服务器标记为主观下线之后, 服务器才会被标记为客观下线(objectively down, 简称 ODOWN ), 这时自动故障迁移才会执行。 将服务器标记为客观下线所需的 Sentinel 数量由对主服务器的配置决定。 parallel-syncs 选项指定了在执行故障转移时, 最多可以有多少个从服务器同时对新的主服务器进行同步, 这个数字越小, 完成故障转移所需的时间就越长。 如果从服务器被设置为允许使用过期数据集(参见对 redis.conf 文件中对 slave-serve-stale-data 选项的说明), 那么你可能不希望所有从服务器都在同一时间向新的主服务器发送同步请求, 因为尽管复制过程的绝大部分步骤都不会阻塞从服务器, 但从服务器在载入主服务器发来的 RDB 文件时, 仍然会造成从服务器在一段时间内不能处理命令请求: 如果全部从服务器一起对新的主服务器进行同步, 那么就可能会造成所有从服务器在短时间内全部不可用的情况出现。 你可以通过将这个值设为 1 来保证每次只有一个从服务器处于不能处理命令请求的状态。
配置文件
指定监控master sentinel monitor mymaster 127.0.0.1 6370 2 {2表示多少个sentinel同意} 安全信息 sentinel auth-pass mymaster root 超过15000毫秒后认为主机宕机 sentinel down-after-milliseconds mymaster 15000 当主从切换多久后认为主从切换失败 sentinel failover-timeout mymaster 900000 这两个配置后面的数量主从机需要一样,epoch为master的版本 sentinel leader-epoch mymaster 1 sentinel config-epoch mymaster 1
Sentinel命令
PING :返回 PONG 。 SENTINEL masters :列出所有被监视的主服务器 SENTINEL slaves <master name> SENTINEL get-master-addr-by-name <master name> : 返回给定名字的主服务器的 IP 地址和端口号。 SENTINEL reset <pattern> : 重置所有名字和给定模式 pattern 相匹配的主服务器。 SENTINEL failover <master name> : 当主服务器失效时, 在不询问其他 Sentinel 意见的情况下, 强制开始一次自动故障迁移。
三、Redis集群
Redis集群是一个可以在多个Redis节点之间进行数据共享的设施(installation)。
Redis集群不支持那些需要同时处理多个键的Redis命令,因为执行这些命令需要在多个Redis节点之间移动数据,并且在高负载的情况下,这些命令降低Redis集群的性能,并导致不可预测的行为。
Redis集群通过分区(partition)来提供一定程度的可用性(availability):即使集群中有一部分节点失效或者无法进行通讯,集群也可以继续处理命令请求。
将数据自动切分(split)到多个节点的能力。
当集群中的一部分节点失效或者无法进行通讯时,仍然可以继续处理命令请求的能力。
Redis集群数据共享
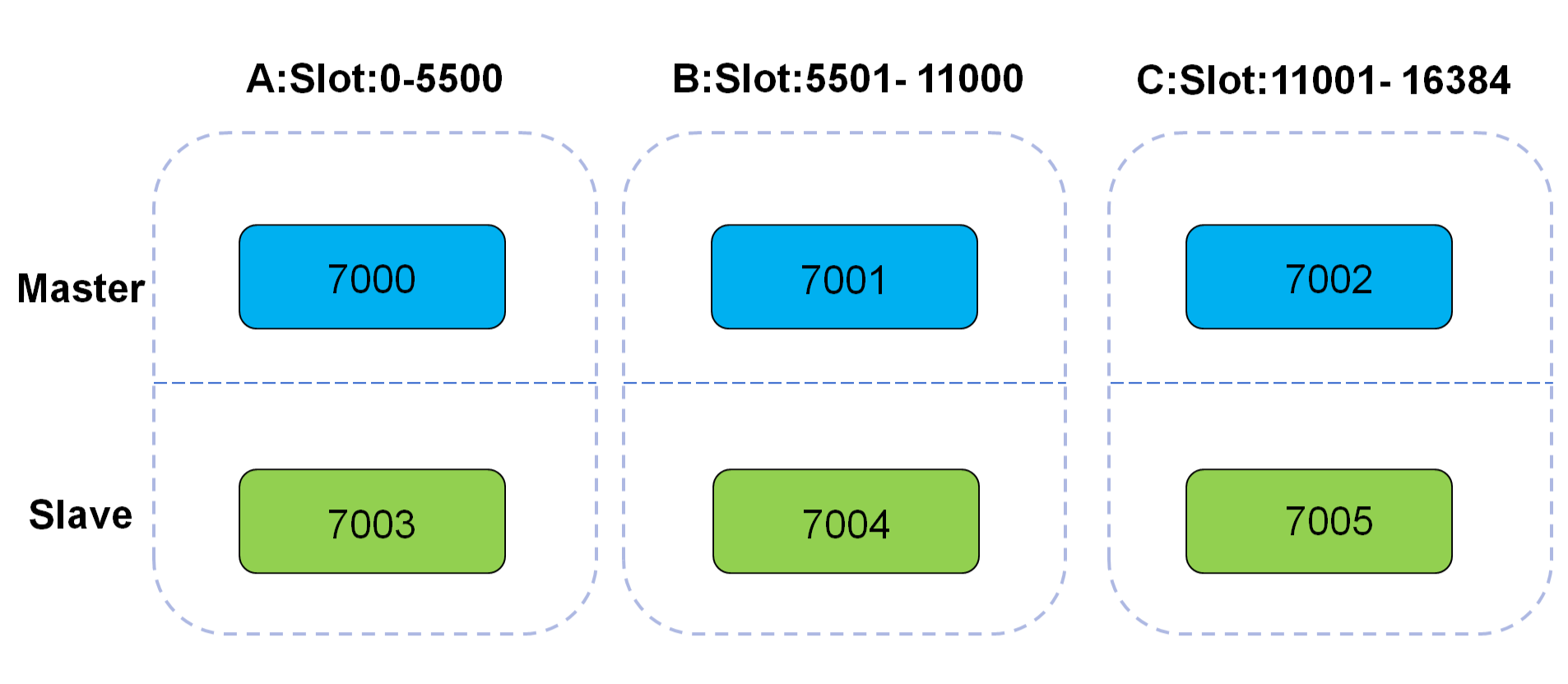
Redis集群使用数据分片(sharding)而非一致性哈希(consistency hashing)来实现:一个Redis集群包含16384个哈希槽(hash slot),数据库中的每个键都属于这16384个哈希槽的其中一个,集群使用公式CRC16(key)%16384来计算键key属于哪个槽,其中CRC16(key)语句用于计算键key的CRC16校验和。
节点A负责处理0号至5500号哈希槽。
节点B负责处理5501号至11000号哈希槽。
节点C负责处理11001号至16384号哈希槽。
Redis Cluster
集群组件安装
