
常用命令:
进入管理员模式:sudo su
退出:exit;
查看当前目录文件:ls ( -a:显示隐藏文件;-l:查看详细信息)
查看当前目录位置:pwd
查看文件内容:cat more head tail (head与tail可以加行数)
查看多个:cat a.c b.c
拼接文件:cat a.c b.c ->d.c
查看帮助文档:man name
创建目录: mkdir name
进入/切换目录:cd name
进入根目录:cd \
进入家目录: cd ~
返回上一级: cd ..
创建文件:touch name
打开并编辑文件:nano name; gedit name
创建文件并进入编辑: vi name
删除文件: rm name
删除非空目录:rm -r name
复制文件: cp a.txt b.txt(将a复制到b)
复制目录(文件夹):cp -r test1 test2(将目录test1复制到test2目录)
文件 file 复制到目录 /usr/men/tmp ,并改名为 file1::cp file/usr/men/tmp/file1
文件改名:mv a.txt b.txt(将a改名为b)
文件移动:mv a.txt 文件夹
mv a.txt 文件夹/新名字
进程间通信:
进程间通信:进程之间要协调工作,所以要进行信息交互。
进程间通信方式:管道、信号、信号量、共享内存、套接字(socket)、消息队列;
管道:管道是半双工通信(同一时刻单向传递);通过管道符“|”创建的是匿名管道且在用完后自动释放。
Linux 下代码中使用pipe创建匿名管道,创建的是大小为2的问文件述符数组,若创建成功则返回 0,创建失败就返回 -1:
int pipe (int fd[2]);
- fd[0] 指向管道的读端,fd[1] 指向管道的写端
- fd[1] 的输出是 fd[0] 的输入
- 双向通信需要创建两个管道;
- 管道的本质就是内核在内存中开辟了一个缓冲区,这个缓冲区与管道文件相关联,对管道文件的操作,被内核转换成对这块缓冲区的操作。
管道分类:
-
有名管道:任意进程之间使用;也称做 FIFO,因为数据是先进先出的传输方式。就是提供一个路径名与之关联,这样,即使与创建有名管道的进程不存在亲缘关系的进程,只要可以访问该路径,就能够通过这个有名管道进行相互通信。
创建代码:mkfifo myPipe
-
无名管道:只适用于父子进程(有亲属关系的进程)
信号:是进程通信机制中唯一的异步通信机制,它可以在任何时候发送信号给某个进程。通过发送指定信号来通知进程某个异步事件的发送,以迫使进程执行信号处理程序。信号处理完毕后,被中断进程将恢复执行。用户、内核和进程都能生成和发送信号。
信号有两种:
- 硬件:键盘:组合键 Ctrl+C 产生 SIGINT 信号,表示终止该进程;
- 软件:命令: kill -9 1111 ,表示给 PID 为 1111 的进程发送 SIGKILL 信号,让其立即结束。
LINUX信号有:
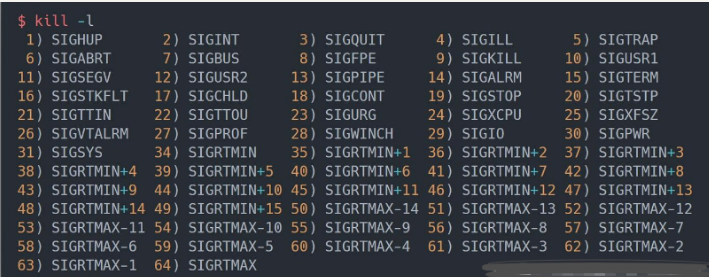
信号量:其实就是一个变量 ,我们可以用一个信号量来表示系统中某种资源的数量,用户进程可以通过使用PV操作来对信号量进行操作,从而很方便的实现进程互斥或同步
-
P 操作:将信号量值减 1,表示申请占用一个资源。
-
V 操作:将信号量值加 1,表示释放一个资源,即使用完资源后归还资源。
-
PV操作成对出现,缺少 P 操作就不能保证对共享内存的互斥访问,缺少 V 操作就会导致共享内存永远得不到释放、处于等待态的进程永远得不到唤醒。
-
问:信号量的值 大于 0 表示有共享资源可供使用,这个时候为什么不需要唤醒进程?
