
集合
集合中的关系
常用类
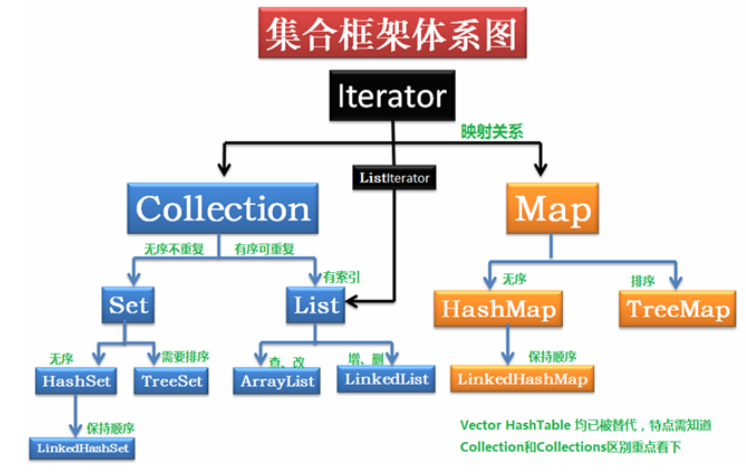
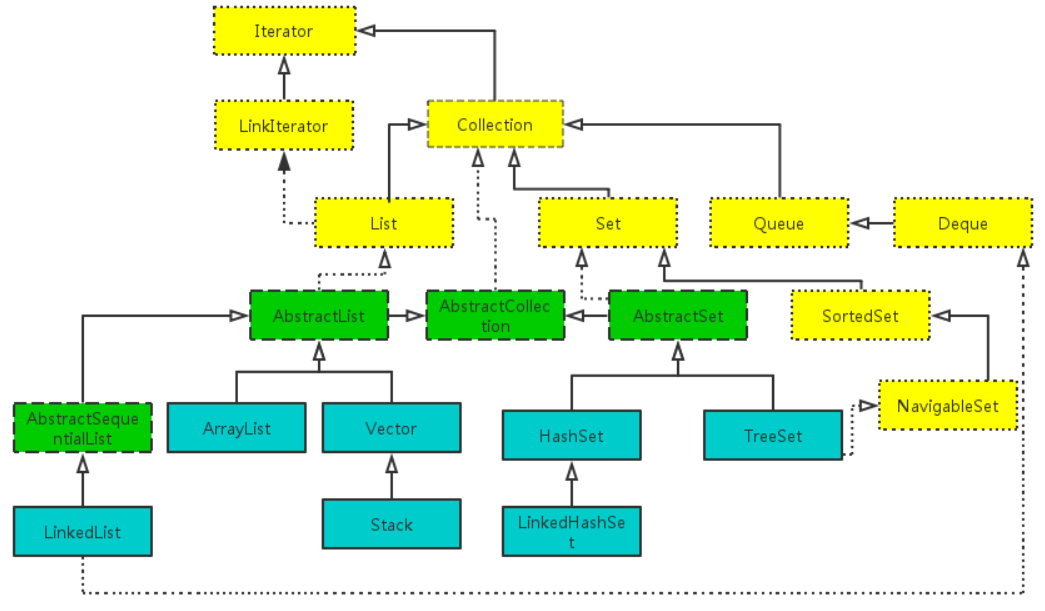
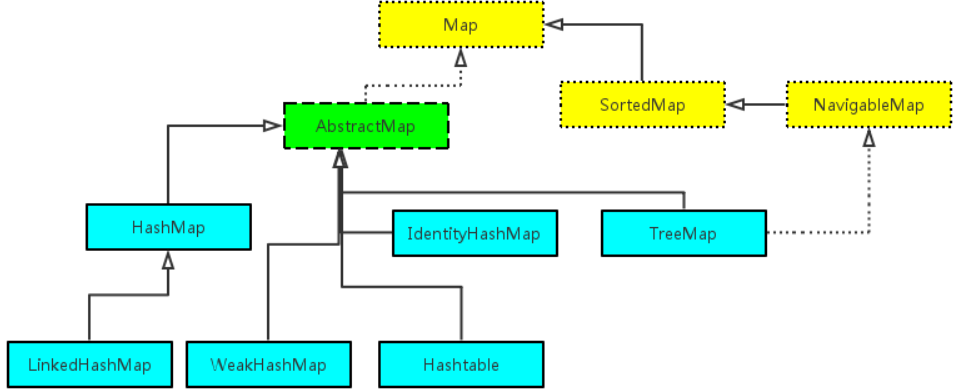
详细图:黄色的代表接口,绿色的是抽象类,蓝色的具体类
/**
----collection接口:单列集合,用来存储一个一个的对象
---List接口:存储有序的、可重复的数据。“动态”数组,替换原有的数组
----Arraylist:作为list接口的主要实现类;线程不安全的,效率高;
底层使用Object[] elementData存储
----Linkedlist:对于频繁的插入、删除操作,使用此类效率比ArrayList高;
底层使用双向链表存储
----Vector:作为list接口的古老实现类;线程安全的,效率低;
底层使用Object[] elementData存储
----Set接口:存储无序的、不可重复的数据
----HashSet:作为set接口的主要实现类;线程不安全的;可以存储nuLl值
---LinkedHashSet:作HashSet的子类;遍历其内部数据时,可以按照添加的顺序遍历
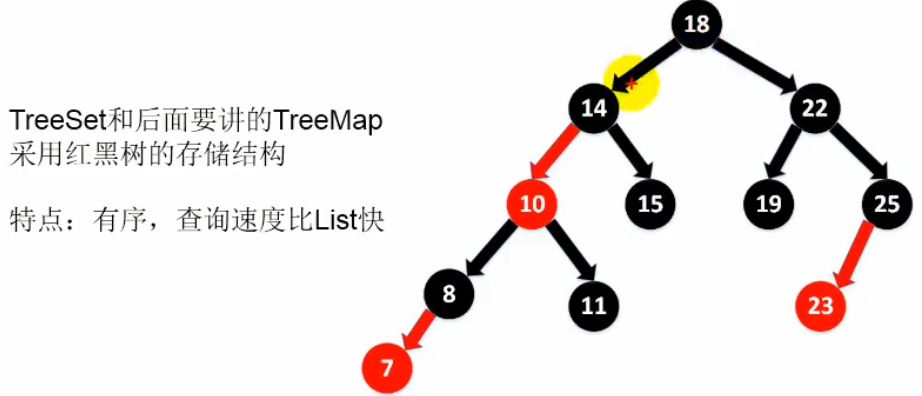
---TreeSet:可以按照添加对象的指定属性,进行排序;底层是 红黑树结构
向TreeSet中添加数据,要求是相同类的对象,才能进行排序;
----Map:双列数据,存储key-value对的数据
----HashMap:作为Map的主要实现类;线程不安全的,效率高;可以存储null的key 和 value。
底层:数组+链表(jdk7及之前);数组+链表+红黑树(jdk8)|
----LinkedHashMap:保证在遍历map元素时,可以按照添加的顺序实现遍历。
原因:在原有的HashMap底层结构基础上,添加了一对指针,指向前一个和后一个元素。
----TreeMap:保证按照添加的key-value对进行排序,实现排序遍历(要求key必须是同一类型)。
此时考虑key的自然排序和定制排序。底层使用红黑树结构。
---Hashtable:作为古老的实现类;线程安全的,效率低;不能存储nuLL的key 和value
----Properties: 常用来处理配置文件。key value都是string类型
*/
ArrayList源码
JDK7 中ArrayList源码
ArrayList list=new Arraylist();//底层创建了长度是10的object[]数组elementData
list.add(123); //相当于elementData[e]=new Integer(123);
...
List.add(11);//“加到了第11个”,如果此次的添加导致底层eLementData数组容量不够,则扩容。
默认情况下,扩容为原来的容量1.5倍,同时需要将原有数组中的数据复制到新的数组中。
JDK8中ArrayList的变化
Arraylist list=new Arraylist();//底层0bject[] elementData初始化为{}.并没有创建长度为10的数组
List.add(123);//第一次调用add()时,底层才创建了长度为10的数组,并将数123添加到elementData数组中
//后续的添加和护容操作与jdk7无异。
JDK8中ArrayList源码分析
//通过无参构造器进行操作
//ArrayList其中有以下变量:
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* Shared empty array instance used for empty instances.
*/
private static final Object[] EMPTY_ELEMENTDATA = {}; // (EMPTY_ELEMENTDATA).length = 0;
/**
* Shared empty array instance used for default sized empty instances. We
* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
* first element is added.
