(爬虫)Python爬虫02(实战)
目录:
一、爬取图片的例子
三、拓展知识点
四、注意事项


#引入依赖 import urllib.request #将字符串转化为一个 请求对象Request req = urllib.request.Request("http://placekitten.com/200/300") #访问 请求对象Request,并返回 应答对象response response = urllib.request.urlopen(req) #response = urllib.request.urlopen("http://placekitten.com/200/300") 等同于前两步,urlopen函数会自动转化 #应答对象的read方法的使用 print("read方法:图片将下载到该文件的同目录下") #读出 应答对象response,并以二进制字符串形式存入cat_ing中 cat_ing = response.read() #以二进制方式将cat_ing写入cat_ing.jpg文件(图片也是文件)中 with open("cat_200_300.jpg","wb") as f: f.write(cat_ing) #应答对象的geturl方法的使用 print("geturl方法:") cat_url = response.geturl() #返回请求的链接地址url print(cat_url) #将其打印输出 #应答对象的info方法的使用 print("info方法:") cat_message = response.info() #返回HTTPMessage对象。表示远程服务器返回的头信息 print(cat_message) #将其打印输出 #应答对象的getcode方法的使用 print("getcode方法:") cat_code = response.getcode() #返回Http状态码。如果是http请求,200请求成功完成;404网址未找到 print(cat_code) #将其打印输出
运行后会输出如下内容:

import urllib.request #引入请求依赖 import urllib.parse #引入解析依赖 import json #引入json依赖 while 1: #将输入内容存为变量 content = input("请输入需要翻译的内容:") #将链接Request URL存储为变量,便于使用 url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule" #将表单From Data赋值给字典data data = {} data ["i"] = content #将表单中i的值换为变量content(自己输入的内容) data ["from"] = "AUTO" data ["to"] = "AUTO" data ["smartresult"] = "dict" data ["client"] = "fanyideskweb" data ["salt"] = "15838472422107" data ["sign"] = "85a1e803f3f0d04882d66c8cca808347" data ["ts"] = "1583847242210" data ["bv"] = "d6c3cd962e29b66abe48fcb8f4dd7f7d" data ["doctype"] = "json" data ["version"] = "2.1" data ["keyfrom"] = "fanyi.web" data ["action"] = "FY_BY_CLICKBUTTION" #将data编码为url的形式,且将Unicode硬编码为utf-8的形式,存储到data_utf8变量中 data_utf8 = urllib.parse.urlencode(data).encode("utf-8") #通过url和data_utf8获得应答对象,data_utf8将会以POST形式被提交 response = urllib.request.urlopen(url,data_utf8) #将读取的utf-8编码的文件解码回Unicode编码形式 html = response.read().decode("utf-8") print("******返回的原始数据******") #打印输出 (观察会发现:返回的是json结构) print(html) #用json载入字符串(观察发现是一个字典) target = json.loads(html) #打印输出字典中的指定值(即翻译结果) print("******显示处理后的结果******") print("翻译结果:%s" % (target["translateResult"][0][0]["tgt"]))
运行结果如下:

1、开发者模式的使用
(1)有道翻译的例子中部分专业名词可进入 http://fanyi.youdao.com/ 后随意翻译些东西
(2)点击F12进入开发者模式 -- Network -- Name(选择POST表单,如果不知道哪一个是的话,一个一个的试) -- Preview(可以进行预览)如下:

(3)点击F12进入开发者模式 -- Network -- Name(选择POST表单) -- Header
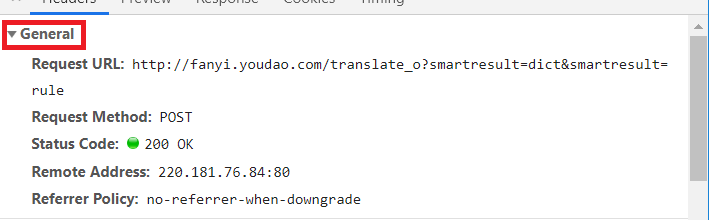
服务器基本信息:(其中Request URL在有道翻译例子中用到了)
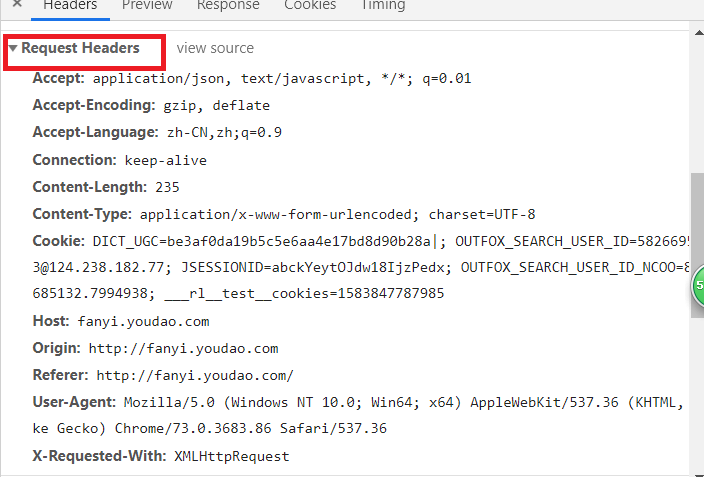
客户端(浏览器)基本信息:
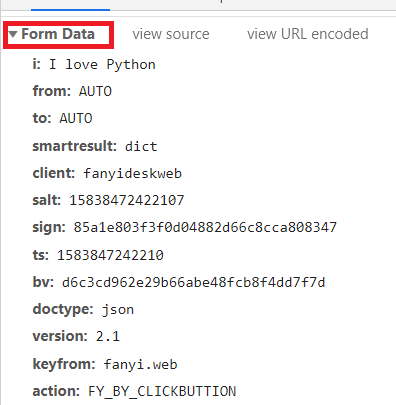
表单数据:(该表单在有道翻译例子中都有用到)
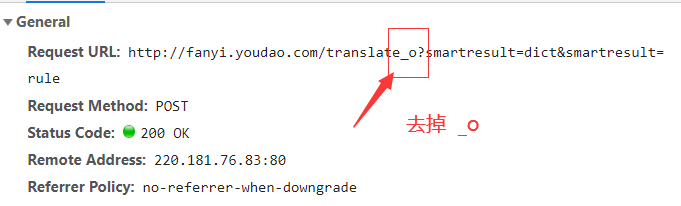
1、有道翻译执行报 {"errorcode":50} 错误
错误原因:有道翻译有反爬虫机制
解决办法:在复制url时去掉链接中的 _o 如下图:
爬虫上一篇:(爬虫)Python爬虫01(入门)
爬虫下一篇:(爬虫)Python爬虫03(隐藏)
本博客参考:
零基础入门学习Python https://www.bilibili.com/video/av4050443?p=55
Python3中rulopen()详解 https://blog.csdn.net/qq_41856814/article/details/99658108
JSON百度百科 https://baike.baidu.com/item/JSON/2462549?fr=aladdin

 浙公网安备 33010602011771号
浙公网安备 33010602011771号