RDD初始以及常见transformations联系(maven打包jar)
@
目录
环境准备
IDEA2022
maven3.8.6
Hadoop3-3-0集群
Spark3-3-0
以上配置可查看我的往期博客
maven框架
目录结构
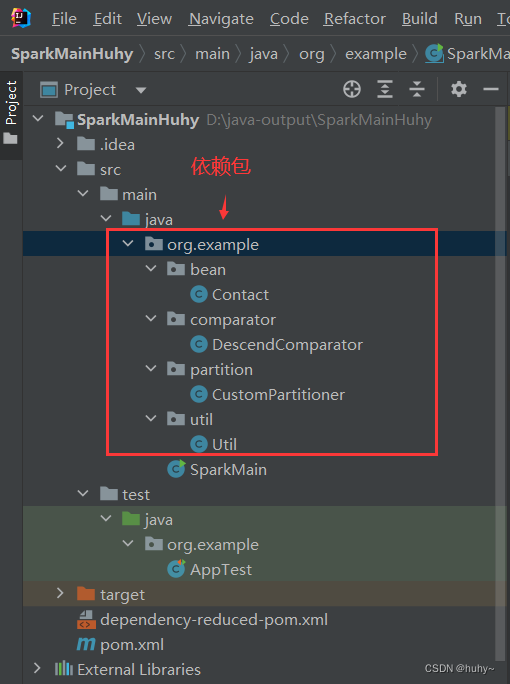
pom文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>SparkStudyHuhy</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>SparkStudyHuhy</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.0</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.13</artifactId>
<version>3.3.0</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.13</artifactId>
<version>3.3.0</version>
</dependency>
</dependencies>
<build>
<finalName>SparkStudyCases</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.4.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
依赖包
bean下的Contact类
package org.example.bean;
import java.io.Serializable;
import java.util.Objects;
/**
* @author zzd
* @create 2022-10-12 8:52
*/
public class Contact implements Serializable {
private Integer id;
private String name;
private String email;
public Contact() {}
public Contact(Integer id, String name, String email) {
this.id = id;
this.name = name;
this.email = email;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
@Override
public String toString() {
return "Contact{" +
"id=" + id +
", name='" + name + '\'' +
", email='" + email + '\'' +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Contact contact = (Contact) o;
return Objects.equals(id, contact.id) &&
Objects.equals(name, contact.name) &&
Objects.equals(email, contact.email);
}
@Override
public int hashCode() {
return Objects.hash(id, name, email);
}
}
comparator下的Descendcomparator类
package org.example.comparator;
import java.io.Serializable;
import java.util.Comparator;
public class DescendComparator implements Serializable, Comparator<String> {
//根据返回值排序:
// == 0, o1 == o2
// < 0, o1 < o2
// > 0, o1 > o2
@Override
public int compare(String o1, String o2) {
return o2.compareTo(o1);
}
}
partition下的CustPartiton类
package org.example.partition;
import org.apache.spark.Partitioner;
import java.io.Serializable;
/**
* 自定义分区器
*/
public class CustomPartitioner extends Partitioner implements Serializable {
@Override
public int numPartitions() {
//分区个数
return 2;
}
@Override
public int getPartition(Object key) {
//对于pair RDD中每个key,返回分区索引,也即该元素存放的分区。
//分区索引从0开始,到分区数-1。
String strKey = (String) key;
if(strKey.equals("candy1") || strKey.equals("candy3")) {
return 0;
}
return 1;
}
}
util下的Util类
package org.example.util;
import java.io.FileWriter;
/**
* @author zzd
* @create 2022-10-07 9:07
*/
public class Util {