答:所谓唤醒进程是从就绪队列(阻塞队列)中唤醒进程,而信号量的值大于 0 表示有共享资源可供使用,也就是说这个时候没有进程被阻塞在这个资源上,所以不需要唤醒,正常运行即可。
问:信号量的值 等于 0 的时候表示没有共享资源可供使用,为什么还要唤醒进程?
答:V 操作是先执行信号量值加 1 的,也就是说,把信号量的值加 1 后才变成了 0,在此之前,信号量的值是 -1,即有一个进程正在等待这个共享资源,我们需要唤醒它。
定义信号量:
共享内存:多个进程可以访问同一段内存,当某个进程向共享内存写入数据,将立即影响到可以访问同一段共享内存的任何其他进程。
套接字(socket):是网络通信的基石,用于跨网络与不同主机上的进程进行通信,Socket 的本质其实是一个编程接口(API),是应用层与 TCP/IP 协议族通信的中间软件抽象层,它对 TCP/IP 进行了封装。
消息队列:本质就是存放在内存中的消息的链表,。如果进程从消息队列中读取了某个消息,这个消息就会被从消息队列中删除。
- 消息队列允许一个或多个进程向它写入或读取消息。
- 消息队列可以实现消息的随机查询,不一定非要以先进先出的次序读取消息,也可以按消息的类型读取。比有名管道的先进先出原则更有优势。
- 对于消息队列来说,在某个进程往一个队列写入消息之前,并不需要另一个进程在该消息队列上等待消息的到达。而对于管道来说,除非读进程已存在,否则先有写进程进行写入操作是没有意义的。
- 消息队列的生命周期随内核,如果没有释放消息队列或者没有关闭操作系统,消息队列就会一直存在。而匿名管道随进程的创建而建立,随进程的结束而销毁。
注意:消息队列对于交换较少数量的数据很有用,如果数据量较大,使用消息队列就会造成频繁的系统调用,也就是需要消耗更多的时间以便内核介入。
同步与互斥:
- 互斥是指某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。但互斥无法控制对资源的访问顺序;
- 同步是指在互斥的基础上实现对资源的有序访问;就是多个进程协调工作,按照预定的顺序执行.
互斥锁:多进程访问资源时,用加锁的方法来控制对共享资源的访问,互斥锁只有两种状态,即上锁( lock )和解锁( unlock )。
- 在某个资源已经上锁的情况下,另一个进程想枷锁会被挂起等待(不占资源),等上个进程解锁了这个进程再加锁.
条件变量:用来自动阻塞一个线程,直 到某特殊情况发生为止。通常条件变量和互斥锁同时使用。
条件变量是利用线程间共享的全局变量进行同步 的一种机制,主要包括两个动作:
- 一个线程等待"条件变量的条件成立"而挂起;
- 另一个线程使 “条件成立”(给出条件成立信号)。
读写锁:与互斥量类似,不过读写锁允许更改的并行性,也叫共享互斥锁。互斥量要么是锁住状态,要么就是不加锁状态,而且一次只有一个线程可以对其加锁。读写锁可以有3种状态:读模式下加锁状态、写模式加锁状态、不加锁状态。
一次只有一个线程可以占有写模式的读写锁,但是多个线程可以同时占有读模式的读写锁(允许多个线程读但只允许一个线程写)。
特点:
-
如果有其它线程读数据,则允许其它线程执行读操作,但不允许写操作;
-
如果有其它线程写数据,则其它线程都不允许读、写操作。
-
如果某线程申请了读锁,其它线程可以再申请读锁,但不能申请写锁;
-
如果某线程申请了写锁,其它线程不能申请读锁,也不能申请写锁。
进程与线程
进程:一个正在运行的程序,有独立的内存和资源,一个进程可以有多个线程.是资源分配的最小单位。
线程:进程中的一条执行单元;同一个进程的多个线程间共享资源
区别:
第一:什么是进程,什么是线程?
- 进程是程序一次执行的过程,动态的,进程切换时系统开销大
- 线程是轻量级进程,切换效率高
第二:进程和线程的空间分配?