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
//空构造器如下:
/**
* Constructs an empty list with an initial capacity of ten.
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; //默认数组容量是0
}
//当执行add方法时,数组自动扩容。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // 初次使用add时 size = 0
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity)); //括号里面返回值是10
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { //初次使用add方法 走这条语句
return Math.max(DEFAULT_CAPACITY, minCapacity); //return DEFAULT_CAPACITY = 10
}
return minCapacity;
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0) //10 - 0 = 10 > 0
grow(minCapacity); //扩容方法
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;//旧容量,0
//新容量,右移一位表示oldCapacity / 2,右移比计算除法要快的多,这里扩容1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)//新容量小于最小需要的容量则把最小需要的容量 赋值给新容量
newCapacity = minCapacity; // 10
//新容量大于数组最大的容量【Integer.MAX_VALUE - 8 = 2147483639】则新容量是hugeCapacity的返回值
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
public static <T> T[] copyOf(T[] original, int newLength) {
return (T[]) copyOf(original, newLength, original.getClass());
}
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
@SuppressWarnings("unchecked")
//若是Object类型则创建Object数组,反之获取元素类型,创建该类型数组
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
public static Object newInstance(Class<?> componentType, int length)
throws NegativeArraySizeException {
return newArray(componentType, length); //创建了数组
}
/**
Params:
src – the source array.
srcPos – starting position in the source array.
dest – the destination array.
destPos – starting position in the destination data.
length – the number of array elements to be copied.
*/
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
ArrayList中有两个remove()方法
public E remove(int index){} //根据索引删除,并返回删除的数据
public boolean remove(Object o){} //根据对象删除
//如:
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add(1);
list.add(2); //此处 整数 自动装箱成Integer类型,因为List 的 add方法参数是对象类型
list.add(3);
removeList(list);
System.out.println(list); //[1, 2]
}
public static void removeList(List list){
list.remove(2); //此处删除的是 索引
}
Iterator迭代器
查看集合中所有元素可以使用迭代器。
Collection<String> c = . . .;
Iterator<String> iter = c.iterator();
while (iter.hasNext()){
String element = iter.next();
do something with element
}
//也可用for each循环来实现
for (String element : c){
do something with element
}
//编译器简单地将“ foreach” 循环翻译为带有迭代器的循环。
Iterator接口中的方法如下
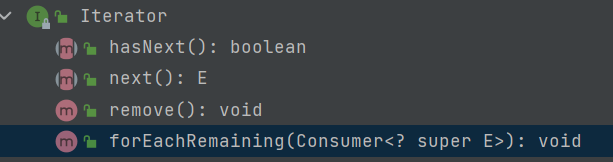
remove()方法
//remove 方法将会删除上次调用 next 方法时返回的元素。如:
Iterator<String> it = c.iterator()
it.next() // skip over the first element
it.remove(); // now remove it
forEachRemaining()方法
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
//可以用lambda表达式来操作
LinkedList源码
- 底层是双链表
1. 节点存储结构类型
private static class Node<E> {
E item; //具体元素值
Node<E> next; //前驱
Node<E> prev; //后继
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
以空构造器为例阐述插入元素过程
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0; //链表上现存元素个数
/**
* Pointer to first node.