public static String logFile = "spark-result.txt";
public static boolean appendToLogFile(String content) {
return appendToLogFile(content, true);
}
public static boolean appendToLogFile(String content, boolean append) {
boolean result = true;
try {
FileWriter fw = new FileWriter(logFile, append);
fw.write(content + "\n");
fw.close();
}catch (Exception e) {
result = false;
}
return result;
}
}
主函数
里面包含了;Spark RDD两种初始化方式: Parallelized Collections和External Datasets创建初始RDD。
练习RDD transformations,具体包括:map, flatMap, mapPartitions, mapPartitionsWithIndex等八种方法
输出RDD内容到外部日志文件。分别以1-8的参数形式来调用
package org.example;
import org.example.bean.Contact;
import org.example.comparator.DescendComparator;
import org.example.partition.CustomPartitioner;
import org.example.util.Util;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.storage.StorageLevel;
import scala.Tuple2;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Random;
/**
* @author huhy
* @create 2022-10-07 9:04
*/
public class SparkMain {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setAppName("SparkMain");
JavaSparkContext ctx = new JavaSparkContext(sparkConf);
Util.appendToLogFile(ctx.version());
new SparkMain().start(ctx, args);
ctx.close();
}
private void start(JavaSparkContext ctx, String[] args) {
String choice=args[0];
switch (choice){
case "1":testParallelize(ctx);break;
case "2":testExternalDatasets(ctx, args);break;
case "3":testRDDTransformations(ctx, args);break;
case "4":testActions(ctx, args);break;
case "5":testKeyValueTransformations(ctx, args);break;
case "6":testKeyValueActions(ctx, args);break;
case "7":testPartition(ctx,args);break;
case "8":wordCount(ctx, args);break;
}
// testParallelize(ctx);
// testExternalDatasets(ctx, args);
// testRDDTransformations(ctx, args);
// testActions(ctx, args);
// testKeyValueTransformations(ctx, args);
// testKeyValueActions(ctx, args);
// testPartition(ctx,args);
// wordCount(ctx, args);
}
private void wordCount(JavaSparkContext ctx, String[] args) {
//从外部文件创建字符串RDD,RDD中元素为文件的行。
JavaRDD<String> lines = ctx.textFile(args[1]);
//将字符串RDD中的每个元素,分割成一个个单词,去掉单词结尾的符号,创建单词RDD。
JavaRDD<String> words = lines.flatMap(line -> {
List<String> results = new ArrayList<>();
String[] splits = line.split("\\s+");
for(String split : splits) {
if(split.endsWith(".") || split.endsWith(",")
|| split.endsWith(":") || split.endsWith("!")) {
results.add(split.substring(0, split.length() - 1));
} else {
results.add(split);
}
}
return results.iterator();
});
//将单词RDD转换为Pair RDD,key为单词,value为1。