- 进程:每个进程都有独立的0-3G的空间,都参与内核调度,互不影响
- 线程:同一进程中的线程共享相同的地址空间(共享0-3G)
第三:进程之间和线程之间各自的通信方式
- 进程间:(7种)无名管道、有名管道、信号机制、信号灯、共享内存、消息队列、套接字socket
- 线程间:全局变量,信号量,互斥锁
并行与并发
- 并发:并发指的是在同一时间段内处理多个任务,通常在单核处理器上模拟多个任务的同时进行。多个进程交替执行.
- 并行:并行则是在多个处理器或核心上真正同时执行多个任务。并发关注任务的管理和调度,而并行关注任务的同时执行。
线程安全
:是指在多线程环境中,代码能够正确处理多个线程同时访问共享资源的情况,而不会导致数据不一致或程序崩溃等问题。简单来说,就是当多个线程访问同一个对象时,如果不用额外的同步措施,或者在调用方确保调用顺序,这个对象的行为仍然是正确的。
保证线程安全
- 避免共享状态:
- 最简单的方法是避免在多个线程间共享状态。如果每个线程都使用自己的局部变量,那么自然就不存在线程安全问题。
- 使用同步机制:
- 使用互斥锁(Mutex)、读写锁(RWLock)、信号量(Semaphore)等同步机制来控制对共享资源的访问。这些机制可以保证在任何时刻只有一个线程能够访问共享资源。
- 使用原子操作:
- 原子操作是指不可分割的操作,即在执行过程中不会被任何其他线程打断。许多编程语言提供了原子操作的库,如C++11中的
std::atomic,Java中的AtomicInteger等。
- 原子操作是指不可分割的操作,即在执行过程中不会被任何其他线程打断。许多编程语言提供了原子操作的库,如C++11中的
- 使用线程局部存储(Thread Local Storage, TLS):
- 线程局部存储是指每个线程都有自己的存储空间,这样每个线程都只能访问自己的数据,避免了共享状态。
- 使用不可变对象:
- 不可变对象是指一旦创建后其状态就不能被改变的对象。由于不可变对象的状态不会改变,因此它们天然是线程安全的。
- 使用线程安全的类和库:
- 许多编程语言提供了线程安全的类和库,如Java的
Collections框架中的Vector和Hashtable,以及ConcurrentHashMap等。
- 许多编程语言提供了线程安全的类和库,如Java的
- 正确使用条件变量:
- 条件变量是一种同步机制,它允许线程在某个条件不满足时挂起,并在条件满足时被唤醒。
- 避免死锁:
- 在使用多个锁时,要避免死锁的发生。一种常见的策略是总是以相同的顺序获取锁。
- 最小化锁的持有时间:
- 减少线程持有锁的时间可以减少其他线程的等待时间,提高程序的并发性能。
- 使用无锁编程技术:
- 无锁编程是一种避免使用锁的编程技术,它通常依赖于原子操作和特定的算法来保证线程安全。
线程间通信:
信号量:头文件:semaphore.h;
- set_t set;
- sem_init(&sem,0,1);//初始化:传入:地址,是否共享,初始值;
- P操作:sem_wait(&set);
- V操作:sem_post(&sem);
- 销毁:sem_destroy(&set);
互斥锁(可以与信号量为1的信号量互换)
- 定义:pthread_mutex_t name
- pthread_mutex_init(&name,NULL)初始化:传入:地址,属性
- pthread_mutex_lock(&name)加锁:阻塞,传入:地址
- pthread_mutex_unlock(&name)解锁:释放,传入:地址
- pthread_mutex_destroy(&name),传入:地址
读写锁:
-
pthread_rwlock_t name;//创建
-
pthread_rwlock_init(&name,NULL)初始化
-
pthread_rwlock_rdlock()读锁
-
pthread_rwlock_wrlock()写锁
-
pthread_rwlock_unlock()解锁
-
pthread_rwlock_destroy(&name);//销毁
-
读可以共同进行但写只能单个进行
条件变量:多线程等待条件变量,被唤醒的线程运行;
- pthread_mutex_ t name1;
- pthread_cond_t name2;//创建条件变量
- pthread_cond_wait(&name2,&name1);//还需要互斥锁;内部会有加锁,解锁的过程;
- pthread_creat(&name,NULL,fun1,NULL);//创建
- 初始化:pthread_cond_init();
- 销毁pthread_cond_destroy();
- 唤醒某个线程:pthread_cond_signal();
- 唤醒所有等待的线程:pthread_cond_broadcast();
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <pthread.h>