* Invariant(不变量): (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
public LinkedList() {
}
public boolean add(E e) {
linkLast(e); //插入链表末尾
return true;
}
void linkLast(E e) {
final Node<E> l = last; //插入第一个元素时,l=null;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null) //第一次插入判断结果true
first = newNode;
else
l.next = newNode; //每次last指向链表的末尾
size++;
modCount++;
}
Set
/**
1. 无序性:不等同随机性,添加数据按照 哈希值 添加
2. 不可重复性: 添加的元素按照equals判断时,不能返回true
*/
public static void Test1(){
Set set = new HashSet(); //①
set.add(11);
set.add(11);
set.add(new String("aa"));
set.add("bb");
set.add("aa");
for (Object s: set){
System.out.println(s); //结果:aa bb 11, 体现了 无序 和 不可重复性
}
}
//当把 ① 换成 Set set = new LinkedHashSet();时
//结果是: 11 aa bb, 按照添加的顺序输出
以HashSet为例 阐述元素添加过程
//HashSet底层是 HashMap
/**
1. 向Set中添加数据时,要重写hashCode()和equals()方法。
2. 向 HashSet 中添加元素a,首先调用元素a所在类的hashCode()方法,计算元素a的哈希值,
此哈希值接着通过某种算法计算出在HashSet底层数组中的存放位置(即为:索引位置),
判断数组此位置上是否已经有元素:
如果此位置上没有其他元素,则元素a添加成功。
如果此位置上有其他元素b(或以链表形式存在的多个元素),则比较元素a与元素b的hash值:
如果hash值不相同,则元素a添加成功。
如果hash值相同,进而需要调用元素a所在类的equlas()方法:
equals()返回true,元素a添加失败
equals()返回false,则元素a添加成功。
对于添加成功的元素来说:元素a与已经存在指定索引位置上数据以链表的方式存储。
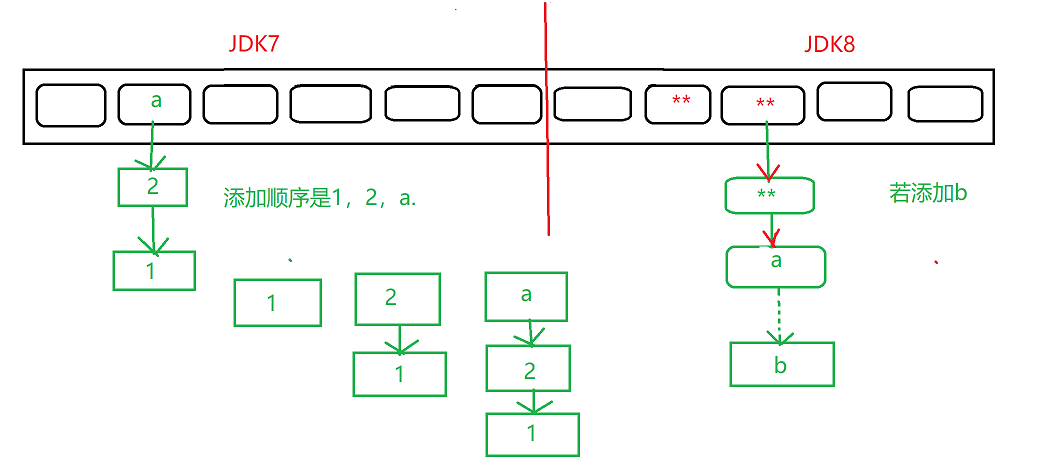
在jdk7:元素a放到数组中,指向原来的元素。jdk8:原来的元素在数组中,指向元素a。如下图
*/
TreeSet
example
// Ⅰ.TreeSet自然排序
// 1.
/**
编译时不报错,运行时抛出异常 java.lang.Integer cannot be cast to java.lang.String
原因是:TreeSet 添加数据时,需要添加同一种类型
*/
TreeSet treeSet = new TreeSet();
treeSet.add(33);
treeSet.add("33");
treeSet.add(new String("df"));
// 2.
TreeSet treeSet = new TreeSet();
treeSet.add(35);
treeSet.add(-85);
treeSet.add(25);
treeSet.add(17);
treeSet.add(15);
Iterator iterator = treeSet.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
// result:-85 15 17 25 35
// 3.