JavaPairRDD<String, Integer> ones = words.mapToPair(word -> new Tuple2<>(word, 1));
//通过key将value求和,因key为单词,求和后,value即为每个单词出现次数。
JavaPairRDD<String, Integer> counts = ones.reduceByKey((a, b) -> a + b);
//将单词按出现次数倒序排序。先将key变为次数,然后调用sortByKey倒序排序。
JavaPairRDD<Integer, String> sortedCountWord = counts.mapToPair(tuple2 -> new Tuple2<>(tuple2._2, tuple2._1)).sortByKey(false);
//将按次数倒序排序后的RDD转换为key为单词,value为次数的RDD。
JavaPairRDD<String, Integer> results = sortedCountWord.mapToPair(tuple2 -> new Tuple2<>(tuple2._2, tuple2._1));
//将RDD内容收集,然后写入日志文件。
Util.appendToLogFile(results.collect().toString());
}
private void testPartition(JavaSparkContext ctx, String[] args){
JavaPairRDD<String, Double> candyTx = ctx.parallelizePairs(Arrays.asList(
new Tuple2<>("candy1", 5.2), new Tuple2<>("candy2", 3.5),
new Tuple2<>("candy1", 2.0), new Tuple2<>("candy2", 6.0),
new Tuple2<>("candy3", 3.0)
), 4);
//getNumPartitions:获取RDD分区数。
Util.appendToLogFile("####### candyTx #######");
Util.appendToLogFile("partition : " + candyTx.getNumPartitions());
//coalesce:降低RDD分区到指定参数。
JavaPairRDD<String, Double> coalesceRDD = candyTx.coalesce(2);
Util.appendToLogFile("####### coalesceRDD #######");
Util.appendToLogFile("partition : " + coalesceRDD.getNumPartitions());
//repartition:随机重新shuffle(混洗)RDD 中的数据来创建更多或更少的分区,
//并在分区间进行数据平衡,也即每个分区包含数据量差不多。
//该操作将在整个网络上shuffle RDD中所有数据。
JavaPairRDD<String, Double> repartitionRDD = candyTx.repartition(2);
Util.appendToLogFile("####### repartitionRDD #######");
Util.appendToLogFile("partition : " + repartitionRDD.getNumPartitions());
//repartitionAndSortWithinPartitions:通过指定的分区器对象对RDD重分区,
//并在每个分区内通过自定义Comparator对key进行排序。
JavaPairRDD<String, Double> reRDD =
candyTx.repartitionAndSortWithinPartitions(
new CustomPartitioner(), new DescendComparator());
JavaRDD<String> stringJavaRDD = reRDD.mapPartitionsWithIndex((index, iterator) -> {
List<String> result = new ArrayList<>();
while (iterator.hasNext()) {
result.add(index + " -> " + iterator.next());
}
return result.iterator();
}, true);
Util.appendToLogFile("############## stringJavaRDD #############");
Util.appendToLogFile("partition : " + stringJavaRDD.getNumPartitions());
Util.appendToLogFile("partition content : " + stringJavaRDD.collect());
}
private void testKeyValueActions(JavaSparkContext ctx, String[] args) {
JavaPairRDD<String, Double> candyTx = ctx.parallelizePairs(Arrays.asList(
new Tuple2<>("candy1", 5.2), new Tuple2<>("candy2", 3.5),
new Tuple2<>("candy1", 2.0), new Tuple2<>("candy2", 6.0),
new Tuple2<>("candy3", 3.0)
));
Util.appendToLogFile("######## countByKey : " + candyTx.countByKey());