#include <semaphore.h>
pthread_mutex_t mutex;
pthread_cond_t cond;
char buff[128] = {0};
void * funa(void* arg)
{
while( 1 )
{
pthread_mutex_lock(&mutex);
pthread_cond_wait(&cond,&mutex);
pthread_mutex_unlock(&mutex);
if( strncmp(buff,"end",3) == 0 )
{
printf("funa break\n");
break;
}
printf("funa :%s\n",buff);
}
}
void* funb(void* arg)
{
while( 1 )
{
pthread_mutex_lock(&mutex);
pthread_cond_wait(&cond,&mutex);
pthread_mutex_unlock(&mutex);
if( strncmp(buff,"end",3) == 0 )
{
printf("funb break\n");
break;
}
printf("funb :%s\n",buff);
}
}
int main()
{
pthread_mutex_init(&mutex,NULL);
pthread_cond_init(&cond,NULL);
pthread_t id1,id2;
pthread_create(&id1,NULL,funa,NULL);
pthread_create(&id2,NULL,funb,NULL);
while( 1 )
{
fgets(buff,128,stdin);//
if( strncmp(buff,"end",3) == 0 )
{
pthread_mutex_lock(&mutex);
pthread_cond_broadcast(&cond);
pthread_mutex_unlock(&mutex);
break;
}
else
{
pthread_mutex_lock(&mutex);
pthread_cond_signal(&cond);
pthread_mutex_unlock(&mutex);
}
}
pthread_join(id1,NULL);
pthread_join(id2,NULL);
pthread_mutex_destroy(&mutex);
pthread_cond_destroy(&cond);
exit(0);
}
作业:使用信号量,按顺序打印5遍A,B,C;
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <semaphore.h>
sem_t s1, s2, s3;
void* funa(void* arg) {
for (int i = 0; i < 5; i++) {
sem_wait(&s1);
printf("A ");
fflush(stdout);
sem_post(&s2);
}
return NULL;
}
void* funb(void* arg) {
for (int i = 0; i < 5; i++) {
sem_wait(&s2);
printf("B ");
fflush(stdout);
sem_post(&s3);
}
return NULL;
}
void* func(void* arg) {
for (int i = 0; i < 5; i++) {
sem_wait(&s3);
printf("C\n ");
fflush(stdout);
sem_post(&s1);
}
return NULL;
}
int main() {
pthread_t thread_a, thread_b, thread_c;
sem_init(&s1, 0, 1);
sem_init(&s2, 0, 0);
sem_init(&s3, 0, 0);
pthread_create(&thread_a, NULL, funa, NULL);
pthread_create(&thread_b, NULL, funb, NULL);
pthread_create(&thread_c, NULL, func, NULL);
pthread_join(thread_a, NULL);
pthread_join(thread_b, NULL);
pthread_join(thread_c, NULL);
sem_destroy(&s1);
sem_destroy(&s2);
sem_destroy(&s3);
return 0;
}
生产者消费者问题概述
生产者/消费者问题,也被称作有限缓冲问题。可以描述为:两个或者更多的线程共享同一个缓冲区,其中一个或多个线程作为“生产者”会不断地向缓冲区中添加数据,另一个或者多个线程作为“消费者”从缓冲区中取走数据。生产者/消费者模型关注的是以下几点:
- 生产者和消费者必须互斥的使用缓冲区