class Person3 implements Comparable<Person3>{
private String name;
private int age;
public Person3() {
}
public Person3(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person3 person3 = (Person3) o;
return age == person3.age && Objects.equals(name, person3.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
@Override
public String toString() {
return "Person3{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public int compareTo(Person3 o) {
return this.name.compareTo(o.getName());
}
}
public static void test1(){
TreeSet treeSet = new TreeSet();
treeSet.add(new Person3("jerry",20));
treeSet.add(new Person3("marry",30));
treeSet.add(new Person3("xiaoMing",18));
treeSet.add(new Person3("liBai",21));
treeSet.add(new Person3("wangAnShi",15));
Iterator iterator = treeSet.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
}
/** result
Person3{name='jerry', age=20}
Person3{name='liBai', age=21}
Person3{name='marry', age=30}
Person3{name='wangAnShi', age=15}
Person3{name='xiaoMing', age=18}
*/
// 4.看下面一种情况
// 比较器是根据姓名比较的,当添加相同姓名时,TreeSet按照相同处理了
treeSet.add(new Person3("jerry",20));
treeSet.add(new Person3("marry",30));
treeSet.add(new Person3("xiaoMing",18));
treeSet.add(new Person3("liBai",21));
treeSet.add(new Person3("wangAnShi",15));
treeSet.add(new Person3("wangAnShi",16));
/** result:相同的姓名没有添加进来,若想相同姓名也添加进来,可以在比较方法中做判断
Person3{name='jerry', age=20}
Person3{name='liBai', age=21}
Person3{name='marry', age=30}
Person3{name='wangAnShi', age=15}
Person3{name='xiaoMing', age=18}
*/
// Ⅱ.TreeSet定制排序,可以用此构造器
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
Map的理解
- Map 中的key:无序的、不可重复的,使用Set 存储所有的key
key所在的类要重写equals()和hashCode()(以HashMap为例) - Map 中的value:无序的、可重复的,使用coLLection存储所有的value
value所在的类要重写equals()- 一个键值对:key-value构成了一个Entry对象。
- Map 中的entry:无序的、不可重复的,使用Set 存储所有的entry
HashMap的底层,以jdk7为例说明:
HashMap map=new HashMap():在实例化以后,底层创建了长度是16的一维数组Entry[] table。- ..可能已经执行过多次
put()... map.put(key1,value1):首先,调用key1所在类的hashcode()计算key1哈希值,
此哈希值经过某种算法计算以后,得到在Entry数组中的存放位置。- 如果此位置上的教据为空,此时的
key1-value1添加成功。 - 如果此位置上的数据不为空,(意味着此位置上存在一个或多个数据(以链表形式存在)),比较
key1和已经存在的一个或多个数据的哈希值:
- 如果key1的哈希值与已经存在的数据的哈希值都不相同,此时
key1-value1添加成功。 - 如果key1的哈希值和已经存在的某一个数据
(key2-value2)的哈希值相同,继续比较:调用key1所在类的equals(key2)
- 如果
equals()返回false:此时key1-value1添加成功。 - 如果
equals()返回true:使用value1替换value2。
在不断的添加过程中,会涉及到扩容问题,默认的扩容方式:扩容为原来容量的2倍,并将原有的数据复制过来。
HashMap中jdk8相较于jdk7的区别
new HashMap():底层没有创建一个长度为16的数组jdk8底层的数组是:Node[],而非Entry[]- 首次调用
put()方法时,底层创建长度为16的数组 jdk7低层结构只有:效组+链表。
jdk8中民层结构:组+链表+红器树。当数组的某一个索引位置上的元素以链表形式存在的
数据个数 > 8 且 当前数组的长度 > 64时,此时此索引位置上的所有数据改为使用红黑树(二叉排序树)存储。
JDK8中字段说明
DEFAULT_INITIAL_CAPACITY //HashMap的默认容量,16;且必须是2的幂次方
DEFAULT_LOAD_FACTOR //HashMap的默认加载因子:0.75
threshold //扩容的临界值,=容量*填充因子:16*0.75 = 12
TREEIFY_THRESHOLD //Bucket 中链表长度大于该默认值,转化为红黑树:8
MIN_TREEIFY_CAPACITY //桶中的Node被树化时最小的hash表容量:64
HashMap源码
以空构造器 示例:new HashMap()
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; //16
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
Node<K,V>[] table; table = null
Node<K,V>[] table = {}; table = 引用值
*/
transient Node<K,V>[] table; // 底层Node类型的数组
/**
Constructs an empty HashMap with the default initial capacity
(16) and the default load factor (0.75).
*/
//用a b c ...代表向map中添加数据【put()】的情况
//【a】第一次put().
//【b】未扩容时put().
//【c】
public HashMap() { //【a】可以看到 new HashMap()时,并没有 创建长度16的数组,在put()时 创建数组
this.loadFactor = DEFAULT_LOAD_FACTOR; // 装在因子0.75
}
public V put(K key, V value) { // hash(key) 根据指定算法计算哈希值,一个int型值,了解即可
return putVal(hash(key), key, value, false, true);
}
/** Params:
onlyIfAbsent – if true, don't change existing value[true:当添加的数据和已经存在的数据相同,
则不更改其值,false:当添加的数据和已经存在的数据相同,更改其值]
evict – if false, the table is in creation mode.