Util.appendToLogFile("######## collectAsMap : " + candyTx.collectAsMap());
//lookup:通过key查找,返回匹配key的value列表。
Util.appendToLogFile("############## lookup ####################");
Util.appendToLogFile("candy1 : " + candyTx.lookup("candy1"));
Util.appendToLogFile("candy2 : " + candyTx.lookup("candy2"));
Util.appendToLogFile("candy3 : " + candyTx.lookup("candy3"));
//RDD持久化
candyTx.persist(StorageLevel.MEMORY_ONLY());
candyTx.cache();
}
private void testKeyValueTransformations(JavaSparkContext ctx, String[] args) {
JavaRDD<String> stringRDD = ctx.parallelize(Arrays.asList(
"Spark","is","an","amazing","piece","of","technology"
));
//在Java中,key-value pair(键-值对)通过Tuple2对象表示。
//元素为key-value pair的RDD称为PairRDD,用JavaPairRDD表示,类似Map,但key允许重复。
//Spark中有一些操作只有在pair RDD上才能调用。Pair RDD同时具有标准RDD操作和一些特殊的key-value操作。
//通过mapToPair操作,生成PairRDD。mapToPair和map含义一样,lambda表达式要求返回一个Tuple2对象。
JavaPairRDD<Integer, String> lenWordRDD = stringRDD.mapToPair(word -> new Tuple2<>(word.length(), word));
//groupByKey:将父RDD中相同key的value进行分组,作为生成的子RDD中的一个元素。
//子RDD中元素也为key-value,个数和父RDD中不同key的个数相同。
//子RDD中每个元素的key为父RDD中不同的key,value为父RDD中该key对应的value的集合。
JavaPairRDD<Integer, Iterable<String>> wordByLenRDD = lenWordRDD.groupByKey();
Util.appendToLogFile("############## groupByKey ##################");
Util.appendToLogFile(wordByLenRDD.collect().toString());
//通过并行化集合的方式生成PairRDD,要求集合中的元素为Tuple2对象。
JavaPairRDD<String, Double> candyTx = ctx.parallelizePairs(Arrays.asList(
new Tuple2<>("candy1", 5.2), new Tuple2<>("candy2", 3.5),
new Tuple2<>("candy1", 2.0), new Tuple2<>("candy2", 6.0),
new Tuple2<>("candy3", 3.0)
));
//如果需要对groupByKey操作之后的值的集合进一步处理,该处理是遵守交换律和结合律的二项操作,
//那么最好使用reduceByKey操作来加快处理逻辑。
//reduceByKey:将父RDD中相同key的value归约为一个value,作为生成的子RDD中的一个元素(key-value)。
//该操作的执行分为两步:
// 1. 将相同key的value分组在一起;
// 2. 对每个key的分组后的value列表应用给定的归约函数,将其归约为一个value。
//reduceByKey的实现包含一个内置的优化,可在两个级别上执行上述两步。
// 第一个级别是在每个分区;
// 第二个级别是在分区间。
//首先通过在每个分区应用此操作,可将分区内相同key的多个元素归约成一个元素,
//结果将大大减少需要在分区间移动的数据量。
JavaPairRDD<String, Double> summaryTx = candyTx.reduceByKey((a, b) -> a + b);
Util.appendToLogFile("############## reduceByKey ##################");
Util.appendToLogFile(summaryTx.collect().toString());
JavaPairRDD<Double, String> summaryByPrice = summaryTx.mapToPair(
tuple2 -> new Tuple2<>(tuple2._2, tuple2._1));
//sortByKey:通过key对父RDD中的元素进行排序,生成子RDD中元素。
//默认为升序排序,可以指定降序或自定义Comparator。
JavaPairRDD<Double, String> sortRDD = summaryByPrice.sortByKey();
Util.appendToLogFile("############## sortByKey ##################");