EPEL源安装ruby支持 yum install ruby rubygems -y 使用国内源 gem sources --add https://gems.ruby-china.org/ --remove https://rubygems.org/ gem install redis -v 3.3.3 gem sources -l 如果无法使用,可以使用aliyun gem sources -a http://mirrors.aliyun.com/rubygems/ gem sources --remove http://rubygems.org/
配置文件中包含
Redis 集群由多个运行在集群模式(cluster mode)下的 Redis 实例组成, 实例的集群模式需要通过配置来开启, 开启集群模式的实例将可以使用集群特有的功能和命令。
以下是一个包含了最少选项的集群配置文件示例:
port 7000 cluster-enabled yes cluster-config-file nodes.conf cluster-node-timeout 5000 appendonly yes
文件中的 cluster-enabled 选项用于开实例的集群模式, 而 cluster-conf-file 选项则设定了保存节点配置文件的路径, 默认值为 nodes.conf 。 节点配置文件无须人为修改, 它由 Redis 集群在启动时创建, 并在有需要时自动进行更新。 要让集群正常运作至少需要三个主节点, 不过在刚开始试用集群功能时, 强烈建议使用六个节点: 其中三个为主节点, 而其余三个则是各个主节点的从节点。 cd /data mkdir cluster-test cd cluster-test mkdir 7000 7001 7002 7003 7004 7005
创建应用
mkdir cluster-test cd cluster-test mkdir 7000 7001 7002 7003 7004 7005 拷贝应用 cp redis.conf redis-server ./7000 启动应用 cd 7000 ./redis-server ./redis.conf
创建集群
{redis_src_home}/src/redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 \
127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
给定 redis-trib.rb 程序的命令是 create , 这表示我们希望创建一个新的集群。
选项 --replicas 1
表示我们希望为集群中的每个主节点创建一个从节点。
集群客户端
redis-cli -c -p 7000 set foo bar get foo 重新分片 ./redis-trib.rb reshard 127.0.0.1:7000
集群管理
集群状态 redis-cli -p 7000 cluster nodes | grep master 故障转移 redis-cli -p 7002 debug segfault 查看状态 redis-cli -p 7000 cluster nodes | grep master
增加新的节点 ./redis-trib.rb add-node 127.0.0.1:7006 127.0.0.1:7000 删除一个节点 redis-trib del-node ip:port '<node-id>' 删除master节点之前首先要使用reshard移除master的全部slot,然后再删除当前节点 添加一个从节点 ./redis-trib.rb add-node --slave --master-id $[nodeid] 127.0.0.1:7008 127.0.0.1:7000
状态说明
集群最近一次向节点发送 PING 命令之后, 过去了多长时间还没接到回复。 节点最近一次返回 PONG 回复的时间。 节点的配置节点(configuration epoch):详细信息请参考 Redis 集群规范 。 本节点的网络连接情况:例如 connected 。 节点目前包含的槽:例如 127.0.0.1:7001 目前包含号码为 5960 至 10921 的哈希槽。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号