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//【a】第一次Put,table是null,因为是或(||),则||后面的判断不用再看,整体判断结果true
//【b】table不为null且n(表里有值)不为0,整体判断结果false
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; //【a】看下面resize(),结果 n = 16;
//(n - 1) & hash是计算哈希索引的算法(可类比数据结构中取模运算)
//【a】第一次put,p=null
//【b】若计算出的地址没有存值即p=null,则此位置添加值
// 若计算出的地址有值,则走else语句
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);//tab[i]位置处放入第一个key-value值
else {
Node<K,V> e; K k;
//哈希值不同,则整体结果false.哈希值相同,则比较key
//(k = p.key) == key这里是引用比较,若是同一个引用,后面不用再判断
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode) //p是否是红黑树类型
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) { //e是链表上下一个元素
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // 链表上有8个数据,则转treeifyBin
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key【a】e!=null 新值替换旧值
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)//【a】size=1,threshold=12.判断false
resize();
afterNodeInsertion(evict);//看代码,啥也不干,在LinkedHashMap需要此函数
return null; //添加成功返回null
}
void afterNodeAccess(Node<K,V> p) { }
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table; //【a】第一次put table是null
int oldCap = (oldTab == null) ? 0 : oldTab.length; //【a】oldCap=null
int oldThr = threshold; //【a】threshold初始值:0
int newCap, newThr = 0;
if (oldCap > 0) {//第一次Put 判断结果false
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // 第一次Put 判断结果false
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY; //【a】newCap = 16
//【a】newThr=0.75*16=12
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr; //threshold = 12
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; //创建长度16数组
table = newTab;
if (oldTab != null) { //【a】第一次put,oldTab = table = null
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab; //返回数组
}
map示例
HashMap map = new HashMap();
//添加
map.put("AA",23);
map.put("BB",13);
map.put("CC",43);
//修改,key无序,不可重复
map.put("AA",63);
System.out.println(map); //result: {AA=63, BB=13, CC=43}
map.clear(); //看clear源码,不是让map=null,
System.out.println(map); //结果:{},下面的结果:0
System.out.println(map.size()); //因为map不是null,不会报空指针异常.
//clear源码
public void clear() {
Node<K,V>[] tab;
modCount++;
if ((tab = table) != null && size > 0) {
size = 0;
for (int i = 0; i < tab.length; ++i)
tab[i] = null;
}
}
//size源码
public int size() {
return size;
}
map遍历
public static void test(){
HashMap map = new HashMap();
map.put("XX",23);
map.put("AB",13);
map.put("CC",43);
//遍历所有的Key集
Set set = map.keySet();
Iterator iterator = set.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next()); //result: XX CC AB
}
//遍历所有Value集
Collection values = map.values();
for (Object c: values){
System.out.println(c); //result: 23 43 13
}
//遍历所有的key-value集
/** 结果:
XX=23
key=XX,value=23
CC=43
key=CC,value=43
AB=13
key=AB,value=13
*/
Set entrySet = map.entrySet();
for (Object s: entrySet){
System.out.println(s);
Map.Entry entry = (Map.Entry) s;
System.out.println("key="+entry.getKey()+",value="+entry.getValue());
}
/** 结果:
key=XX,value=23
key=CC,value=43
key=AB,value=13
*/
Set keySet = map.keySet();
Iterator iterator1 = keySet.iterator();
while (iterator1.hasNext()){
Object set1 = iterator1.next();
Object value1 = map.get(set1);
System.out.println("key="+set1+",value="+value1);
}
}
LinkedHashMap
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>{}
/**
看源码发现 该类没有put方法,由此可知该put方法用的是父类HashMap的put().
*/
示例
//按照添加的顺序输出
HashMap map = new LinkedHashMap();
map.put("XX",23);
map.put("AB",13);
map.put("CC",43);
System.out.println(map); //结果:{XX=23, AB=13, CC=43}
TreeMap
//1. 自然排序
public static void test7(){
TreeMap map = new TreeMap();
map.put("XX",23);
map.put("AB",13);
map.put("CC",43);
System.out.println(map); //{AB=13, CC=43, XX=23} 按照key值排序
}
//2. 定制排序
public static void test8(){
Comparator<String> c = new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return -o1.compareTo(o2);
}
};
TreeMap map = new TreeMap(c);
map.put("XX",23);
map.put("AB",13);
map.put("CC",43);
map.put("CC",63);
System.out.println(map); //{XX=23, CC=63, AB=13}
}