Util.appendToLogFile(sortRDD.collect() + "");
JavaPairRDD<String, Double> candy1Tx = ctx.parallelizePairs(Arrays.asList(
new Tuple2<>("candy1", 5.2), new Tuple2<>("candy2", 3.5),
new Tuple2<>("candy1", 2.0), new Tuple2<>("candy2", 6.0),
new Tuple2<>("candy3", 3.0)
));
JavaPairRDD<String, Double> candy2Tx = ctx.parallelizePairs(Arrays.asList(
new Tuple2<>("candy1", 5.2), new Tuple2<>("candy2", 3.5),
new Tuple2<>("candy1", 2.0), new Tuple2<>("candy2", 6.0),
new Tuple2<>("candy3", 3.0)
));
//join:连接操作,类似于数据库中的join,该操作有多个变形,在后续Spark SQL模块中细说。
JavaPairRDD<String, Tuple2<Double, Double>> joinRDD = candy1Tx.join(candy2Tx);
Util.appendToLogFile("############## join ##################");
Util.appendToLogFile(joinRDD.collect() + "");
}
private void testActions(JavaSparkContext ctx, String[] args) {
JavaRDD<Integer> numberRDD = ctx.parallelize(
Arrays.asList(6,4,1,7,10,2,9,3,8,5), 2);
long count = numberRDD.count();
Util.appendToLogFile("############## count : " + count);
List<Integer> integers = numberRDD.takeOrdered(4);
Util.appendToLogFile("############## takeOrdered : " + integers);
List<Integer> top = numberRDD.top(4);
Util.appendToLogFile("############## top : " + top);
//reduce:归约操作,使用给定的函数func把RDD中所有元素归约为一个值,返回给驱动程序。
//函数func必须满足:1.二项操作,即两个相同类型的参数产生一个相同类型的结果;2. 满足交换律和结合律。
//归约过程:
//1. 对于每个分区,首先取分区的前2个元素作为func的参数,生成一个计算结果;
//2. 将上一次计算结果作为func的第一个参数,取分区中的第三个元素作为第二个参数,生成计算结果;
//3. 依次类推,直到分区中所有数据归约为一个值;
//4. 将每个分区归约结果值再按上述过程归约,生成最终结果返回给驱动程序。
Integer reduce = numberRDD.reduce((a, b) -> a + b);
Util.appendToLogFile("############## reduce : " + reduce);
numberRDD.saveAsObjectFile(args[1]);
numberRDD.saveAsTextFile(args[2]);
}
private void testRDDTransformations(JavaSparkContext ctx, String[] args) {
//创建字符串RDD
JavaRDD<String> stringRDD = ctx.parallelize(Arrays.asList(
"Spark is awesome",
"Spark is cool"
));
//map : 对于父RDD的每个元素调用一次函数func,且函数func只能返回一个值,不能返回集合类型。
//父RDD中元素作为func的形参,func的返回值作为子RDD的元素。
//func可以返回任意类型,也就是说子RDD中元素类型可以和父RDD不同。
//map操作是1to1映射,即父RDD中一个元素生成子RDD中一个元素,
//父RDD和子RDD元素个数一一对应。
JavaRDD<String> allCapsRDD = stringRDD.map(line -> line.toUpperCase());
Util.appendToLogFile("######## map allCapsRDD #########");
//将allCapsRDD中所有元素以列表形式收集返回驱动程序,驱动程序将其写入日志文件中。
Util.appendToLogFile(allCapsRDD.collect().toString());
JavaRDD<String> contactDataRDD = ctx.parallelize(Arrays.asList(
"1#John Doe#jdoe@domain.com",
"2#Mary Jane#jane@domain.com"
));
//子RDD是自定义Contact类型,和父RDD类型不同。
JavaRDD<Contact> contactRDD = contactDataRDD.map(line -> {
String[] splits = line.split("#");
return new Contact(Integer.parseInt(splits[0]), splits[1], splits[2]);