- 缓冲区空时,消费者不能读取数据
- 缓冲区满时,生产者不能添加数据
生产者消费者模型优点:
-
解耦:因为多了一个缓冲区,所以生产者和消费者并不直接相互调用,这样生产者和消费者的代码发生变化,都不会对对方产生影响。这样其实就是把生产者和消费者之间的强耦合解开,变成了生产者和缓冲区,消费者和缓冲区之间的弱耦合
-
支持并发:如果消费者直接从生产者拿数据,则消费者需要等待生产者生产数据,同样生产者需要等待消费者消费数据。而有了生产者/消费者模型,生产者和消费者可以是两个独立的并发主体。生产者把制造出来的数据添加到缓冲区,就可以再去生产下一个数据了。而消费者也是一样的,从缓冲区中读取数据,不需要等待生产者。这样,生产者和消费者就可以并发的执行。
-
支持忙闲不均:如果消费者直接从生产者这里拿数据,而生产者生产数据很慢,消费者消费数据很快,或者生产者生产数据很多,消费者消费数据很慢。都会造成占用CPU的时间片白白浪费。生产者/消费者模型中,生产者只需要将生产的数据添加到缓冲区,缓冲区满了就不生产了。消费者从缓冲区中读取数据,缓冲区空了就不消费了,使得生产者/消费者的处理能力达到一个动态的平
衡。
生产者消费者模型实现
- 假定缓冲池中有N个缓冲区,一个缓冲区只能存储一个int类型的数据。定义互斥锁mutex实现对缓冲区的互斥访问;计数信号量dempty用来表示空闲缓冲区的数量,其初值为N;计数信号量dfull用来表示有数据的缓冲区的数量,其初值为0
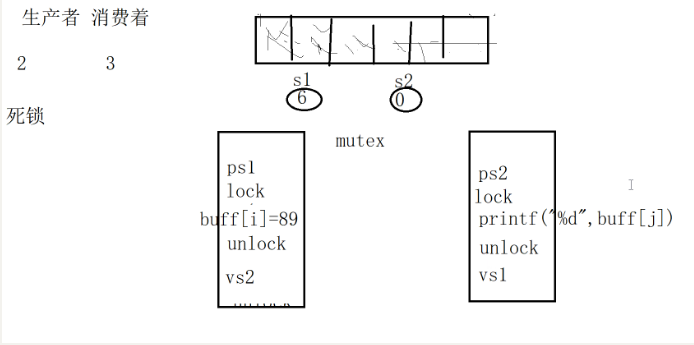
代码实现如下:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <assert.h>
#include <pthread.h>
#include <semaphore.h>
#include <time.h>
#define BUFF_MAX 30
#define SC_NUM 2
#define XF_NUM 3
int in = 0;
int out = 0;
sem_t sem_empty;
sem_t sem_full;
pthread_mutex_t mutex;
int buff[BUFF_MAX] = {0};
void * sc_thread(void* arg)
{
int index = (int)arg;
while( 1 )
{
sem_wait(&sem_empty);
pthread_mutex_lock(&mutex);
buff[in] = rand()%100;
printf("生产者%d 产生数据%d,in=%d\n",index,buff[in],in);
in = (in + 1) % BUFF_MAX;
pthread_mutex_unlock(&mutex);
sem_post(&sem_full);
int n = rand() % 10;
sleep(n);
}
}
void * xf_thread(void* arg)
{
int index = (int)arg;
while(1)
{
sem_wait(&sem_full);
pthread_mutex_lock(&mutex);
printf("消费者%d 消费数据%d,out=%d\n",index,buff[out],out);
out = (out+1) % BUFF_MAX;
pthread_mutex_unlock(&mutex);
sem_post(&sem_empty);
int n = rand() % 10;
sleep(n);
}
}
int main()
{
pthread_mutex_init(&mutex,NULL);
sem_init(&sem_empty,0,BUFF_MAX);
sem_init(&sem_full,0,0);
srand((int)time(NULL));
pthread_t sc_id[SC_NUM];
pthread_t xf_id[XF_NUM];
int i = 0;
for( ; i < SC_NUM; i++ )
{
pthread_create(&sc_id[i],NULL,sc_thread,(void*)i);
}
for( i = 0; i < XF_NUM; i++ )
{
pthread_create(&xf_id[i],NULL,xf_thread,(void*)i);
}
for( i = 0; i < SC_NUM; i++ )
{
pthread_join(sc_id[i],NULL);
}
for( i = 0; i < XF_NUM; i++ )
{
pthread_join(xf_id[i],NULL);
}
sem_destroy(&sem_empty);
sem_destroy(&sem_full);
pthread_mutex_destroy(&mutex);
exit(0);
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号