});
Util.appendToLogFile("######## map contactRDD #########");
Util.appendToLogFile(contactRDD.collect().toString());
//flatMap : 和map类似,也是对于父RDD的每个元素调用一次函数func,
//区别在于函数func的返回值是集合,而不能是单个值。
//此操作父RDD中一个元素可能生成子RDD中的0、1或者多个元素,
//即父RDD和子RDD中元素是1toM(1对多)映射。
//flatMap要求函数func的返回值是集合类型的迭代器对象,
//常见简单做法是在func内部定义一个集合对象,把要返回的元素放在集合中,
//最后返回集合对象的迭代器。
JavaRDD<String> wordRDD = stringRDD.flatMap(line -> {
List<String> results = new ArrayList<>();
String[] wordSplits = line.split("\\s+");
for(String word : wordSplits) {
results.add(word);
}
return results.iterator();
});
Util.appendToLogFile("######## flatMap wordRDD #########");
Util.appendToLogFile(wordRDD.collect().toString());
//filter:对于父RDD中的每个元素,调用一次函数func,
//父RDD中元素作为func的形参,
//func返回true时,此元素将作为子RDD中的一个元素,
//func返回false时,此元素将不出现在子RDD中。
//filter操作常用来对RDD进行过滤,生成满足过滤条件的子RDD。
//函数func的返回值必须是boolean类型。
JavaRDD<String> filterRDD = wordRDD.filter(word -> {
boolean result = false;
if(word.length() > 3) {
result = true;
}
return result;
});
Util.appendToLogFile("######## filter filterRDD #########");
Util.appendToLogFile(filterRDD.collect().toString());
JavaRDD<String> sampleListRDD = ctx.parallelize(Arrays.asList(
"One", "Two", "Three", "Four", "Five"
), 2);
//mapPartitions:和map类型,对于父RDD的每个分区调用一次函数func,
//func的形参是父RDD分区迭代器对象,通过该迭代器可访问父RDD分区中元素,
//func的返回值也是迭代器对象,用于生成子RDD分区中元素。
//即func的输入和返回值必须都是迭代器对象。
//此操作对于父RDD的一个分区调用一次func,而不是一个元素调用一次func。
//如,父RDD有2个分区,共1000个元素,对于map或者flatMap操作,func将被调用1000次,
//而对于mapPartitions操作,func只被调用2次。
//此操作在实际大数据处理中更常用,通过减少函数调用次数来优化数据处理性能。
JavaRDD<String> sampleRDD = sampleListRDD.mapPartitions(iterator -> {
List<String> results = new ArrayList<>();
Random random = new Random();
String prefix = random.nextInt(10) + " -> ";
while (iterator.hasNext()) {
String element = iterator.next();
results.add(prefix + element);
}
return results.iterator();
});
Util.appendToLogFile("######## mapPartitions sampleRDD #########");
Util.appendToLogFile(sampleRDD.collect().toString());
//mapPartitionsWithIndex:和mapPartitions含义一样,区别在于函数func的形参多了一个分区索引(从0开始)
JavaRDD<String> sampleIndexRDD = sampleListRDD.mapPartitionsWithIndex(
(index, iterator) -> {
List<String> results = new ArrayList<>();
String prefix = index + " -> ";
while (iterator.hasNext()) {
String element = iterator.next();
results.add(prefix + element);
}
return results.iterator();
}, true);
Util.appendToLogFile("######## mapPartitionsWithIndex sampleIndexRDD #########");
Util.appendToLogFile(sampleIndexRDD.collect().toString());
JavaRDD<Integer> rdd1 = ctx.parallelize(Arrays.asList(1,2,3,4,5));
JavaRDD<Integer> rdd2 = ctx.parallelize(Arrays.asList(3,4,5,6,7));
//union:并集操作,参数为另一个RDD,生成的子RDD由两个父RDD中的所有元素组成。
JavaRDD<Integer> union = rdd1.union(rdd2);
Util.appendToLogFile("######## union #########");
Util.appendToLogFile(union.collect().toString());
//intersection:交集操作,参数为另一个RDD,生成的子RDD由两个父RDD中都存在的元素组成。
//此操作通过比较元素的hash值来判断两个RDD中是否存在相同的元素。
JavaRDD<Integer> rdd3 = rdd1.intersection(rdd2);
Util.appendToLogFile("######## intersection #########");
Util.appendToLogFile(rdd3.collect().toString());
//subtract:差集,参数为另一个RDD,生成的子RDD由在RDD1中存在而在RDD2中不存在的元素组成。
rdd3 = rdd1.subtract(rdd2);
Util.appendToLogFile("######## subtract #########");
Util.appendToLogFile(rdd3.collect().toString());
//distinct:去重操作,将父RDD中重复元素只保留一个作为子RDD元素,
//即子RDD中没有重复元素。该操作对父RDD中每个元素计算hash值,通过比较hash值判断两个元素是否相同。
JavaRDD<Integer> distinct = union.distinct();
Util.appendToLogFile("######## distinct #########");
Util.appendToLogFile(distinct.collect().toString());
JavaRDD<Integer> numberRDD = ctx.parallelize(Arrays.asList(1,2,3,4,5,6,7,8,9,10));
//sample:随机采集操作,即在父RDD中随机采集一部分元素生成子RDD。
//该操作有三个参数:
//第一个参数表示采集的结果是否有重复元素,即一个元素被采集多次。
//第二个参数表示采集的百分比,0-1之间的小数,并不能保证采集数据个数和百分比精确匹配。
//第三个参数为随机数种子,用来产生随机数用于随机采集,当种子相同时,
//产生的随机数相同,也就采集的结果相同。该参数使用默认值即可,也即不必输入此参数。
JavaRDD<Integer> sampleNumberRDD = numberRDD.sample(true, 0.5);
Util.appendToLogFile("######## sample #########");
Util.appendToLogFile(sampleNumberRDD.collect().toString());
sampleNumberRDD = numberRDD.sample(false, 0.5, 123463);
Util.appendToLogFile("######## sample #########");
Util.appendToLogFile(sampleNumberRDD.collect().toString());
sampleNumberRDD = numberRDD.sample(false, 0.5, 123463);
Util.appendToLogFile("######## sample #########");
Util.appendToLogFile(sampleNumberRDD.collect().toString());
}
private void testExternalDatasets(JavaSparkContext ctx, String[] args) {
//通过HDFS中文件创建RDD,文件内容的每行作为RDD中的一个元素,
//即文件有多少行,RDD中就有多少个元素。
JavaRDD<String> textRDD1 = ctx.textFile(args[1]);
//基于目录创建pair RDD,RDD中每个元素包含两部分,即key和value,类似Java中Map,
//目录下每个文件对应RDD中一个元素,key为文件名,value为文件内容。
JavaPairRDD<String, String> textRDD2 = ctx.wholeTextFiles(args[2]);
Util.appendToLogFile("###############################");
Util.appendToLogFile("text rdd1 : " + textRDD1.take(2));
Util.appendToLogFile("###############################");
Util.appendToLogFile("pair text rdd2 : " + textRDD2.take(2));
}
private void testParallelize(JavaSparkContext ctx) {
List<Integer> data = Arrays.asList(1,2,3,4,5);
List<String> data1 = new ArrayList<>();
data1.add("AA");
data1.add("BB");
data1.add("CC");
JavaRDD<Integer> dataRDD1 = ctx.parallelize(data);
JavaRDD<String> dataRDD2 = ctx.parallelize(data1, 2);
Util.appendToLogFile("int rdd1 : " + dataRDD1.take(2));
Util.appendToLogFile("String rdd2 : " + dataRDD2.take(2));
List<Tuple2<String, String>> data3 = Arrays.asList(
new Tuple2<>("k1", "v1"), new Tuple2<>("k2", "v2"),
new Tuple2<>("k3", "v3"), new Tuple2<>("k4", "v4")
);
JavaPairRDD<String, String> dataRDD3 = ctx.parallelizePairs(data3);
Util.appendToLogFile(dataRDD3.take(2).toString());
}
}
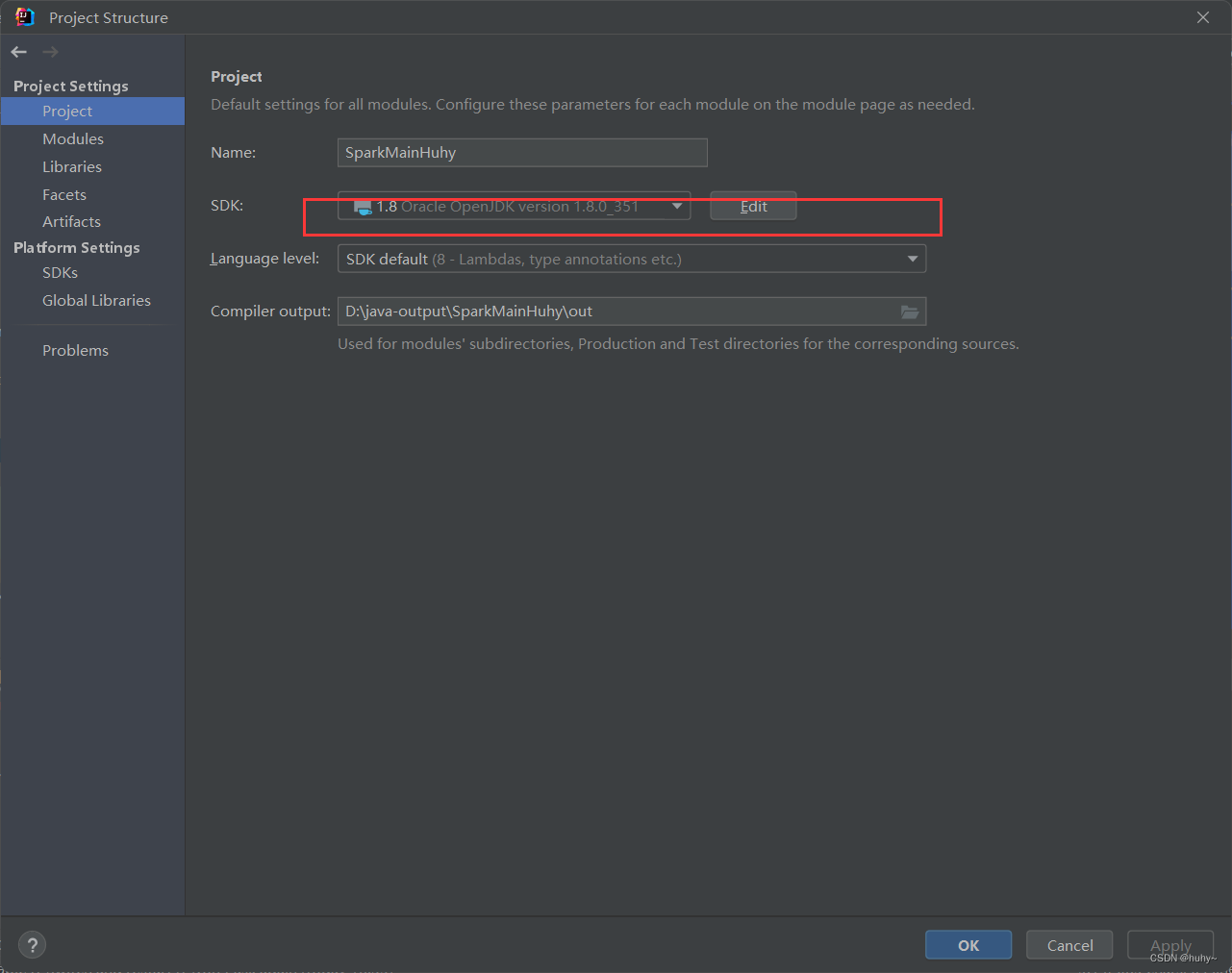
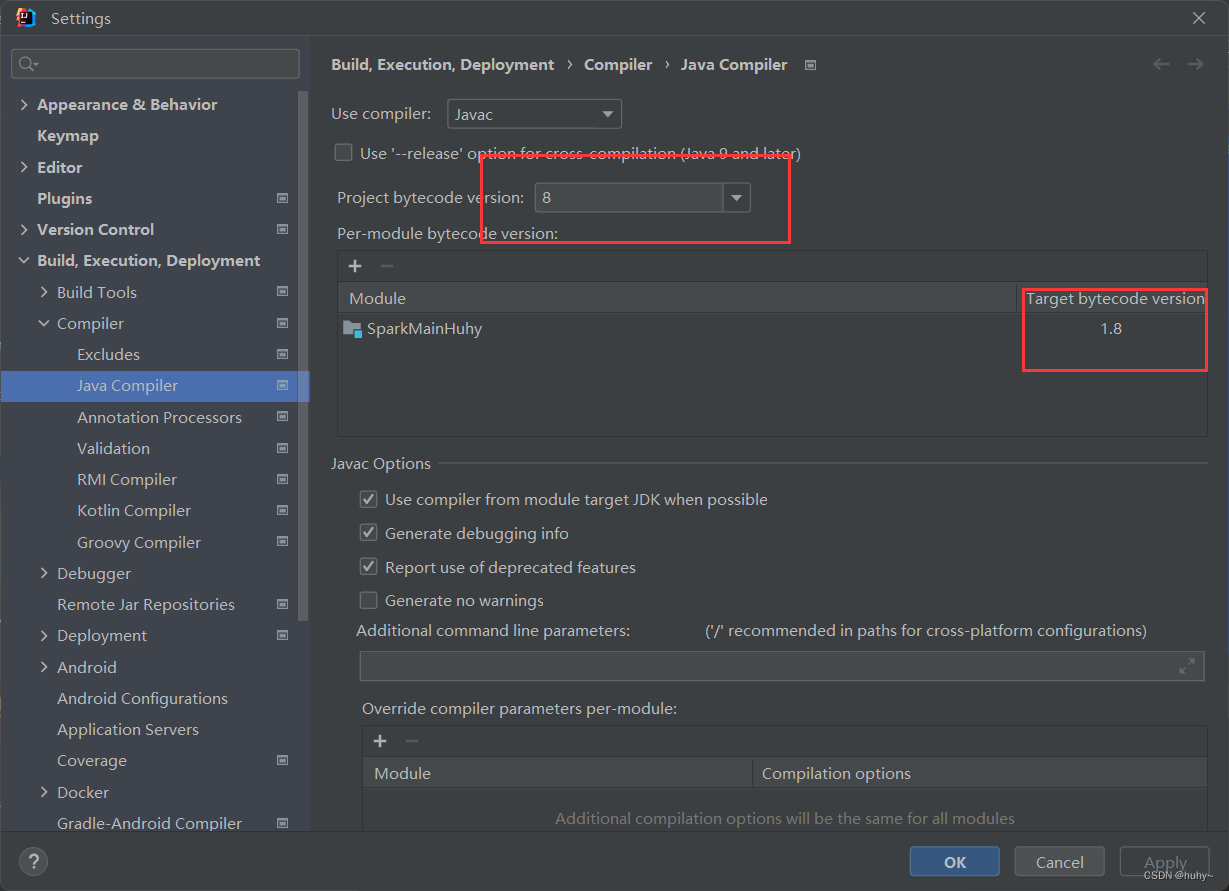
解决(无效的源发行版本问题)
如果本地用的jdk与maven打包的依赖不一致的问题,如本地是18,pom文件里面指定的是1.8
那么打包的时候可能就会出现无效的源发行版本18.
解决:
1,下载相应的jdk1.8
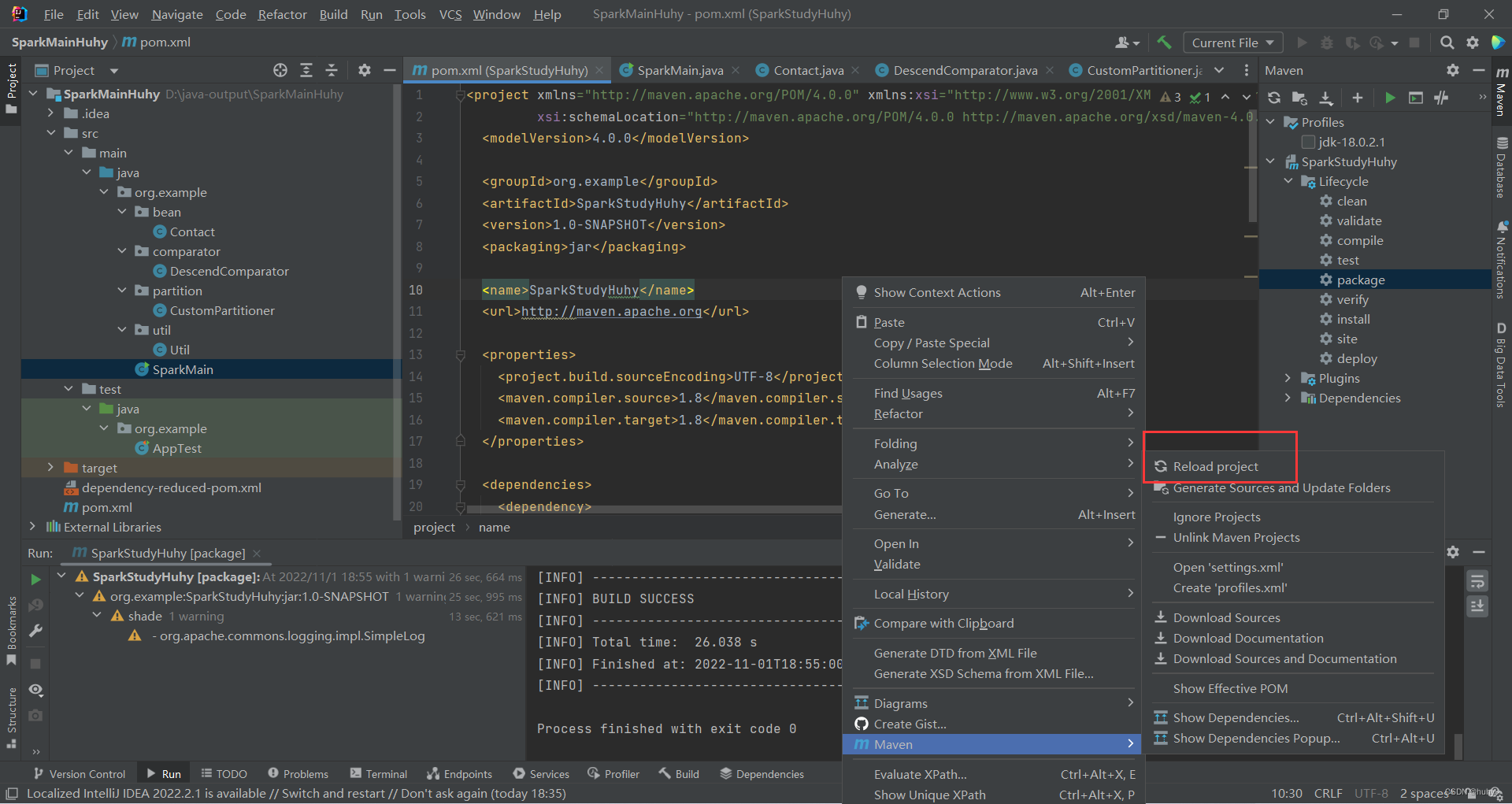
2,修改项目的指定jdk,然后点击apply应用后点击ok
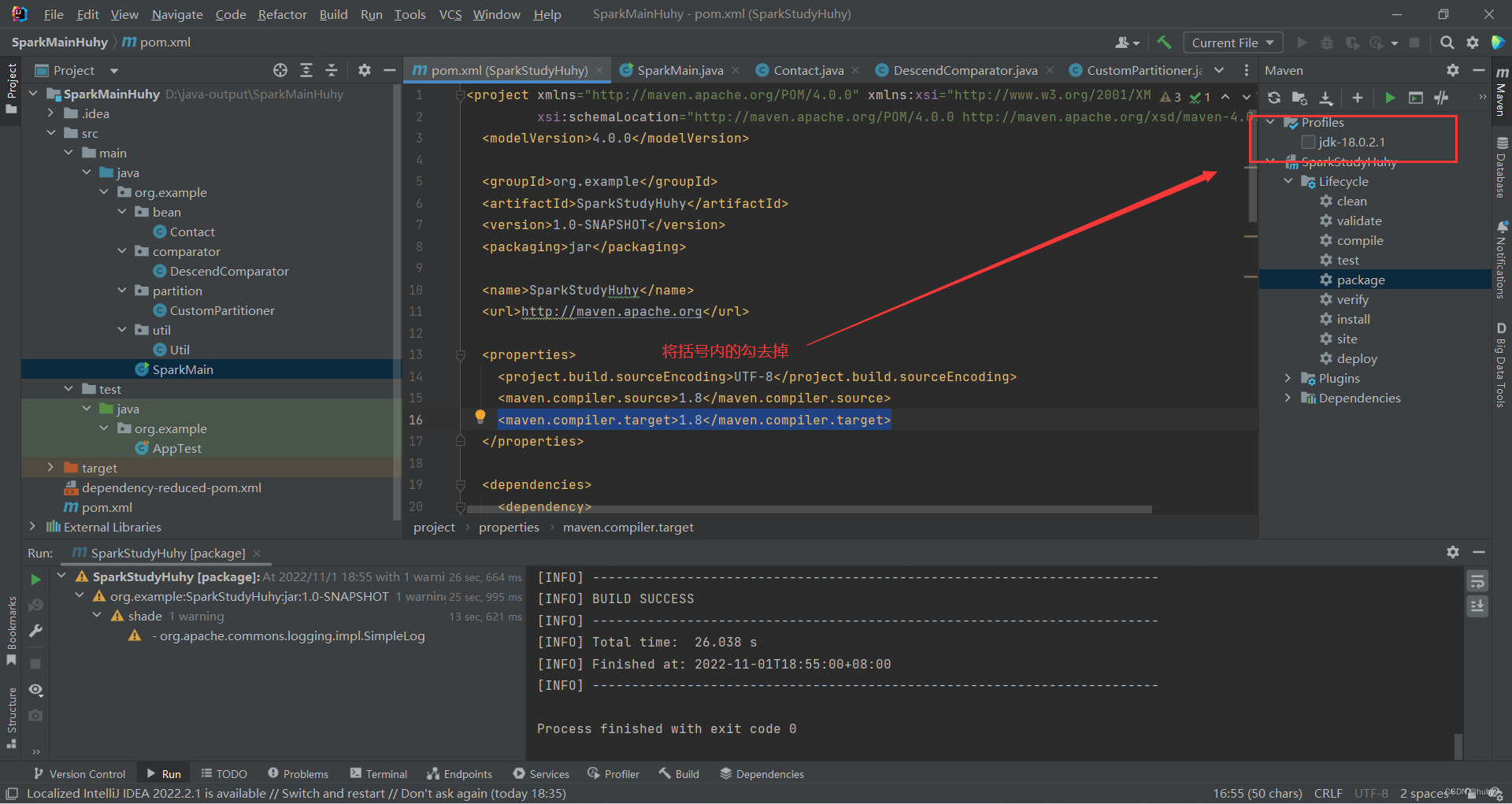
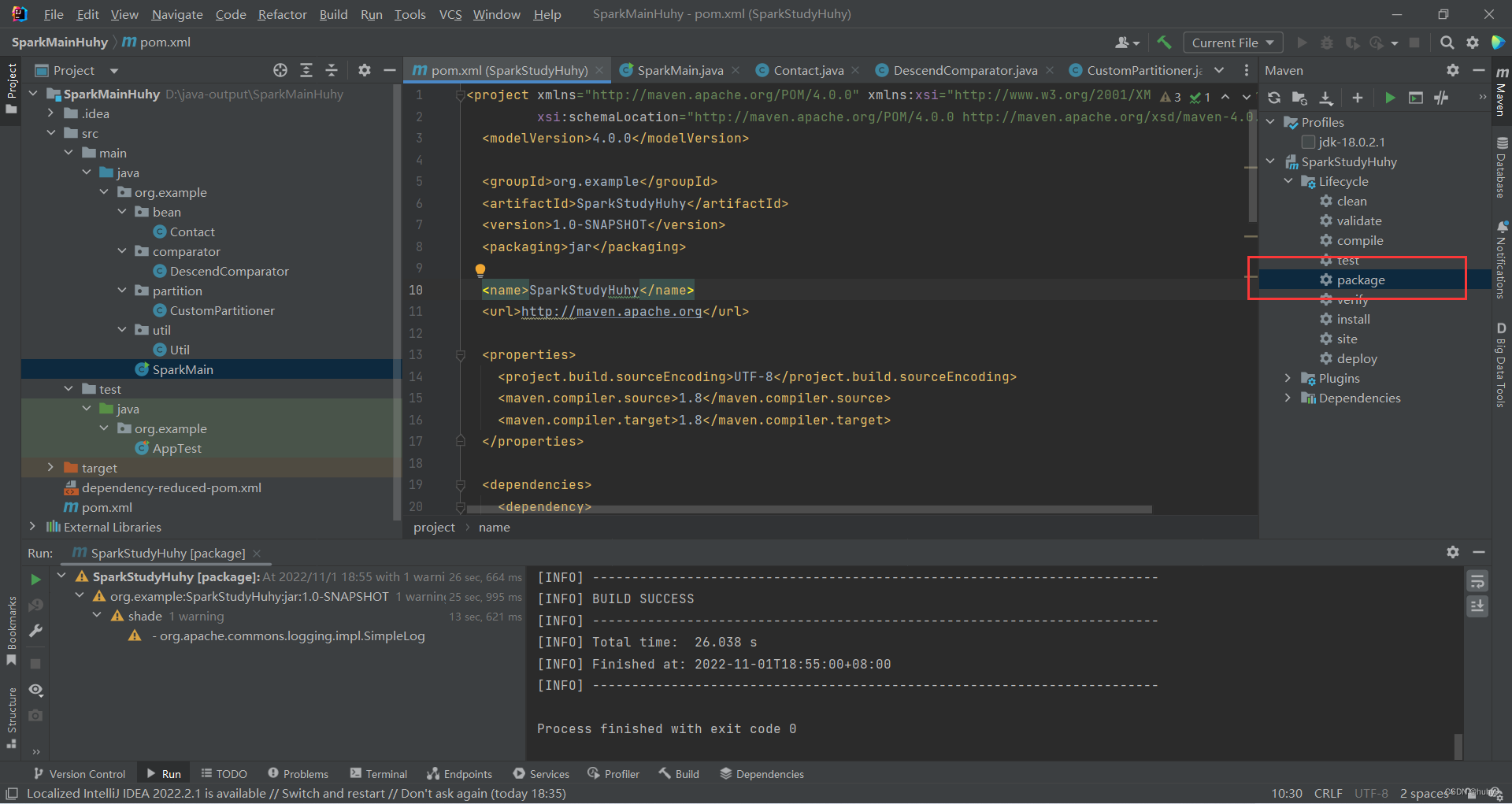
3,然后重新加载一下项目后打包
运行打包的jar包
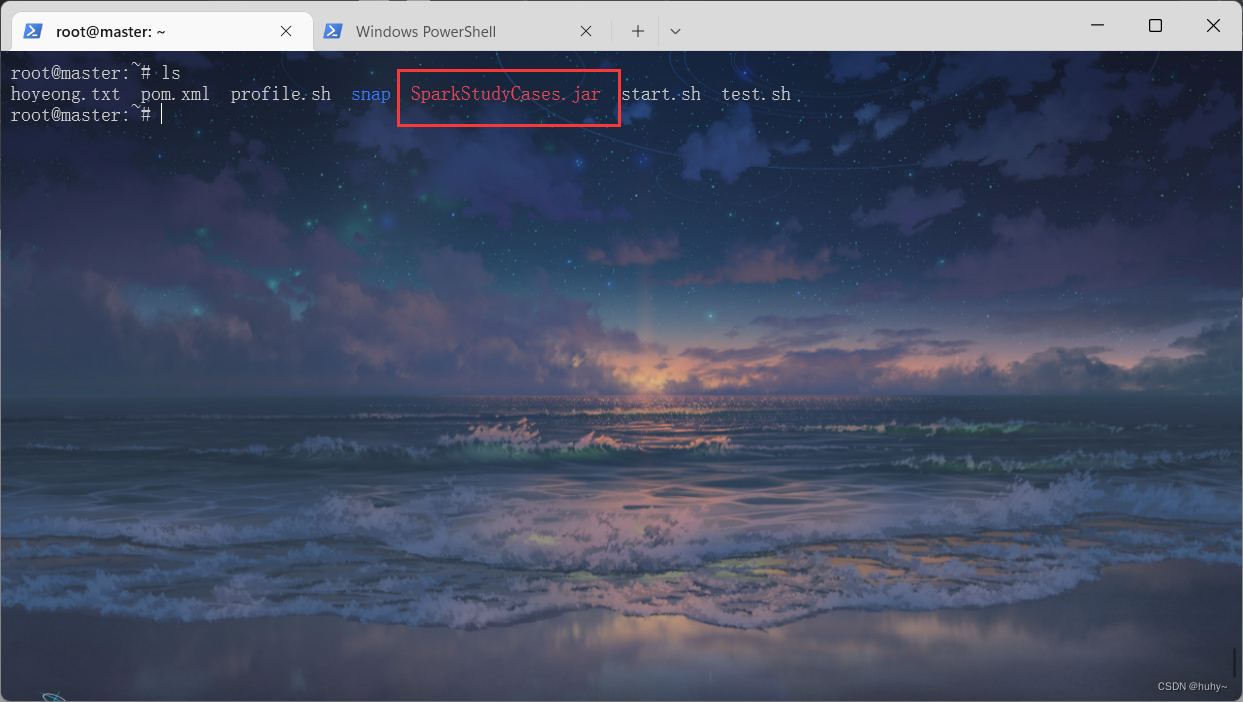
环境准备
jar包上传到集群环境下
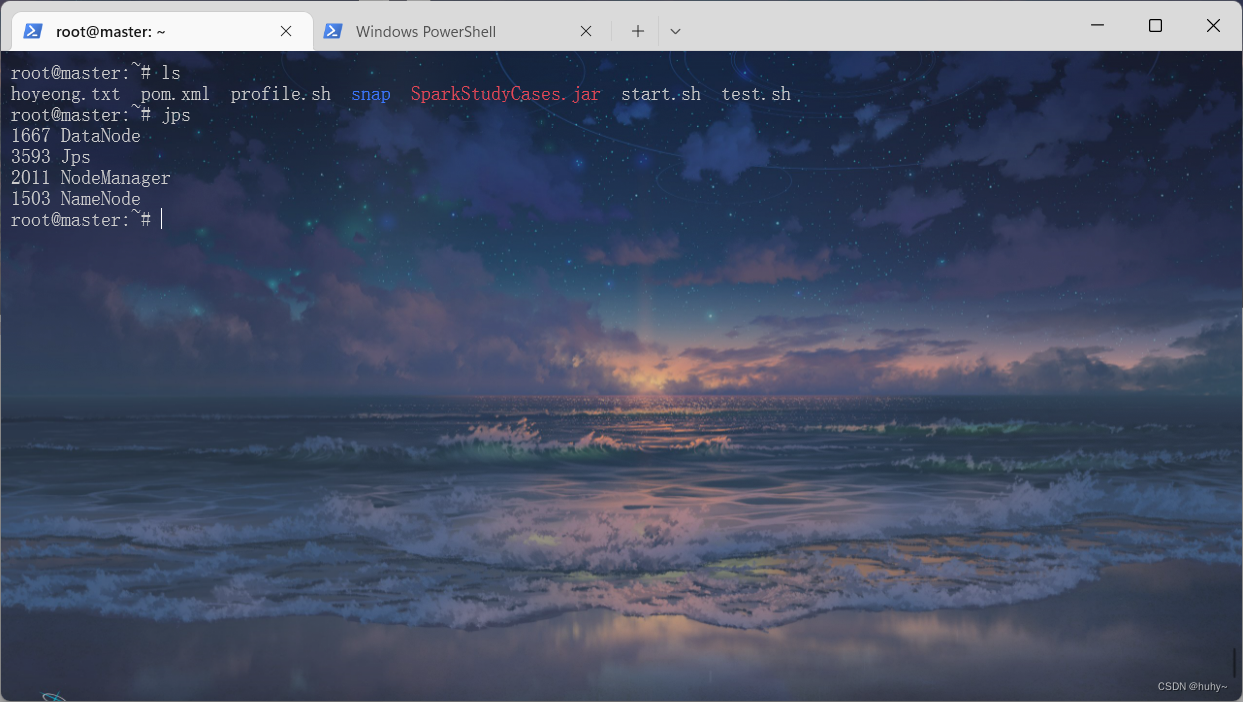
启动hadoop集群,保证环境是运行的
RDD初始化
Parallelized Collections
语法格式;
sparkbin目录下;spark-submit --clss GroupID.主函数类名 jar包名 类中自定义的参数名称
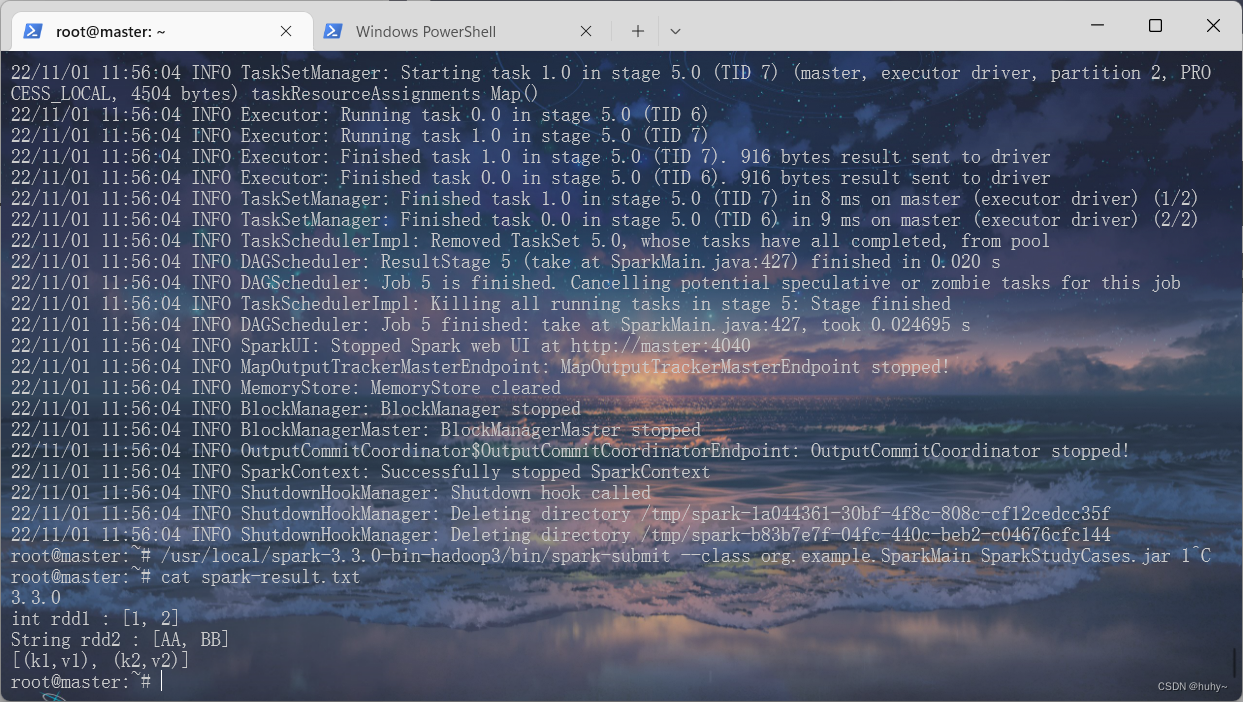
/usr/local/spark-3.3.0-bin-hadoop3/bin/spark-submit --class org.example.SparkMain SparkStudyCases.jar 1
查看生成的日志
ExternalDatasets
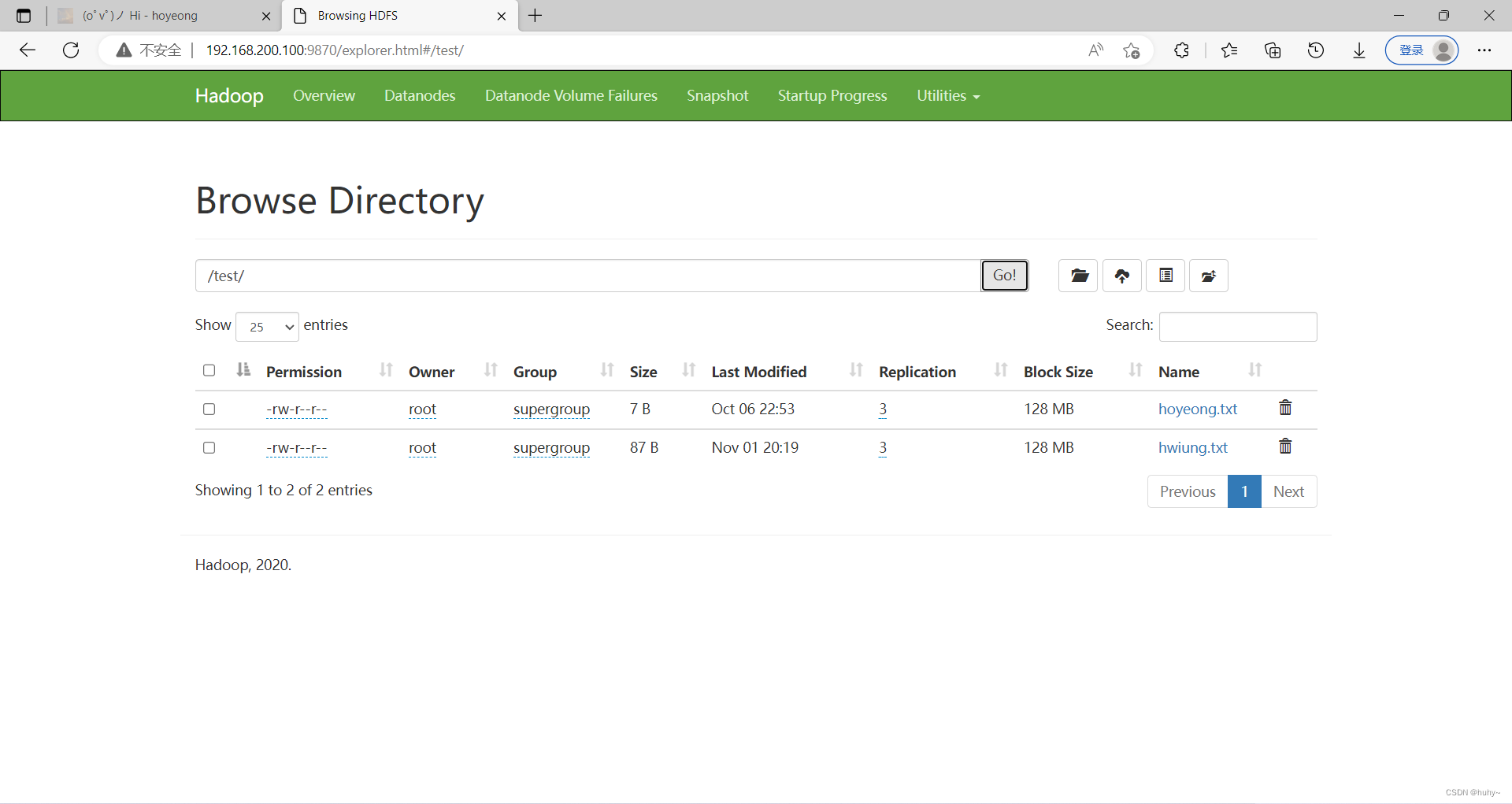
作用;用于查看hadoop的hdfs下的目录
代码后需要跟上路径,第一个是单个文件查看,第二个是多个文件查看
/usr/local/spark-3.3.0-bin-hadoop3/bin/spark-submit --class org.example.SparkMain SparkStudyCases.jar 2 /
test/hoyeong.txt /test/*.txt
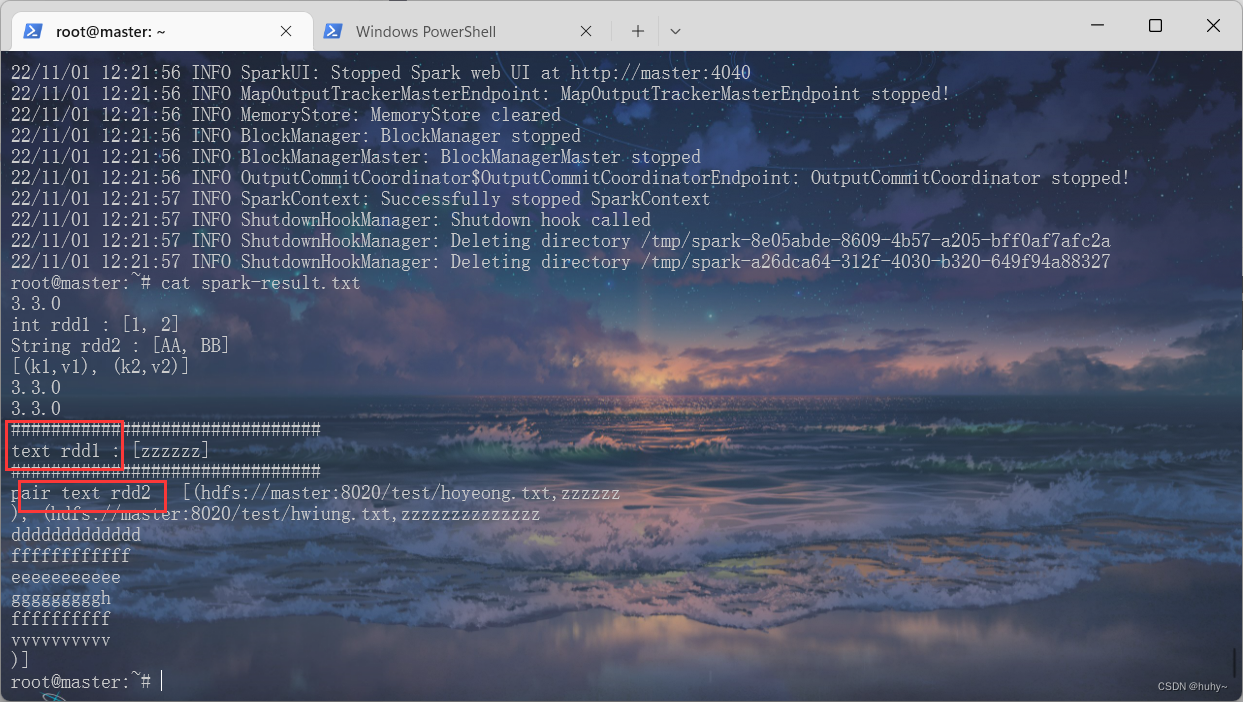
两种方式查看
RDDTransformations
/usr/local/spark-3.3.0-bin-hadoop3/bin/spark-submit --class org.example.SparkMain SparkStudyCases.jar 3
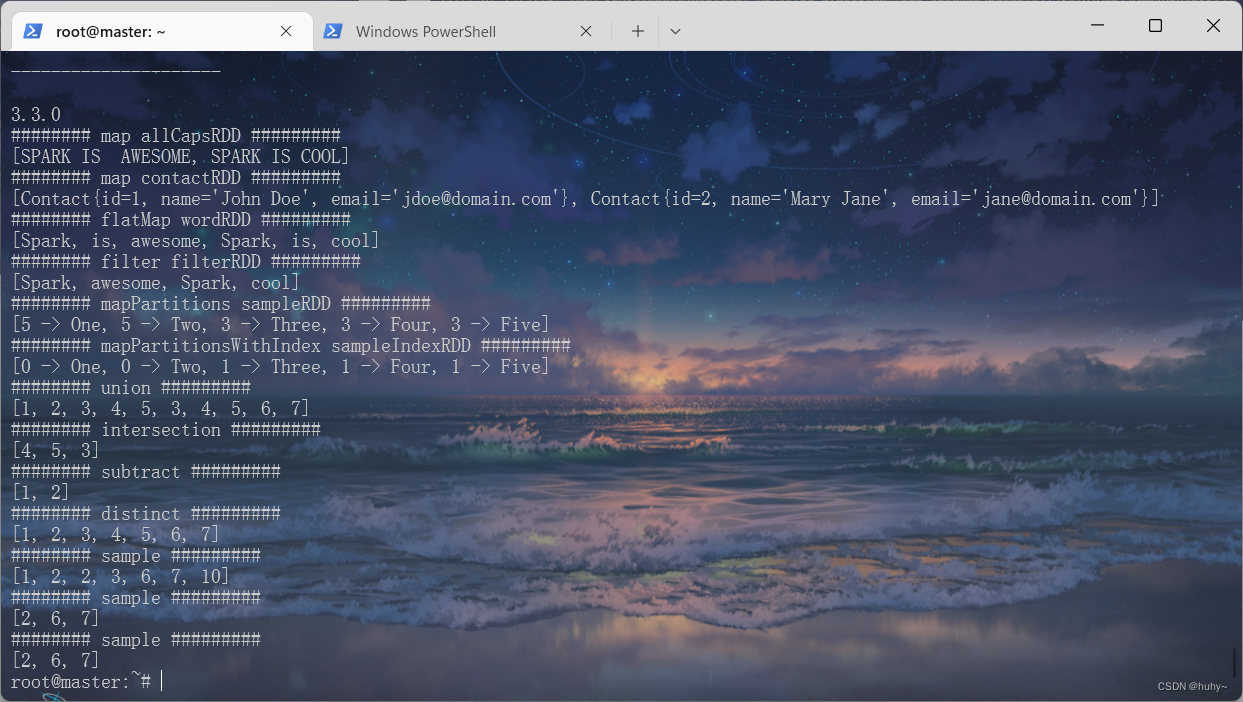
Actions
/usr/local/spark-3.3.0-bin-hadoop3/bin/spark-submit --class org.example.SparkMain SparkStudyCases.jar 4
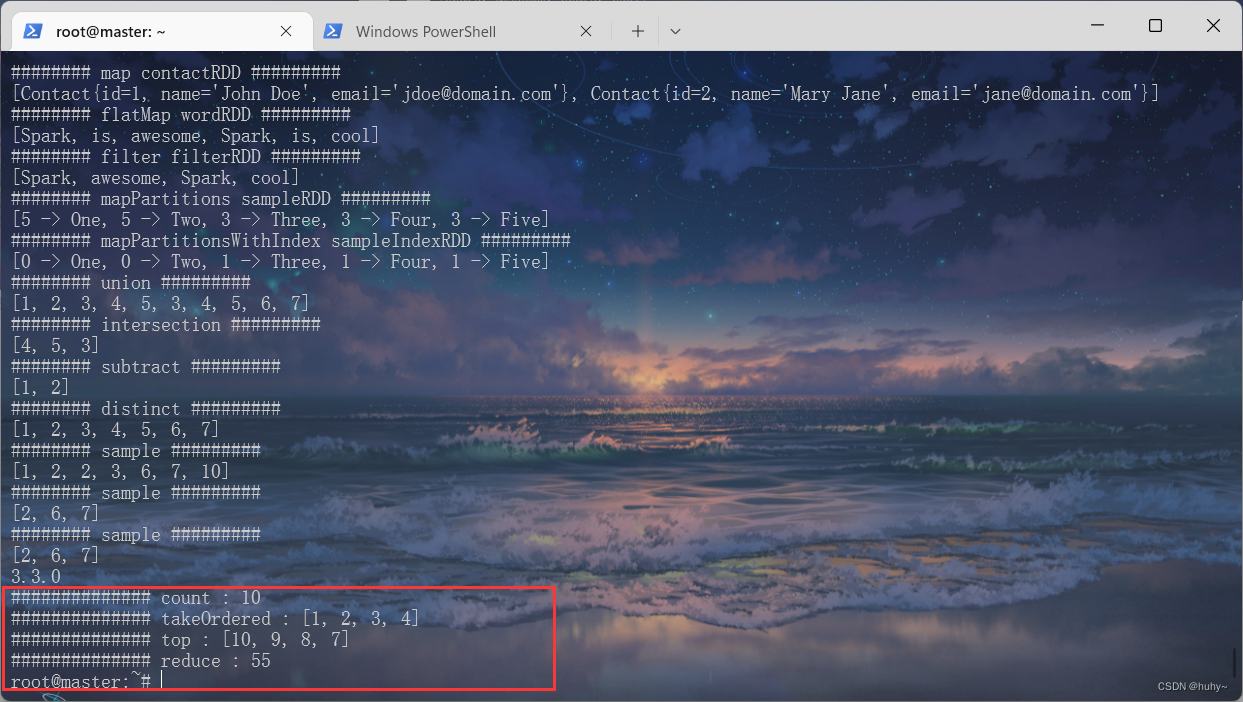
KeyValueTransformations
/usr/local/spark-3.3.0-bin-hadoop3/bin/spark-submit --class org.example.SparkMain SparkStudyCases.jar 5

KeyValueActions
/usr/local/spark-3.3.0-bin-hadoop3/bin/spark-submit --class org.example.SparkMain SparkStudyCases.jar 6
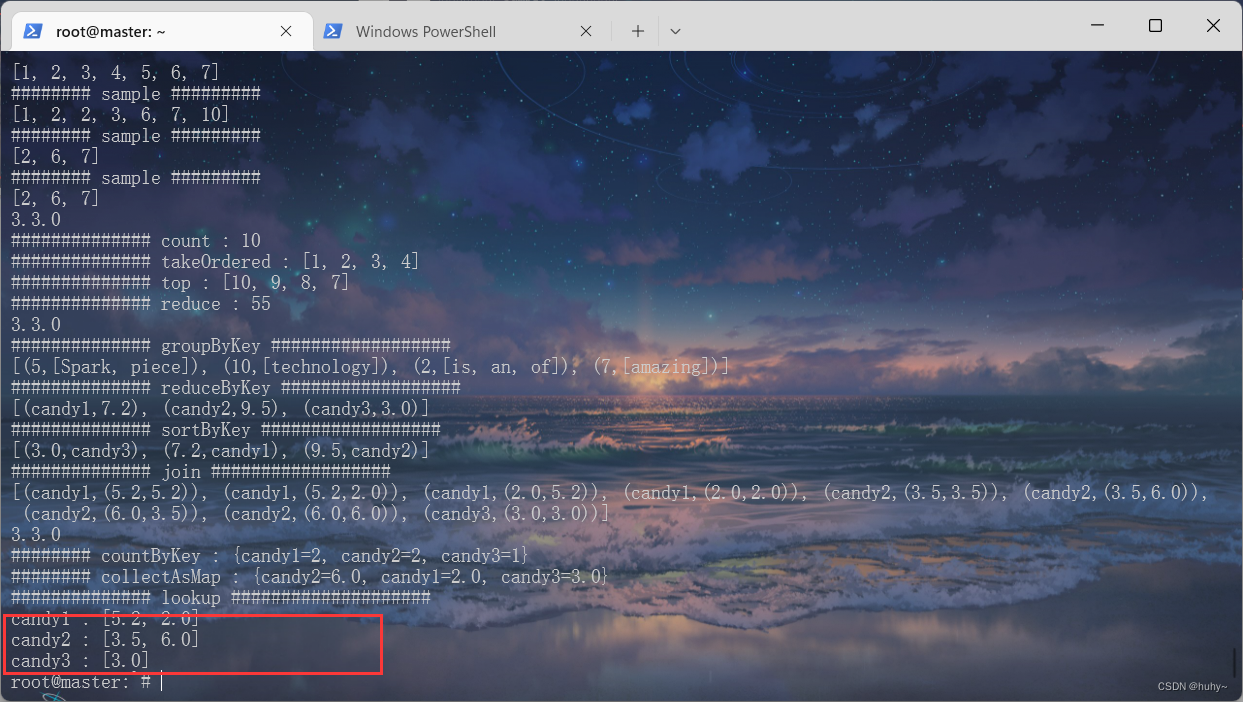
Partition
/usr/local/spark-3.3.0-bin-hadoop3/bin/spark-submit --class org.example.SparkMain SparkStudyCases.jar 7
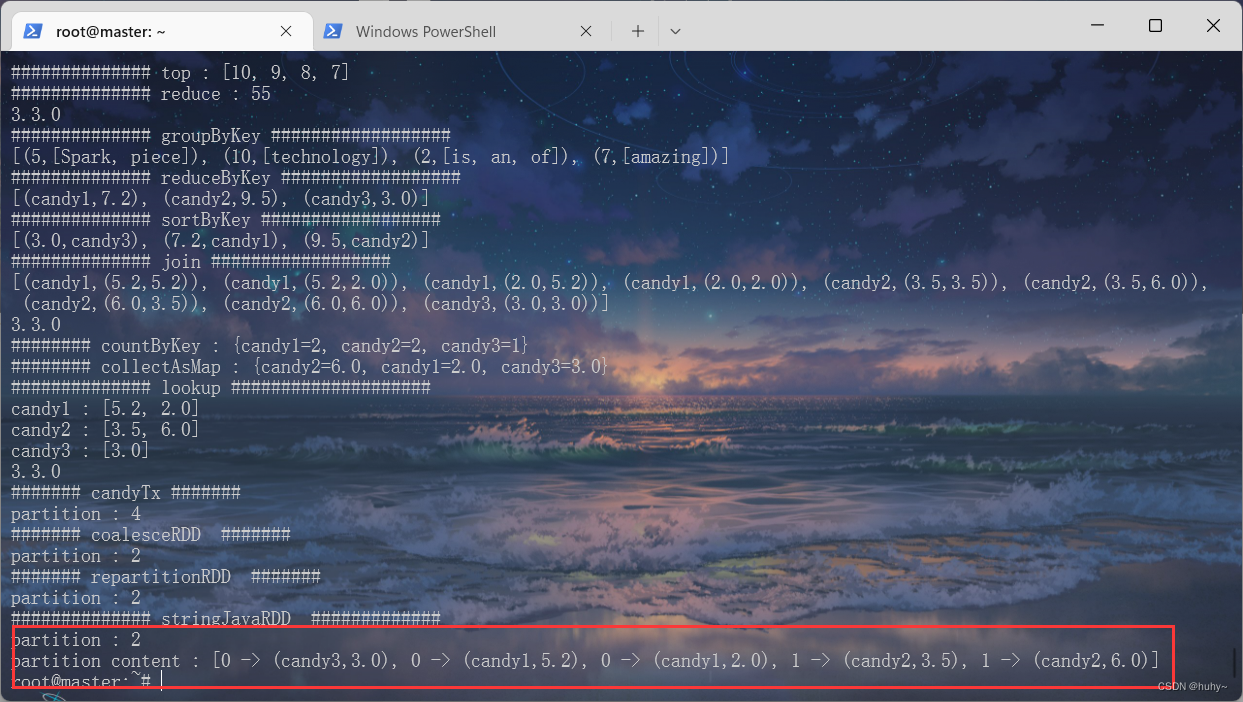
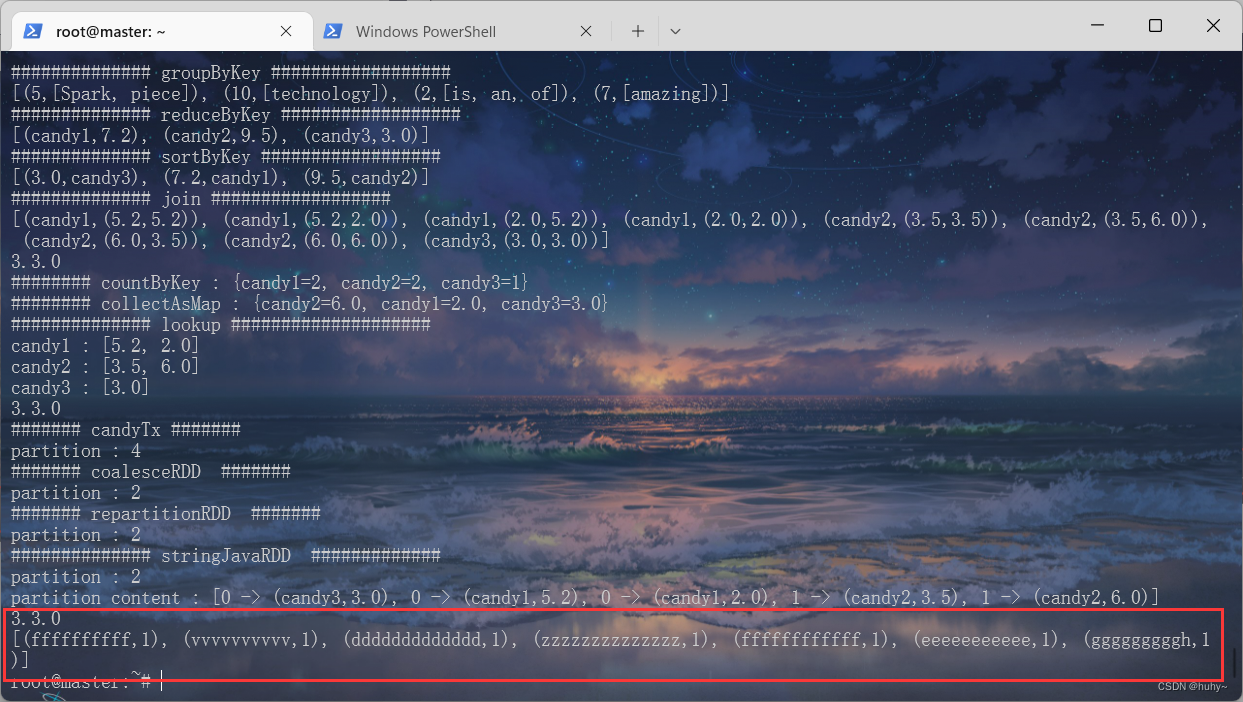
wordCount
词云案例统计
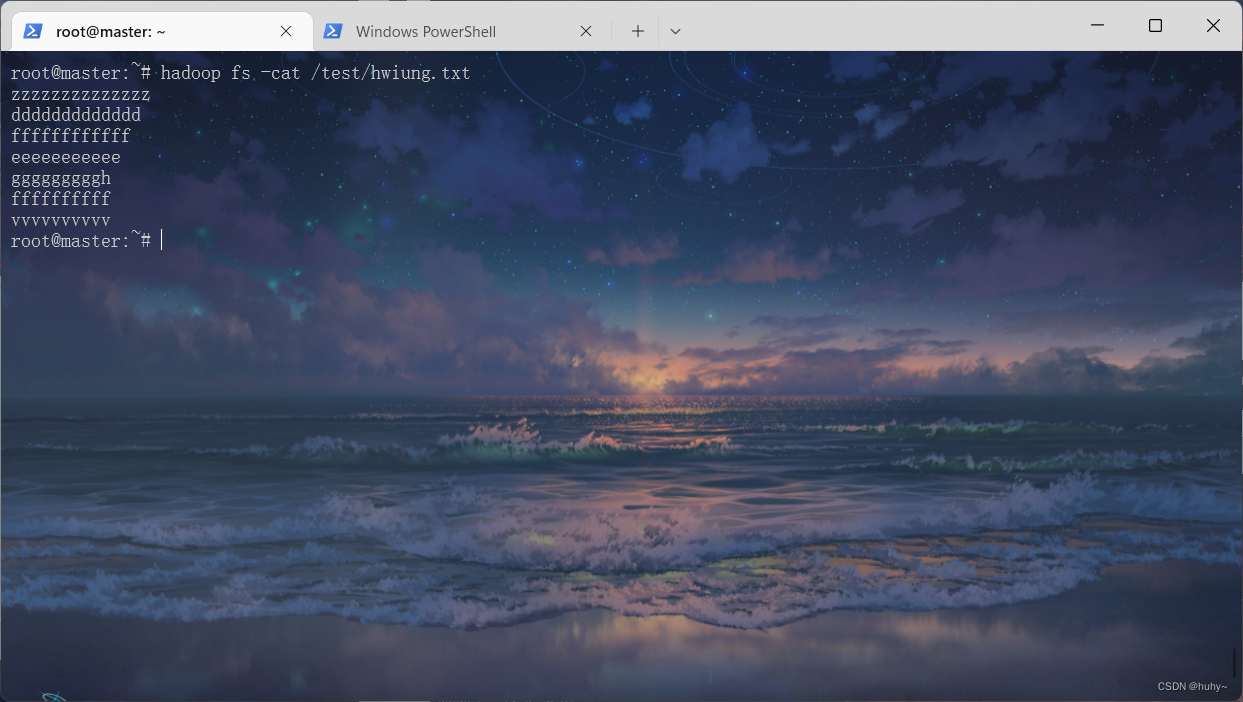
/usr/local/spark-3.3.0-bin-hadoop3/bin/spark-submit --class org.example.SparkMain SparkStudyCases.jar 8 /test/hwiung.txt
仅学习使用~

